React Fiber 简介 —— React 背后的算法
在这篇文章中,我们将了解 React Fiber —— React 背后的核心算法。React Fiber 是 React 16 中新的协调算法。你很可能听说过 React 15 中的 virtualDOM,这是旧的协调算法(因为它在内部使用堆栈也被称为堆栈协调器)。不同的渲染器,如 DOM、Native 和 Android 视图,都会共享同一个协调器,所以称它为 virtualDOM 可能会导致混淆。
让我们赶紧看看什么是 React Fiber。
介绍
React Fiber 是针对就协调器重写的完全向后兼容的一个版本。React 的这种新的协调算法被称为 Fiber Reconciler。这个名字来自于 fiber,它经常被用来表示 DOM 树的节点。我们将在后面的章节中详细介绍 fiber。
Fiber 协调器的主要目标是增量渲染,更好更平滑地渲染 UI 动画和手势,以及用户互动的响应性。协调器还允许你将工作分为多个块,并将渲染工作分为多个帧。它还增加了为每个工作单元定义优先级的能力,以及暂停、重复使用和中止工作的能力。
React 的其他一些特性包括从一个渲染函数返回多个元素,支持更好的错误处理(我们可以使用 componentDidCatch 方法来获得更清晰的错误信息),以及 portals。
在计算新的渲染更新时,React 会多次回访主线程。因此,高优先级的工作可以跳过低优先级的工作。React 在内部为每个更新定义了优先级。
在进入技术细节之前,我建议你学习以下术语,这将有助于理解 React Fiber。
先决条件
协调
正如官方 React 文档 所解释的, reconciliation 是两个 DOM 树 diff 的算法。当用户界面第一次渲染时,React 创建了一个节点树。每个单独的节点都代表 React 元素。它创建了一个虚拟树(被称为 virtualDOM),是渲染的 DOM 树的副本。在来自用户界面的任何更新之后,它递归地比较两棵树的每一个树节点。然后,累积的变化被传递给渲染器。
调度
正如官方 React 文档所解释的, 假设我们有一些低优先级的工作(如大型计算函数或最近获取的元素的渲染),和一些高优先级的工作(如动画)。应该有一个选项,将高优先级的工作优先于低优先级的工作。在旧的堆栈协调器实现中,递归遍历和调用整个更新的树的渲染方法都发生在单个流程中,这可能会导致丢帧。
调度可以是基于时间或基于优先级的。更新应该根据 deadline 来安排,高优先级的工作应该被安排在低优先级的工作之上。
requestIdleCallback(请求闲置回调)
requestAnimationFrame 安排高优先级的函数在下一个动画帧之前被调用。类似地,requestIdleCallback 安排低优先级或非必要的函数在帧结束时的空闲时间被调用。
requestIdleCallback(lowPriorityWork);
这里展示了 requestIdleCallback 的用法。lowPriorityWork 是一个回调函数,将在帧结束时的空闲时间内被调用。
function lowPriorityWork(deadline) {
while (deadline.timeRemaining() > 0 && workList.length > 0)
performUnitOfWork();
if (workList.length > 0) requestIdleCallback(lowPriorityWork);
}当这个回调函数被调用时,它得到参数 deadline 对象。正如你在上面的片段中看到的,timeRemaining 函数返回最近的剩余空闲时间。如果这个时间大于零,我们可以做一些必要的工作。而如果工作没有完成,我们可以在下一帧的最后一行再次安排工作。
所以,现在我们可以继续研究 fiber 对象本身,看看 React Fiber 是如何工作的。
Fiber 的结构
一个 fiber(小写'f')是一个简单的 JavaScript 对象。它代表 React 元素或 DOM 树的一个节点。它是一个工作单位。相比之下,Fiber 是 React Fiber 的协调器。
这个例子展示了一个简单的 React 组件,在 root div 中进行渲染。
function App() {
return (
<div className="wrapper">
<div className="list">
<div className="list_item">List item A</div>
<div className="list_item">List item B</div>
</div>
<div className="section">
<button>Add</button>
<span>No. of items: 2</span>
</div>
</div>
);
}
ReactDOM.render(<App />, document.getElementById("root"));这是一个简单的组件,为我们从组件状态得到的数据显示一个列表项。(我把 .map 和对数据的迭代替换成两个列表项,只是为了让这个例子看起来更简单)还有一个按钮和 span,它显示了列表项的数量。
如前所述,fiber 代表 React 元素。在第一次渲染时,React 会浏览每个 React 元素并创建一棵 fibers 树。(我们将在后面的章节中看到它是如何创建这个树的)。
它为每个单独的 React 元素创建一个 fiber,就像上面的例子。它将为 div 创建一个 fiber,例如 W,它的类是 wrapper。然后,为具有 list 类的 div 创建 L fiber,以此类推。让我们为两个列表项的 fiber 命名为 LA 和 LB。
在后面的部分,我们将看到它是如何迭代的,以及树的最终结构。虽然我们称之为树,但 React Fiber 创建了一个节点的链表,其中每个节点都是一个 fiber。 并且在父、子和兄弟姐妹之间存在着一种关系。React 使用一个 return 键来指向父节点,任何一个子 fiber 在完成工作后都应该返回该节点。所以,在上面的例子中,LA 的返回是 L,而兄弟姐妹是 LB。
那么,这个 fiber 物体究竟是什么样子的呢?
