SQL零基础入门必知必会!
前言
SQL语言有40多年的历史,从它被应用至今几乎无处不在。我们消费的每一笔支付记录,收集的每一条用户信息,发出去的每一条消息,都会使用数据库或与其相关的产品来存储,而操纵数据库的语言正是 SQL !
SQL 介绍
什么是 SQL
SQL 是用于访问和处理数据库的标准的计算机语言。
- SQL 指结构化查询语言
- SQL 使我们有能力访问数据库
- SQL 是一种 ANSI 的标准计算机语言

但是由于各种各样的数据库出现,导致很多不同版本的 SQL 语言。
为了与 ANSI 标准相兼容,它们必须以相似的方式共同地来支持一些主要的关键词(比如 SELECT、UPDATE、DELETE、INSERT、WHERE 等等),这些就是我们要学习的SQL基础。
SQL 的类型
可以把 SQL 分为两个部分:数据操作语言 (DML) 和 数据定义语言 (DDL)。
- 数据查询语言(DQL: Data Query Language)
- 数据操纵语言(DML:Data Manipulation Language)
学习 SQL 的作用
SQL 是一门 ANSI 的标准计算机语言,用来访问和操作数据库系统。SQL 语句用于取回和更新数据库中的数据。
- SQL 面向数据库执行查询
- SQL 可从数据库取回数据
- SQL 可在数据库中插入新的记录
- SQL 可更新数据库中的数据
- SQL 可从数据库删除记录
- SQL 可创建新数据库
- SQL 可在数据库中创建新表
- SQL 可在数据库中创建存储过程
- SQL 可在数据库中创建视图
- SQL 可以设置表、存储过程和视图的权限
数据库是什么
「顾名思义,你可以理解为数据库是用来存放数据的一个容器。」
打个比方,每个人家里都会有冰箱,冰箱是用来干什么的?冰箱是用来存放食物的地方。
例如你每天使用余额宝查看自己的账户收益,就是从数据库读取数据后给你的。
「最常见的数据库类型是关系型数据库管理系统(RDBMS):」
RDBMS 是 SQL 的基础,同样也是所有现代数据库系统的基础,比如:
- MS SQL Server
- IBM DB2
- Oracle
- MySQL
- Microsoft Access
RDBMS 中的数据存储在被称为表(tables)的数据库对象中。表 是相关的数据项的集合,它由列和行组成。
由于本文主要讲解 SQL 基础,因此对数据库不做过多解释,只需要大概了解即可。
「咱们直接开始学习SQL!」
SQL 基础语言学习
在了解 SQL 基础语句使用之前,我们先讲一下 表 是什么?
一个数据库通常包含一个或多个表。每个表由一个名字标识(例如“客户”或者“订单”)。表包含带有数据的记录(行)。
「下面的例子是一个名为 "Persons" 的表:」
| Id | LastName | FirstName | Address | City |
|---|---|---|---|---|
| 1 | Adams | John | Oxford Street | London |
| 2 | Bush | George | Fifth Avenue | New York |
| 3 | Carter | Thomas | Changan Street | Beijing |
上面的表包含三条记录(每一条对应一个人)和五个列(Id、姓、名、地址和城市)。
「有表才能查询,那么如何创建这样一个表?」
CREATE TABLE – 创建表
CREATE TABLE 语句用于创建数据库中的表。
「语法:」
CREATE TABLE 表名称
(
列名称1 数据类型,
列名称2 数据类型,
列名称3 数据类型,
....
);数据类型(data_type)规定了列可容纳何种数据类型。下面的表格包含了SQL中最常用的数据类型:
| 数据类型 | 描述 |
|---|---|
| integer(size),int(size),smallint(size),tinyint(size) | 仅容纳整数、在括号内规定数字的最大位数 |
| decimal(size,d),numeric(size,d) | 容纳带有小数的数字、"size" 规定数字的最大位数、"d" 规定小数点右侧的最大位数 |
| char(size) | 容纳固定长度的字符串(可容纳字母、数字以及特殊字符)、在括号中规定字符串的长度 |
| varchar(size) | 容纳可变长度的字符串(可容纳字母、数字以及特殊的字符)、在括号中规定字符串的最大长度 |
| date(yyyymmdd) | 容纳日期 |
「实例:」
本例演示如何创建名为 "Persons" 的表。
该表包含 5 个列,列名分别是:"Id_P"、"LastName"、"FirstName"、"Address" 以及 "City":
CREATE TABLE Persons
(
Id_P int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);Id_P 列的数据类型是 int,包含整数。其余 4 列的数据类型是 varchar,最大长度为 255 个字符。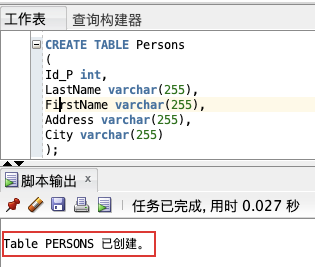


INSERT – 插入数据
INSERT INTO 语句用于向表格中插入新的行。
「语法:」
INSERT INTO 表名称 VALUES (值1, 值2,....);
我们也可以指定所要插入数据的列:
INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....);
「实例:」
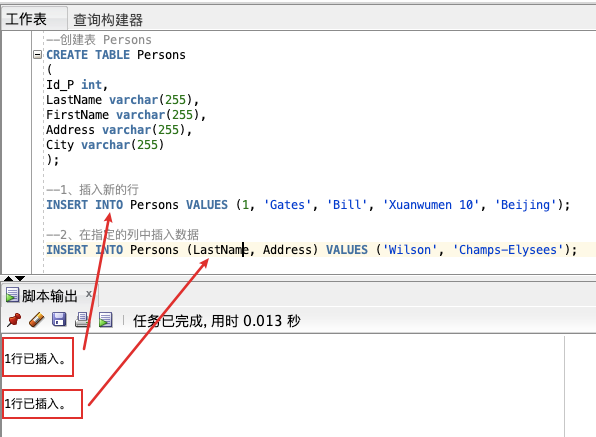
本例演示 "Persons" 表插入记录的两种方式:
「1、插入新的行」
INSERT INTO Persons VALUES (1, 'Gates', 'Bill', 'Xuanwumen 10', 'Beijing');
「2、在指定的列中插入数据」
INSERT INTO Persons (LastName, Address) VALUES ('Wilson', 'Champs-Elysees');

SELECT 语句进行查询出来的,别急马上讲!
