从根上理解 Node.js 的 fs 模块:一起设计一个文件系统
Node.js 提供了 File System 的 api,可以读写文件、目录、修改权限、创建软链等。
可能大家 api 用的比较熟练,但对于这些 api 的原理不一定理解。要想真正理解 File System,还得从根上来看。
下面我们从 0 到 1 设计一个文件系统试试。
从 0 到 1 设计一个文件系统
什么是文件呢?

但是计算机的持久化存储是在硬盘,主要是磁盘和 SSD 固定硬盘:

那么如果给了这样一个硬盘,让我们自己造一个文件系统出来,实现文件的功能。怎么做呢?
简单想了下:挨着放。
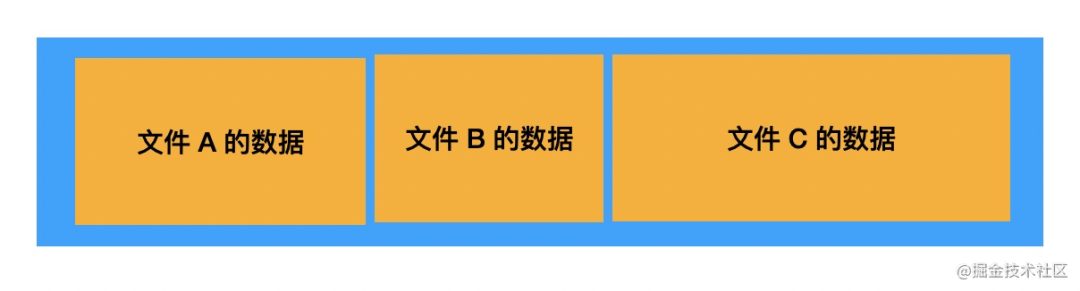


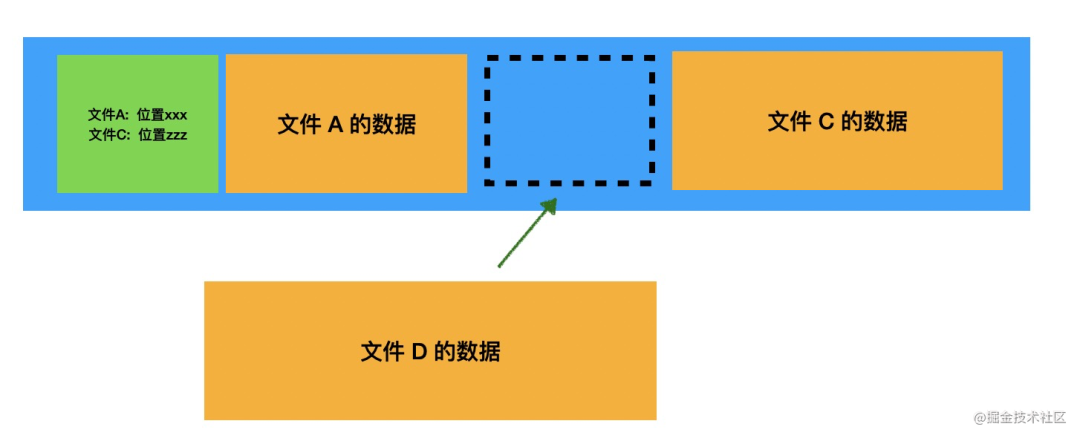
怎么办呢?如何更好的利用磁盘空间?
分块!把文件分成一小块一小块的,比如 1k 为一个块,可以不用连续存,把所有块记录在索引中就行了。
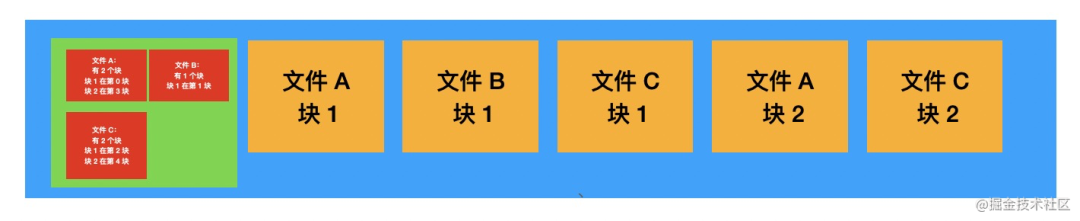

而且文件删除了,那些块还可以继续用,不会有很大的碎片。
妙啊!
难怪文件系统第一步就是分块,内存管理第一步是分页,这样才能高效利用空间啊。
这种索引节点,可以叫做 index node,简称 inode 就好了。
而且,除了文件名和存放的块以外,还可以记录其他信息,比如创建时间、修改时间、文件权限、所属用户等等。

