分享一个 UT failed 引出的思考
前几天某个服务 ut 失败,导致别人无法构建。查看下源代码以及 ut case, 发现槽点蛮多,分享下如何修复,写单测要注意的一些点,由此引出设计模式中的概念依赖反转、依赖注入、控制反转
失败 case
func toSeconds(in int64) int64 {
if in > time.Now().Unix() {
nanosecondSource := time.Unix(0, in)
if dateIsSane(nanosecondSource) {
return nanosecondSource.Unix()
}
millisecondSource := time.Unix(0, in*int64(time.Millisecond))
if dateIsSane(millisecondSource) {
return millisecondSource.Unix()
}
// default to now rather than sending something stupid
return time.Now().Unix()
}
return in
}
func dateIsSane(in time.Time) bool {
return (in.Year() >= (time.Now().Year()-1) &&
in.Year() <= (time.Now().Year()+1))
}函数 toSeconds 接收一个时间参数,可能是秒、毫秒和其它时间,经过判断后返回秒值
......
{
desc: "less than now",
args: 1459101327,
expect: 1459101327,
},
{
desc: "great than year",
args: now.UnixNano()/6000*6000 + 7.55424e+17,
expect: now.Unix(),
},
......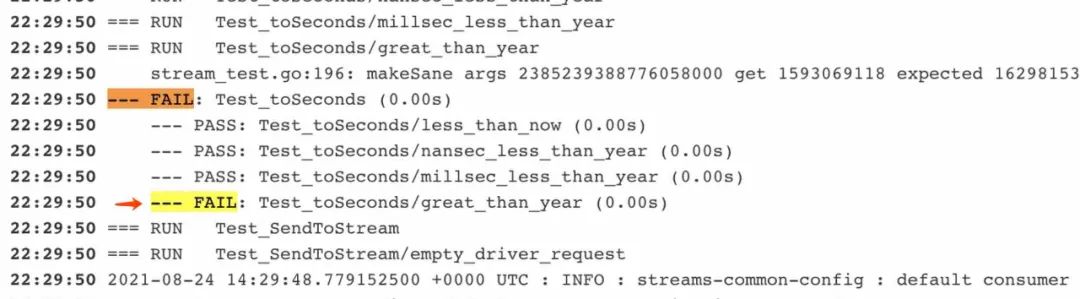
上面是 test case table, 最后报错 great than year 断言失败了。简单的看下实现逻辑就能发现,函数是想修正到秒值,但假如刚好 go gc STW 100ms, 就会导致 expect 与实际结果不符
如何从根本上修复问题呢?要么修改函数签名,外层传入 time.Now()
func toSeconds(in int64, now time.Time) int64 {
......
}要么将 time.Now 函数定义成当前包内变量,写单测时修改 now 变量
var now = time.Now
func toSeconds(in int64) int64 {
if in > now().Unix() {
......
}以上两种方式都比较常见,本质在于单测 ut 不应该依赖于当前系统环境,比如 mysql, redis, 时间等等,应该仅依赖于输入参数,同时函数执行多次结果应该一致。去年遇到过 CI 机器换了,新机器没有 redis/mysql, 导致一堆 ut failed, 这就是不合格的写法
如果依赖环境的资源,那么就变成了集成测试。如果进一步再依赖业务的状态机,那么就变成了回归测试,可以说是层层递进的关系。只有做好代码的单测,才能进一步确保其它测试正常。同时也不要神话单测,过份追求 100% 覆盖
依赖注入
刚才我们非常自然的引入了设计模式中,非常重要的 依赖注入 Dependenccy injection 概念
func toSeconds(in int64, now time.Time) int64
简单的讲,toSeconds 函数调用系统时间 time.Now, 我们把依赖以参数的形式传给 toSeconds 就是注入依赖,定义就这么简单
关注 DI, 设计模式中抽像出来四个角色:
service我们所被依赖的对像client依赖 service 的角色interface定义 client 如何使用 service 的接口injector注入器角色,用于构造 service, 并将之传给 client
我们来看一下面像对像的例子,Hero 需要有武器,NewHero 是英雄的构造方法
type Hero struct {
name string
weapon Weapon
}
func NewHero(name string) *Hero {
return &sHero{
name: name,
weapon: NewGun(),
}
}这里面问题很多,比如换个武器 AK 可不可以呢?当然行。但是 NewHero 构造时依赖了 NewGun, 我们需要把武器在外层初始化好,然后传入
type Hero struct {
name string
weapon Weapon
}
func NewHero(name string, wea Weapon) *Hero {
return &Hero{
name: name,