SELECT – 查询数据
SELECT 语句用于从表中选取数据,结果被存储在一个结果表中(称为结果集)。
「语法:」
SELECT * FROM 表名称;
我们也可以指定所要查询数据的列:
SELECT 列名称 FROM 表名称;
「 注意:」 SQL 语句对大小写不敏感,SELECT 等效于 select。
「实例:」
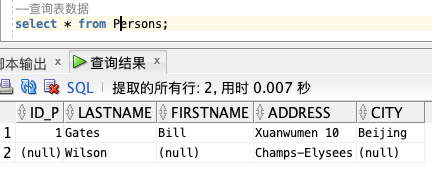
「SQL SELECT * 实例:」
SELECT * FROM Persons;
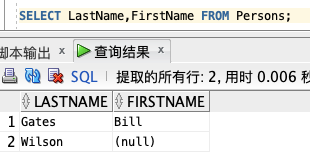
如需获取名为 "LastName" 和 "FirstName" 的列的内容(从名为 "Persons" 的数据库表),请使用类似这样的 SELECT 语句:
SELECT LastName,FirstName FROM Persons;
DISTINCT – 去除重复值
如果一张表中有多行重复数据,如何去重显示呢?可以了解下 DISTINCT 。
「语法:」
SELECT DISTINCT 列名称 FROM 表名称;
「实例:」
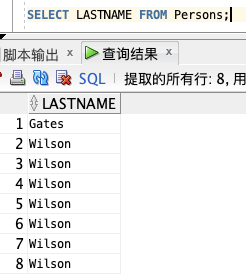
如果要从 "LASTNAME" 列中选取所有的值,我们需要使用 SELECT 语句:
SELECT LASTNAME FROM Persons;
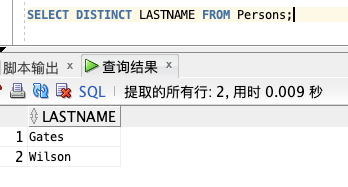
如需从 "LASTNAME" 列中仅选取唯一不同的值,我们需要使用 SELECT DISTINCT 语句:
SELECT DISTINCT LASTNAME FROM Persons;
WHERE – 条件过滤
如果需要从表中选取指定的数据,可将 WHERE 子句添加到 SELECT 语句。
「语法:」
SELECT 列名称 FROM 表名称 WHERE 列 运算符 值;
下面的运算符可在 WHERE 子句中使用:
| 操作符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
「实例:」
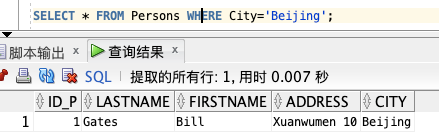
如果只希望选取居住在城市 "Beijing" 中的人,我们需要向 SELECT 语句添加 WHERE 子句:
SELECT * FROM Persons WHERE City='Beijing';
AND & OR – 运算符
AND 和 OR 可在 WHERE 子语句中把两个或多个条件结合起来。
- 如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。
- 如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
「语法:」
「AND 运算符实例:」
SELECT * FROM 表名称 WHERE 列 运算符 值 AND 列 运算符 值;
「OR 运算符实例:」
SELECT * FROM 表名称 WHERE 列 运算符 值 OR 列 运算符 值;
「实例:」
由于 Persons 表数据太少,因此增加几条记录:
INSERT INTO Persons VALUES (2, 'Adams', 'John', 'Oxford Street', 'London');
INSERT INTO Persons VALUES (3, 'Bush', 'George', 'Fifth Avenue', 'New York');
INSERT INTO Persons VALUES (4, 'Carter', 'Thomas', 'Changan Street', 'Beijing');
INSERT INTO Persons VALUES (5, 'Carter', 'William', 'Xuanwumen 10', 'Beijing');
