从微信后端仓库发展史谈谈单仓和多仓
最近某些代码大仓的思想风靡整个 DevOps 圈子,这里的所谓大仓指的并不是仓库的代码容量达到多少 G,而是一种指导思想——就一个公司的代码(如 Google)的增长趋势,代码的趋近于整合到一个单一的仓库的,而非趋于分割为多个仓库分开存储的。但除了 Google、Microsoft 这些历史悠久的公司实践了大仓,其它的新兴公司几乎都没有一个划分仓库的规则。 本文从微信后端的代码仓储方式的历史说起,一步步的描述微信后端是如何构建一套真实可用的小仓方案的,并将这样一种分仓的方法分享出来,希望实践微服务的同事们有所帮助。
其实或许不应该使用小仓这个词来描述当前微信后端的代码组织方式,就占用空间而言,微信后端的某些仓库从体积上来说并不算得上是小 ,微信支付后端的旧代码仓库项目截止 2021-08-23 已使用了超过 2T 的存储空间。这里使用小仓这个词汇实际上对应英语中的 multirepo 或 polyrepo,也就是相对于单仓 monorepo 概念中的多仓。
本文中所描述的仓库的大小划分并不是按照其占用空间划分,而是提供一种划分代码仓库的思想:
- 代码仓库应该是被合理划分的,而非全公司共用的一个 repo(对应 monorepo)
- 代码仓库的划分应该是有标准的(对应下文的一致性 )
- 代码仓库所使用的工具链应该不和代码的组织结构强相关,甚至不应该和版本管理工具强耦合
- 小仓应该是一个完整的包含代码的完整构建单元,包括但不限于实现代码、单元测试用例、自动生成的代码报告(如覆盖率、用例执行结果)、代码相关的说明文件(README.md)、构建配置文件(BUILD、package.json 等)
本文将从微信后端的代码仓库的发展历史开始,逐个分析微信后端代码的演化过程,试图从大仓逐渐分解成小仓的历史进程来解构小仓研发流程的客观规律,并最终提出小仓的整体解决方案。欢迎提出任何理性的讨论和建议。
1 微信后端代码仓库发展史
以人为鉴可以知得失,以史为鉴可以知兴替。
了解微信后端的开发都知道,微信这个项目启动的非常偶然,微信最初来源于广州研发部的一个创意,微信后端天生就继承了 QQ 邮箱非常多的代码。你仔细研究代码就会发现,在很多部署的路径中都是用了 QQMail 这样的 hardcode(当然现在并不推荐这样做)。这里就来先回顾一下后端代码仓库的发展历史。
1.1 单一svn仓时代 (2011~2013)
最开始的年代微信后台是直接复制了一份邮箱的代码然后在上面修改的,当时的微信后端代码是一个单仓其中的代码示意结构如下。

大部分的代码都是原封不动的从 QQ 邮箱复制过来,只是创建一个新的 svn 仓库用于编写业务代码,可是由于业务的快速发展,代码的管理也处出现了一些不和谐的音符。
- 刚开始大家都只把代码仓库当成一个放东西的地方,甚至是有些正式数据都放在了仓库上;
- 公众平台项目随后大爆发,某些不属于微信基础后端的代码(如公共平台的代码)也被放置到此仓库下,但新增的微信基础团队却不应该有权限能看到到公众平台的代码;
- 由于是基于 SVN 的大仓模式存储代码,导致核心仓库的代码权限审批特别复杂,只有非常少数的人有通用公共组件、通用后端框架的权限,导致有理想的新人非常难对基础库贡献代码,无奈之下只能将一些业务的公共库被放置在业务代码下,而这些公共函数最后又被吸收到公共组件文件夹中,以至于代码重复;
- 新人并不是不想共享代码,而是疲于各种流程的审批、代码仓库权限的扯皮,最终这些流程打消的他们的积极性,同时他又不希望自己业务卡住不上线,所以只能找一个自己有权限放代码的地方,最终导致代码结构的混乱,而这也正是大仓非常难解决的难题。大仓的权限控制是集中的,在集中的文件夹审批过程中,有理想的开发者压根就不肯让出自己宝贵的时间和权限的审批人员相互扯皮;
- 导致代码重复的根本原因不是胡乱放置的第三方库,而是散落在业务代码仓库的各种公共逻辑的私有化实现。
由于没有统一构建系统,变更一个微服务的基本流程是野蛮的。
- 在本机调试好代码后上传到 svn;
- 在一台专用的编译机上更新 svn;
- 使用魔改版的 blade 编译 release 版本的二进制;
- 如果要发配置、前端页面模板,需要手动将文本文件
scp到编译机上(当然你也可以把开发版本的二进制直接scp到编译机上,省掉1,2,3); - 去微信运维门户提交发布单,告诉发布系统需要更新那些文件,需要重启那些服务;
- 微信运维门户发布到预发布环境;
- 灰度→全量上线。
单元测试全凭自觉,上线前也不会跑 cc_test,所以不写单元测试也没关系,就是这么野蛮。
1.2 拆分svn时代 (2013~2018)
随着业务的成长,在单一 svn 仓库逐渐不满足的业务的开发了,2013 年左右逐渐开始将非微信基础核心的业务部门的代码,从 MicroMsg_proj 仓拆出去。各个业务团队如微信支付、开放平台基础部、开放平台业务部、微信游戏等都有了自己的仓库。由于 svn 可以检出子目录,且可以通过目录来设置权限,代码库的目录划分开始和组织架构挂钩。
当时编译机的目录结构不再是映射单一的仓库,而是第一级映射的是某个仓库的 trunk 目录下的子目录,例如开放平台创新部的工作区目录是:

