为什么要了解 Go 语言编译器
编译器是一个大型且复杂的系统,一个好的编译器会很好地结合形式语言理论、算法、人工智能、系统设计、计算机体系结构及编程语言理论。Go 语言的编译器遵循了主流编译器采用的经典策略及相似的处理流程和优化规则(例如经典的递归下降的语法解析、抽象语法树的构建)。另外,Go 语言编译器有一些特殊的设计,例如内存的逃逸。
编译原理值得用一本书的笔墨去讲解,通过了解 Go 语言编译器,不仅可以了解大部分高级语言编译器的一般性流程与规则,也能指导我们写出更加优秀的程序。很多 Go 语言的语法特性都离不开编译时与运行时的共同作用。另外,如果读者希望开发 go import、go fmt、go lint 等扫描源代码的工具,那么同样离不开编译器的知识和 Go 语言提供的 API。
Go 语言编译器的阶段
如图 1-1 所示,在经典的编译原理中,一般将编译器分为编译器前端、优化器和编译器后端。这种编译器被称为三阶段编译器(three-phase compiler)。其中,编译器前端主要专注于理解源程序、扫描解析源程序并进行精准的语义表达。编译器的中间阶段(Intermediate Representation,IR)可能有多个,编译器会使用多个 IR 阶段、多种数据结构表示代码,并在中间阶段对代码进行多次优化。例如,识别冗余代码、识别内存逃逸等。编译器的中间阶段离不开编译器前端记录的细节。编译器后端专注于生成特定目标机器上的程序,这种程序可能是可执行文件,也可能是需要进一步处理的中间形态 obj 文件、汇编语言等。

图1-1 三阶段编译器
需要注意的是,编译器优化并不是一个非常明确的概念。优化的主要目的一般是降低程序资源的消耗,比较常见的是降低内存与 CPU 的使用率。但在很多时候,这些目标可能是相互冲突的,对一个目标的优化可能降低另一个目标的效率。同时,理论已经表明有一些代码优化存在着 NP 难题,这意味着随着代码的增加,优化的难度将越来越大,需要花费的时间呈指数增长。因为这些原因,编译器无法进行最佳的优化,所以通常采用一种折中的方案。
Go 语言编译器一般缩写为小写的 gc(go compiler),需要和大写的 GC(垃圾回收)进行区分。Go 语言编译器的执行流程可细化为多个阶段,包括词法解析、语法解析、抽象语法树构建、类型检查、变量捕获、函数内联、逃逸分析、闭包重写、遍历函数、SSA 生成、机器码生成,如图 1-2 所示。
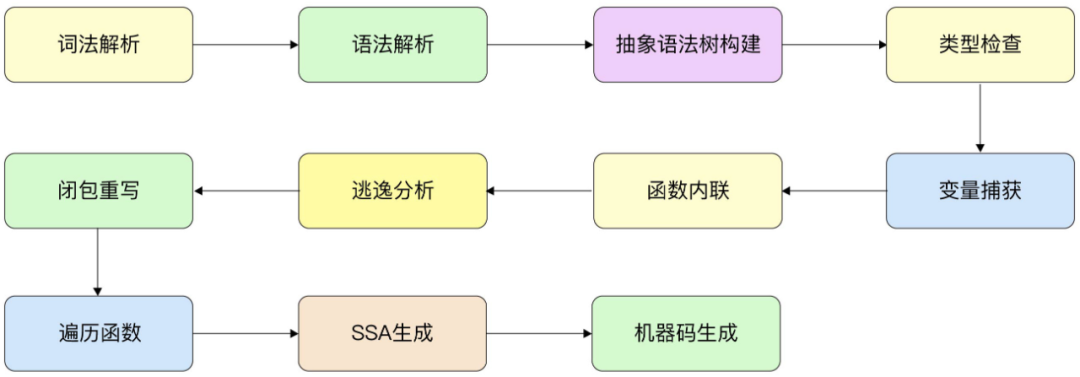
图 1-2 Go 语言编译器执行流程
词法解析
Go 语言编译器有关的代码主要位于 src/cmd/compile/internal 目录下,在后面分析中给出的文件路径均默认位于该目录中。在词法解析阶段,Go 语言编译器会扫描输入的 Go 源文件,并将其符号(token)化。
