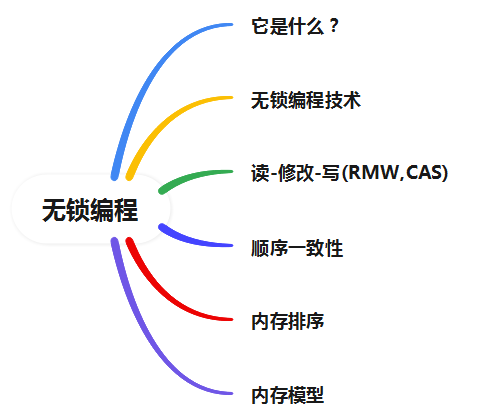
深入理解无锁编程
hi,大伙好,今天介绍一下无锁编程基础知识,希望大家可以了解无锁编程基本原理。
无锁编程是一个挑战,不仅因为任务本身的复杂性,还因为从一开始就很难深入了解这个主题,因为该主题和底层技术(编译器,CPU,内存)息息相关,需要深厚底层功底。
我学习无锁编程是Bruce Dawson 出色而全面的白皮书Lockless Programming Considerations(无锁编程的思考)。和许多技术一样,需要将理论付诸实践,在平台上开发和调试无锁代码。
在这篇文章中,我想重新介绍无锁编程,首先是定义它,然后将大部分信息提炼为几个关键概念。我将使用流程图展示这些概念如何相互关联,然后我们将深入研究细节。至少,任何从事无锁编程的程序员都应该已经了解如何使用互斥锁和其他高级同步对象(如信号量和事件)编写正确的多线程代码。
它是什么?
人们通常将无锁编程描述为没有互斥锁的编程,互斥锁也称为锁。这是真的,但这只是故事的一部分。基于学术文献的普遍接受的定义更广泛一些。从本质上讲,无锁是一种用于描述某些代码的属性,而无需过多说明该代码的实际编写方式。
基本上,如果您的程序的某些部分满足以下条件,那么该部分可以理所当然地被认为是无锁的。相反,如果代码的给定部分不满足这些条件,则该部分不是无锁的。
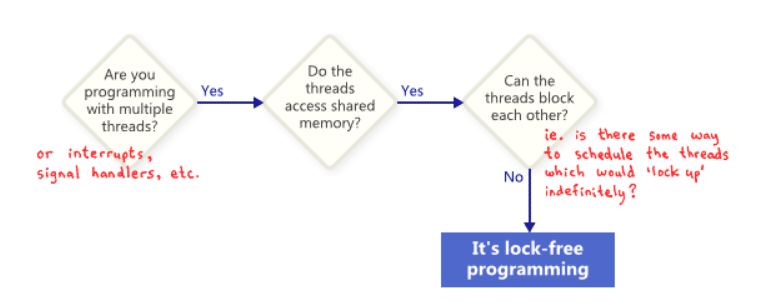
从这个意义上说,无锁中的锁并不直接指互斥锁,而是指以某种方式“锁定”整个应用程序的可能性,无论是死锁、活锁——甚至是由于由你最大的敌人。最后一点听起来很有趣,但这是关键。共享互斥锁被简单地排除在外,因为一旦一个线程获得互斥锁,您最大的敌人就再也不会调度该线程了。当然,真正的操作系统不是这样工作的——我们只是定义术语。
这是一个不包含互斥锁但仍然不是无锁的操作的简单示例。最初,X = 0。作为读者的练习,考虑如何以一种方式调度两个线程,使得两个线程都不退出循环。
while(X == 0 ) {
X = 1 - X;
}没有人期望大型应用程序是完全无锁的。通常,我们从整个代码库中识别出一组特定的无锁操作。例如,在一个无锁队列中,有可能是无锁的操作,比如极少数的push,pop也许isEmpty等。

Herlihy & Shavit 是The Art of Multiprocessor Programming(多处理器编程的艺术) 的作者,倾向于将此类操作表示为类方法,并提供以下无锁的简洁定义:
“在无限执行中,某些方法调用会无限频繁地结束”
换句话说,只要程序能够继续调用那些无锁操作,无论发生什么,完成的调用次数都会不断增加。在这些操作期间,系统在算法上不可能锁定。