所有的一级子目录都对应 svn 的一个子目录,不同子目录的权限由各个业务方维护,比如微信基础(广州)负责维护基础框架和微信底层通信代码,开放平台基础部(广州)负责维护维护开放平台的业务代码,开放平台业务部(深圳)负责维护摇一摇电视 ibeacon wifi 游戏等创新项目,微信支付(广深)负责维护支付底层业务代码。
此时实际上微信后端已经从 monorepo(单仓)走向了 multirepo(多仓)模式。
同时为了解决越来越多的依赖混乱的问题,广研在后端微服务工具链中增加了对依赖的强制校验。并规定:
- 基础组件中的定义的 Protobuf 源文件可以被所有的目录依赖;
- 部门的对外服务,其中的 Protobuf 定义的结构可以被其他所有非基础组件依赖。例如,创新业务内部服务可以依赖微信支付对外服务、开放平台后端对外服务下的定义的结构;
- 非对外服务的只能依赖本部门对应的私有仓的微服务和其他对外的服务定义的结构,比如创新业务对外服务可以依赖创新业务内部服务、开放平台对外服务但不能依赖开放平台内部服务和微信内部服务。
每一个项目组都有独立的编译机,在这个编译机上会有多个编译账户用来管理编译工作区(这个编译账户在后面的统一编译也会用到),有了不同的编译账户就从编译机上解决了某些代码禁止依赖的问题。
- 微信支付编译账户不会拉取微信后端内部服务、开放平台后端内部服务、创新部内部服务的代码,所以在微信支付的编译账户下,编译脚本如果分析出有微信后端内部服务、开放平台后端内部服务、创新部内部服务下的依赖,就会提示路径不存在(注意此时 bazel 还没有开源,也没有在包管理的概念);
- 通用框架使用的账户不能拉取任何业务代码的仓库,所以基础库的如果依赖了某个业务代码将不会编译通过;
- 以上规则只在编译机上生效,如果你是在开发机,还是可以编译通过的,这也就是为什么现在依然存在某些单元测试编译目标依赖混乱的问题,因为这些单元测试并不需要在编译机上编译。
正是有了不同的编译账户和各个部门不同的编译机,使得不同业务部门之间有了高度的独立性。高度受政策管控的微信支付业务可以使用稳定版本的基础库,而激进的开放平台创新部以及后来的游戏中心却非常乐于体验带新特性但不那么稳定的基础库框架的版本,而这样的选择是由于业务的迭代特性的自发的选择,并非由某位大佬自上而下的强制推行。
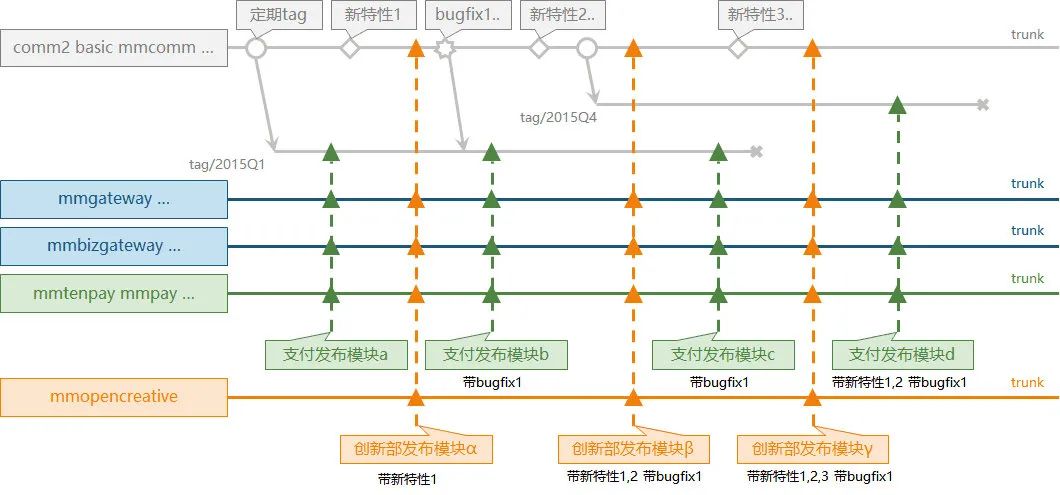
1.3 迁移git时代(2018~2020)
2018 年到 2019 年公司启动仓库由 svn 到 git 的过程。公司的出发点非常好,不强制业务选择迁移的方案,广研团队和微信支付团队分别提出了两种不同的方案。广研的方案比较粗暴直接:
- 将以前的编译工作区各个一级文件夹直接创建对应的 git 仓库;
- 将代码直接从 svn 迁移到 git,之后再考虑怎么拆;
- 第三方公共库全部收敛到专用仓库,但仓库并不直接对应代码,而是软链到与开源仓库对应的 Fork 仓库路径中,这样保持代码兼容性问题;
- 对于不同项目团队会分配不同的工蜂(腾讯内部 git 管理平台,类似于 gitlab 的私有化定制版)项目组。

此时的后端编译仓库不再是扁平的二级结构,而是树形结构,每个节点都和一个 GIT 仓库对应。这样做的好处非常明显:
- 后端的代码工作区的结构和组织架构解耦,根据功能来划分。以前需要增加一个第三方库,需要到处求爷爷告奶奶,求广研基础部在自己管理仓库
mm3rd下增加,到时候出了事,责任难界定; - 统一管理第三方库。第三方库统一收归到
mm3rd2下,完全是一个开发协作的思想,你增加了第三方库挂载到伏羲平台中,自己的编译账户就可以使用了,再也不需要自己硬复制文件到自己的目录下了; - 编译依赖和库版本解耦。曾经使用 bazel 写依赖项需要带上版本号,svn 时代都是大一统的单仓,根本没办法对依赖项统一规划。某些时候不得不写成
//mm3rd/boost-1.66:regex这样奇葩的写法,如果其包含的次级依赖中又依赖了//mm3rd/boost-target:regex,就会存在符号冲突,现在统一写成//mm3rd/boost-target:regex即可,而使用不同的编译账户,就可以完美的切换不同版本的第三方库; - 公共组件可以及时共享协作了。新增的
mmcontrib非常开放的将所有想为 WXG 后端建设的成员开放,并集成到统一编译中,并使用了专用的编译账户以保证不能依赖业务仓库中的代码。 - 代码仓库项目组和前后端构建系统解耦。越来越多的项目采用工蜂项目组的形式来管理,比如一个项目中同时存在前端、客户端、小程序、后端不同的仓库,以前这些代码都需要被粗暴的拉到本地,但对于微信后端代码的构建系统来说,客户端、小程序、前端等并不需要被看到,现在只有那些需要被微信后端构建系统构建的代码才会被检出。
迁移到 git 后,广研基础团队提出了改进 GitFlow 的工作流模式。
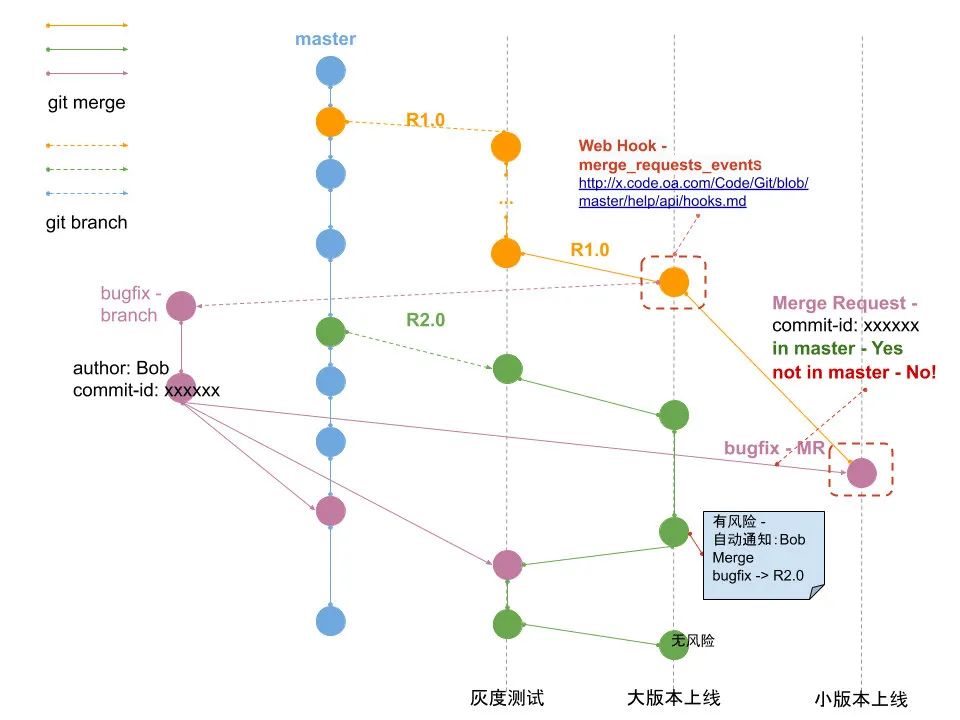
comm2 基础库使用了主干开发模式。
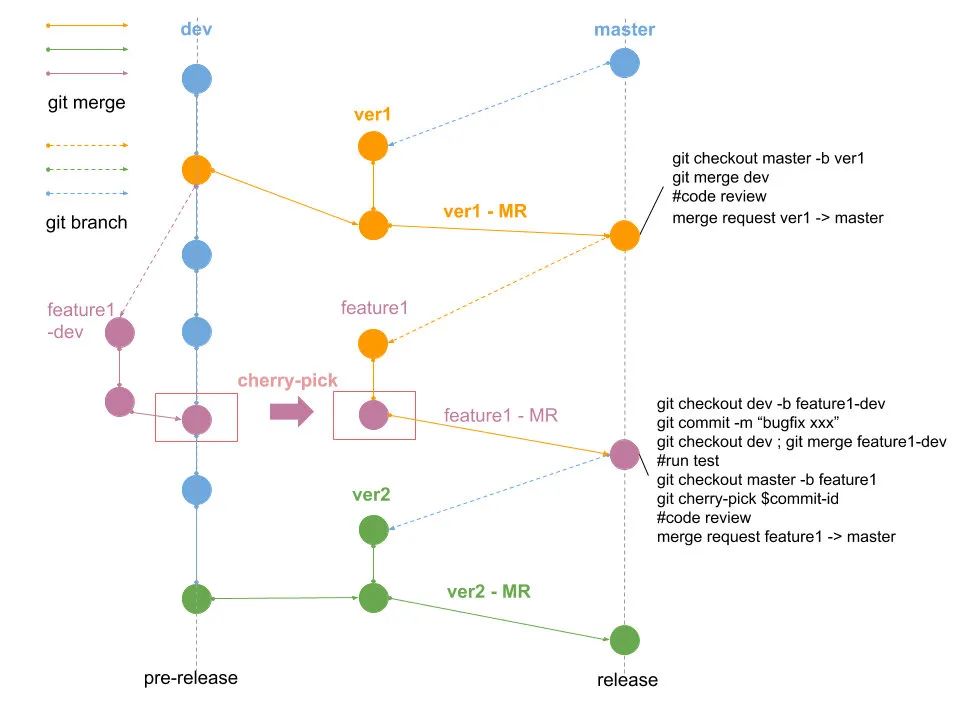
1.4 根据领域驱动拆分小仓(微信支付整洁 git) (2020~现在)
在迁移到 git 时引出了另外的问题,如何划分工蜂项目组?工蜂项目需要由什么样的规则来管理呢?
