BPF、eBPF、XDP 和 Bpfilter……这些东西是什么?
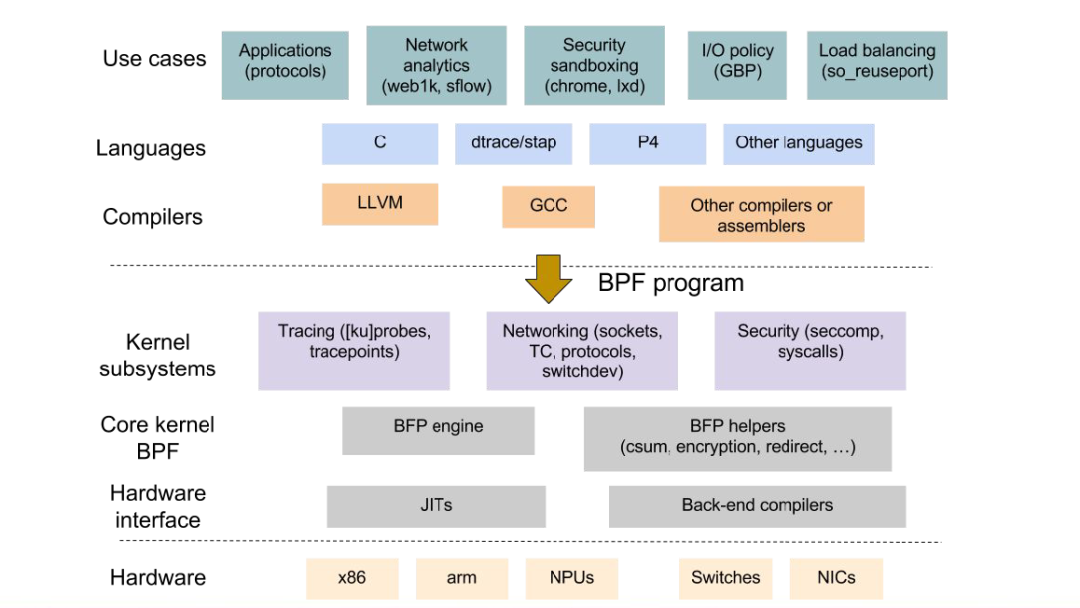
从 Linux 内核3.15 开始,您可能一直在关注内核社区中扩展的 Berkeley Packet Filter (eBPF) 的开发,或者您可能仍然将 Berkeley Packet Filter 与 Van Jacobson 在 1992 年所做的工作联系起来。您可能已经使用 BPF 和 tcpdump 多年,或者您可能已经开始在您的数据平面中探测它!本博客旨在从高性能网络的角度在高层次上描述BPF的关键发展,以及为什么它对网络运营商、系统管理员和企业解决方案提供商变得越来越重要。
BPF 或 eBPF——有什么区别?
虚拟机
从根本上说,eBPF 仍然是 BPF:它是一个小型虚拟机,它从用户空间注入并附加到内核中特定钩子的程序。它可以对网络数据包进行分类和操作。多年来,它一直在 Linux 上用于过滤数据包并避免将昂贵的副本复制到用户空间,例如使用 tcpdump。但是,在过去几年中,虚拟机的范围已经变得面目全非。
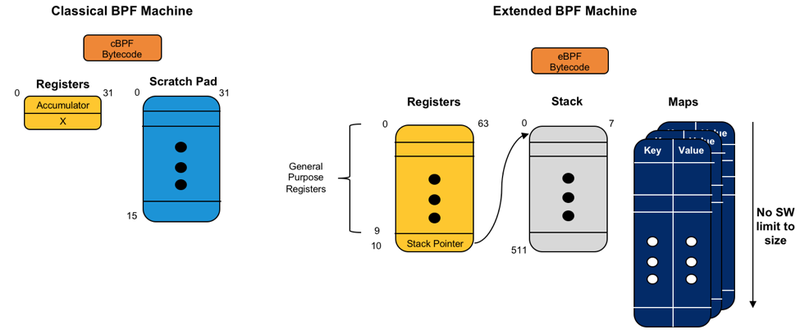
图 1. cBPF 与 eBPF 机器的比较
经典 BPF (cBPF),旧版本,由一个 32 位宽累加器、一个 32 位宽“X”寄存器(也可以在指令中使用)和 16 个 32 位寄存器(用作暂存存储器)组成. 这显然导致了一些关键的限制。顾名思义,经典的伯克利数据包过滤器主要限于(无状态)数据包过滤。任何更复杂的事情都将在其他子系统中完成。
eBPF 通过使用一组扩展的寄存器和指令、添加映射(没有大小限制的键/值存储)、512 字节堆栈、更复杂的查找、帮助程序,显着拓宽了 BPF 的用例集可从程序内部调用的函数,以及链接多个程序的可能性。现在可以进行状态处理,也可以与用户空间程序进行动态交互。由于这种灵活性的提高,eBPF 处理的数据包的分类级别和可能的交互范围得到了极大的扩展。