例如 “+” 和 “-” 操作符会被转换为 _IncOp ,赋值符号 “:= ” 会被转换为 _Define。这些 token 实质上是用 iota 声明的整数,定义在 syntax/tokens.go 中。符号化保留了 Go 语言中定义的符号,可以识别出错误的拼写。同时,字符串被转换为整数后,在后续的阶段中能够被更加高效地处理。
图 1-3 为一个示例,展现了将表达式 a:=b + c(12) 符号化之后的情形。代码中声明的标识符、关键字、运算符和分隔符等字符串都可以转化为对应的符号。
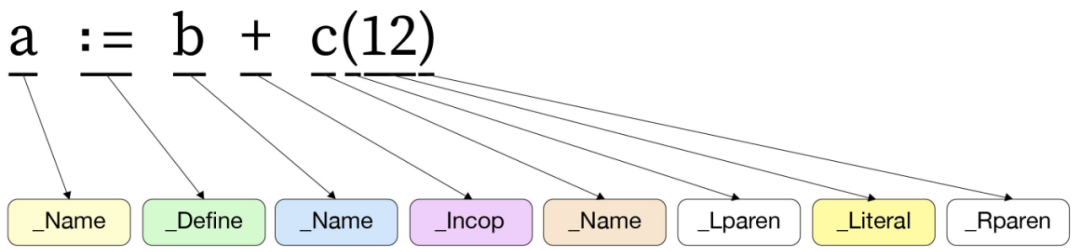
图1-3 Go 语言编译器词法解析示例
Go 语言标准库 go/scanner、go/token 也提供了许多接口用于扫描源代码。在下例中,我们将使用这些接口模拟对 Go 文本文件的扫描。
package main
import (
"fmt"
"go/scanner"
"go/token"
)
func main() {
src := []byte("cos(x) + 2i*sin(x) // Euler")
// 初始化 scanner
var s scanner.Scanner
fset := token.NewFileSet()
file := fset.AddFile("", fset.Base(), len(src))
s.Init(file, src, nil , scanner.ScanComments)
// 扫描
for {
pos, tok, lit := s.Scan()
if tok == token.EOF {
break
}
fmt.Printf("%s\t%s\t%q\n", fset.Position(pos), tok, lit)
}
}在上例中,src 为进行词法扫描的表达式,可以将其模拟为一个文件并调用 scanner.Scanner 词法,扫描后分别打印出 token 的位置、符号及其字符串字面量。每个标识符与运算符都被特定的 token 代替,例如 2i 被识别为复数 IMAG,注释被识别为 COMMENT。
1:1 IDENT "cos"
1:4 ( ""
1:5 IDENT "x"
1:6 ) ""
1:8 + ""
1:10 IMAG "2i"
1:12 * ""
1:13 IDENT "sin"
1:16 ( ""
1:17 IDENT "x"
1:18 ) ""
1:20 ; "\n"
1:20 COMMENT "// Euler"语法解析
