深度细节 | Go 的 panic 的秘密都在这
前情提要
关于 panic 的时机,在上篇 [深度细节 | Go 的 panic 的三种诞生方式] 对 panic 总结三种诞生方式:
- 程序猿主动:调用
panic( )函数; - 编译器的隐藏代码:比如除零场景;
- 内核发送给进程信号:比如非法地址访问 ;
三种都归一到 panic( ) 函数的调用,指出 Go 的 panic 只是一个特殊的函数调用,是语言层面的处理。初学 Go 的时候,奇伢心里也常常有些疑问:
- panic 究竟是啥?是一个结构体?还是一个函数?
- 为什么 panic 会让 Go 进程退出的 ?
- 为什么 recover 一定要放在 defer 里面才生效?
- 为什 么 recover 已经放在 defer 里面,但是进程还是没有恢复?
- 为什么 panic 之后,还能再 panic ?有啥影响?
今天便是深入到代码原理,明确解答以上问题。Go 源码版本声明
Go 1.13.5
_panic 数据结构
看看 _panic 的数据结构:
// runtime/runtime2.go
// 关键结构体
type _panic struct {
argp unsafe.Pointer
arg interface{} // panic 的参数
link *_panic // 链接下一个 panic 结构体
recovered bool // 是否恢复,到此为止?
aborted bool // the panic was aborted
}重点字段关注:
link字段:一个指向_panic结构体的指针,表明_panic和_defer类似,_panic可以是一个单向链表,就跟_defer链表一样;recovered字段:重点来了,所谓的_panic是否恢复其实就是看这个字段是否为 true,recover( )其实就是修改这个字段;
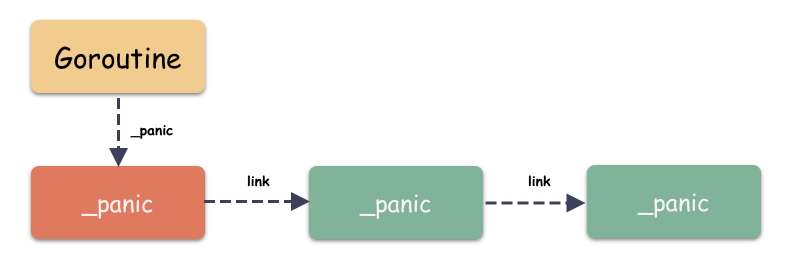
再看一下 goroutine 的两个重要字段:
type g struct {
// ...
_panic *_panic // panic 链表,这是最里的一个
_defer *_defer // defer 链表,这是最里的一个;
// ...
}从这里我们看出:_defer 和 _panic 链表都是挂在 goroutine 之上的。什么时候会导致 _panic 链表上多个元素?
panic( ) 的流程下,又调用了 panic( ) 函数。
这里有个细节要注意了,怎么才能做到 panic( ) 流程里面再次调用 panic( ) ?
划重点:只能是在 defer 函数上,才有可能形成一个 _panic 链表。因为 panic( ) 函数内只会执行 _defer 函数 !
recover 函数
为了方便讲解,我们由简单的开始分析,先看 recover 函数究竟做了什么?