但新功能不能以牺牲安全为代价。为确保正确行使 VM 增加的责任,内核中实施的验证程序已被修订和整合。这个验证器检查代码中的任何循环(这可能导致可能的无限循环,从而挂起内核)和任何不安全的内存访问。它拒绝任何不符合安全标准的程序。每次用户尝试注入程序时,都会在实时系统上执行此步骤,然后将 BPF 字节码 JIT 转换为所选平台的本机汇编指令。
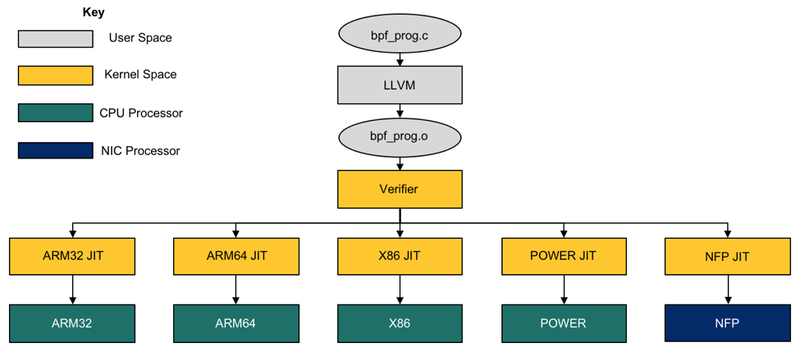
图 2. 主机上 eBPF 程序的编译流程。一些CPU架构没有显示。
为了允许在 eBPF 的限制内难以执行或优化的任何关键功能,有许多帮助程序旨在协助执行过程,例如地图查找或随机数的生成。我的同事 Quentin Monnet 目前正在完成记录所有内核助手的过程,并准备了一个补丁供审查。
钩子 - 数据包在哪里分类?
由于其灵活性和实用性,eBPF 的钩子数量正在激增。但是,我们将重点关注数据路径低端的那些。这里的关键区别在于 eBPF 在驱动程序空间中添加了一个额外的钩子。此挂钩称为 eXpress DataPath,或 XDP。这允许用户在将 skb(套接字缓冲区)元数据结构添加到数据包之前丢弃、反射或重定向数据包。这导致性能提高约 4-5 倍。
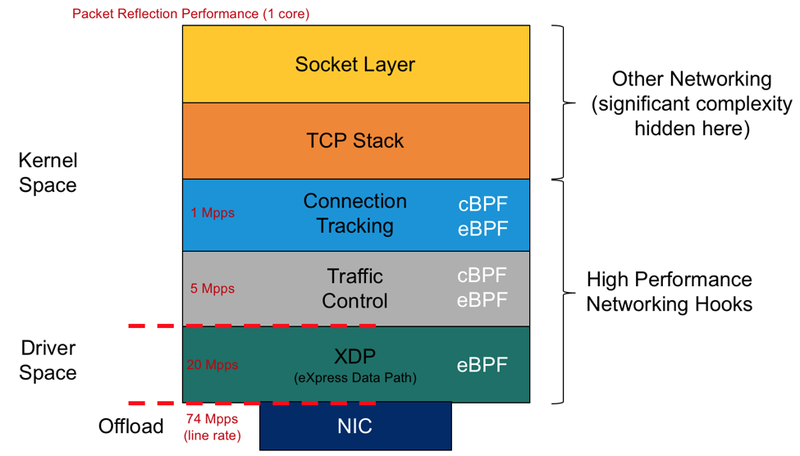
图 3. 高性能网络相关 eBPF 钩子性能比较
将 eBPF 卸载到 NFP
回到 4.9,我的同事和我们的内核驱动程序维护者 Jakub Kicinski 将网络流处理器 (NFP) BPF JIT 编译器添加到内核中,最初用于 cls_bpf ( https://www.spinics.net/lists/netdev/msg379464 .html)。从那时起,Netronome 一直致力于改进内核和 LLVM 中的 BPF 基础设施,它生成字节码(感谢 Jiong Wang 的工作)。通过 NFP JIT,我们设法有效地修改了程序流程,如下图所示:
图 4. 包含 NFP JIT 的编译流程(未显示某些支持的 CPU 架构)