微信基础部也曾经遇到这样的问题,当时只是仅仅通过行政组织架构来对应文件夹,最终导致了依赖混乱,代码耦合严重等问。
基于这样的问题,支付团队决定进一步将代码仓库拆小,在迁移 GIT 的过程时,支付提出了整洁 GIT的方案。

整洁 GIT 定义了一系列的使用规范。
-
位置约定
-
业务模块路径与领域边界、模块分类对齐。模块路径:系统、子域、模块功能分类(gateway|application|domain)、模块;
-
模块公共代码与模块私有代码分离。公共代码包括:可以被其它模块依赖的部分。组件api、错误码、proto代码、client代码、以及用于公共使用而封装业务基础代码;
-
业务模块与组件分离。
-
依赖约束
-
只能依赖公共代码不能依赖其他领域的私有代码。编译时检测,依赖非自身外的私有代码,编译失败;
-
跨项目组的业务代码不能通过 lib 依赖,只能通过
service_export_gen或mmpay_service_export依赖。 -
接管服务契约
-
proto 文件由专门的契约管理系统管理,结构化编辑、线上契约冲突检查;
-
编辑完成后由 CI 工具生成 client 代码推送到
service_export_gen代码仓库; -
service_export_gen除机器人外没有任何人权限。 -
一站式管理
-
通过 API 访问整洁 GIT 代码树;
-
使用契约系统持续集成统一生成服务 client 的代码,禁止在 client 自己编写逻辑。
这样有计划的一致的拆分方案解决了使用大仓的一系列问题。
1 . 权限独立
a . svn 中通过组织架构和文件夹权限对应,一旦组织架构调整,文件夹而又不可能随着组织架构一起调整,最终导致编写代码混乱;
b . 整洁 GIT 将代码通过业务系统拆分,同时工蜂可以将组织架构动态绑定到项目组或项目中,当组织结构有变动时,可以非常的方便的调整权限。
2 . 持续集成
a . 整洁 GIT 使用 CI 工具收敛了变更最多、协同最多的服务契约,者将会使得因为服务契约协同开发而导致的拉分支状况相当少,只要在契约系统中完成契约编辑,会自动将契约转化成 client.h``client.cpp 并放置到对应的专用仓库中;
b . 不同项目组由于业务性质不同,可以采用不同的 CI 策略。如基础支付的产品生死攸关,必须添加单元测试流水线,代码覆盖率超过 80%,才能被合入主干发布;而行业运营开发组项目大多数实验性项目,产品的生命周期很短,并不要求完美的单元测试,只需要保证代码基本的风格统一即可。
3 . 工作流优化
a . 由于将代码仓库拆小,所有的发布关联和问题集成都可以在工蜂中完成,特别是做基础组件的团队,已经非常熟悉 GitHub 一套 MR 流程,工蜂的使用效能达到最大化。而大仓除了提供一堆 99+ 的数字、无数五颜六色的 label 毫无利用价值,最终弱化成带历史记录的超大文件系统;
b . 各个编译系统可以根据不同的编译产物进行构建,自由组合虚拟的编译工作区,而不是像无头苍蝇一样把所有的代码都拉取下来。例如:编译后端代码,只需要拉取编译账户下的后端代码仓库,忽略掉项目组中其他的例如前端、小程序、私有组件仓库。同时,若使用前端构建方案,则只需要检出一个单独的前端仓库即可;
c . 由于依赖的清晰化,从构建工具开始就对一些无效的依赖限制,如根据领域驱动设计来确定某些依赖项需要被斩断。
代码仓库一直都是伴随着开发一生绕不开的话题,随着业务的膨胀,代码仓库也会一天天变的巨大,无论大仓还是小仓。都必须是在业务的发展中经得起检验的,而回顾这微信发展的 10 年,团队也一直通过实践的方式优化代码仓库的合理使用,并在使用过程中结合了软件方法、领域驱动建模等非仓库的理论来实践,一步一步的发现问题解决问题。而并不是一开始就弄一个超大的概念,制定超过模糊的强规则让众多开发屈服,只有同时让开发用的爽(提升研发效能)让老板满意(满足组织上一致性)的方案才是最优秀可行的解决方案。
2 小仓的优秀实践(效能篇)
某研发:你的方案怎么好,你来写啊,别光说不做
首先需要承认一点的是,对于效能工具团队,广大的一线程序员就是最好的调研目标,让他们开发起来爽,他们就更加有干劲的产出,同时要保证服务质量,就是我们存在的价值。如果弄一堆空中楼阁式的自研工具,搞一套业界差别很大的理论,让开发人员疲于奔波和学习某深奥些理论知识,招来的不仅是一线业务团队的拒绝合作,更会严重拖慢业务精益迭代的目标。
2.1 全局代码搜索
由于使用了小仓和虚拟工作区的方法来处理各个开发机后端代码,在每位开发本机开发或远程编译时,并不需要耗费非常长的时间把所有的代码都下载到本机,只需要检出自己有权限的仓库(如果你使用远程编译,甚至是你当前开发项目的仓库)。
此时如果需要查询某个符号的引用,如果在本机搜索当前工作区的副本显然是不现实的(特别是后端代码),如果直接使用全文搜索,不仅效率低,而且还费时,搜索的结果也差强人意(不能使用语义的搜索,按照符号类型搜索等),这里时候就有必要构建一个在线的准实时的全局代码搜索门户。
无论是使用 OpenGrok 还是使用 [Mozilla DXR](Overview — DXR 2.0 documentation) 都是非常成熟的解决方案,但这样的解决方案都是基于单机目录设计的,如果一个超级大仓都不能在一台机器上被检出,那几乎无法简单的做出一个非常好用的代码搜索门户。
微信后端团队在 2013年左右就部署了一套基于 OpenGrok 的代码搜索工具,当时的微信后端的仓库比较小,一套门户就适用所有的微信后端的开发。但随着编译账户的增多,代码库的数量也在增加慢慢一台单机已完全不满足所有微信后端代码仓库的搜索了。