weapon: wea,
}
}
func main(){
wea:= NewGun();
myhero = NewHero("killer47", wea)
}在这个 case 里面,Hero 就是上面提到的 client 角色,Weapon 就是 service 角色,injector 是谁呢?是 main 函数,其实也是码农
这个例子还有问题,原因在于武器不应该是具体实例,而应该是接口,即上面提到的 interface 角色
type Weapon interface {
Attack(damage int)
}也就是说我们的武器要设计成接口 Weapon, 方法只有一个 Attack 攻击并附带伤害。但是到现在还不是理想的,比如说我没有武器的时候,就不能攻击人了嘛?当然能,还有双手啊,所以有时我们要用 Option 实现默认依赖
type Weapon interface {
Attack(damage int)
}
type Hero struct {
name string
weapon Weapon
}
func NewHero(name string, opts ...Option) *Hero {
h := &Hero{
name: name,
}
for _, option := range options {
option(i)
}
if h.weapon == nil {
h.weapon = NewFist()
}
return h
}
type Option func(*Hero)
func WithWeapon(w Weapon) Option {
return func(i *Hero) {
i.weapon = w
}
}
func main() {
wea := NewGun()
myhero = NewHero("killer47", WithWeapon(wea))
}上面就是一个生产环境中,比较理想的方案,看不明白的可以运行代码试着理解下
第三方框架
刚才提到的例子比较简单,injector 由码农自己搞就行了。但是很多时候,依赖的对像不只一个,可能很多,还有交叉依赖,这时候就需要第三方框架来支持了
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<bean id="service" class="ExampleService">
</bean>
<bean id="client" class="Client">
<constructor-arg value="service" />
</bean>
</beans>Java 党写配置文件,用注解来实现。对于 go 来讲,可以使用 wire, https://github.com/google/wire
// +build wireinject
package main
import (
"github.com/google/wire"
"wire-example2/internal/config"
"wire-example2/internal/db"
)
func InitApp() (*App, error) {
panic(wire.Build(config.Provider, db.Provider, NewApp)) // 调用wire.Build方法传入所有的依赖对象以及构建最终对象的函数得到目标对象
}类似上面一样,定义 wire.go 文件,然后写上 +build wireinject 注释,调用 wire 后会自动生成 injector 代码
//go:generate go run github.com/google/wire/cmd/wire
//+build !wireinject
package main
import (
"wire-example2/internal/config"
"wire-example2/internal/db"
)
// Injectors from wire.go:
func InitApp() (*App, error) {
configConfig, err := config.New()
if err != nil {
return nil, err
}
sqlDB, err := db.New(configConfig)
if err != nil {
return nil, err
}
app := NewApp(sqlDB)
return app, nil
}我司有项目在用,感兴趣的可以看看官方文档,对于构建大型项目很有帮助
依赖反转 DIP 原则
我们还经常听说一个概念,就是依赖反转 dependency inversion principle, 他有两个最重要的原则:
- High-level modules should not depend on low-level modules. Both should depend on abstractions (e.g., interfaces).
- Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
高层模块不应该依赖低层模块,需要用接口进行抽像。抽像不应该依赖于具体实现,具体实现应该依赖于抽像,结合上面的 Hero&Weapon 案例应该很清楚了
那我们学习 DI、DIP 这些设计模式目的是什么呢?使我们程序各个模块之间变得松耦合,底层实现改动不影响顶层模块代码实现,提高模块化程度,增加括展性
但是也要有个度,服务每个都做个 interface 抽像一个模块是否可行呢?当然不,基于这么多年的工程实践,我这里面有个准则分享给大家:易变的模块需要做出抽像、跨 rpc 调用的需要做出抽像
控制反转 IOC 思想
本质上依赖注入是控制反转 IOC 的具体一个实现。在传统编程中,表达程序目的的代码调用库来处理通用任务,但在控制反转中,是框架调用了自定义或特定任务的代码,Java 党玩的比较多
推荐大家看一下 coolshell 分享的 undo 例子。比如我们有一个 set 想实现 undo 撤回功能
type IntSet struct {
data map[int]bool
}
func NewIntSet() IntSet {
return IntSet{make(map[int]bool)}
}
func (set *IntSet) Add(x int) {
set.data[x] = true
}
func (set *IntSet) Delete(x int) {
delete(set.data, x)
}
func (set *IntSet) Contains(x int) bool {
return set.data[x]
}这是一个 IntSet 集合,拥有三个函数 Add, Delete, Contains, 现在需要添加 undo 功能
type UndoableIntSet struct { // Poor style
IntSet // Embedding (delegation)
functions []func()
}
func NewUndoableIntSet() UndoableIntSet {
return UndoableIntSet{NewIntSet(), nil}
}
func (set *UndoableIntSet) Add(x int) { // Override
if !set.Contains(x) {
set.data[x] = true
set.functions = append(set.functions, func() { set.Delete(x) })
} else {
set.functions = append(set.functions, nil)
}
}
func (set *UndoableIntSet) Delete(x int) { // Override
if set.Contains(x) {
delete(set.data, x)
set.functions = append(set.functions, func() { set.Add(x) })
} else {
set.functions = append(set.functions, nil)
}
}
func (set *UndoableIntSet) Undo() error {
if len(set.functions) == 0 {
return errors.New("No functions to undo")
}
index := len(set.functions) - 1
if function := set.functions[index]; function != nil {
function()
set.functions[index] = nil // For garbage collection
}
set.functions = set.functions[:index]
return nil
}上面是具体的实现,有什么问题嘛?有的,undo 理论上只是控制逻辑,但是这里和业务逻辑 IntSet 的具体实现耦合在一起了
type Undo []func()
func (undo *Undo) Add(function func()) {
*undo = append(*undo, function)
}
func (undo *Undo) Undo() error {
functions := *undo
if len(functions) == 0 {
return errors.New("No functions to undo")
}
index := len(functions) - 1
if function := functions[index]; function != nil {
function()
functions[index] = nil // For garbage collection
}
*undo = functions[:index]
return nil
}上面就是我们 Undo 的实现,跟本不用关心业务具体的逻辑
type IntSet struct {
data map[int]bool
undo Undo
}
func NewIntSet() IntSet {
return IntSet{data: make(map[int]bool)}
}
func (set *IntSet) Undo() error {
return set.undo.Undo()
}
func (set *IntSet) Contains(x int) bool {
return set.data[x]
}
func (set *IntSet) Add(x int) {
if !set.Contains(x) {
set.data[x] = true
set.undo.Add(func() { set.Delete(x) })
} else {
set.undo.Add(nil)
}
}
func (set *IntSet) Delete(x int) {
if set.Contains(x) {
delete(set.data, x)
set.undo.Add(func() { set.Add(x) })
} else {
set.undo.Add(nil)
}
}这个就是控制反转,不再由控制逻辑 Undo 来依赖业务逻辑 IntSet, 而是由业务逻辑 IntSet 来依赖 Undo. 想看更多的细节可以看 coolshell 的博客
再举两个例子,我们有 lbs 服务,定时更新司机的坐标流,中间需要处理很多业务流程,我们埋了很多 hook 点,业务逻辑只需要对相应的点注册就可以了,新增加业务逻辑无需改动主流程的代码
很多公司在做中台,比如阿里做的大中台,原来各个业务线有自己的业务处理逻辑,每条业务线都有工程师只写各自业务相关的代码。中台化会抽像出共有的流程,每个新的业务只需要配置文件自定义需要的哪些模块即可,这其实也是一种控制反转的思想
小结
上面是我关于 依赖反转、依赖注入、控制反转 的思考,分享给大家,如果有理解错误,有不到位的请指正