这是可能的关键原因是因为 BPF 机器映射到我们 NFP 上的流处理核心的程度,这意味着运行在 15-25W 之间的基于 NFP 的 Agilio CX SmartNIC 可以从主机卸载大量处理. 在下面的负载平衡示例中,NFP 处理的数据包数量与来自主机的近 12 个 x86 内核的总和相同,由于 PCIe 带宽限制(使用的内核:Intel Xeon CPU E5-2630 v4 @ 2.20GHz)。
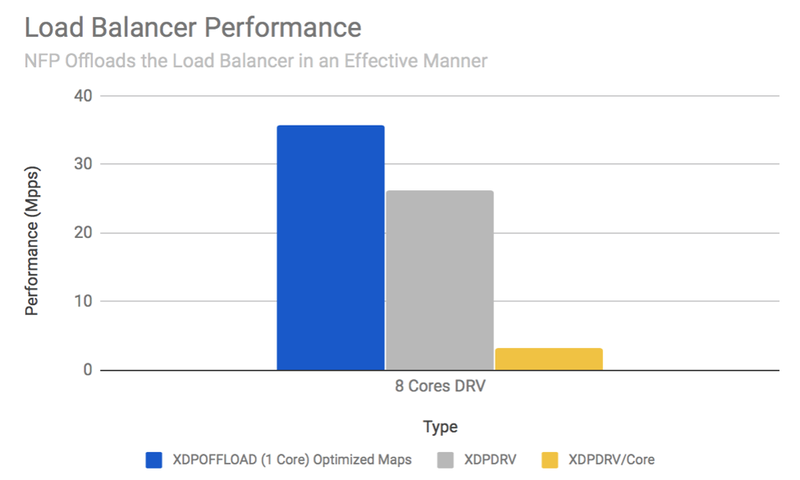
图 5. NFP 和 x86 CPU (E5-2630 v4) 上的示例负载平衡器的比较性能
性能是使用 BPF 硬件卸载是对 SmartNIC 进行编程的正确技术的主要原因之一。但它不是唯一的:让我们回顾一些其他的激励措施。
1 . 灵活性:BPF 在主机上提供的主要优势之一是能够即时重新加载程序。这使得在运行的数据中心中动态替换程序成为可能。可能是树外内核代码或插入其他一些不太灵活的子系统的代码现在可以轻松加载或卸载。由于不需要系统重新启动的错误,这为数据中心提供了显着的优势:相反,只需重新加载调整后的程序即可。
这个模型现在也可以扩展到卸载。用户可以在流量运行时动态加载、卸载、重新加载 NFP 上的程序。这种在运行时动态重写固件提供了一个强大的工具来被动地使用 NFP 的灵活性和性能。
2 . 延迟:通过卸载 eBPF,由于数据包不必跨越 PCIe 边界,延迟显着减少。这可以改善负载平衡或 NAT 用例的网络卫生。请注意,通过避免 PCIe 边界,在 DDoS 预防案例中也有显着的好处,因为数据包不再跨越边界,否则可能会在构造良好的 DDoS 攻击下形成瓶颈。
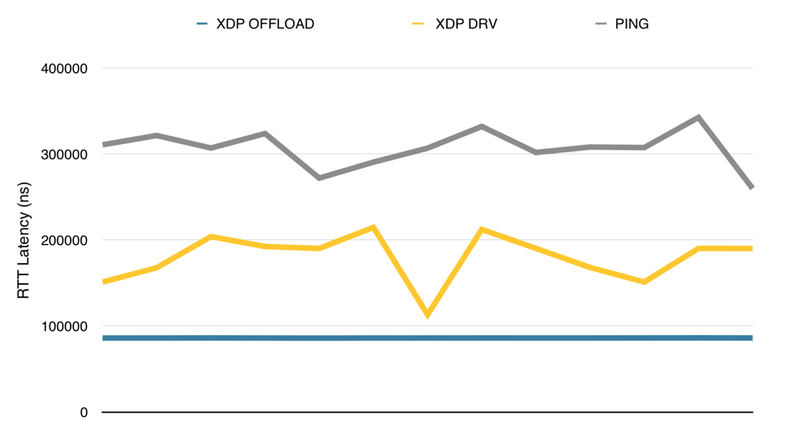
图 6. 驱动程序中卸载的 XDP 与 XDP 的延迟,注意使用卸载时延迟的一致性
3 . 用于对 SmartNIC 数据路径进行编程的接口:通过能够使用 eBPF 对 SmartNIC 进行编程,这意味着可以非常轻松地实现诸如速率限制、数据包过滤、不良行为者缓解或其他传统 NIC 必须在硅片中实现的功能. 这可以针对最终用户的特定用例进行定制。
我如何实际使用它?