那我写文件利用了一个块,删除文件释放了一个块,怎么知道呢?得单独记录下来块的状态。
数据块只有空闲和被占用两个状态,一个二进制位就行了。通过一段二进制数把所有块的空闲状态记录下来。一个位代表一个值,这叫做位图。在这里就是块位图。
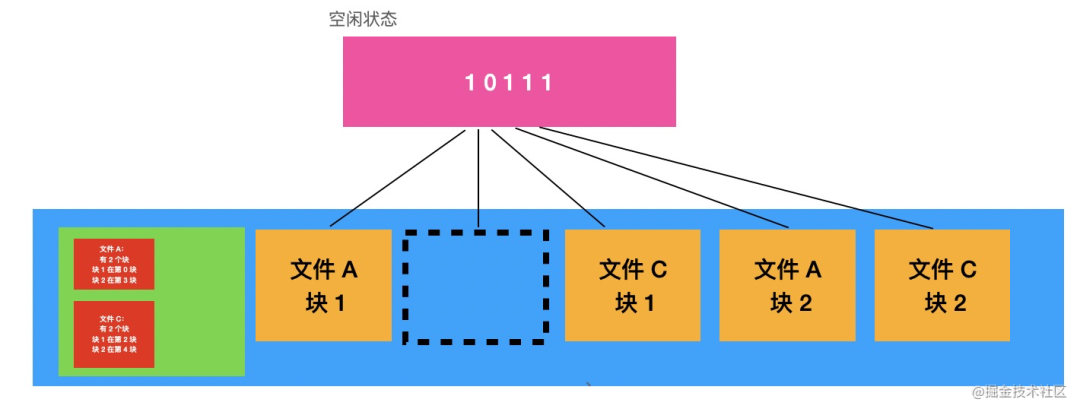
inode 也是存在块里的,比如我们规定只能用 5 个块放 inode,那 inode 总量是有限的,也就是是说文件系统可以创建的文件是有上限的。
我们也要记录下所有 inode 的空闲状态,也就是 inode 位图。
简单理一下我们设计的文件系统:
为了更好的利用硬盘空间,我们对数据进行了分块,每个文件用到了哪些块记录在 inode 里。inode 还记录了文件的创建时间、修改时间、权限等信息。
通过块位图来记录数据块空闲状态,通过 inode 位图来记录 inode 的空闲状态。
但我如果想知道硬盘中有几个块、用了几个,有几个 inode、用了几个,怎么办呢?
简单,遍历一遍块位图和 inode 位图,就知道个数了。
但每次这么算太慢了,这就像我们设计数据库的时候,一个论坛下面有多少个帖子,这个数据不会是每次用 sql 查询的,而是在帖子增删的时候动态维护一个字段在数据库表中,直接查询即可。
那我们也设计一个块用来存这种统计信息,也就是:

现在把我们设计好的文件系统交给用户,就可以通过它来高效利用硬盘了。
发布版本:神光文件系统 V1.0。
但现在我们的文件系统好像还不是很好用,只能创建文件,那如果我创建了 1000 个文件呢?
查询起来慢,也容易命名冲突。
怎么办呢?
命名空间!目录!就像文件夹的思想一样。
那怎么实现呢?
每个 inode 是一个文件,那把 inode 组织成树不就行了。
比如我们有两个文件 B 和 C:
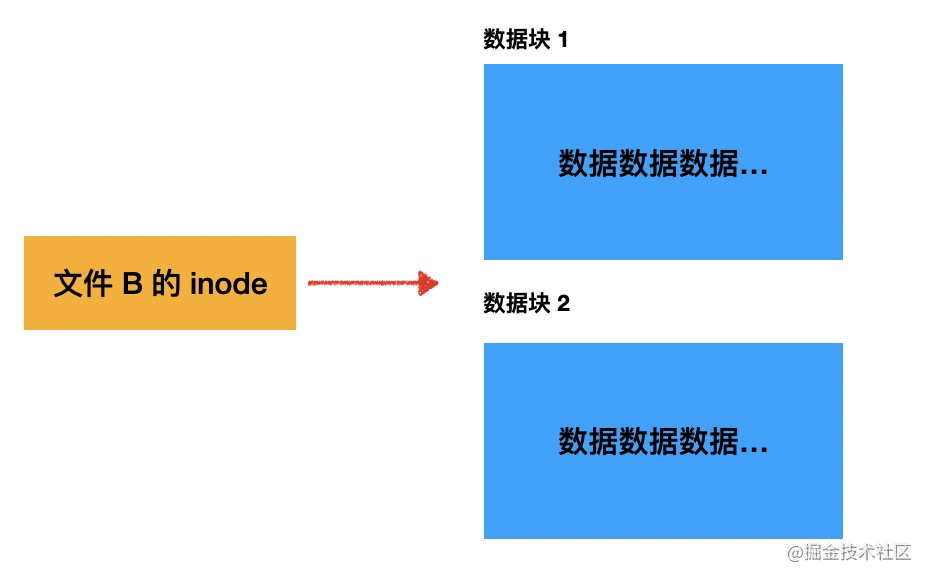