defer func() {
recover()
}()recover 对应了 runtime/panic.go 中的 gorecover 函数实现。
1 gorecover 函数
func gorecover(argp uintptr) interface{} {
// 只处理 gp._panic 链表最新的这个 _panic;
gp := getg()
p := gp._panic
if p != nil && !p.recovered && argp == uintptr(p.argp) {
p.recovered = true
return p.arg
}
return nil
}这个函数可太简单了:
- 取出当前 goroutine 结构体;
- 取出当前 goroutine 的
_panic链表最新的一个_panic,如果是非 nil 值,则进行处理; - 该
_panic结构体的recovered赋值 true,程序返回;
这就是 recover 函数的全部内容,只给 _panic.recovered 赋值而已,不涉及代码的神奇跳转。而 _panic.recovered 的赋值是在 panic 函数逻辑中发挥作用。
panic 函数
panic 的实现在一个叫做 gopanic 的函数,位于 runtime/panic.go 文件。panic 机制最重要最重要的就是 gopanic 函数了,所有的 panic 细节尽在此。为什么 panic 会显得晦涩,主要有两个点:
- 嵌套 panic 的时候,gopanic 会有递归执行的场景;
- 程序指令跳转并不是常规的函数压栈,弹栈,在 recovery 的时候,是直接修改指令寄存器的结构体,从而直接越过了 gopanic 后面的逻辑,甚至是多层 gopanic 递归的逻辑;
一切秘密都在下面这个函数:
// runtime/panic.go
func gopanic(e interface{}) {
// 在栈上分配一个 _panic 结构体
var p _panic
// 把当前最新的 _panic 挂到链表最前面
p.link = gp._panic
gp._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
for {
// 取出当前最近的 defer 函数;
d := gp._defer
if d == nil {
// 如果没有 defer ,那就没有 recover 的时机,只能跳到循环外,退出进程了;
break
}
// 进到这个逻辑,那说明了之前是有 panic 了,现在又有 panic 发生,这里一定处于递归之中;
if d.started {
if d._panic != nil {
d._panic.aborted = true
}
// 把这个 defer 从链表中摘掉;
gp._defer = d.link
freedefer(d)
continue
}
// 标记 _defer 为 started = true (panic 递归的时候有用)
d.started = true
// 记录当前 _defer 对应的 panic
d._panic = (*_panic)(noescape(unsafe.Pointer(&p)))
// 执行 defer 函数
reflectcall(nil, unsafe.Pointer(d.fn), deferArgs(d), uint32(d.siz), uint32(d.siz))
// defer 执行完成,把这个 defer 从链表里摘掉;
gp._defer = d.link
// 取出 pc,sp 寄存器的值;
pc := d.pc
sp := unsafe.Pointer(d.sp)
// 如果 _panic 被设置成恢复,那么到此为止;
if p.recovered {
// 摘掉当前的 _panic
gp._panic = p.link
// 如果前面还有 panic,并且是标记了 aborted 的,那么也摘掉;
for gp._panic != nil && gp._panic.aborted {
gp._panic = gp._panic.link
}
// panic 的流程到此为止,恢复到业务函数堆栈上执行代码;
gp.sigcode0 = uintptr(sp)
gp.sigcode1 = pc
// 注意:恢复的时候 panic 函数将从此处跳出,本 gopanic 调用结束,后面的代码永远都不会执行。
mcall(recovery)
throw("recovery failed") // mcall should not return
}
}
// 打印错误信息和堆栈,并且退出进程;
preprintpanics(gp._panic)
fatalpanic(gp._panic) // should not return
*(*int)(nil) = 0 // not reached
}上面逻辑可以拆分为循环内和循环外两部分去理解:
- 循环内:程序执行 defer,是否恢复正常的指令执行,一切都在循环内决定;
- 循环外:一旦走到循环外,说明
_panic没人处理,认命吧,程序即将退出;
for 循环内
循环内的事情拆解成:
1 . 遍历 goroutine 的 defer 链表,获取到一个 _defer 延迟函数;
2 . 获取到 _defer 延迟函数,设置标识 d.started,绑定当前 d._panic(用以在递归的时候判断);
3 . 执行 _defer 延迟函数;
4 . 摘掉执行完的 _defer 函数;
5 . 判断 _panic.recovered 是否设置为 true,进行相应操作;
a . 如果是 true 那么重置 pc,sp 寄存器(一般从 deferreturn 指令前开始执行),goroutine 投递到调度队列,等待执行;
6 . 重复以上步骤;
1 思考问题有答案了!你会发现,更改 recovered 这个字段的时机只有在第三个步骤的时候。在任何地方,你都改不到 _panic.recovered 的值。
问题一:为什么 recover 一定要放在 defer 里面才生效?
因为,这是唯一的修改 _panic.recovered 字段的时机 !
举几个对比的栗子:
func main() {
panic("test")
recover()
}上面的例子调用了 recover( ) 为什么还是 panic ?
因为根本执行不到 recover 函数,执行顺序是:
panic
gopanic
执行 defer 链表
exit有童鞋较真,那我把 recover() 放 panic("test") 前面呗?
func main() {
recover()
panic("test")
}不行,因为执行 recover 的时候,还没有 _panic 挂在 goroutine 上面呢,recover 了个寂寞。
问题二:为什么 recover 已经放在 defer 里面,但是进程还是没有恢复?