词法解析阶段结束后,需要根据 Go 语言中指定的语法对符号化后的 Go 文件进行解析。Go 语言采用了标准的自上而下的递归下降(Top-Down Recursive-Descent)算法,以简单高效的方式完成无须回溯的语法扫描,核心算法位于 syntax/nodes.go及 syntax/parser.go 中。图 1-4 为 Go 语言编译器对文件进行语法解析的示意图。在一个 Go 源文件中主要有包导入声明(import)、静态常量(const)、类型声明(type)、变量声明(var)及函数声明。
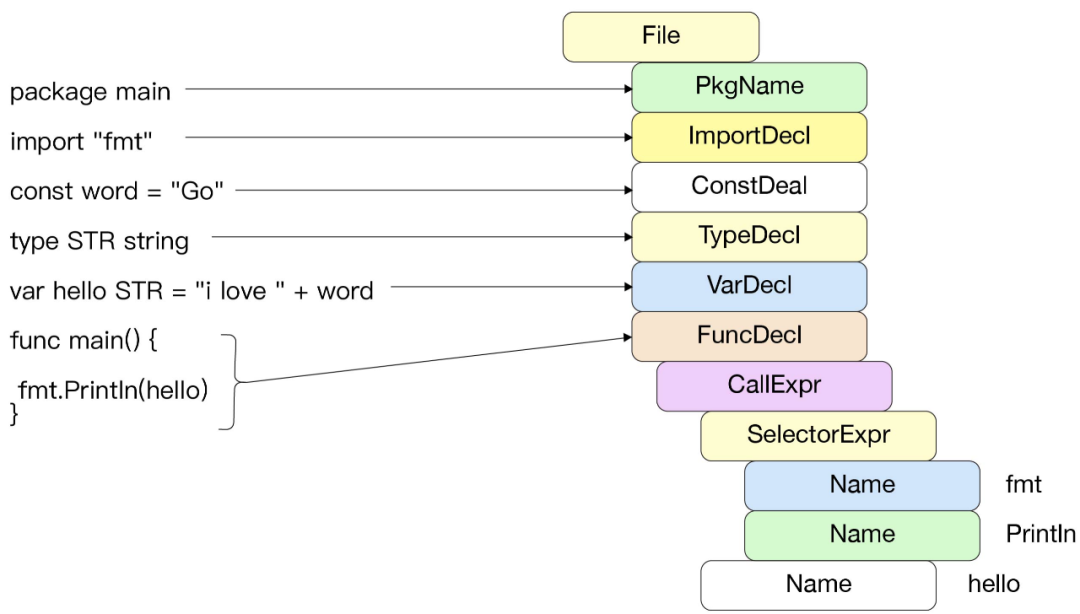
图 1-4 Go 语言编译器对文件进行语法解析的示意图
源文件中的每一种声明都有对应的语法,递归下降通过识别初始的标识符,例如_const,采用对应的语法进行解析。这种方式能够较快地解析并识别可能出现的语法错误。每一种声明语法在 Go 语言规范中都有定义
// 包导入声明
ImportSpec = [ "." | PackageName ] ImportPath .
ImportPath = string_lit .
// 静态常量
ConstSpec = IdentifierList [ [ Type ] "=" ExpressionList ] .
// 类型声明
TypeSpec = identifier [ "=" ] Type .
// 变量声明
VarSpec = IdentifierList ( Type [ "=" ExpressionList ] | "=" ExpressionList ) .函数声明是文件中最复杂的一类语法,因为在函数体的内部可能有多种声明、赋值(例如 := )、表达式及函数调用等。例如 defer 语法为 defer Expression ,其后必须跟一个函数或方法。每一种声明语法或者表达式都有对应的结构体,例如 a := b + f(89) 对应的结构体为赋值声明 AssignStmt。Op 代表当前的操作符,即 “ :=”, Lhs 与 Rhs 分别代表左右两个表达式。
AssignStmt struct {
Op Operator
Lhs, Rhs Expr
impleStmt
}语法解析丢弃了一些不重要的标识符,例如括号“ (”,并将语义存储到了对应的结构体中。语法声明的结构体拥有对应的层次结构,这是构建抽象语法树的基础。图 1-5为 a := b + c(12) 语句被语法解析后转换为对应的 syntax.AssignStmt 结构体之后的情形。最顶层的 Op 操作符为 token.Def(:= )。Lhs 表达式类型为标识符 syntax.Name,值为标识符“a”。Rhs 表达式为 syntax.Operator 加法运算。加法运算左边为标识符 “b”,右边为函数调用表达式,类型为 CallExpr。其中,函数名 c 的类型为syntax.Name,参数为常量类型 syntax.BasicLit,代表数字 12。
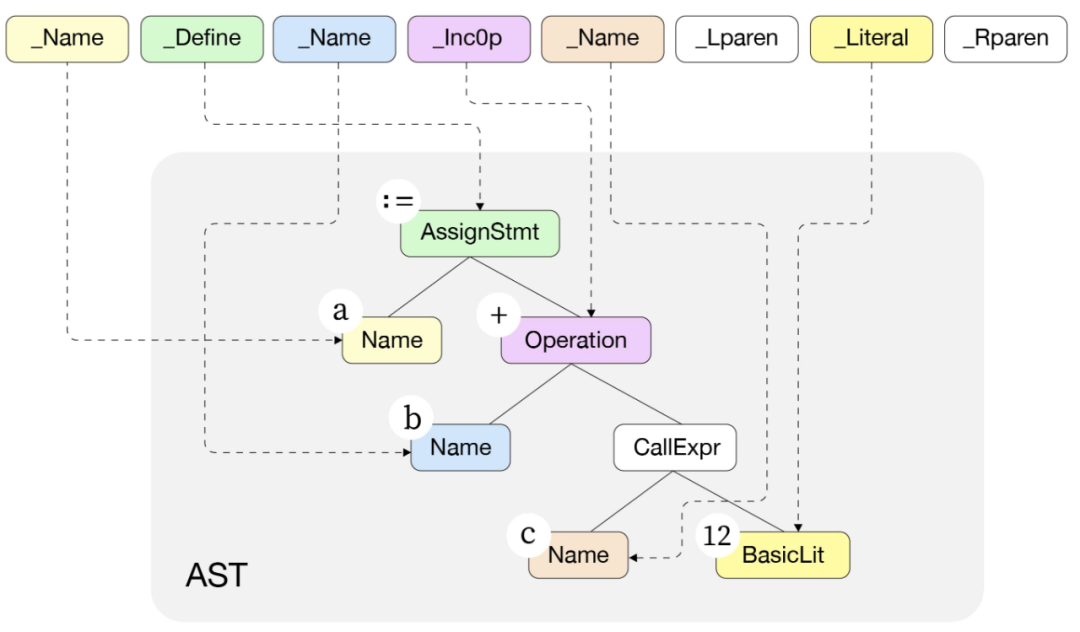