无锁编程的一个重要结论是,如果您挂起单个线程,它永远不会阻止其他线程作为一个组通过它们自己的无锁操作取得进展。这暗示了在编写中断处理程序和实时系统时无锁编程的价值,其中某些任务必须在一定的时间限制内完成,无论程序的其余部分处于什么状态。
最后一个说明:某些操作被设计为阻塞的并不意味是这就不是Lock-Free的。例如,当队列为空时,队列的弹出操作可能会故意阻塞。其余的代码路径仍然可以被认为是无锁的。
无锁编程技术
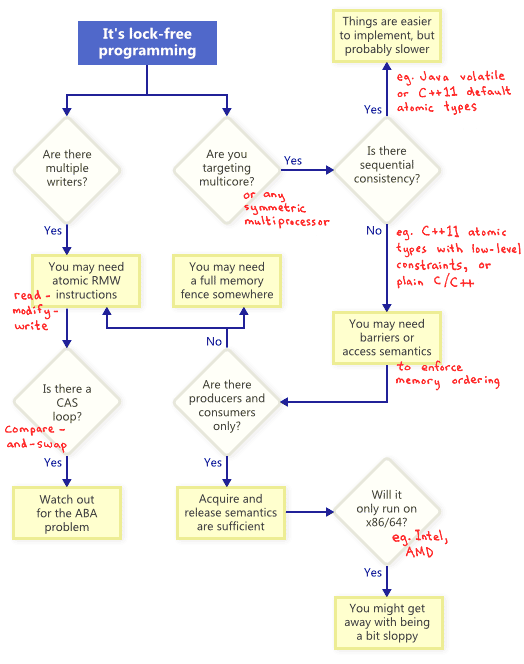
事实证明,当您尝试满足无锁编程的非阻塞条件时,会出现一整套技术:原子操作、内存屏障、避免 ABA 问题,仅举几例。这就是事情很快变得邪恶的地方。
那么这些技术如何相互关联呢?为了说明,我整理了以下流程图。下面我将逐一详述。
原子读-修改-写操作
原子操作是以一种看起来不可分割的方式操作内存的操作:没有线程可以观察到半完成的操作。在现代处理器上,许多操作已经是原子的。例如,简单类型的对齐读取和写入通常是原子的。
读-修改-写(RMW) 操作更进一步,允许您以原子方式执行更复杂的事务。当无锁算法必须支持多个写入器时,它们特别有用,因为当多个线程在同一地址上尝试 RMW 时,它们将有效地排成一行并一次执行这些操作。我已经在这篇博客中谈到了 RMW 操作,例如实现轻量级互斥锁、递归互斥锁和轻量级日志系统时。
RMW 操作的示例包括_InterlockedIncrementWin32、OSAtomicAdd32iOS 和std::atomic
::fetch_addC++11。请注意,C++11 原子标准并不能保证实现在每个平台上都是无锁的,因此最好了解您的平台和工具链的功能。你可以使用std::atomic<>::is_lock_free确认一下。
不同的 CPU 系列以不同的方式支持 RMW。诸如 PowerPC 和 ARM 之类的处理器公开了load-link/store-conditional)条件指令,这有效地允许您在低级别实现自己的 RMW 原语,尽管这并不常见。常见的 RMW 操作通常就足够了。
如流程图所示,即使在单处理器系统上,原子 RMW 也是无锁编程的必要部分。如果没有原子性,线程可能会在事务中途中断,从而可能导致状态不一致。
Compare-And-Swap Loops
也许最常讨论的 RMW 操作是compare-and-swap**(CAS)**。在 Win32 上,CAS 是通过一系列内在函数提供的,例如_InterlockedCompareExchange. 通常使用 CAS Loops 来完成对事务的原子处理:
void LockFreeQueue::push(Node* newHead)
{
for (;;)
{
// Copy a shared variable (m_Head) to a local.