基于这样的特点,微信技术架构部开始使用不同账户分治的构建代码搜索门户,并使用了更强大的 [Mozilla DXR](Overview — DXR 2.0 documentation) 方案。这样使得微信基础团队不用再去关心支付的业务代码,微信基础消息收发的代码也不必在支付团队的成员中显示。
大仓的支持者会想当然的会认为做搜索是不是直接弄一个超大仓做一个类似 Google 的搜索页是不是更好呢,这个问题我们就需要回到最初的一线开发者愿景(Want)上来分析。
那一线开发到底是怎么来看待这个问题的呢?
- 我们需要一个快速搜索代码符号的门户;
- 我们只关心我自己写的或依赖的代码的符号;
- 当出现符号错误或链接错误时,我希望可以快速定位到依赖的关键;
- 前端开发者通常不太需要全局代码搜索,因为使用
npm install之后所有的代码依赖都会下载到本机,通过 IDE 搜索比一个单独的搜索门户来的方便,若想搜索开源组件,直接使用开源社区即可; - 依赖的第三方库也不会在代码库中搜索,因为 Google、Stack Overflow 或 GitHub 已经可以提供足够多的解决方案;
- 微服务的服务契约,有专门的门户管理(管理兼容、输入输出请求、静态规则校验、返回信息等),也不应该直接在代码库中搜索中间代码;
- C# / Java 开发者也通常不需要全局代码搜索,因为 IDE 内置的对象浏览器已经可以满足各种搜索需求,而且还支持快速跳转,查看实现。
所以全局代码搜索这个需求服务的目标人群是:具有超大规模的后端编译需求的开发们。
这样看起来将后端编译的工作区,作为搜索的数据源来分析是最合适不过了,如果整个 WXG 是一个大仓,或者全公司是一个大仓那么想这样简单做一个搜索项目出来就非常困难。
- 搜索出非常多的 fork 仓库的代码,这些代码根本就不会在微信的编译系统下使用,只是徒增筛选成本;
- 搜索到一些非代码包括学习笔记之类的不想关心的内容;
- 想搜索符号或声明,却搜索出一堆注释之类无关的代码;
- 私有仓的代码无法搜索,可惜 WXG 基础部的核心代码都是私有仓,只对 WXG 开放;
- 虽然搜索的速度很快,但筛选的成本相当高,你需要精通了解大仓的每个文件夹是怎么放置的,才能精确搜索到自己关心的代码。
2.2 第三方开源库治理
小仓的方案被很多人诟病的原因是依赖混乱,很多开发使用第三方库直接就在自己的仓库的文件夹下复制一份代码,最终造成整个编译工作区很多重复的开源库。然后就有人提出使用大仓来统一管理开源的三方库。
在单一 svn 仓时代微信后端编译工作区也确实会遇到这样的问题,因为在大仓时代文件夹的权限和组织结构强绑定,掌握 mm3rd 的开发者不愿意为其他开发者将第三方库引入到编译工作区中,因为 mm3rd 的开发者通常是最先创建仓库的人,而非专职处理人员。通常情况下这些开发者会认为引入第三方库会引入风险,故会对需求方的建议推诿、拖延、甚至拒绝执行,而需求方迫于业务时间上的压力,不得不将库粗暴的直接拷贝到自己有权限的文件夹下,最终造成第三方库引用混乱的问题。事实上正是因为大仓耦合了太多功能,才导致第三方开源库治理的混乱,大仓耦合了组织架构权限、构建系统、代码检查规范等,导致某些时候不得不为了非存储代码的目标,而一定要将第三方开源库引入到库中。
在以静态语言为基础的构建系统中,这个问题会出现的尤为突出,而且会引起链接问题从而阻塞业务上线流程。例如,下图中的 svrkit 框架升级到 v1.1 后,业务代码将无法链接通过,因为 libboost-1.66 和 libboost-1.55 的符号有冲突。
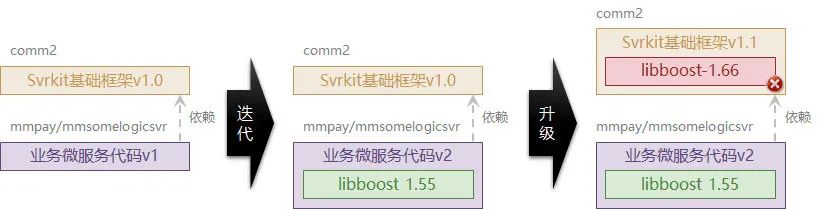

公司的工蜂小组强力推荐使用 git 和开源界对标,我们也调整了自己的构建工作区的环境来适配这样的改变,比起使用 svn 来配置权限的,git 管理起来更加灵活而且通过不同的编译账户,即可灵活的组织编译依赖。

比起使用大仓单独文件夹来管理第三方依赖。使用虚拟文件夹对应社区的完整的 git 的仓库的好处是显而易见的。
- 后端代码也可以像前端代码有良性互动,后端代码中第三方仓库由 GitHub Fork 而来,所有会保留以往的提交记录,有想法的同学可以将自己贡献的代码 cherry-pick 到开源社区的仓库中;
- 由于 mm3rd2 是一个虚拟的目录,里面的第三方库只是类似挂载的机制引用进来,第三方库中所有的测试、文档、代码都是完整的不可分割的,我们在贡献代码时也必须按照第三方库的规范保持风格,如果使用公司级单仓,势必会按照公司单仓的风格执行,届时将形成完全不同风格的代码,第三方库作为一个完整仓库的完整性遭到破坏;
- 伏羲平台管理的统一编译的代码仓库的虚拟文件夹的映射表,这是一个开放的平台,任何 WXG 参与开放的同学都可以将自己觉得需要的第三方库挂载到统一编译系统中。不过对于一些专门敏感的库,如(openssl 总是会修复一些漏洞)会有专人运营,督促开发修复漏洞,而正是因为将这些第三方库统一管理起来,使得我们修复漏洞时非常容易,重新编译一下即可。(若是使用 wxmesh 架构的微服务,只需要更新 mesh Sidecar 即可,业务代码无感)。
2.3 统一编译 伏羲平台
其实相对于其他 BG,微信后端相比较是比较幸运的,我们一开始就站在了巨人的肩膀上,早在 2012 年就引入了 blade 后端构建系统,统一的编译系统解决了 C++ 在编译方面引起的巨大依赖问题,尤其是对于 C++ 缺乏完整的好用的包管理系统。早在 2014 年就推广使用的发布平台,统一了后端服务的发布流程。抓住了微服务的生产和发布两个一致性的大头,扫清了我们在流程一致性中的障碍。