SELECT * FROM Persons;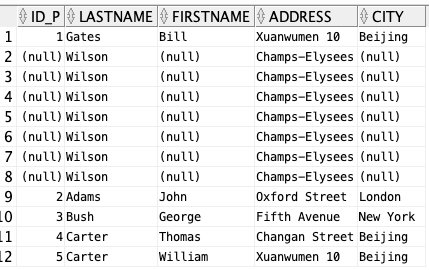
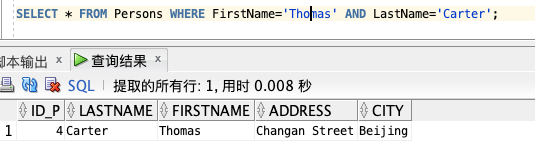
使用 AND 来显示所有姓为 "Carter" 并且名为 "Thomas" 的人:
SELECT * FROM Persons WHERE FirstName='Thomas' AND LastName='Carter';
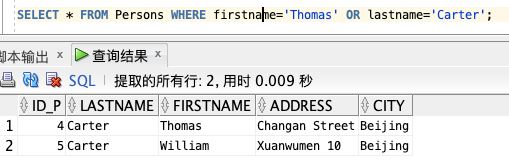
使用 OR 来显示所有姓为 "Carter" 或者名为 "Thomas" 的人:
SELECT * FROM Persons WHERE firstname='Thomas' OR lastname='Carter';
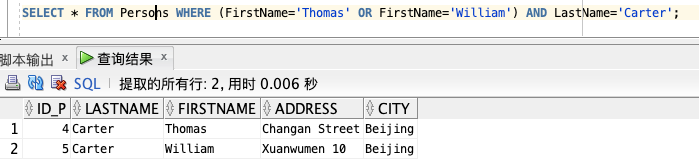
我们也可以把 AND 和 OR 结合起来(使用圆括号来组成复杂的表达式):
SELECT * FROM Persons WHERE (FirstName='Thomas' OR FirstName='William') AND LastName='Carter';
ORDER BY – 排序
ORDER BY 语句用于根据指定的列对结果集进行排序,默认按照升序对记录进行排序,如果您希望按照降序对记录进行排序,可以使用 DESC 关键字。
「语法:」
SELECT * FROM 表名称 ORDER BY 列1,列2 DESC;
默认排序为 ASC 升序,DESC 代表降序。
「实例:」
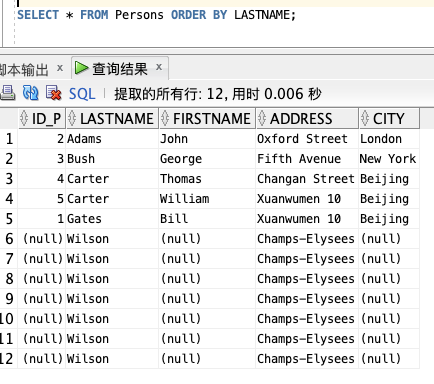
以字母顺序显示 LASTNAME 名称:
SELECT * FROM Persons ORDER BY LASTNAME;
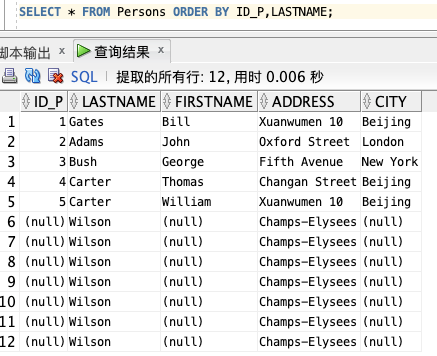
以数字顺序显示ID_P,并以字母顺序显示 LASTNAME 名称:
SELECT * FROM Persons ORDER BY ID_P,LASTNAME;
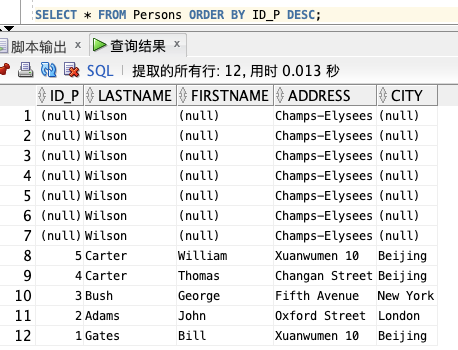
ID_P:
SELECT * FROM Persons ORDER BY ID_P DESC;
UPDATE – 更新数据
Update 语句用于修改表中的数据。
「语法:」
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值;
「实例:」
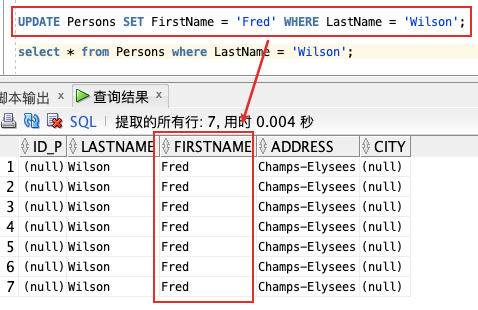
「更新某一行中的一个列:」
目前 Persons 表有很多字段为 null 的数据,可以通过 UPDATE 为 LASTNAME 是 "Wilson" 的人添加FIRSTNAME:
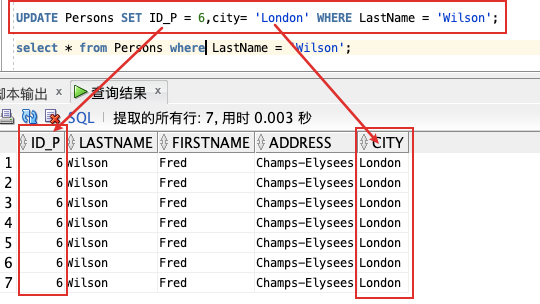
UPDATE Persons SET FirstName = 'Fred' WHERE LastName = 'Wilson';
UPDATE Persons SET ID_P = 6,city= 'London' WHERE LastName = 'Wilson';
DELETE – 删除数据
DELETE 语句用于删除表中的行。
「语法:」
DELETE FROM 表名称 WHERE 列名称 = 值;
「实例:」
「删除某行:」
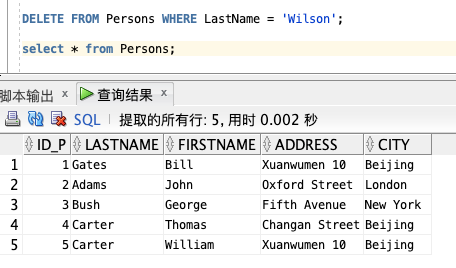
删除 Persons 表中 LastName 为 "Fred Wilson" 的行:
DELETE FROM Persons WHERE LastName = 'Wilson';
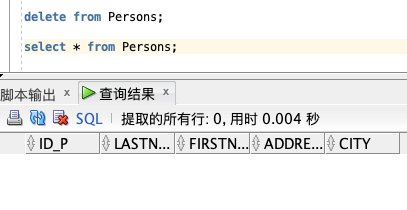
可以在不删除表的情况下删除所有的行。这意味着表的结构、属性和索引都是完整的:
DELETE FROM table_name;
TRUNCATE TABLE – 清除表数据
如果我们仅仅需要除去表内的数据,但并不删除表本身,那么我们该如何做呢?
可以使用 TRUNCATE TABLE 命令(仅仅删除表格中的数据):
「语法:」
TRUNCATE TABLE 表名称;
「实例:」
本例演示如何删除名为 "Persons" 的表。
TRUNCATE TABLE persons;
DROP TABLE – 删除表
DROP TABLE 语句用于删除表(表的结构、属性以及索引也会被删除)。
「语法:」
DROP TABLE 表名称;
「实例:」
本例演示如何删除名为 "Persons" 的表。
drop table persons;
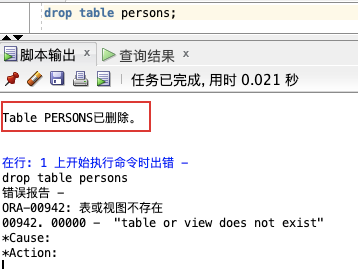
persons,第二次执行删除时,报错找不到表 persons,说明表已经被删除了。
SQL 高级言语学习
LIKE – 查找类似值
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
「语法:」
SELECT 列名/(*) FROM 表名称 WHERE 列名称 LIKE 值;
「实例:」
Persons 表插入数据:
INSERT INTO Persons VALUES (1, 'Gates', 'Bill', 'Xuanwumen 10', 'Beijing');
INSERT INTO Persons VALUES (2, 'Adams', 'John', 'Oxford Street', 'London');
INSERT INTO Persons VALUES (3, 'Bush', 'George', 'Fifth Avenue', 'New York');
INSERT INTO Persons VALUES (4, 'Carter', 'Thomas', 'Changan Street', 'Beijing');
INSERT INTO Persons VALUES (5, 'Carter', 'William', 'Xuanwumen 10', 'Beijing');
select * from persons;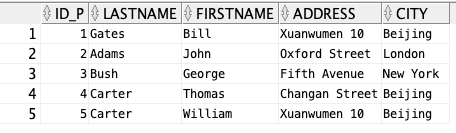
SELECT * FROM Persons WHERE City LIKE 'N%';
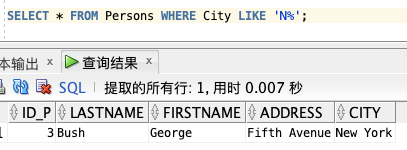
SELECT * FROM Persons WHERE City LIKE '%g';
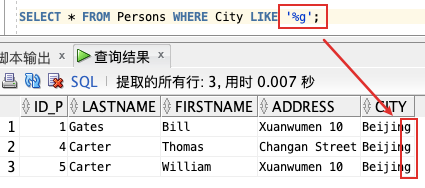
SELECT * FROM Persons WHERE City LIKE '%on%';
SELECT * FROM Persons WHERE City NOT LIKE '%on%';
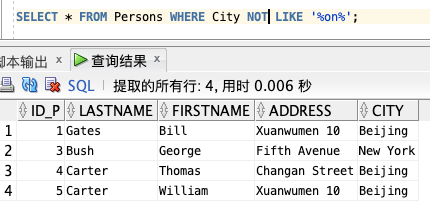
IN – 锁定多个值
IN 操作符允许我们在 WHERE 子句中规定多个值。
「语法:」
SELECT 列名/(*) FROM 表名称 WHERE 列名称 IN (值1,值2,值3);
「实例:」
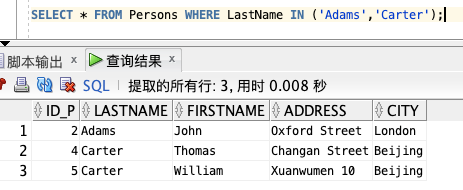
现在,我们希望从 Persons 表中选取姓氏为 Adams 和 Carter 的人:
SELECT * FROM Persons WHERE LastName IN ('Adams','Carter');
⛵️ BETWEEN – 选取区间数据
操作符 BETWEEN ... AND 会选取介于两个值之间的数据范围。这些值可以是数值、文本或者日期。
「语法:」
SELECT 列名/(*) FROM 表名称 WHERE 列名称 BETWEEN 值1 AND 值2;
