前端如何实现高性能表格?
每个前端都想做一个完美的表格,业界也在持续探索不同的思路,比如钉钉表格、语雀表格。
笔者所在数据中台团队也对表格有着极高的要求,尤其是自助分析表格,需要兼顾性能与交互功能,本文便是记录自助分析表格高性能的研发思路。
精读
要做表格首先要选择基于 DOM 还是 Canvas,这是技术选型的第一步。比如钉钉表格就是 基于 Canvas 实现的,当然这不代表 Canvas 实现就比 DOM 实现要好,从技术上各有利弊:
- Canvas 渲染效率比 DOM 高,这是浏览器实现导致的。
- DOM 可拓展性比 Canvas 好,渲染自定义内容首选 DOM 而非 Canvas。
技术选型要看具体的业务场景,钉钉表格其实就是在线 Excel,Excel 这种形态决定了单元格内一定是简单文本加一些简单图标,因此不用考虑渲染自定义内容的场景,所以选择 Canvas 渲染在未来也不会遇到不好拓展的麻烦。
而自助分析表格天然可能拓展图形、图片、操作按钮到单元格中,对轴的拖拽响应交互也非常复杂,为了不让 Canvas 成为以后拓展的瓶颈,还是选择 DOM 实现比较妥当。
那问题来了,既然 DOM 渲染效率天然比 Canvas 低,我们应该如何用 DOM 实现一个高性能表格呢?
其实业界已经有许多 DOM 表格优化方案了,主要以按需渲染、虚拟滚动为主,即预留一些 Buffer 区域用于滑动时填充,表格仅渲染可视区域与 Buffer 区域部分。但这些方案都不可避免的存在快速滑动时白屏问题,笔者通过不断尝试终于发现了一种完美解决的方案,我们一起往下看吧!
单元格使用 DIV 绝对定位
即每个单元格都是用绝对定位的 DIV 实现,整个表格都是有独立计算位置的 DIV 拼接而成的:
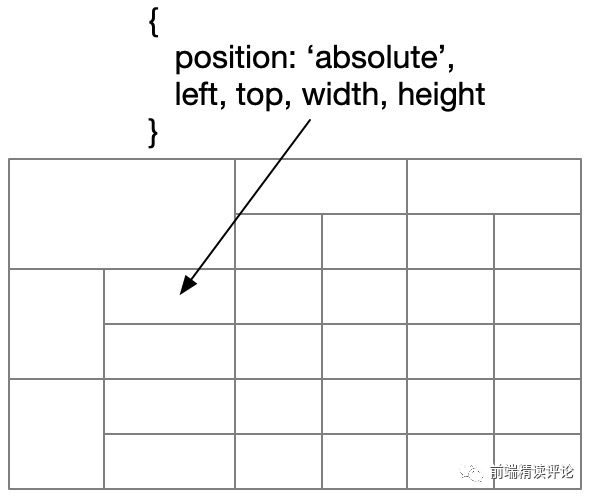
- 所有单元格位置都要提前计算,这里可以利用 web worker 做并行计算。
- 单元格合并仅是产生一个更大的单元格,它的定位方式与小单元格并无差异。
带来的好处是:
- 滚动时,单元格可以最大程度实现复用。
- 对于合并的单元格,只会让可视区域渲染的总单元格数更小,更利于性能提升,而不是带来性能负担。