但随着代码库越来越多,comm2``basic``mmcomm 等基础库变更越来越频繁,越来越多的开发在本机开发需要频繁的更新相关依赖。而且正是由于根深蒂固的单仓思想,开发者习惯于将整个编译工作区都检出到个人开发机上,但却发现这样做的收益是非常低的,因为编写一个微服务所需要提交的代码相比基础框架和依赖项是非常少的。
于是我们研究出了 patchbuild 统一编译。patch 是指把只需要提交到编译系统的部分通过补丁的方式提交到远端,build 指这些提交补丁的行为是用于构建二进制产物。于是统一编译系统提供了一套命令行工具给开发使用,其目的是希望用统一编译取代开发机的本地编译,实现本地开发,云端编译[^8]。
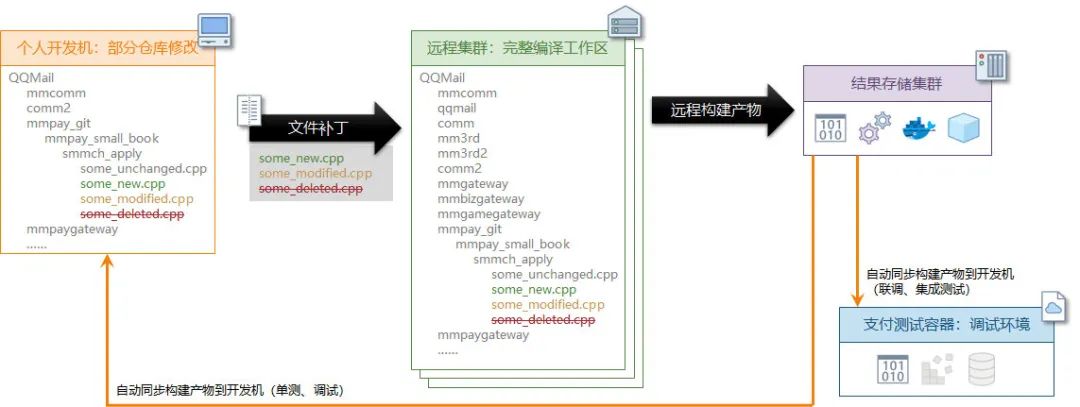
-
在本机的要开发的小仓中创建一个分支(特性分支、个人分支、修复分支)
-
编写代码,将需要统一编译的资源添加到 git 暂存区(cpp/h 等源代码不需要添加,会自动识别)
-
使用
patchbuild build :build_target来编译目标 -
可以指定将编译结果同和中间文件(*.pb.h / *.pb.cc 之类)同步到本机
-
可以指定传送编译后传送目标,传送到预发布环境
-
可以指定编译后打包 docker 镜像并发布到微信测试环境
-
可以指定编译后传送到微信支付个人调试容器(数据和接口完全和正式环境隔离)
-
在本机使用 XTP 工具调试开发机本机服务或远程服务
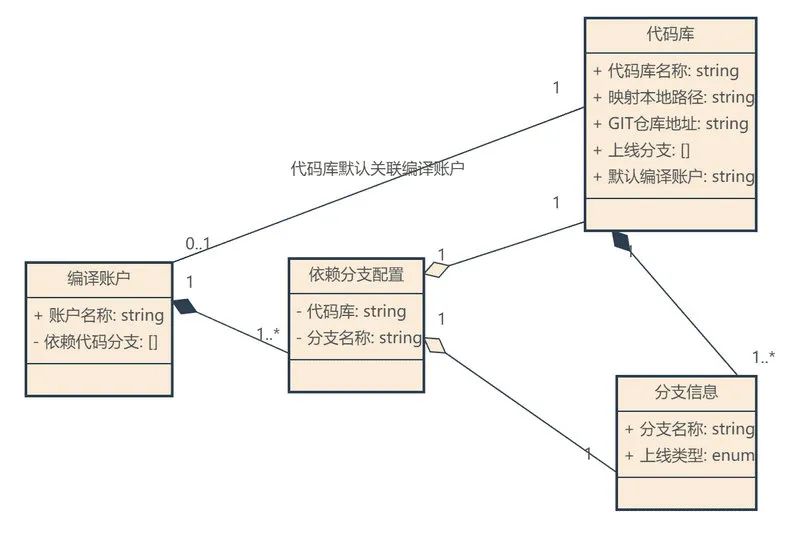
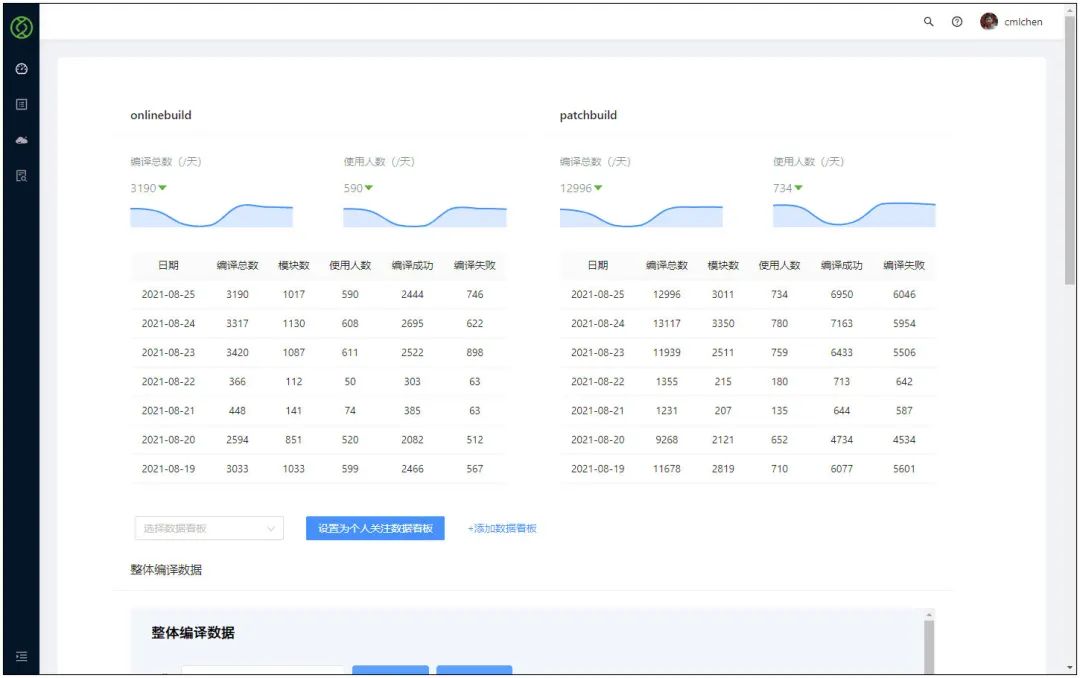
在伏羲平台中维护了一套编译账户和代码库的信息,通过一套门户来决定某位开发者在当前的目录应该使用哪个编译账户来统一编译。管理者也可以通过这个网站来查看每日构建的使用情况,统计慢速编译和缓存使用情况。
- 需要把所有代码都检出到本机,消耗大量的时间,魔改版的工具的成本又相当高;
- 因为大仓的设计导致无论多么小的改动的提交都会创建一个整套仓的分支,现在已经有
mmtenpay``mmbiz这样的比较大的仓库,已经无法使用 git 来管理和跟踪 issue,上千个开发分支导致 git 完全成为一个超大的文件存储系统; - 超级大仓在计算 diff 时将消耗非常大的时间,云端编译甚至可能将一些不需要的中间产物一起打包;
- 超级大仓在远端编译时拉取仓的时间会非常长,因为分支的数目众多,使得非常小的改动就会要更新整个仓库,大多数情况下这样会导致 bazel 计算依赖路径失效,频繁的切换不同分支的源代码。
无论大仓还是小仓,能够服务于一线业务开发的仓就是好仓。腾讯公司作为一个超大体量的公司,从组织上说如果不能服务好他们,影响的不仅仅只是核心技术团队的口碑,更还会影响公司业务的发展。整个微信后端也不是一开始就确定使用大仓或小仓的,还是在不断的业务发展中优先为一线开发提供研发效能的解决方案,然后再从方案中提炼出合适自己团队业务的方案的。
3 小仓的优秀实践(一致性篇)
首先必须承认一点大仓在一致性方面确实有独特的优势——你离开了仓库就不能写代码了,不能写代码了哪儿来的方式发布,特别是对于后端服务来说,使用大仓似乎是可以堵住胡乱发布、胡乱写代码的一种简单粗暴的方式。但我们认为众多小仓如果管理得当,一样可以做到可规模化,也一样可以做主干发布,这些优势并不能成为使用大仓的理由。
3.1 切换后端构建系统
微信后端编译系统于 2017 年将魔改版的 blade 切换到 bazel 构建工具。blade 实际上是一个 scons 脚本的生成工具,当我们通过命令行调用 blade 的,blade会根据所需要编译的 target 通过 python eval 的方式加载本次编译所需要用到的 BUILD 文件。BUILD 文件加载完成之后,blade 会根据 BUILD 文件当中所声明的target依赖关系和源文件列表生成一个 scons 的声明文件。bazel 和 blade 一个最大的不同的地方就在于,bazel 在处理依赖关系的时候并不区分 targe t级别和文件级别,也就是说在加载 BUILD 文件的过程当中 bazel 是直接计算文件之间的依赖。这使得 bazel 不需要等待整个编译依赖图全部都加载完成之后再开始执行编译动作。
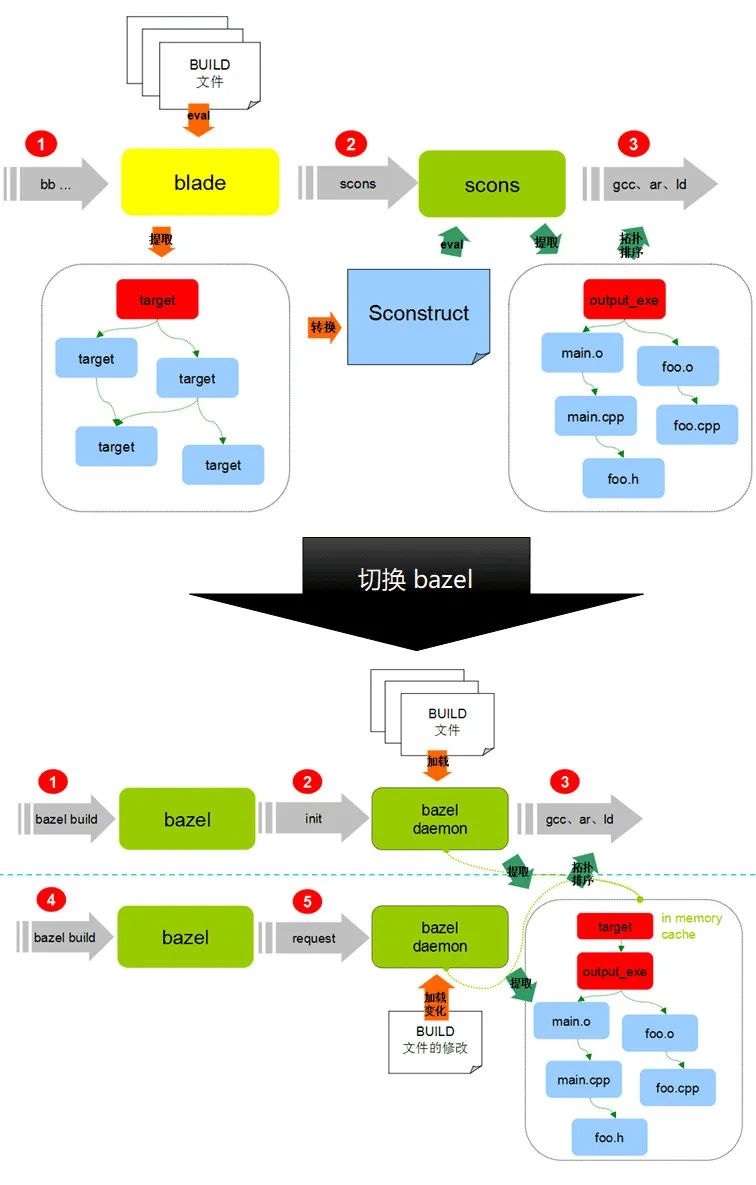
blade2bazel 的转换工具,并制定了一套迁移方案,整个迁移涉及到所有 WXG 后端开发。
- 升级后端构建工具魔改版的 blade,继续魔改,如果发现有
BUILD_OF_BLADE就使用此文件,否则就还是使用BUILD; - 提供
blade2bazel工具,尝试通过工具将 blade 版本BUILD转换为 bazel 版的BUILD,备份原有的文件为BUILD_OF_BLADE; - 通过每日构建找到不兼容 bazel 的
BUILD文件或无法转换的文件,提示开发根据指引修改; - 开发需要在一段时间持续维护
BUILD和BUILD_OF_BLADE两个构建脚本; - 逐个 repo 迁移构建工具。直到所有的 repo 都迁移完毕,废除 blade。
当时所有的开发都秉承一种思想“所有的技术升级都不能阻塞业务的开发”,在 WXG 里面最重要的思想就是灰度、平滑升级、业务无感(此思想也适用于效能团队)。
也正是当时微信后端都启用分仓的模式,使得推进这进程没有那么痛苦。
- 初期可以拿小仓库来试点,搜集反馈,打磨方案;
- 工具链的仓库可以使用不同的分支来开发,小范围试点时,在构建系统中合理配置编译账户的仓库配置,即可使得不同仓库的构建系统的升级切换平滑;
- 当试点一段时间方案成熟时,只需要调整对应编译账户的构建工具仓的分支,即可对其他仓库应用新的构建工具;