「实例:」
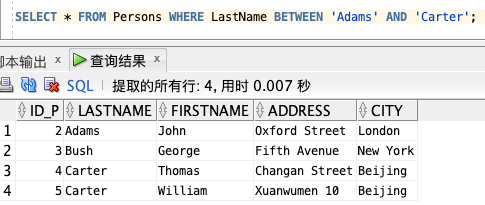
1、查询以字母顺序显示介于 "Adams"(包括)和 "Carter"(不包括)之间的人:
SELECT * FROM Persons WHERE LastName BETWEEN 'Adams' AND 'Carter';
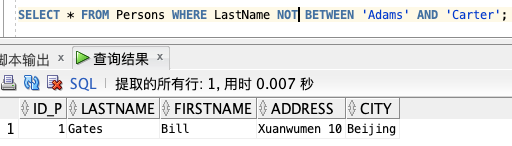
SELECT * FROM Persons WHERE LastName NOT BETWEEN 'Adams' AND 'Carter';
❝某些数据库会列出介于 "Adams" 和 "Carter" 之间的人,但不包括 "Adams" 和 "Carter" ;某些数据库会列出介于 "Adams" 和 "Carter" 之间并包括 "Adams" 和 "Carter" 的人;而另一些数据库会列出介于 "Adams" 和 "Carter" 之间的人,包括 "Adams" ,但不包括 "Carter" 。
❞
「所以,请检查你的数据库是如何处理 BETWEEN....AND 操作符的!」
AS – 别名
通过使用 SQL,可以为列名称和表名称指定别名(Alias),别名使查询程序更易阅读和书写。
「语法:」
「表别名:」
SELECT 列名称/(*) FROM 表名称 AS 别名;
「列别名:」
SELECT 列名称 as 别名 FROM 表名称;
「实例:」
「使用表名称别名:」
SELECT p.LastName, p.FirstName
FROM Persons p
WHERE p.LastName='Adams' AND p.FirstName='John';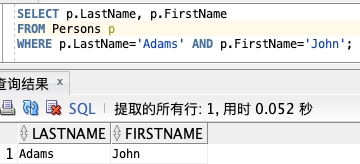
SELECT LastName "Family", FirstName "Name" FROM Persons;
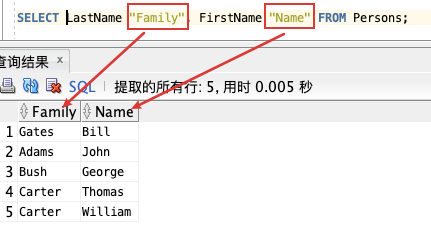
AS 可以省略,但是列别名需要加上 " "。
JOIN – 多表关联
JOIN 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。
有时为了得到完整的结果,我们需要从两个或更多的表中获取结果。我们就需要执行 join。
数据库中的表可通过键将彼此联系起来。主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的。在表中,每个主键的值都是唯一的。这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。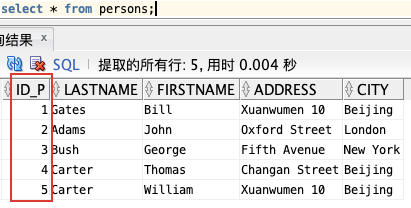
「❤️ 为了下面实验的继续,我们需要再创建一个表:Orders。」
create table orders (id_o number,orderno number,id_p number);
insert into orders values(1,11111,1);
insert into orders values(2,22222,2);
insert into orders values(3,33333,3);
insert into orders values(4,44444,4);
insert into orders values(6,66666,6);
select * from orders;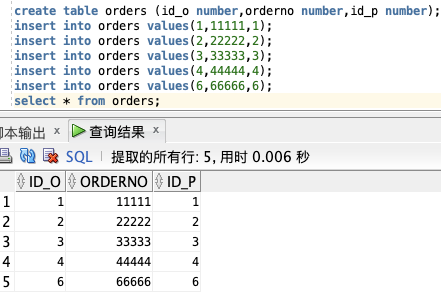
select * from persons p,orders o where p.id_p=o.id_p;
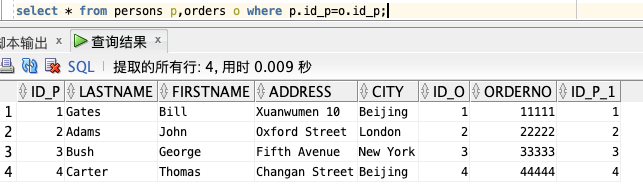
「语法:」
select 列名
from 表A
INNER|LEFT|RIGHT|FULL JOIN 表B