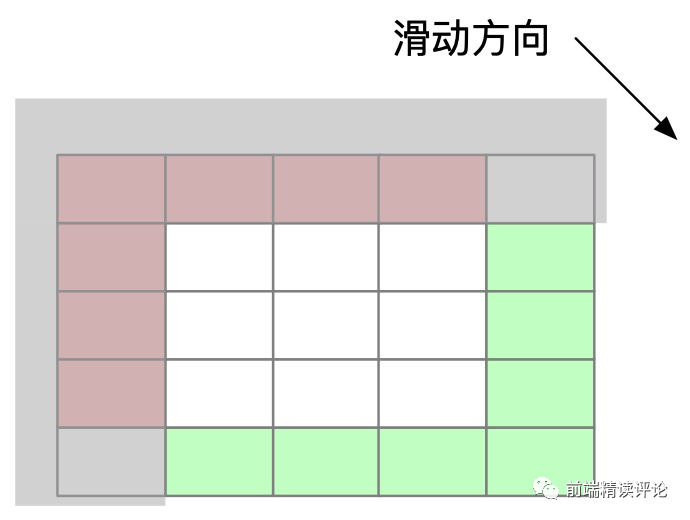
如果你采用 React 框架来实现,只要将每个格子的 key 设置为唯一的即可,比如当前行列号。
模拟滚动而非原生滚动
一般来说,轴因为逻辑特殊,其渲染逻辑和单元格会分开维护,因此我们将表格分为三个区域:横轴、纵轴、单元格。
显然,常识是横轴只能纵向滚动,纵轴只能横向滚动,单元格可以横纵向滚动,那么横向和纵向滚动条就只能出现在单元格区域:
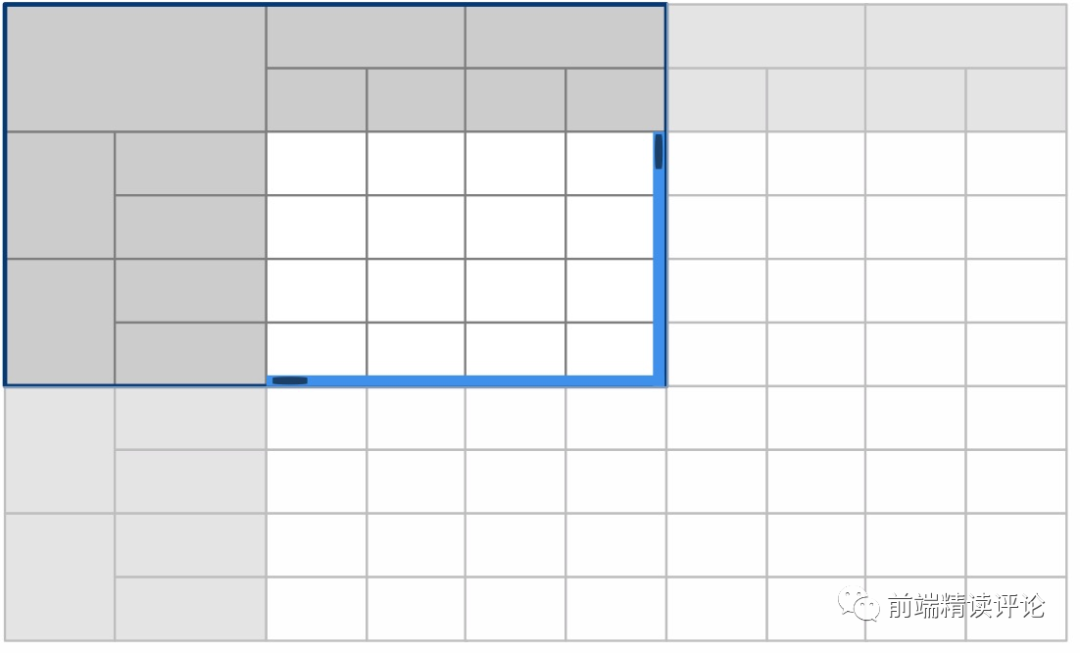
- 单元格使用原生滚动,横纵轴只能在单元格区域监听滚动后,通过
.scroll模拟滚动,这必然会导致单元格与轴滚动有一定错位,即轴的滚动有几毫秒的滞后感。 - 鼠标放在轴上时无法滚动,因为只有单元格是
overflow: auto的,而轴区域overflow: hidden无法触发滚动。 - 快速滚动出现白屏,即便留了 Buffer 区域,在快速滚动时也无能为力,这是因为渲染速度跟不上滚动导致的。
经过一番思考,我们只要将方案稍作调整,就能同时解决上面三个问题:即不要使用原生的滚动条,而是使用 .scroll 代替滚动,用 mousewheel 监听滚动的触发:
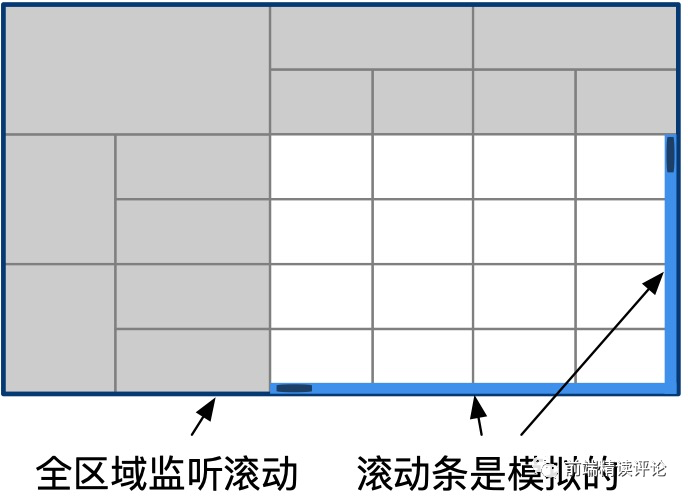
- 轴、单元格区域都使用
.scroll触发滚动,使得轴和单元格不会出现错位,因为轴和单元格都是用.scroll触发的滚动。 - 任何位置都能监听滚动,使得轴上也能滚动了,我们不再依赖
overflow属性。 - 快速滚动时惊喜的发现不会白屏了,原因是用
js控制触发的滚动发生在渲染完成之后,所以浏览器会在滚动发生前现完成渲染,这相当有趣。
模拟滚动时,实际上整个表格都是 overflow: hidden 的,浏览器就不会给出自带滚动条了,我们需要用 DIV 做出虚拟滚动条代替,这个相对容易。
零 buffer 区域
当我们采用模拟滚动方案时,相当于采用了在滚动时 “高频渲染” 的方案,因此不需要使用截留,更不要使用 Buffer 区域,因为更大的 Buffer 区域意味着更大的渲染开销。