下面是 React 代码库中对 fiber 类型的定义。我删除了一些额外的 props,并保留了一些注释以理解属性的含义。你可以在 React codebase 中找到详细的结构。
export type Fiber = {
// 识别 fiber 类型的标签。
tag: TypeOfWork,
// child 的唯一标识符。
key: null | string,
// 元素的值。类型,用于在协调 child 的过程中保存身份。
elementType: any,
// 与该 fiber 相关的已解决的 function / class。
type: any,
// 与该 fiber 相关的当前状态。
stateNode: any,
// fiber 剩余的字段
// 处理完这个问题后要返回的 fiber。
// 这实际上就是 parent。
// 它在概念上与堆栈帧的返回地址相同。
return: Fiber | null,
// 单链表树结构。
child: Fiber | null,
sibling: Fiber | null,
index: number,
// 最后一次用到连接该节点的引用。
ref:
| null
| (((handle: mixed) => void) & { _stringRef: ?string, ... })
| RefObject,
// 进入处理这个 fiber 的数据。Arguments、Props。
pendingProps: any, // 一旦我们重载标签,这种类型将更加具体。
memoizedProps: any, // 用来创建输出的道具。
// 一个状态更新和回调的队列。
updateQueue: mixed,
// 用来创建输出的状态
memoizedState: any,
mode: TypeOfMode,
// Effect
effectTag: SideEffectTag,
subtreeTag: SubtreeTag,
deletions: Array<Fiber> | null,
// 单链表的快速到下一个 fiber 的副作用。
nextEffect: Fiber | null,
// 在这个子树中,第一个和最后一个有副作用的 fiber。
// 这使得我们在复用这个 fiber 内所做的工作时,可以复用链表的一个片断。
firstEffect: Fiber | null,
lastEffect: Fiber | null,
// 这是一个 fiber 的集合版本。每个被更新的 fiber 最终都是成对的。
// 有些情况下,如果需要的话,我们可以清理这些成对的 fiber 来节省内存。
alternate: Fiber | null,
};React Fiber 是如何工作的?
接下来,我们将看到 React Fiber 是如何创建链表树的,以及当有更新时它会做什么。
在此之前,让我们解释一下什么是 current tree 和 workInProgress tree,以及如何进行树形遍历。