ON 表A主键列 = 表B外键列;「不同的 SQL JOIN:」
下面列出了您可以使用的 JOIN 类型,以及它们之间的差异。
- JOIN: 如果表中有至少一个匹配,则返回行
- INNER JOIN: 内部连接,返回两表中匹配的行
- LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN: 只要其中一个表中存在匹配,就返回行
「实例:」
如果我们希望列出所有人的定购,可以使用下面的 SELECT 语句:
SELECT p.LastName, p.FirstName, o.OrderNo
FROM Persons p
INNER JOIN Orders o
ON p.Id_P = o.Id_P
ORDER BY p.LastName DESC;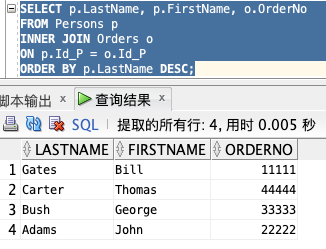
UNION – 合并结果集
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
「UNION 语法:」
SELECT 列名 FROM 表A
UNION
SELECT 列名 FROM 表B;「注意:」 UNION 操作符默认为选取不同的值。如果查询结果需要显示重复的值,请使用 UNION ALL。
「UNION ALL 语法:」
SELECT 列名 FROM 表A
UNION ALL
SELECT 列名 FROM 表B;另外,UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
为了实验所需,创建 Person_b 表:
CREATE TABLE Persons_b
(
Id_P int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);
INSERT INTO Persons_b VALUES (1, 'Bill', 'Gates', 'Xuanwumen 10', 'Londo');
INSERT INTO Persons_b VALUES (2, 'John', 'Adams', 'Oxford Street', 'nBeijing');
INSERT INTO Persons_b VALUES (3, 'George', 'Bush', 'Fifth Avenue', 'Beijing');
INSERT INTO Persons_b VALUES (4, 'Thomas', 'Carter', 'Changan Street', 'New York');
INSERT INTO Persons_b VALUES (5, 'William', 'Carter', 'Xuanwumen 10', 'Beijing');
select * from persons_b;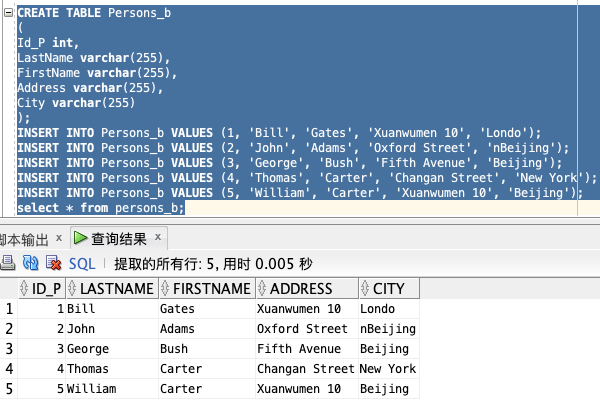
「使用 UNION 命令:」
列出 persons 和 persons_b 中不同的人:
select * from persons
UNION
select * from persons_b;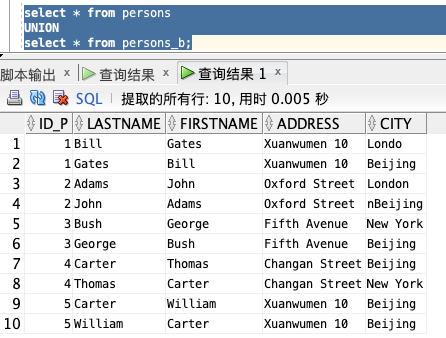
NOT NULL – 非空
NOT NULL 约束强制列不接受 NULL 值。
NOT NULL 约束强制字段始终包含值。这意味着,如果不向字段添加值,就无法插入新记录或者更新记录。
「语法:」
CREATE TABLE 表
(
列 int NOT NULL
);如上,创建一个表,设置列值不能为空。
「实例:」
create table lucifer (id number not null);
insert into lucifer values (NULL);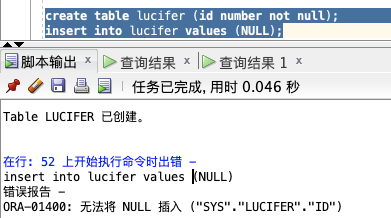
NULL 值,则会报错 ORA-01400 提示无法插入!