当我们把 Buffer 区域移除时,发现整个屏幕内渲染单元格在 1000 个以内时,现代浏览器甚至配合 Windows 都能快速完成滚动前刷新,并不会影响滚动的流畅性。
当然,滚动过快依然不是一件好事,既然滚动是由我们控制的,可以稍许控制下滚动速度,控制在每次触发 mousewheel 位移不超过 200 左右最佳。
预计算
像单元格合并、行列隐藏、单元格格式化等计算逻辑,最好在滚动前提前算掉,否则在快速滚动时实时计算必然会带来额外的计算成本损耗。
但是这种预计算也有弊端,当单元格数量超过 10w 时,计算耗时一般会超过 1 秒,单元格数量超过 100w 时,计算耗时一般会超过 10 秒,用预计算的牺牲换来滚动的流畅,还是有些遗憾,我们可以再思考以下,能否降低预计算的损耗?
局部预计算
局部预计算就是一种解决方案,即便单元格数量有一千万个,但我们如果仅计算前 1w 个单元格呢?那无论数据量有多大,都不会出现丝毫卡顿。
但局部预计算有着明显缺点,即表格渲染过程中,局部计算结果并不总等价于全局计算结果,典型的有列宽、行高、跨行跨列的计算字段。
我们需要针对性解决,对于单元格宽高计算,必须采用局部计算,因为全量计算的损耗非常大。但局部计算肯定是不准确的,如下图所示:
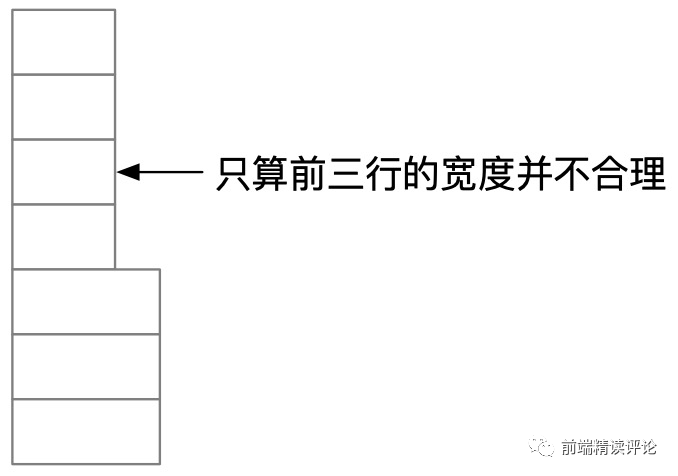
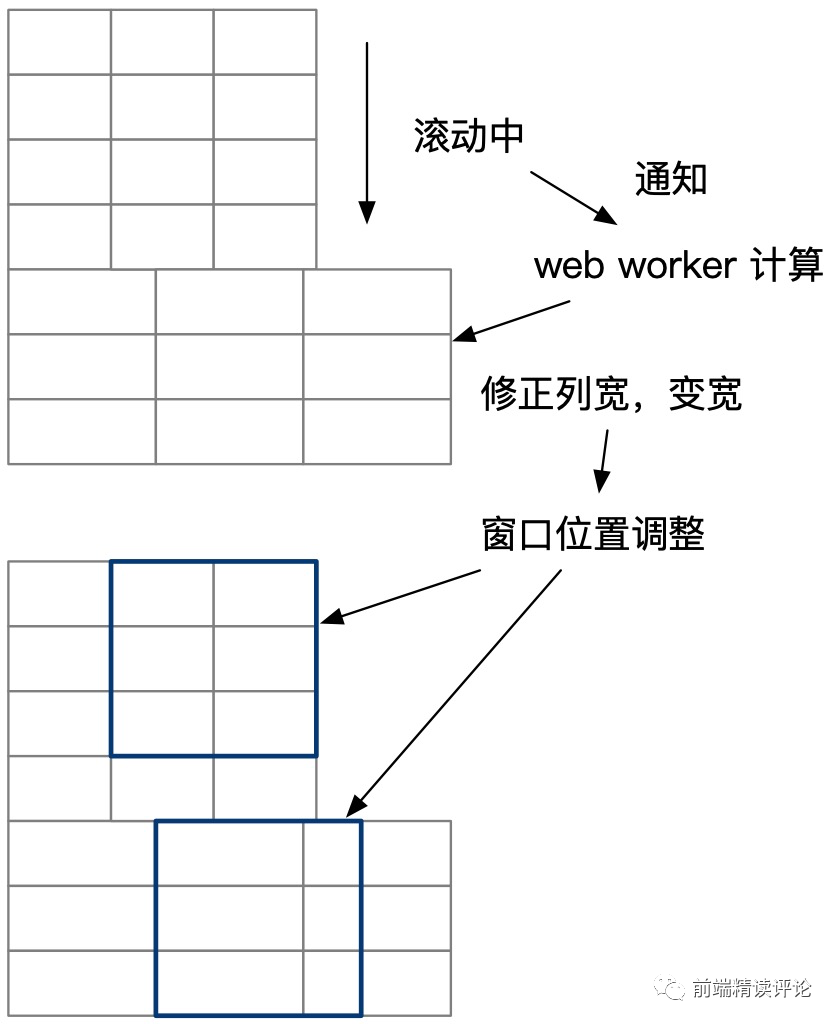
- 在快速滚动的时候,向 web worker 发送预计要滚动到的位置,增量计算这些位置文字宽度,并实时修正列总宽。(因为列总宽算完只要存储最大值,所以已计算的数量级会被压缩为 O(1))。
- 宽度计算完毕后,快速刷新当前屏幕单元格宽度,但在宽度校准的同时,维持可视区域内左对齐不变,如下图所示:
计算字段也是同理,可以在滚动时按片预计算,但要注意仅能在计算涉及局部单元格的情况下进行,如果这个计算是全局性质的,比如排名,那么局部排序的排名肯定是错误的,我们必须进行全量计算。
好在,即便是全量计算,我们也只需要考虑一部分数据,假设行列数量都是 n,可以将计算复杂度由 O(n²) 降低为 O(n):

在 10w 行 * 10w 列的情况下,等待时间是 1+1 = 2s,用户会感受到明显卡顿,但总单元格数量可是惊人的 100 亿,光数据可能就几 TB 了,不可能出现这种规模的聚合数据。