- 整个调整在阵痛时期都是可灰度可回退的,仓库足够小就能保证灰度和回退的粒度,当然某些大仓的拥护者会提出质疑说大仓分文件夹也可以做这样的事情。诚然分文件夹也可以这么做,但你会让每一次依赖联都创建一个分支么。还是正如一些激进分子一把梭,一次性全部替换整个构建系统,一旦出现构建失败,阻塞的就是每天上千次的微信后端发布流程,这显然是不可接受的
在当时切换 bazel 时还有一次有意思的故事。支付团队以前由于 mmtenpay 仓库过大,一直都没有处理,就算是有升级工具的加持,依然在每日构建时成为阻塞的瓶颈。有一部分比较开明的开发,单独创建了一份 mmtenpay_bazel 的仓库来只是用 bazel 作为构建工具。试想一下,当时如果存在支付的整洁 GIT,所有的仓库根据业务系统来划分,那么就会有更加一致性的迁移过程,迁移的时间也就更加平滑,更省时。
3.2 支付整洁 GIT 实践
支付在 2016 年业务和开发人员规模迅速膨胀,导致 mmtenpay``mmpaygateway 两个 svn 的依赖混乱,构建复杂,甚至时不时的还引入环形依赖导致构建失败。最终痛定思痛在在 2018年决定启用单独 mmpay 新的 svn 仓库来结束混乱的局面,但 svn 依旧是权限管理非常生搬硬套,由于缺乏一个划分文件夹的标准,导致文件夹的层级越来越深,依赖查找越来越复杂。2018年底公司提出整体搬迁 git 战略,组织上加强领域驱动理论的学习,我们于是找到一套切实可行的划分 git 工作组仓库的方案。
首先我们需要理解领域驱动设计的思想:
- 把项目的主要重点放在核心领域和领域逻辑;
- 以领域中的模型为基础,进行复杂的设计;
- 让技术人员以及领域专家合作,以迭代方式来完善特定领域问题的概念模型。
如果按照领域驱动建模设计微服务是一个什么样的结构呢


-
一个领域(例如微信支付系统)中可以包含不同类型的仓库。
-
后端服务:挂载到伏羲平台中,进行统一编译走微信后端发布系统发布;
-
前端工程:使用唐刀平台、或 XDC 平台进行统一 CI CD;
-
文档沉淀(之后切换到 iWiki):使用工蜂平台管理文件源数据,跟踪缺陷,保留修改记录和讨论详情。
-
仓库的权限和组织架构解耦,当组织架构变动时不需要频繁更新整个仓库的权限控制。
-
对于不同的仓库都是一个完整的独立代码单元,可以根据工程不同类型做独立的CI CD。
-
属于支撑域的 RPC client 自动生成的仓库,禁止人员修改,根据服务契约变更自动生成 client 的代码。
但我们也需要了解并不是所有业务系统都会选择领域驱动建模作为系统设计、代码开发的指导思想。所以不同的团队也许会有不同的划分小仓的方案,支付团队只能提供类似支付业务的一致性实践,不能代表所有的业务的开发。
构建一个基于领域驱动建模的需求管理系统也是一个困难的工程,如果忽略掉了这些先决条件,盲目凭直觉而简单地根据语言来划分文件,只用大仓甚至是全公司单仓来作为根本解决方案是不太合适的。
3.3 支付质量红线
公司在 2019 年的一个 KM 乐问引爆了大家对代码风格、规范的统一思考。支付团队在 2020 年中成立了代码委员会来统一管理微信支付代码红线,为了保证团队代码风格一致性和规范性,团队在公司 C++ 代码规范的基础上制定了支付质量红线,初步制定了要参与的代码仓库。
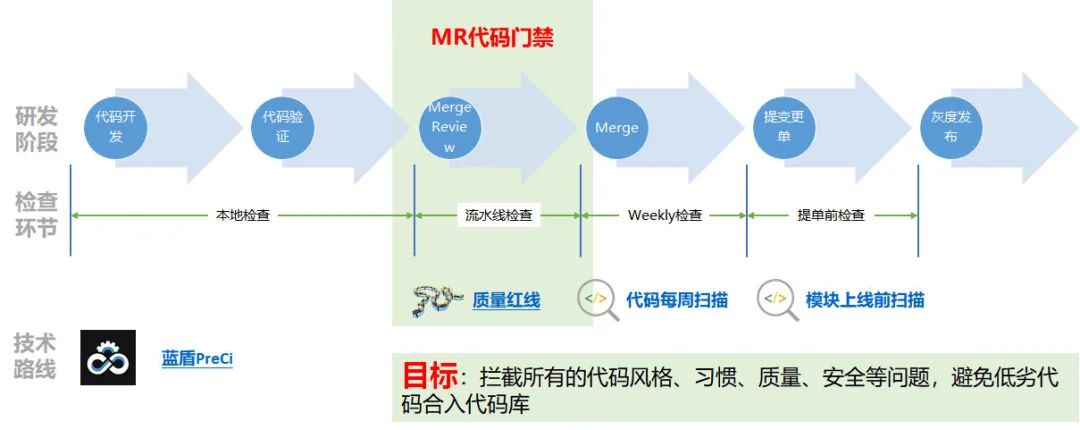
- 杜绝代码中对于公司内网 IP 的硬编码行为;
- 杜绝代码中对于 appid appsecect github 账号账号等硬编码;
- 配置中杜绝明文私钥的存储。
在推行质量红线时,同样的我们对于任何一种发布或变更都会采取可灰度、可回退的方针。我们不能把质量红线这样一套门禁系统立即运用于所有代码工程,一刀切的政策搞不好就会上热搜,这样对于整个团队的士气的打击无疑是巨大的。同时我们也没办法一开始就保证流水线的设计是合理的,所以一定需要拿一些对质量要求特别敏感的仓库来小试牛刀。由于蓝盾的流水线的模板特性,我们确定只要我们设计好一套好用的流水线模板,就可以非常方便可扩展的应用到所有微信支付小仓项目中。
我们的行动计划是:
- 拿出一些典型的仓库作为设计质量红线的目标客户(如支付的公共组件 Xlib,基础支付中心某些新的仓库),设计支付红线流水线;
- 验证流水线是否可以拦截不规范的代码;
- 根据流水线设计流水线模板;
- 扩大流水线应用的仓库;
- 搜集流水线造成阻塞的反馈;
- 继续调整流水线策略并加大风格习惯的宣传;
- 将所有新增的仓库都自动添加质量红线堵住增量入口;
- 进一步灰度流水线到其他陈旧代码仓库。
支付线本身就有整洁 git 和非整洁 git 两种不同代码仓库,在进度到第 8 步时遇到了非常大的阻力。因为陈旧代码仓库的代码量之大导致蓝盾出错的几率增加,而蓝盾的客服人员告诉我们可以将 MR 关闭之后再打开重试流水线,这又造成了蓝盾的负载进一步增加。
我们庆幸在 2021 年整洁 git 的思想和代码编写模式已经非常深入人心,否则这样强推质量红线的实践可能就会成为灾难。在一个工具型产品应用的过程中,你会受到来自业务团队开发的各种阻力,只有不断的灰度打磨、精益的调整工具型产品的口碑,让各行各业的开发人员切实感觉到提升了他们利益,而不是让业务开发天天做一些修代码风格,整治遗留重构的漩涡中,这样才能让广大的开发人员接受研发效能工作,才能形成效能工具打磨的正反馈。至于说是否采用大仓,对于领导这一涉众而言只是一个解决一致性问题的方案,工具和管理才是提高效能的本质。
从组织上来说,小仓大仓只要能解决“一致性”的问题就是好的解决方法,无论是从后端构建系统、开源治理、仓库划分等组织上的诉求来看,大仓都并没有非常有利的优势。相反大仓的支持者通常使用“我们先用一个大仓规范起来,既然都在一个仓库了就理所应当的好治理了”这样一种话术来掩饰组织上在治理“一致性”方面的难题,仔细想想是不是规整分类的小仓库治理起来,比混乱不堪的文件夹乱飞的大仓,要简单容易呢。