「⭐️ 拓展小知识:」NOT NULL 也可以用于查询条件:
select * from persons where FirstName is not null;
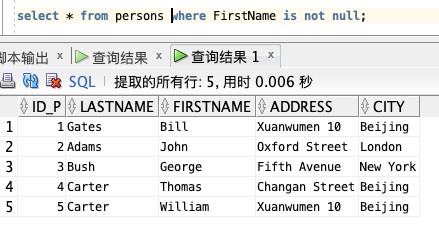
NULL 也可:
select * from persons where FirstName is null;
感兴趣的朋友,可以自己尝试一下!
VIEW – 视图
在 SQL 中,视图是基于 SQL 语句的结果集的可视化的表。
视图包含行和列,就像一个真实的表。视图中的字段就是来自一个或多个数据库中的真实的表中的字段。我们可以向视图添加 SQL 函数、WHERE 以及 JOIN 语句,我们也可以提交数据,就像这些来自于某个单一的表。
「语法:」
CREATE VIEW 视图名 AS
SELECT 列名
FROM 表名
WHERE 查询条件;「 注意:」 视图总是显示最近的数据。每当用户查询视图时,数据库引擎通过使用 SQL 语句来重建数据。
「实例:」
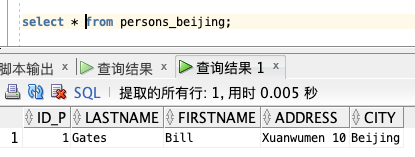
下面,我们将 Persons 表中住在 Beijing 的人筛选出来创建视图:
create view persons_beijing as
select * from persons where city='Beijing';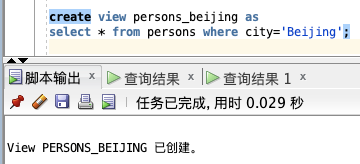
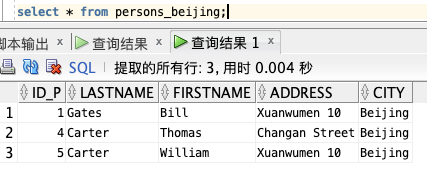
CREATE OR REPLACE VIEW 选项:
CREATE OR REPLACE VIEW 视图名 AS
SELECT 列名
FROM 表名
WHERE 查询条件;「实例:」
现在需要筛选出,LASTNAME 为 Gates 的记录:
create or replace view persons_beijing as
select * from persons where lastname='Gates';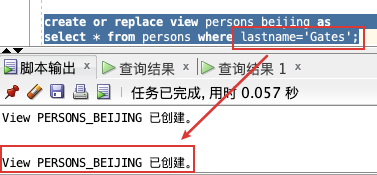
DROP 即可:
drop view persons_beijing;
SQL 常用函数学习
SQL 拥有很多可用于计数和计算的内建函数。
「函数的使用语法:」
SELECT function(列) FROM 表;
「❤️ 下面就来看看有哪些常用的函数!」
AVG – 平均值
AVG 函数返回数值列的平均值。NULL 值不包括在计算中。
「语法:」
SELECT AVG(列名) FROM 表名;
「实例:」
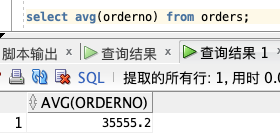
计算 "orderno" 字段的平均值。
select avg(orderno) from orders;
select * from orders where orderno < (select avg(orderno) from orders);

COUNT – 汇总行数
COUNT() 函数返回匹配指定条件的行数。
「语法:」
count() 中可以有不同的语法:
- COUNT(*) :返回表中的记录数。
- COUNT(DISTINCT 列名) :返回指定列的不同值的数目。
- COUNT(列名) :返回指定列的值的数目(NULL 不计入)。
SELECT COUNT(*) FROM 表名;
SELECT COUNT(DISTINCT 列名) FROM 表名;
SELECT COUNT(列名) FROM 表名;「实例:」
「COUNT(*) :」
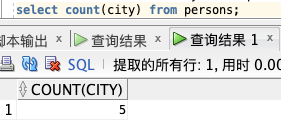
select count(*) from persons;
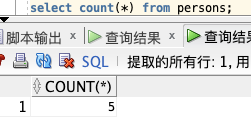
select count(distinct city) from persons;
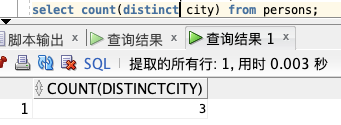
select count(city) from persons;
MAX – 最大值
MAX 函数返回一列中的最大值。NULL 值不包括在计算中。
「语法:」
SELECT MAX(列名) FROM 表名;
MIN 和 MAX 也可用于文本列,以获得按字母顺序排列的最高或最低值。
「实例:」
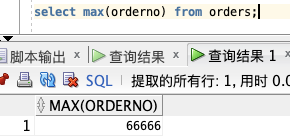
select max(orderno) from orders;
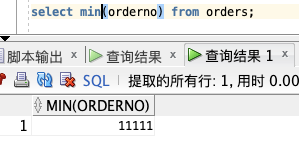
MIN – 最小值
MIN 函数返回一列中的最小值。NULL 值不包括在计算中。
「语法:」
SELECT MIN(列名) FROM 表名;