图 1-5 特定表达式的语法解析示例
Go 语言可执行文件的生成离不开编译器所做的复杂工作,如果不理解 Go 语言的编译器,那么对 Go 语言的理解是不完整的。Go 语言的编译器、运行时,本身就是用 Go 语言写出的既复杂又精巧的程序;探究语言设计、语法特性,本身就是学习程序设计与架构、数据结构与算法等知识的绝佳途径。学习底层原理能够帮助我们更好地了解 Go 语言的语法,做出合理的性能优化,设计科学的程序架构,监控程序的运行状态,排查复杂的程序异常问题,开发出检查协程泄露、语法等问题的高级工具,理解 Go 语言的局限性,从而在不同场景下做出合理抉择。
编译阶段包括词法解析、语法解析、抽象语法树构建、类型检查、变量捕获、函数内联、逃逸分析、闭包重写、遍历并编译函数、SSA 生成、机器码生成。编译器不仅能准确地表达语义,还能对代码进行一定程度的优化。可以看到,Go 语言的很多语法检查、语法特性都依赖编译时。理解编译时的基本流程、优化方案及一些调试技巧有助于写出更好的程序。
目前市面上鲜有系统介绍 Go 语言底层实现原理的书籍,如果你想系统了解学习更多,今天给大家推荐这本新书书,书中系统性地介绍 Go 语言在编译时、运行时以及语法特性等层面的底层原理和更好的使用方法。

本书语言通俗易懂,书中有系统权威的知识解构、精美的示意图,并对照源码和参考文献字斟句酌,在一线大规模系统中提炼出设计哲学与避坑方法,对于编译时、运行时及垃圾回收的精彩讲解弥补了国内的多项缺陷,这本罕见的诚意之作必将陪伴读者实现最艰苦的能力跨越,你想要的都会到来……
内容简介
本书由 21 章组成,这 21 章可以分为 6 部分。
- 第 1~8 章为第 1 部分,介绍 Go 语言的基础——编译时及类型系统。包括浮点数、切片、哈希表等类型以及类型转换的原理。
- 第 9~11 章为第 2 部分,介绍程序运行重要的组成部分——函数与栈。包括栈帧布局、栈扩容、栈调试的原理,并介绍了延迟调用、异常与异常捕获的原理。
- 第 12、13 章为第 3 部分,介绍 Go 语言程序设计的关键——接口。包括如何正确合理地使用接口构建程序、接口的实现原理和可能遇到的问题,并探讨了接口之上的反射原理。
- 第 14~17 章为第 4 部分,介绍 Go 语言并发的核心——协程与通道。详细论述了协程的本质以及运行时调度器的调度时机与策略。介绍了通过通信来共享内存的通道本质以及通道的多路复用原理,并探讨了并发控制、数据争用问题的解决办法及锁的本质。
- 第 18~20 章为第 5 部分,介绍 Go 语言运行时最复杂的模块——内存管理与垃圾回收。详细论述了 Go 语言中实现内存管理方法及垃圾回收的详细步骤。
- 第 21 章为第 6 部分,介绍 Go 语言可视化工具——pprof 与 trace。详细论述了通过工具排查问题、观察系统运行状态的方法与实现原理。