4 分治
公司的开源治理的政策的核心是“一致性”。
- 首先大家需要有开源共建的精神;
- 在开源的基础上提升代码质量提升效能;
- 消除开发团队中的信息壁垒;
- 减少重复工作提升研发效率。
而大仓的拥护者似乎把这个政策搞颠倒了,似乎只有使用大仓或未来让全公司都有几个为数不多的大仓才能解决上述问题,似乎把所有生产程序的原材料堆放在一起,才是解决效能的第一步,而这恰恰是目前和近 10 年来去中心化的大主流不相符合。
4.1 主干开发 vs 金丝雀 vs GitFlow
你看的没错,微信支付团队后端就是基于小仓做主干开发的。使用小仓并不影响使用主干开发,而且正式由于仓库是基于领域驱动划分的,所有的业务逻辑代码都在一个非常聚焦的仓库中进行。比起大仓做主干发开,小仓反而有更加灵活方便,主干开发并不是大仓的特有的,而是一种开发理念,只要是做业务开发的都可以选择使用主干开发,大仓做主干开发只是一种非常想当然的认为,但主干开发并不是大仓的必要条件。
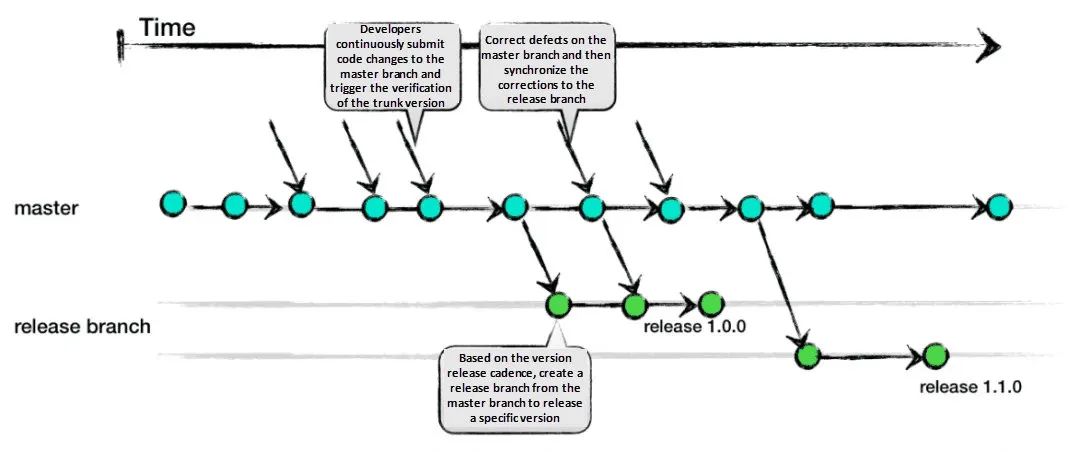
- 保留陈旧的不合时宜的业务代码逻辑并不能提升效能,反而会影响团队开发人员的视野;
- 由于现在自动化测试用例工具非常普遍,尽快合入主干会防止一次性合入过多代码而导致无法对代码进行有效的审核;
- 微服务之间的交流通过统一的契约管理,通过契约变更的兼容性来保证,即便是在不同时期不同仓库合入的主干,也不会出现通信上的兼容性问题;
- 特性开关、特性发布和构建产物解耦,就算是业务逻辑夹带出去,也不会对非开启特性的用户产生影响。
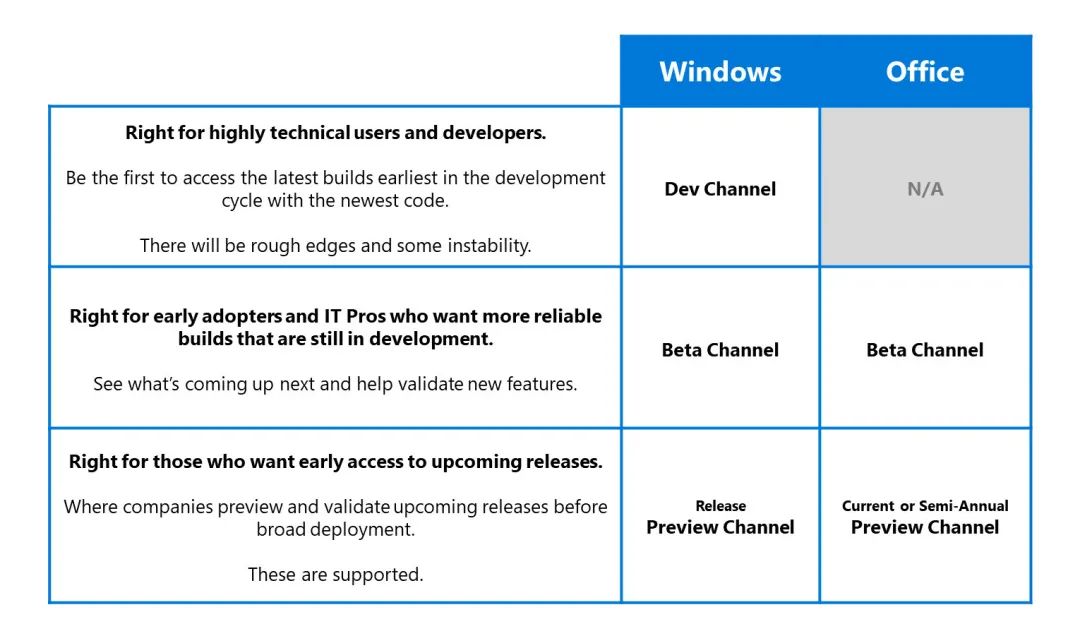
-
基础框架维护的仓库包含一个 master (Release Channel) 分支一个 PreMaster (Beta Channel) 分支;
-
当某个特性开发时创建 feature 分支,分支完成好后立即合入 PreMaster 分支;
-
此时 PreMaster 可能是未经大规模验证的,但又可以基本使用的(跑通过了单元测试用例)版本;
-
某些内在的 BUG 非常有可能不会出现:如核心微服务调度算法,资源管理算法类的框架,再没有大规模上生产环境时,是很难被验证的;
-
此时框架团队会和有需求的团队或比较激进的团队来协商试用 PreMaster 版本的框架,此时需要注意业务团队非常可能是用自己的 master 分支和框架的 PreMaster 分支一起构建(参见统一编译的部分);
-
当 PreMaster 框架验证一段时间后(比如一个月,跟剧规模和业务方的诉求来确定),再合入 master;
-
此时很多在 PreMaster 通过验证发现的 BUG 会得到修复,也非常有可能在 PreMaster 评估不合理的特性会被去掉;
-
核心业务在此时会非常乐于接受被验证的特性,因为已经经受到了其他业务团队的验证;
-
对于某些对可用率要求非常高的业务如(微信支付的收付退结,必须要达到 99.999%)会使用 stable 版本的框架;
-
stable 版本的框架是通过半年或以上沉淀下来的基础库的版本,只有在非常紧急的情况下才会将 bugfix 合入 stable;
-
任何人都没办法保证在 master 下的特定时期不会出现任何 bug,只有在得到充分验证的情况下,可用率要求高的业务才会接受使用新版框架;
-
某个业务的升级灰度其可能会长达1年,他们根本就不想冒着框架中未知的 bug 而升级框架。
-
因为不像公司内部代码治理,你无法穷举出所有开源的被依赖者;
-
所以你没办法对不兼容性更新舍弃一个大版本;
-
你必须会一个稳定的提交设置一个 tag 以便让你的客户有选择的保留在这个提交中;
-
仓库需要做的非常职责单一,要不耦合业务逻辑;
-
世界是瞬息万变的,世界的变化可不能做到最大的兼容型(比如要吴签同学下课你就得下);
-
业务也是瞬息万变的,耦合了业务逻辑即使是的当时你认为稳定的 tag 也会变成要必须处理的问题;
-
仓库要做的不能耦合公司的基础设施;
-
公司的基础设施天生不会为开源社区准备的,在版本维护上非常有可能只采取金丝雀模式(即只保留 dev PreMaster master stable)几个版本;
-
仓库耦合了公司的基础设施首先对于开源社区是不和谐,因为离开了不开源的基础设施,你的代码根本没办法进行 CI CD,甚至连编译都做不了(当然这样的仓库也不适合对外开源);
-
目前前端的一些公司级的开源产品(如 [weRequest] )已经借助一个全世界的开源仓库管理系统 github 实现完全的自洽,这一类项目应该按照目前开源界的运作规范来运行(不限于只是用 GitFlow)。
由此可见主干开发、金丝雀开发、GitFlow 的选择并不应该是由公司的政策所导向,而是应该由业务特性、所选用的基础设施决定的,是需要不同定位的。而如果整个公司被划分成几个超级大仓,开发模式将会被完全锁死到看似比较简单的主干开发模式。至于腾讯会不会将来走到全公司一个大仓,大仓支持者却认为不一定有必要。这里关键是看什么样的项目使用什么样的仓库类型,而且仓库之间的组合是需要根据业务、构建系统、所处在的研发阶段动态配置的。
4.2 开源 vs 闭源
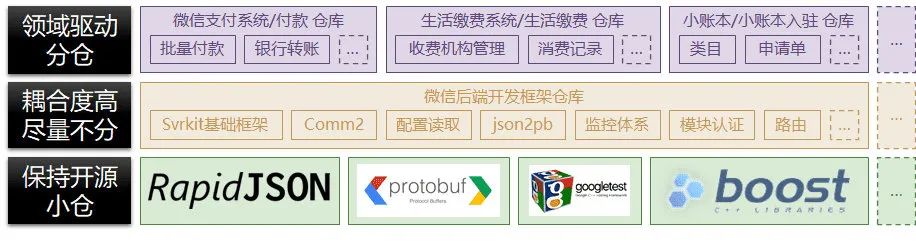
大仓的支持者一直认为将公共库放在大仓中可以解决依赖地狱的问题,而且会使得代码更容易的代码复用与分享。但此时我认为大仓小仓的划分不应该由代码的是不是公共库来划分,而是需要根据公共库所处在的研发地位和解决发方式来划分。例如(这两个例子都来源于真实的后端代码):