Node* oldHead = m_Head;
// Do some speculative work, not yet visible to other threads.
newHead->next = oldHead;
// Next, attempt to publish our changes to the shared variable.
// If the shared variable hasn't changed, the CAS succeeds and we return.
// Otherwise, repeat.
if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead)
return;
}
}这样的循环仍然符合无锁的条件,因为如果一个线程的测试失败,则意味着它必须在另一个线程上成功——尽管某些架构提供了CAS的较弱变体,而这不一定是真的。每当实现 CAS 循环时,必须特别注意避免ABA 问题。
顺序一致性
顺序一致性是指所有线程都同意内存操作发生的顺序,并且该顺序与程序源代码中的操作顺序一致。
实现顺序一致性的一种简单(但显然不切实际)的方法是禁用编译器优化并强制所有线程在单个处理器上运行。处理器永远不会看到它自己的内存效果出问题,即使线程在任意时间被抢占和调度。
一些编程语言即使对于在多处理器环境中运行的优化代码也提供顺序一致性。在 C++11 中,您可以将所有共享变量声明为具有默认内存排序约束的 C++11 原子类型。在 Java 中,您可以将所有共享变量标记为volatile. 这是我上一篇文章中的示例,以 C++11 风格重写:
std::atomic< int > X( 0 ), Y( 0 );
int r1, r2;
void thread1()
{
X.store( 1 );
r1 = Y.load();
}
void thread2()
{
Y.store( 1 );
r2 = X.load();
}
因为 C++11 原子类型保证顺序一致性,结果 r1 = r2 = 0 是不可能的。为了实现这一点,编译器会在幕后输出额外的指令——通常是内存栅栏和/或 RMW 操作。与程序员直接处理内存排序的指令相比,这些附加指令可能会降低实现的效率。
内存排序
正如流程图所暗示的那样,任何时候您对多核(或任何对称多处理器)进行无锁编程,并且您的环境不保证顺序一致性,您必须考虑如何防止内存重新排序。
在当今的体系结构中,强制执行正确内存排序的工具通常分为三类,它们可以防止编译器重新排序和处理器重新排序:
- 轻量级同步或栅栏指令;
- 一个完整的内存栅栏指令;
- 提供获取或释放语义的内存操作。
获取语义防止在程序顺序中跟随它的操作的内存重新排序,并且释放语义防止在它之前的操作的内存重新排序。这些语义特别适用于存在生产者/消费者关系的情况,即一个线程发布一些信息而另一个线程读取它。
不同的处理器有不同的内存模型
不同的 CPU 系列在内存重新排序方面有不同的习惯。这些规则由每个 CPU 供应商记录,并由硬件严格遵守。例如,PowerPC 和 ARM 处理器可以更改相对于指令本身的内存存储顺序,但通常情况下,Intel 和 AMD 的 x86/64 系列处理器不会。我们说前者的处理器具有更宽松的内存模型。
人们很容易抽象出这些特定于平台的细节,尤其是 C++11 为我们提供了一种编写可移植无锁代码的标准方法。但是目前,我认为大多数无锁程序员至少对平台差异有一些了解。如果要记住一个关键区别,那就是在 x86/64 指令级别,每次从内存加载都带有获取语义,并且每次存储到内存都提供释放语义——至少对于非 SSE 指令和非写组合内存. 因此,过去常常编写能在x86/64 上运行成功但在其他处理器上失败的无锁代码。
如果你对处理器需要内存排序的硬件细节感兴趣,我推荐附录的并行编程困难吗? 请记住在任何情况下,由于编译器指令重排序也会导致内存重新排序。
在这篇文章中,我没有过多地谈论无锁编程的实际方面,例如:我们什么时候做?我们真正需要多少?我也没有提到验证无锁算法的重要性。尽管如此,我希望对于一些读者来说,这篇介绍已经提供了对无锁概念的基本熟悉,因此您可以继续深入阅读其他文章而不会感到太困惑。