当前被刷新用来渲染用户界面的树,被称为 current,它用来渲染当前用户界面。每当有更新时,Fiber 会建立一个 workInProgress 树,它是由 React 元素中已经更新数据创建的。React 在这个 workInProgress 树上执行工作,并在下次渲染时使用这个更新的树。一旦这个 workInProgress 树被渲染到用户界面上,它就成为 current 树。
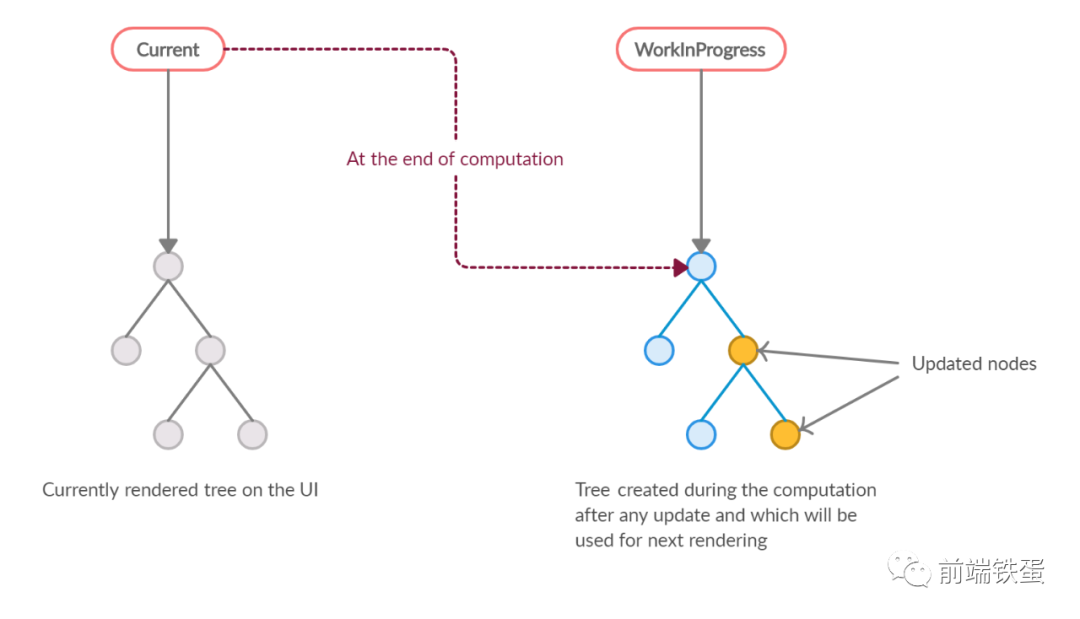
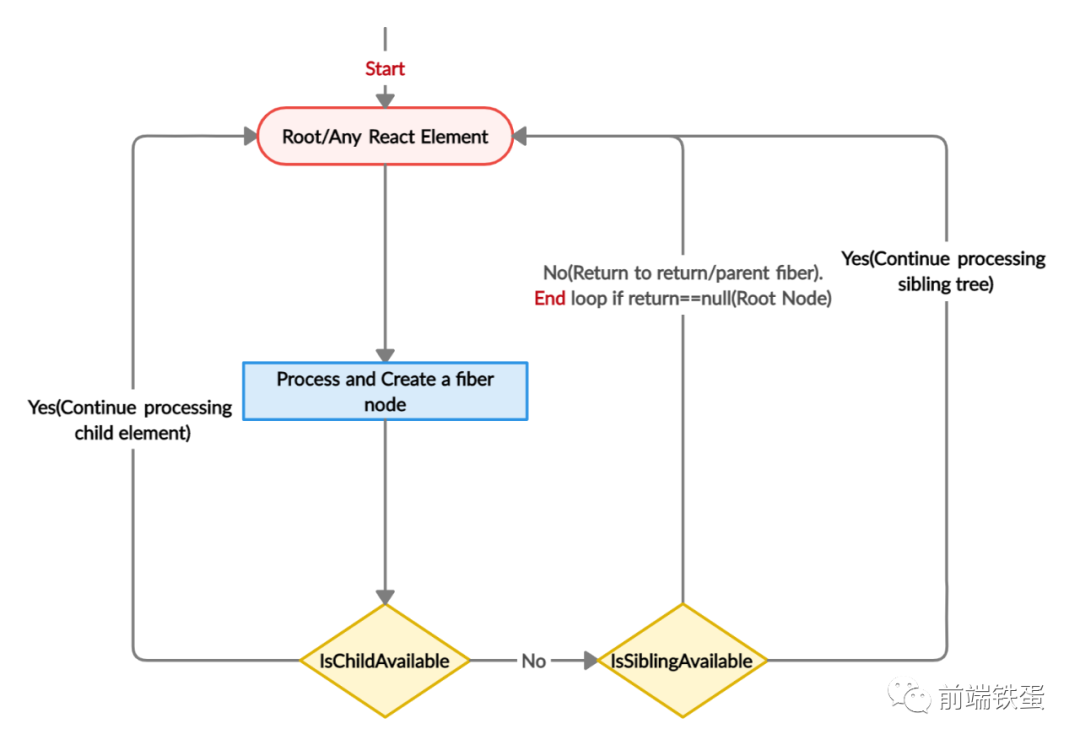
Fiber 树的遍历是这样发生的。
- 开始:Fiber 从最上面的 React 元素开始遍历,并为其创建一个 fiber 节点。
- 子节点:然后,它转到子元素,为这个元素创建一个 fiber 节点。这样继续下去,直到到达叶子元素。
- 兄弟节点:现在,它检查是否有兄弟节点元素。如果有,它就遍历兄弟节点元素,然后再到兄弟姐妹的叶子元素。
- 返回:如果没有兄弟节点,那么它就返回到父节点。
每个 fiber 都有一个子属性(如果没有子属性,则为空值)、兄弟和父节点属性(正如你在前面的章节中看到的 fiber 的结构)。这些是 fiber 中的指针,可以作为一个链表来工作。
让我们举同样的例子,我们先给特定 React 元素的 fiber 命名。
function App() {
// App
return (
<div className="wrapper">
{" "}
// W<div className="list">
{" "}
// L<div className="list_item">List item A</div> // LA
<div className="list_item">List item B</div> // LB
</div>
<div className="section">
{" "}
// S<button>Add</button> // SB
<span>No. of items: 2</span> // SS
</div>
</div>
);
}
ReactDOM.render(<App />, document.getElementById("root")); // HostRoot首先,我们将快速介绍创建树时的挂载阶段,之后,我们将了解树更新后详细逻辑。
初始渲染
App 组件被渲染在 root div 中,它的 id 是 root。
在进一步遍历之前,React Fiber 创建一个根 fiber 。每个 fiber 树都有一个根节点。在我们这里,它是 HostRoot。如果我们在 DOM 中导入多个 React 应用,可以有多个根节点。
在第一次渲染之前,不会有任何树。React Fiber 遍历每个组件的渲染函数的输出,并为每个 React 元素在树上创建一个 fiber 节点。它用 createFiberFromTypeAndProps 来将 React 元素转换为 fiber 。React 元素可以是一个类组件,也可以是一个宿主组件,如 div 或 span。对于类组件,它创建一个实例,而对于宿主组件,它从 React 元素中获得数据和 props。