-
非常单纯且自洽的公共库(如 RapaidJSON),适用于小仓;
-
此类公共库应该是专门为一些通用的需求制定的,(RapaidJSON 就是为 Json 解析访问验证做的库);
-
此类公共库并不耦合特定的研发框架(RapidJSON 放在微信 svrkit 框架或 tRPC 下都可以解决特定域的问题);
-
此类公共库可以能够在集成开源界的 CI CD 工具形成完美的 issue 闭环,分支管理等(RapidJSON 可以在不依赖 patchbuild 的基础上实现完美的构建,运行单测用例);
-
专用框架的公共库(如 svrkit 框架下的 Comm2),适合直接和专用框架一起存储源代码;
-
此类公共库是专为特定框架 svrkit 定制的,而随着 svrkit 框架的升级,此类库需要做频繁的改动,此时放在单独小仓中一定会出现版本依赖复杂,导致编译失败的问题;
-
此类公共库不不需要贡献给开源社区,和私有的构建工具深度绑定,Comm2 只能在 patchbuild 下被构建,所以也只会存在深度耦合的 BUILD 文件,而不需要
autoconf或cmake等标准构建文件; -
此类公共库很多是一些框架和其他组件的粘合剂(比如 Comm2 中的 pb2json)单独离开了框架无法运行任何 CI CD 工具。
所以我们在选用小仓的同时必须考虑其代码解决的问题域,如果属于前者,我认为选择独立的小仓似乎更适合,而且这样的小仓也能更好的为开源界互动。
开源的目的是为了更好的协作,也是为了集合更多的智慧让某一份代码可以解决更多其专有域的问题,此时开源的收益是大于闭源的。闭源的目的是为专用系统更好的定制代码,使得业务开发更加能专注的开发其业务特性,而从依赖地狱、选择困难中解脱出来。
- 从工蜂中直接克隆 github 的仓库;
- 在克隆的仓库中建立一个专用的私有分支,如(release/wx-build);
- 在私有的构建分支中添加适配内部构建的代码文件,如集成到微信后端编译系统,需要添加
BUILD构建依赖脚本; - 将私有分支信息配置到内部构建系统中,如配置到伏羲平台;
- 如果发现仓库有 BUG 直接在 wx-build 分支中快速修复并验证,需要贡献特性也可以如法炮制;
- 将 wx-build 中的更改拣选到 hotfix 分支中;
- 将此分支在外源(如 github)中提交 MR,跑外源的 CI 流水线;
- 若外源有更新,也可以将外源的更新 merge 到 wx-build 中。
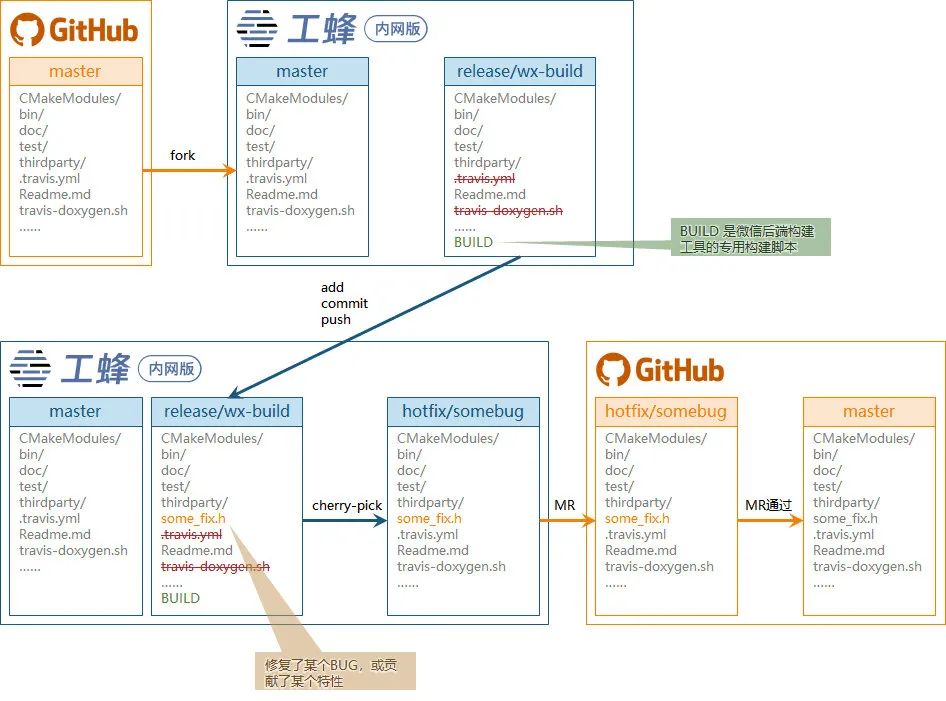
- 外网的仓库类型非常多,不论是前端后端,还是各种构件工具,找一组开源代码委员会的人非常难精通各种不用的仓库的场景;
- 代码委员会因为不是仓库代码的贡献者,非常难有将一个内网的代码发到外网的动力,况且一旦出现构建失败等问题将对这群人产生致命的积极性的打击;
- 作为通用组件的作者,当然是希望自己的组件不会被专用的构建工具所绑定,当然是希望自己能够把自己的智慧贡献给开源社区,所以由此人来维护代码仓库并保持和外源仓库一直是非常自然的想法。
如果使用大仓,可能会将某个开源设计的代码整体复制到一个文件夹中,或采用 sub_module 的方式引入,到时候维护者非常有可能只从整个大仓的角度思考此组件的特性,而忽略了在外源项目中此仓库的独立性。
另外类似这样的第三方库似乎只和生成产物的构建系统强相关,也不适合将其放在代码仓库中。代码仓库应该尽可能做到职责单一,使用单独的构建系统的产品(如微信后端的伏羲平台)可以非常好的解决仓库耦合度过重的问题。
由此可见,划分仓库的大小和工作组的分类并不是应该是有仓库代码的固有特性所决定的,过大过小都可能使得仓库的代码中丧失了其独立性,如果整个公司都或整个BG都是使用同一种划分模式,可能会出现:把代码放进入容易,但日后如何管理这个大仓陷入比较麻烦的局面。
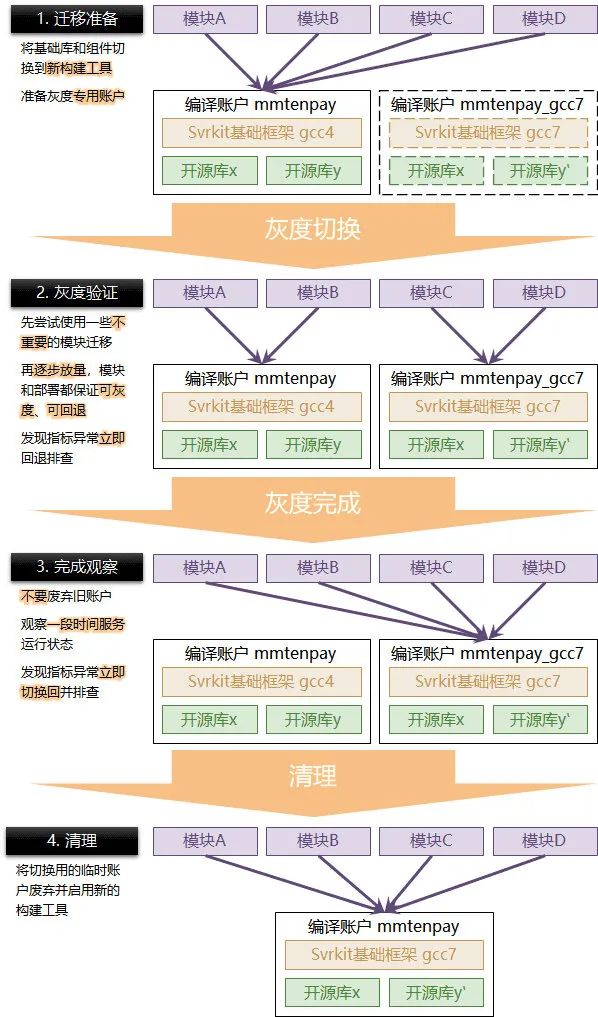
4.3 灰度 灰度 还是灰度
有次有幸听到了 AMS 广告营销服务线的一次分享,分享主有幸提到了在半个月内将所有的模块由 gcc4 升级到 gcc7,并因此推断此单仓的方案能够非常有效的解决遗留债务的问题。但还是那句话,如果抛开业务的特性,很难说任何方案都具有普适性。在微信支付内(特别是收付退结核心产品),在几天内就将所有的模块升级 gcc 大版本是非常不能被接受的。
- 你无法保证 gcc 升级之后一些语法上的特性导致业务上行为的变更(如 C++11 去掉 string cow 特性);
- 你无法保证某些业务在 gcc 升级之后依然保证可以独立编译成功(如 C++11 修改了 map 的 insert 方法的函数签名);
- 你无法保证修改后的代码是可以兼容其他的第三方库的,其他的第三方库是不是需要同步升级;
支付这边的做法是:
- 在伏羲平台中新建一个编译账户;
- 对于基础库和依赖的组件配置低版本 gcc 的分支,并保留一段时间;
- 业务代码使用这个编译账户来构建低版本 gcc 的产物,并使用正常的编译账户构建高版本 gcc 产物;
- 逐步迁移仓库到高版本 gcc,并保持可回退编译的能力;
- 当所有仓库都迁移到高版本 gcc 一段时间后再废弃掉升级时所用的编译账户。
开源治理的思想应该是指定大的方针方向(比如我们要构建开源协同的文化氛围 Oteam,构建开源协同的工具工蜂、Tapd、iWiKi等),而不是特别钦定必须使用哪一中具体的特定解决方案。解决方案应该是“接地气”的和业务相关的一组策略的组合,而非强调必须使用这一组合中某个特定的工具,最终寄希望这一特定工具来解决所有问题。
结语
把上文的要论述的部分整理成一份脑图分享一下。