回忆一下上面 for 循环的操作:
// 步骤:遍历 _defer 链表
d := gp._defer
// 步骤:执行 defer 函数
reflectcall(nil, unsafe.Pointer(d.fn), deferArgs(d), uint32(d.siz), uint32(d.siz))
// 步骤:执行完成,把这个 defer 从链表里摘掉;
gp._defer = d.link划重点:在 gopanic 里,只遍历执行当前 goroutine 上的 _defer 函数链条。所以,如果挂在其他 goroutine 的 defer 函数做了 recover ,那么没有丝毫用途。
举一个栗子:
func main() { // g1
go func() { // g2
defer func() {
recover()
}()
}()
panic("test")
}因为,panic 和 recover 在两个不同的 goroutine,_panic 是挂在 g1 上的,recover 是在 g2 的 _defer 链条里。
gopanic 遍历的是 g1 的 _defer 函数链表,跟 g2 八杆子打不着,g2 的 recover 自然拿不到 g1 的 _panic 结构,自然也不能设置 recovered 为 true ,所以程序还是崩了。
问题三:为什么 panic 之后,还能再 panic ?有啥影响?
这个其实很容易理解,有些童鞋可能想复杂了。gopanic 只是一个函数调用而已,那函数调用为啥不能嵌套递归?
当然可以。
触发的场景一般是:
gopanic函数调用_defer延迟函数;defer延迟函数里面又调用了panic/gopanic函数;
这不就有了嘛,就是个简单的函数嵌套而已,没啥不可以的,并且在这种场景下,_panic 结构体就会从 gp._panic 开始形成了一个链表。
而 gopanic 函数指令执行的特殊在于两点:
_panic被人设置成 recovered 之后,重置 pc,sp 寄存器,直接跨越 gopanic (还有嵌套的函数栈),跳转到正常业务流程中;- 循环之外,等到最后,没人处理
_panic数据,那就 exit 退出进程,终止后续所有指令的执行;
举个嵌套的栗子:
func main() {
defer func() { // 延迟函数
panic("panic again")
}()
panic("first")
}函数执行:
gopanic
defer 延迟函数
gopanic
无 defer 延迟函数(递归往上),终止条件达成
// 打印堆栈,退出程序
fatalpanic童鞋你理解了吗?下面就来考考你哦。看一个栗子:
func main() {
println("=== begin ===")
defer func() { // defer_0
println("=== come in defer_0 ===")
}()
defer func() { // defer_1
recover()
}()
defer func() { // defer_2
panic("panic 2")
}()
panic("panic 1")
println("=== end ===")
}上面的函数会出打印堆栈退出进程吗?
答案是:不会。 猜一下输出是啥?终端输出结果如下:
➜ panic ./test_panic
=== begin ===
=== come in defer_0 ===你猜对了吗?奇伢给你梳理了一下完整的路线:
main
gopanic // 第一次
1. 取出 defer_2,设置 started
2. 执行 defer_2
gopanic // 第二次
1. 取出 defer_2,panic 设置成 aborted
2. 把 defer_2 从链表中摘掉
3. 执行 defer_1
- 执行 recover
4. 摘掉 defer_1
5. 执行 recovery ,重置 pc 寄存器,跳转到 defer_1 注册时候,携带的指令,一般是跳转到 deferreturn 上面几个指令
// 跳出 gopanic 的递归嵌套,直接到执行 deferreturn 的地方;
defereturn
1. 执行 defer 函数链,链条上还剩一个 defer_0,取出 defer_0;
2. 执行 defer_0 函数
// main 函数结束再来一个对比的例子:
func main() {
println("=== begin ===")
defer func() { // defer_0
println("=== come in defer_0 ===")
}()
defer func() { // defer_1
panic("panic 2")
}()
defer func() { // defer_2
recover()
}()
panic("panic 1")
println("=== end ===")
}上面的函数会打印堆栈,并且退出吗?