「实例:」
select min(orderno) from orders;
SUM – 求和
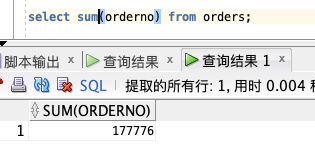
SUM 函数返回数值列的总数(总额)。
「语法:」
SELECT SUM(列名) FROM 表名;
「实例:」
select sum(orderno) from orders;
GROUP BY – 分组
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
「语法:」
SELECT 列名A, 统计函数(列名B)
FROM 表名
WHERE 查询条件
GROUP BY 列名A;「实例:」
获取 Persons 表中住在北京的总人数,根据 LASTNAME 分组:
select lastname,count(city) from persons
where city='Beijing'
group by lastname;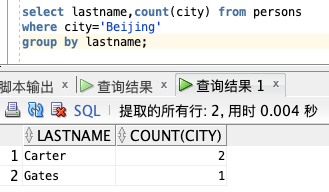
GROUP BY 则会报错: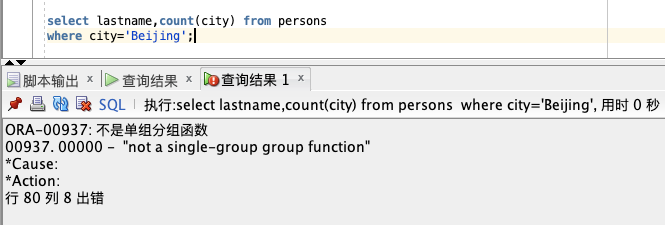
ORA-00937 不是单组分组函数的错误。
HAVING – 句尾连接
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。
「语法:」
SELECT 列名A, 统计函数(列名B)
FROM table_name
WHERE 查询条件
GROUP BY 列名A
HAVING 统计函数(列名B) 查询条件;「实例:」
获取 Persons 表中住在北京的总人数大于1的 LASTNAME,根据 LASTNAME 分组:
select lastname,count(city) from persons
where city='Beijing'
group by lastname
having count(city) > 1;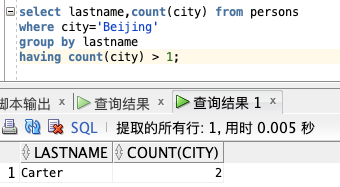
UCASE/UPPER – 大写
UCASE/UPPER 函数把字段的值转换为大写。
「语法:」
select upper(列名) from 表名;
「实例:」
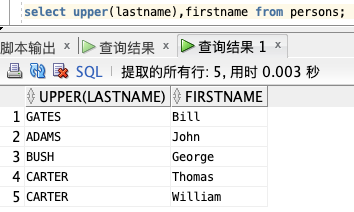
选取 "LastName" 和 "FirstName" 列的内容,然后把 "LastName" 列转换为大写:
select upper(lastname),firstname from persons;
LCASE/LOWER – 小写
LCASE/LOWER 函数把字段的值转换为小写。
「语法:」
select lower(列名) from 表名;
「实例:」
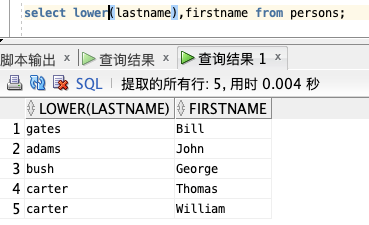
选取 "LastName" 和 "FirstName" 列的内容,然后把 "LastName" 列转换为小写:
select lower(lastname),firstname from persons;
LEN/LENGTH – 获取长度
LEN/LENGTH 函数返回文本字段中值的长度。
「语法:」
select length(列名) from 表名;
「实例:」
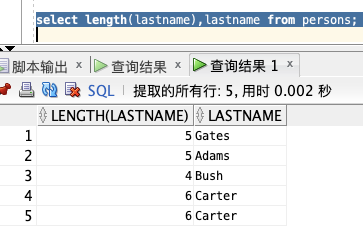
获取 LASTNAME 的值字符长度:
select length(lastname),lastname from persons;
ROUND – 数值取舍
ROUND 函数用于把数值字段舍入为指定的小数位数。
「语法:」
select round(列名,精度) from 表名;
「实例:」
保留2位:
select round(1.1314,2) from dual;
select round(1.1351,2) from dual;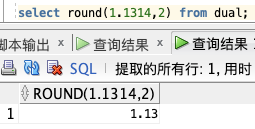
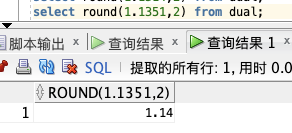
ROUND 取舍是 「四舍五入」 的!
取整:
select round(1.1351,0) from dual;
select round(1.56,0) from dual;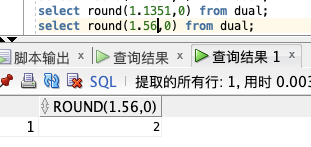
NOW/SYSDATE – 当前时间
NOW/SYSDATE 函数返回当前的日期和时间。
「语法:」
select sysdate from 表名;
「实例:」
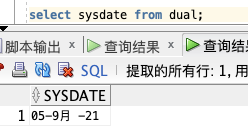
获取当前时间:
select sysdate from dual;
getdate() 函数来获得当前的日期时间。