因此,正如例子中所示,它创建了一个 fiber App。再往前走,它又创建了一个 fiber ,W,然后它转到子 div 并创建了一个 fiber L,如此下去,它为它的子代创建了一个 fiber ,LA 和 LB。 fiber ,LA,将有返回(在这种情况下也可以被称为父级) fiber 作为 L,和兄弟姐妹作为 LB。
因此,这就是最终的 fiber 树的样子。
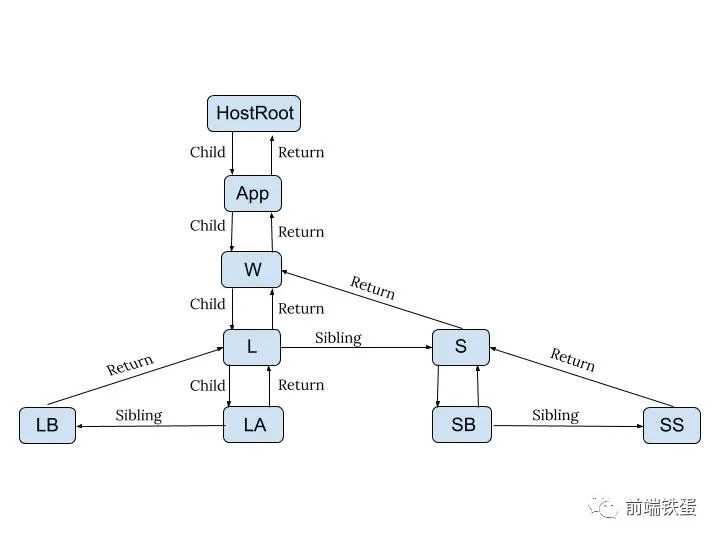
这就是树节点是如何使用子节点、同级节点和返回指针连接的。
更新阶段
现在,让我们来谈谈第二种情况,例如由于 setState 而导致的更新。
所以,在这个时候,Fiber 已经有了 current tree。对于每次更新,它都会建立一个 workInProgress 树。它从根 fiber 开始,遍历该树,直到叶子节点。与初始渲染阶段不同,它不会为每个 React 元素创建一个新的 fiber 。它只是为该 React 元素使用预先存在的 fiber ,并在更新阶段合并来自更新元素的新数据和 props。
早些时候,在 React 15 中,堆栈协调器是同步的。所以,一个更新会递归地遍历整个树,并制作一个树的副本。假设在这之间,如果有其他的更新比它的优先级更高,那么就没有机会中止或暂停第一个更新并执行第二个更新。
React Fiber 将更新划分为工作单元。它可以为每个工作单元分配优先级,并有能力暂停、重用或在不需要时中止工作单元。React Fiber 将工作分为多个工作单位,也就是 fiber 。它将工作安排在多个框架中,并使用来自 requestIdleCallback 的 deadline 。每个更新都有其优先级的定义,如动画,或用户输入的优先级高于从获取的数据中渲染项目的列表。Fiber 使用 requestAnimationFrame 来处理优先级较高的更新,使用 requestIdleCallback 处理优先级较低的更新。因此,在调度工作时,Fiber 检查当前更新的优先级和 deadline (帧结束后的自由时间)。
如果优先级高于待处理的工作,或者没有 截止日期 或者截止日期尚未到达,Fiber 可以在一帧之后安排多个工作单元。而下一组工作单元会被带到更多的帧上。这就是使 Fiber 有可能暂停、重用和中止工作单元的原因。
那么,让我们看看在预定的工作中实际发生了什么。有两个阶段来完成工作。render 和 commit。
渲染阶段
实际的树形遍历和 deadline 的使用发生在这个阶段。这是 Fiber 的内部逻辑,所以在这个阶段对 Fiber 树所做的改变对用户来说是不可见的。因此,Fiber 可以暂停、中止或分担多个框架的工作。
我们可以把这个阶段称为协调阶段。 fiber 从 fiber 树的根部开始遍历,处理每个 fiber 。每一个工作单位都会调用workLoop 函数来执行工作。我们可以把这个工作的处理分成两个步骤。begin 和 complete 。
开始阶段
如果你从 React 代码库中找到 workLoop 函数,它就会调用 performUnitOfWork,它把 nextUnitOfWork 作为一个参数,它就只是个工作的单位,将被执行。 performUnitOfWork 函数内部调用 beginWork 函数。这是 fiber 上发生实际工作的地方,而 performUnitOfWork 只是发生迭代的地方。