首先要做的是将内核更新到 4.16 或更高版本。我建议使用 4.17(撰写本文时的开发版本)或更高版本以利用尽可能多的功能。请参阅用户指南以获取最新版本的功能以及如何使用它们的示例。
在此不赘述,还可以注意到与 eBPF 工作流相关的工具正在开发中,并且相对于旧的 cBPF 版本已经有了很大的改进。用户现在通常会用 C 编写程序,然后使用 clang-LLVM 提供的后端将它们编译成 eBPF 字节码。也可以使用其他语言,包括 Go、Rust 或 Lua。传统工具中添加了对 eBPF 架构的支持:llvm-objdump 可以以人类可读的格式转储 eBPF 字节码,llvm-mc 可以用作 eBPF 汇编器,strace 可以跟踪对 bpf() 系统调用的调用。其他工具的一些工作仍在进行中:binutils 反汇编器应该很快就会支持 NFP 微码,而 valgrind 即将获得对系统调用的支持。还创建了新工具:特别是 bpftool,
过滤器
对于企业系统管理员或 IT 架构师而言,此时仍然悬而未决的一个关键问题是,这如何适用于拥有已完善和维护多年且基于 iptables 的设置的最终用户。更改此设置的风险在于,显然,某些事情可能令人难以接受,必须修改编排层,应该构建新的 API,等等。要解决此问题,请输入建议的 bpfilter 项目。正如昆汀今年早些时候所写:
“这项技术是针对 Linux 中 iptables 防火墙的新的基于 eBPF 的后端的提议。在撰写本文时,它还处于非常早期的阶段:它在 2018 年 2 月中旬左右由 David Miller(网络系统维护者)、Alexei Starovoitov 和 Daniel 在 Linux netdev 邮件列表上作为 RFC(征求意见)提交Borkmann(内核中 BPF 部分的维护者)。因此,请记住,随后的所有细节都可能发生变化,或者根本无法到达内核!
从技术上讲,用于配置防火墙的 iptables 二进制文件将保持不变,而内核中的 xtables 部分可以透明地替换为一组新命令,这些命令需要 BPF 子系统将防火墙规则转换为 eBPF 程序。然后可以将此程序附加到与网络相关的内核挂钩之一,例如在流量控制接口 (TC) 或驱动程序级别 (XDP) 上。规则转换将发生在一种新的内核模块中,它介于传统模块和普通 ELF 用户空间二进制文件之间。运行在具有完全权限但不能直接访问内核的特殊线程中,从而提供较少的攻击面,这种特殊类型的模块将能够直接与 BPF 子系统通信(主要通过系统调用)。而与此同时,使用标准的用户空间工具来开发、调试甚至模糊它仍然非常容易!除了这个新的模块对象之外,bpfilter 方法的好处可能很多。由于 eBPF 验证器,预计会提高安全性。重用 BPF 子系统可能会使这个组件的维护比遗留 xtables 更容易,并且可能提供与内核的其他组件的后续集成,这些组件也依赖于 BPF。当然,利用即时 (JIT) 编译或可能的程序硬件卸载可以显着提高性能!”
bpfilter 正在被开发作为该问题的解决方案。它允许最终用户无缝地迁移到这种新的高性能范例。将 CPU 的 8 个内核和卸载与一系列简单的 iptables 规则的 NFP 与 iptables (netfilter) 传统后端、较新的 nftables、主机上的 bpfilter 和卸载到 SmartNIC 进行比较,清楚地显示了性能所在.
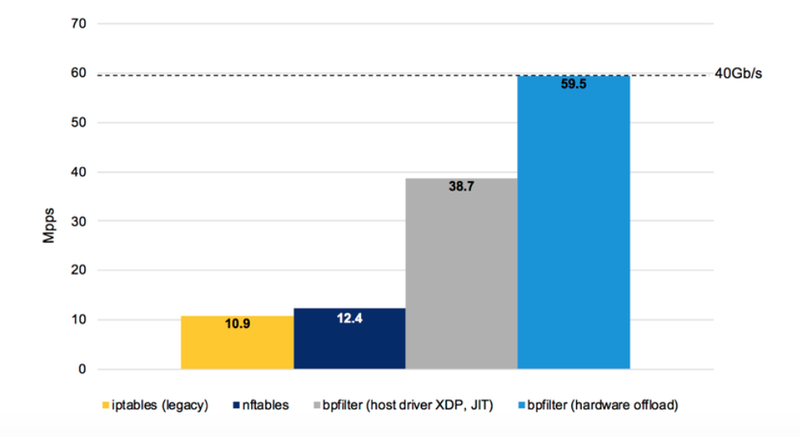
图 7. bpfilter 与旧 iptables 实现的性能比较
概括
因此有它后,内核社区网络方面产生了巨大转变。eBPF 是一个强大的工具,它为内核带来了可编程性,它可以处理拥塞控制(TCP-BPF)、跟踪(kprobes、tracepoints)和高性能网络(XDP、cls_bpf)。由于其在社区中的成功,其他用例可能也会出现。除此之外,也会一直持续到最终用户,他们能够很快平滑地从旧的 iptables 后端,转而使用更新的、更高效的基于 XDP 的后端——使用与今天相同的工具。特别是,这将允许直接的硬件卸载,并在用户迁移到 10G 及以上网络时提供必要的灵活性。