Fail at Scale 读后感
Fail at Scale, Reliability in the face of rapid change 是 Facebook 2015 年发布的一篇论文,分享如何处理故障,以及如何构建稳定性的。现在看论文里少了些东西,偏向 web 社交场景,但是整体依然有参考意义
Why Do Failures Happen?
尽管每个故障的原因都不一样,但是抽象来看,故障类型是可以归纳总结的
1.单机故障
磁盘是有寿命的,一台物理机发生故障的概率比较小,但是 IDC 上万台之后,基本上每天都会有磁盘损坏。这就导致要求服务能够容忍磁盘故障,要么忽略写磁盘错误,要么磁盘做好 RAID.
我司大规模使用 AWS 服务,都是 EBS, 屏蔽了底层的细节,可以默认磁盘是永远不出故障的。除了使用磁盘错误检测工具外,听说某云厂商用机器学习,来预测磁盘何时损坏,提前处理。即使任何变更都没有,物理机器也会过保的,机器性能也会在某个时间点后降低
另外一个单机错误,就是服务自身的异常。比如某个 bug 触发了 deadlock 逻辑
2.负载变化
服务自身没有部题,但是遇到了某些重大的活动。论文里举奥巴马赢得大选,超级碗,世界杯的例子,突发事件导致极高的发贴数量
这点特别像我们打车,比如某个地区做了促销,打车或是点外卖的人特别多。造成了局部大卖家问题,需要我们提前做好扩容。当公司大了,通知机制也是一个问题
3.人为错误
论文里提到,工作日故障或错误数量,远远高于周末,尤其是圣诞节前后,基本没有发生问题
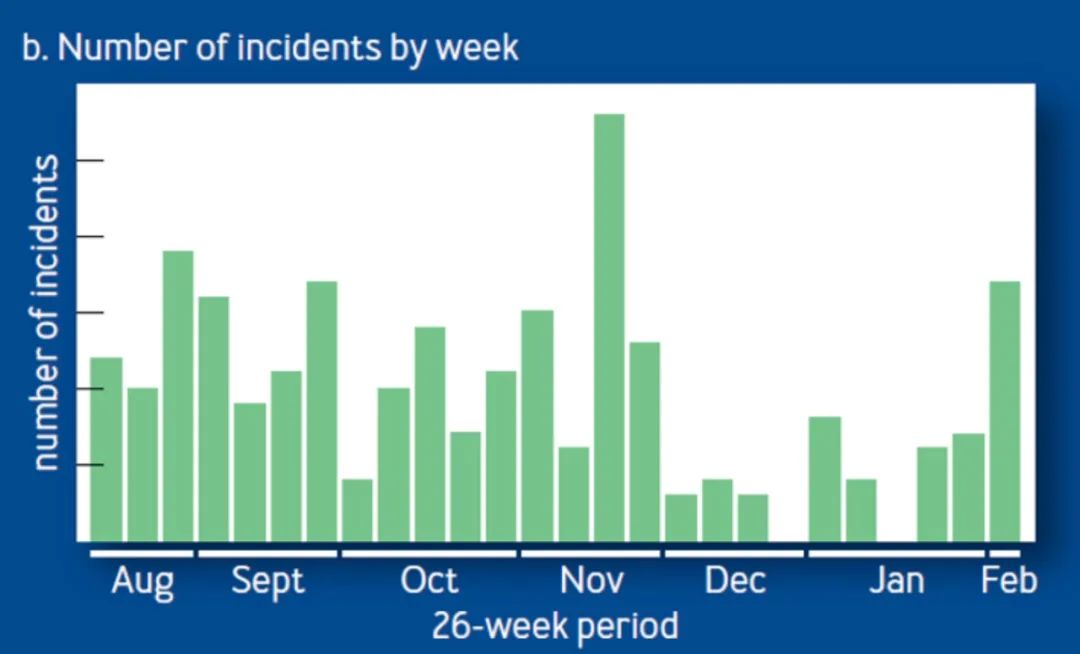
个人感观也一样,同一到周五只要上线就有报警,周末平平安安^^
引起故障的三类大问题
虽然故障原因千奇变怪,但是本质分为三大类,或多或少都是因为这些放大了失败,引起级联故障
1.配置变更
Configuration Systems 用于做到快速配置变更,Facebook 是全球级别的,非常强大。想信每个公司都有自己的配置平台,快速部署,也意味着失败会快速放大,引起故障,那么 Facebook 用如下几种方法来避免
- Make everybody use a common configuration system: 配置变更只允许通用的工具
- Statically validate configuration changes: 静态检查配置,比如有的公司用 json, 字段错了只有运行期才知道。Facebook 使用 thrift IDL, 我司使用 PB, 语言无所谓,重点是要有 schema 约束
- Run a canary: 灰度发布,个人理解除了一台灰度,正式上线也要分组,否则很多 case 是看不出来的
- Hold on to good configurations: 保留正确的配置 (可以随时使用,回滚)
- Make it easy to revert: 快速回退,有时只有回滚时才发现,工具不好使,平时也要多练
2.对核心服务的强依赖
很多时候,我们会默认某些服务是 100% 可靠的,比如服务发现,比如配置系统,比如依赖的 DB 等等,但很多时候问题也因此产生
- Cache data from core services: 对核心服务的数据进行缓存,这点对于 facebook 社交类的场合是非常合适的,但是交易型的场景需要 think carefully
- Provide hardened APIs to use core services: 提供加强版的 API 访问核心服务,可以提供很好的故障处理。比如调用 core services 使用 SDK
- Run fire drills: 消防演练,需要经常做故障演练
3.延迟增加资源耗尽