在 beginWork 函数中,如果 fiber 没有任何待处理的工作,它就会直接跳出(跳过) fiber 而不进入开始阶段。这就是在遍历大树时, fiber 跳过已经处理过的 fiber ,直接跳到有待处理工作的 fiber 。如果你看到大的 beginWork 函数代码块,我们会发现一个开关块,根据 fiber 标签,调用相应的 fiber 更新函数。就像 updateHostComponent 用于宿主组件。这些函数会更新 fiber 。
如果有子 fiber ,beginWork函数返回子 fiber ,如果没有子 fiber 则返回空。函数 performUnitOfWork 持续迭代并调用子 fiber ,直到叶节点到达。在叶子节点的情况下,beginWork 返回 null,因为没有任何子节点,performUnitOfWork 函数调用 completeUnitOfWork 函数。现在让我们看看完善阶段。
完善阶段
这个 completeUnitOfWork 函数通过调用一个 completeWork 函数来完成当前单位的工作。如果有的话,completeUnitOfWork 会返回一个同级的 fiber 来执行下一个工作单元,如果没有工作的话,则会完成 return(parent) fiber 。这将一直持续到返回值为空,也就是说,直到它到达根节点。和 beginWork 一样,completeWork 也是一个发生实际工作的函数,而 completeUnitOfWork 是用于迭代的。
渲染阶段的结果会产生一个效果列表(副作用)。这些效果就像插入、更新或删除宿主组件的节点,或调用类组件节点的生命周期方法。这些 fiber 被标记为各自的效果标签。
在渲染阶段之后,Fiber 将准备提交更新。
提交阶段
这是一个阶段,完成的工作将被用来在用户界面上渲染它。由于这一阶段的结果对用户来说是可见的,所以不能被分成部分渲染。这个阶段是一个同步的阶段。
在这个阶段的开始,Fiber 有已经在 UI 上渲染的 current 树,finishedWork,或者在渲染阶段建立的 workInProgress 树和效果列表。
effect 列表是 fiber 的链表,它有副作用。所以,它是渲染阶段的 workInProgress 树的节点的一个子集,它有副作用(更新)。effect 列表的节点是用 nextEffect 指针链接的。
在这个阶段调用的函数是 completeRoot。
在这里,workInProgress 树成为 current 树,因为它被用来渲染 UI。实际的 DOM 更新,如插入、更新、删除,以及对生命周期方法的调用或者更新相对应的引用 —— 发生在 effect 列表中的节点上。
这就是 fiber 协调器的工作方式。
结论
这就是 React Fiber 协调器使之有可能将工作分为多个工作单元。它设置每个工作的优先级,并使暂停、重用和中止工作单元成为可能。在 fiber 树中,单个节点保持跟踪,这是使上述事情成为可能的需要。每个 fiber 都是一个链表的节点,它们通过子、兄弟节点和返回引用连接起来。