答案是:会。输出如下:
➜ panic ./test_panic
=== begin ===
=== come in defer_0 ===
panic: panic 2
goroutine 1 [running]:
main.main.func2()
/Users/code/gopher/src/panic/test_panic.go:9 +0x39
main.main()
/Users/code/gopher/src/panic/test_panic.go:11 +0xf7奇伢给你梳理的执行路径如下:
main
gopanic // 第一次
1. 取出 defer_2,设置 started
2. 执行 defer_2
- 执行 recover,panic_1 字段被设置 recovered
3. 把 defer_2 从链表中摘掉
4. 执行 recovery ,重置 pc 寄存器,跳转到 defer_1 注册时候,携带的指令,一般是跳转到 deferreturn 上面几个指令
// 跳出 gopanic 的递归嵌套,执行到 deferreturn 的地方;
defereturn
1. 遍历 defer 函数链,取出 defer_1
2. 摘掉 defer_1
2. 执行 defer_1
gopanic // 第二次
1. defer 链表上有个 defer_0,取出来;
2. 执行 defer_0 (defer_0 没有做 recover,只打印了一行输出)
3. 摘掉 defer_0,链表为空,跳出 for 循环
3. 执行 fatalpanic
- exit(2) 退出进程你猜对了吗?
2 recovery 函数最后,看一下关键的 recovery 函数。在 gopanic 函数中,在循环执行 defer 函数的时候,如果发现 _panic.recovered 字段被设置成 true 的时候,调用 mcall(recovery) 来执行所谓的恢复。
看一眼 recovery 函数的实现,这个函数极其简单,就是恢复 pc,sp 寄存器,重新把 Goroutine 投递到调度队列中。
// runtime/panic.go
func recovery(gp *g) {
// 取出栈寄存器和程序计数器的值
sp := gp.sigcode0
pc := gp.sigcode1
// 重置 goroutine 的 pc,sp 寄存器;
gp.sched.sp = sp
gp.sched.pc = pc
// 重新投入调度队列
gogo(&gp.sched)
}重置了 pc,sp 寄存器代表什么意思?
pc 寄存器指向指令所在的地址,换句话说,就是跳转到其他地方执行指令去了。而不是顺序执行 gopanic 后面的指令了,补回来了。
_defer.pc 的指令行,这个指令是哪里?
这个要回忆一下 defer 的章节,defer 注册延迟函数的时候对应一个 _defer 结构体,在 new 这个结构体的时候,_defer.pc 字段赋值的就是 new 函数的下一行指令。这个在 [Golang 最细节篇 — 解密 defer 原理,究竟背着程序猿做了多少事情?] 详细说过。
举个例子,如果是栈上分配的话,那么在 deferprocStack ,所以,mcall(recovery) 跳转到这个位置,其实后续就走 deferreturn 的逻辑了,执行后续的 _defer 函数链。
本次 panic 就到此为止,相当于就恢复了程序的正常运行。
当然,如果后续在 defer 函数里面又出现 panic ,那可能形成一个 _panic 的链条,但是每一个的处理还是一样的。
划重点:函数的 call,ret 是最常见的指令跳转。最本源的就是 pc 寄存器,函数压栈,出栈的时候,修改的也是 pc 寄存器,**在 recovery 流程里,则来的更直接一点,直接改 pc ,sp。**
for 循环外
走到 for 循环外,那程序 100% 要退出了。因为 fatalpanic 里面打印一些堆栈信息之后,直接调用 exit 退出进程的。到这已经没有任何机会了,只能乖乖退出进程。
退出的调用就在 fatalpanic 里:
func fatalpanic(msgs *_panic) {
// 1. 打印协程堆栈
// 2. 退出进程
systemstack(func() {
exit(2)
})
*(*int)(nil) = 0 // not reached
}所以这个问题清楚了嘛:为什么 panic 会让 Go 进程退出的 ?
还能为啥,因为调用了 exit(2) 嘛。
总结
panic()会退出进程,是因为调用了 exit 的系统调用;recover()并不是说只能在 defer 里面调用,而是只能在 defer 函数中才能生效,只有在 defer 函数里面,才有可能遇到_panic结构;recover()所在的 defer 函数必须和 panic 都是挂在同一个 goroutine 上,不能跨协程,因为gopanic只会执行当前 goroutine 的延迟函数;- panic 的恢复,就是重置 pc 寄存器,直接跳转程序执行的指令,跳转到原本 defer 函数执行完该跳转的位置(
deferreturn执行),从gopanic函数中跳出,不再回来,自然就不会再fatalpanic; - panic 为啥能嵌套?这个问题就像是在问为什么函数调用可以嵌套一样,因为这个本质是一样的。
后记
**panic 就是一个函数调用,没啥特殊的。