Map Reduce
前端计算还可以采用多个 web worker 加速,总之不要让用户电脑的 CPU 闲置。我们可以通过 window.navigator.hardwareConcurrency 获取硬件并行能支持的最大 web worker 数量,我们就实例化等量的 web worker 并行计算。
拿刚才排名的例子来说,同样 1000w 单元格数量,如果只有一列呢?那行数就是扎扎实实的 1000w,这种情况下,即便 O(n) 复杂度计算耗时也可能突破 60s,此时我们就可以分段计算。我的电脑 hardwareConcurrency 值为 8,那么就实例化 8 个 web worker,分别并行计算第 0 ~ 125w, 125w ~ 250w ..., 875w ~ 1000w 段的数据分别进行排序,最后得到 8 段有序序列,在主 worker 线程中进行合并。
我们可以采用分治合并,即针对依次收到的排序结果 x1, x2, x3, x4...,将收到的结果两两合并成 x12, x34, ...,再次合并为 x1234 直到合并为一个数组为止。
当然,Map Reduce 并不能解决所有问题,假设 1000w 数据计算耗时 60s,我们分为 8 段并行,每一段平均耗时 7.5s,那么第一轮排序总耗时为 7.5s。分治合并时间复杂度为 O(kn logk),其中 k 是分段数,这里是 8 段,logk 约等于 3,每段长度 125w 是 n,那么一个 125w 数量级的二分排序耗时大概是 4.5s,时间复杂度是 O(n logn),所以等价为 logn = 4.5s, k x logk 等于几?这里由于 k 远小于 n,所以时间消耗会远小于 4.5s,加起来耗时不会超过 10s。
总结
如果你想打造高性能表格,DIV 性能足够了,只要注意实现的时候稍加技巧即可。你可以用 DIV 实现一个兼顾性能、拓展性的表格,是时候重新相信 DOM 了!
笔者建议读完本文的你,按照这样的思路做一个小 Demo,同时思考,这样的表格有哪些通用功能可以抽象?如何设计 API 才能成为各类业务表格的基座?如何设计功能才能满足业务层表格繁多的拓展诉求?