这就是目录的实现原理:通过 inode 的 isDirectory 属性区分是文件还是目录,如果是目录就读取数据块中的 inode 信息来查找子文件,如果是文件,则直接读取数据块作为文件内容。
从一个 inode 到另一个 inode 的查找顺序叫做路径(path)。
比如这样一个文件的 inode 查找顺序:

这就是文件路径的本质:文件路径就是 inode 查找顺序
现在我们支持目录的嵌套了,可以把文件、目录组织成树形结构方便管理。
发布版本:神光文件系统 v2.0。
现在一个 inode 只有一条路径过来,因为是树嘛,那如果我想两条路径都可以找到同一个 inode 呢?
比如 /A/D/dongdong.jpg 可以访问到该文件:
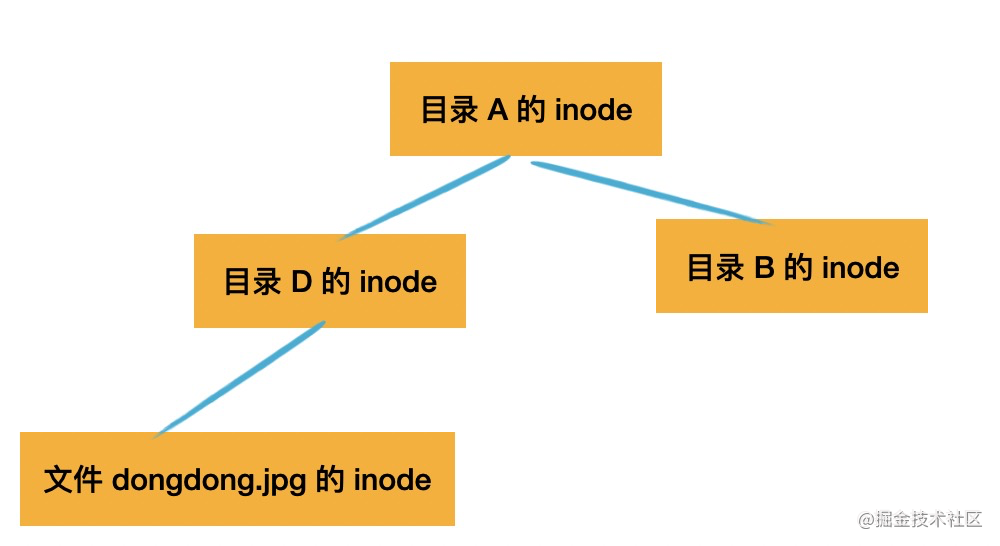
直接指过去不就行了。
这样确实可以有两条路径找到同一个文件,这个额外的链接我们起名叫做硬链接。
但是因为一个节点有两个父节点,就不再是树了,变成了图。所以,文件树这个概念严格意义上来说还是存在问题的,可能是个文件图。
但是我如果想给 dongdong.jpg 换个名字,叫 dongdong2.jpg 呢?
现在都是同一个 inode 节点,改了就都改了。但我只想改 /A/B 的 path 的文件名,别的不改。
那就再创建个 inode 节点,用来改名,然后这个 inode 节点指向 dongdong.jpg。
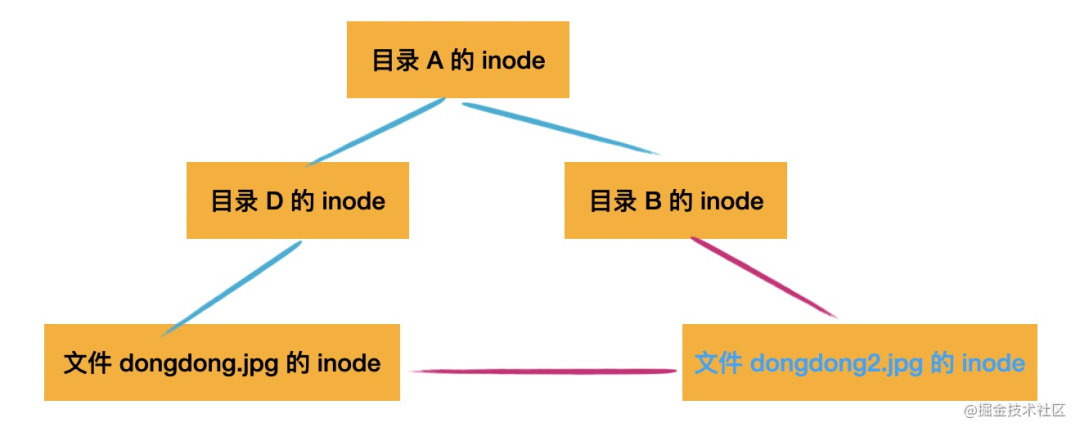
为什么叫硬呢?因为改不了,直接指向同一个 inode。
为什么叫软呢?因为可以改,多了一层 inode 用来改名。
所以我们分别起名硬软链接。
硬链接和软链接都是用于多条路径可以查找到同一个文件的,但是硬链接不能单独改名,软连接可以。
monorepo 的实现就是基于软连接的,可以指向同一个目录 inode,而且还可以起个别名。
实现了软硬链接,可以发新版本了。
发布版本:神光文件系统 v3.0。
复盘一下我们设计的文件系统:
v1.0:
通过数据块来存储文件内容,提高硬盘利用效率
通过 inode 记录所用的数据块和文件的创建时间、权限等信息
通过块位图记录数据块的空闲状态
通过 inode 位图记录 inode 空闲状态。
通过超级块记录 inode 和数据块的统计信息。
这个版本实现了文件的存取,但是不支持目录。
v2.0:
通过 inode 中添加一个属性来记录是文件还是目录
目录的数据块中存放具体文件列表的 inode 信息,读取目录的时候可以读取出文件列表。
按照目录 inode、文件 inode 的一层层的查找顺序叫做文件路径。
这个版本实现了目录和路径的功能。
v3.0:
通过多个目录 inode 包含同一个 inode 的方式,来实现多条路径查找同一文件的功能,叫做硬链接。
目录先创建一个 inode 节点用于改名,然后该 inode 节点指向目标 inode 节点,这叫做软连接。
这个版本实现了多条路径查找统一文件的软硬链接功能。
真实的文件系统也是类似的实现,目前有很多文件系统,比如 ext2、FAT 等,原理和我们设计的文件系统差不多。
文件系统设计完了,回到最开始的目标,我们是想深入理解 Node.js 的 File System 的 api。下面就来看一下。
Node.js 的文件系统 api
Node.js 通过 V8 注入了 fs 的 api 给 js 用,底层是通过 c++ 调用操作系统的文件系统功能,也就是我们上面设计的那种文件系统。
我们调用的 fs 的 api 最终就是调用了操作系统的文件系统功能。
自己设计了一个文件系统之后,我们再来看下 fs 的 api,是不是理解更深了:
- fs.stat 获取 inode 中的信息的
- fs.chmod 修改文件权限,也是修改 inode 信息
- fs.chown 修改所属用户,也是修改 inode 信息
- fs.copyFile 复制 inode 和数据块,把新的 inode 添加到对应目录的 inode 内容中
- fs.link 创建软硬链接的,也就是多条路径查找同一个文件的 inode,软连接还可以改名
- fs.mkdir 创建目录 inode 的
- fs.rmdir 读取目录 inode 包含的所有文件 inode 的
具体 api 还有很多,但都是用来操作我们上面设计的那个文件系统的。
从根上理解了文件系统,用这些 api 也会得心应手。
总结
为了真正理解 Node.js 的 fs 模块,我们一起设计了一个文件系统:
- 把文件分成不同数据块,这样可以高效利用磁盘空间。
- 文件的索引节点 index node 中记录了所包含的数据块和创建时间、权限、是否是目录等信息。
- 通过块位图记录数据块空闲状态。
- 通过 inode 位图记录 inode 空闲状态。
- 通过超级块记录硬盘的 inode、数据块的使用信息。
- 通过 inode 对应的数据块内容包含文件 inode 信息列表的方式实现了目录节点。
我们得出一些重要结论:
文件本质上就是 inode + 数据块。
路径本质上就是查找目标 inode 的路径。
硬链接本质上就是多个目录 inode 包含同一个 inode。
软连接本质上就是多创建了一个 inode 用于改名,对应数据块中指向目标 inode。
Node.js 的 fs api 是通过 c++ 注入 v8 的对操作系统能力的调用,理解了文件系统,再学那些 api 就很轻松了。