这块比较好理解,Facebook 服务采用线程池 work 模式,如果某些请求慢了,哪怕只有 1% 慢了,也会无法处理正常请求,导致资源耗尽,引起级联故障
那我们 Go 服务就不会了嘛?少部份慢了没有问题,但是如果大规模请求都慢了,会引起 Go GC 压力增加,最终导致服务不可用。Facebook 采了两种方法解决
- Controlled Delay: 算法根据不同负载处理排队的请求,解决入队速率与处理请求速率不匹配问题
onNewRequest(req, queue):
if (queue.lastEmptyTime() < (now - N seconds)) {
timeout = M ms
} else {
timeout = N seconds;
}
queue.enqueue(req, timeout)如果过去 N 秒内队列不为空,说明处理不过来了,那么超时时间设短一些 M 毫秒,否则超时时间可以设长一些。Facebook 线上 M 设置为 5ms, N 是 100ms
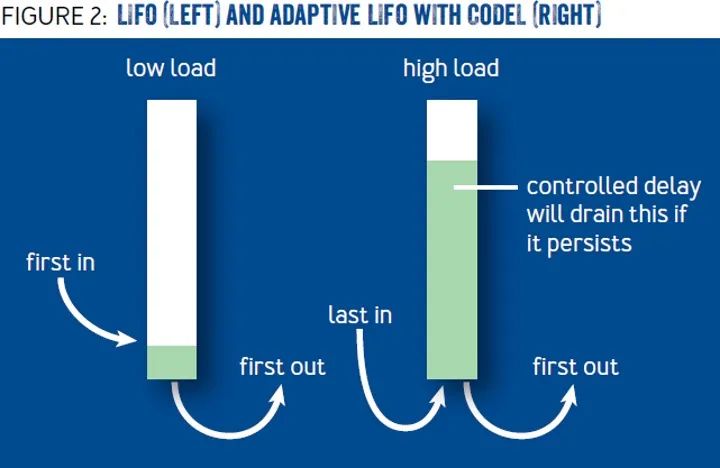
- Adaptive LIFO: 正常队列是 First In First Out 的,但是当业务请理慢,请求堆积时,超时的请求,用户可能己经重试了,还不如处理后入队的请求
- Concurreny Control: 并发控制, 论文描述的其实就是 circuit breaker, 如果 inflight 请求过多,或是错误过多,会触发 Client 熔断。文章通篇没提 cb, 但是意思一样。上面提到的是 Server 做法,而 CB 是 Client 端的设置
构建诊断故障的工具
这块 Facebook 打造了 Cubism 高密度仪表盘,帮助快速诊断故障。这点非常经验性质的,因公司而异
另外最重要的是能看到最近做了哪些 changes, 快速将故障与变更关联起来
Learning from Failure
失败发生后,我们的事件审查过程有助于我们从这些事件中学习
事件审查过程的目的不是为了指责 目的是为了了解发生了什么,补救使事件发生的情况,并建立安全机制以减少未来事件的影响
Facebook 开发了一种名为 DERP(指检测、升级、补救和预防)的方法,以帮助进行富有成效的事件审查。
- Detection 检测,如何检测问题--警报、仪表板、用户报告?
- Escalation 升级,正确的人是否迅速介入?这些人是否可以通过警报而不是手动来处理?
- Remediation 补救,采取了哪些步骤来解决这个问题?这些步骤是否可以自动化?
- Prevention 预防,哪些改进可以消除这种类型的故障再次发生的风险?你如何能优雅地失败,或更快地失败,以减少这次故障的影响?
DERP帮助分析手头事件的每个步骤。在这种分析的帮助下,即使你不能防止这种类型的事件再次发生,你至少能够在下一次更快恢复
小结
前几天写篇文章[你适合做救火队长嘛?] ,感兴趣可以看看,稳定性建设知易行难,需要持续投入,所有团队合作才能完成
- 大部分故障都来自 Human error, 包括手工误操作,频繁上线,需要做好 canary 灰度发布,通知相关上下游密切关注 metrics
- 微服务增加了故障排查的难度,尤其是云上环境,需要构建可观测 Observability, 方便 debug, 这是一个系统工程
- DERP 方法论:Detection 如何检测故障, Escalation 故障如何上报,是否找到了正确的人, Remediation 修复故障的步骤能否自动化, Prevention 如何避免此类故障
以上三点的重要性不言而喻,平时做好这些工作,才能避免大规模故障。即使面对问题时,也有方法可循,而不是出问题时指责下游:调你们服务的代码一直没有变动,为什么会出问题?