iOS底层 - 销毁 一个 单例
前言
单例,我们开发中使用很频繁的一种设计,你有没有想过,
- 为什么其会在app生命周期中只执行一次?
- 系统底层做了哪些事情来实现的呢?
- 再一点,单例可不可以销毁呢?
带着这些疑问,我们开始今天的内容。
单例
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
class = [[self alloc] init];
});单利中最重要的两个参数 一个是 onceToken, 一个是 block。
核心内容有两点:
- 为什么单利会调用一次?
- 单利的这个block为什么会进行调用?
首先,我们先写一个单例来断点调试看一下:
+ (instancetype)shareSM {
static SMObject *class = nil;
static dispatch_once_t predicate;
NSLog(@"1:%ld", predicate);
dispatch_once(&predicate, ^{
NSLog(@"2:%ld", predicate);
class = [[SMObject alloc] init];
});
NSLog(@"3:%ld", predicate);
return class;
}在执行到 dispatch_once 函数的 block 中的时候,我们 bt 下看下堆栈信息:
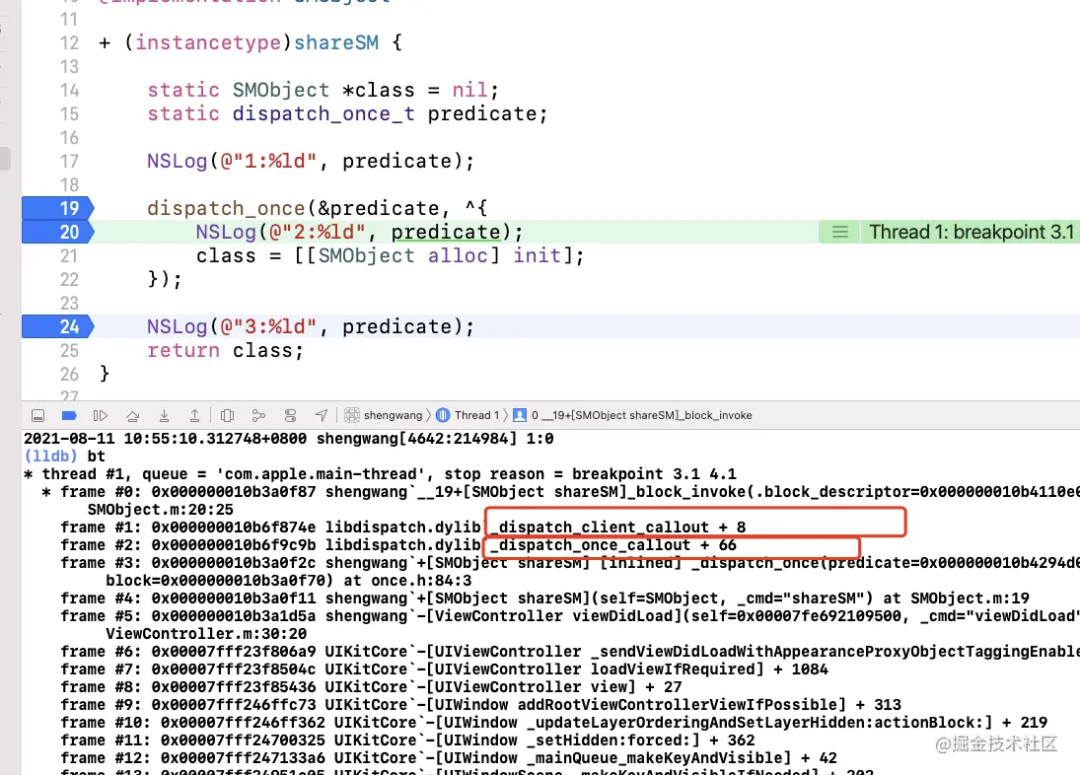
我们第一次调用 sharSM 方法的时候 程序执行来到了:
_dispatch_once_callout -> _dispatch_client_callout
我们之前有过GCD源码探索的经验,明显这个 block 是在 dispatchclient_callout 函数中调用执行了。此处的堆栈信息也是进一步做了验证。 可以看到程序执行的过程中, 参数 predicate 的值:
- 最开始是 0 ;
- block 执行过程中 变为了 256;
- 最后在return 之前 变为了 -1.
接下来,我们就看一下 diapatch_once 函数的底层源码实现:
dispatch_once
void
dispatch_once(dispatch_once_t *val, dispatch_block_t block)
{
dispatch_once_f(val, block, _dispatch_Block_invoke(block));
}dispatch_once_f
void
dispatch_once_f(dispatch_once_t *val, void *ctxt, dispatch_function_t func)
{
dispatch_once_gate_t l = (dispatch_once_gate_t)val;
#if !DISPATCH_ONCE_INLINE_FASTPATH || DISPATCH_ONCE_USE_QUIESCENT_COUNTER
uintptr_t v = os_atomic_load(&l->dgo_once, acquire);
// 状态为 DLOCK_ONCE_DONE 直接返回
if (likely(v == DLOCK_ONCE_DONE)) {
return;
}
#if DISPATCH_ONCE_USE_QUIESCENT_COUNTER
if (likely(DISPATCH_ONCE_IS_GEN(v))) {
return _dispatch_once_mark_done_if_quiesced(l, v);
}
#endif
#endif
// 第一次进来 获取锁, 原子操作多线程处理
if (_dispatch_once_gate_tryenter(l)) {
//执行调用
return _dispatch_once_callout(l, ctxt, func);
}
// 有锁锁住的话 会 等待开锁
return _dispatch_once_wait(l);
}跟着 dispatch_once_f 函数内部流程我们解释一下,调用一次是因为:内部实现的 val (也就是 static dispatch_once_t predicate )底层会封装成dispatch_once_gate_t , 这个变量用来获取底层原子性的一个关联。关联一个 uintptr_t 类型 v的一个变量,用来查询。当前的 onceToken是一个全局的静态变量。根据每个单利不同,每个静态变量也不同。为了保证唯一性,在底层使用类似KVC的形式通过 os_atomic_load 出来。如果取出来的值为 DLOCK_ONCE_DONE 了:已经处理过一次了,就retune返回出去了。当第一次代码执行进来的时候:为了保证线程的安全性把自己锁起来,保证当前任务执行的唯一,防止相同的onceToken进行多次执行。锁住之后进行 block 的调用执行。调用完毕后将锁解开,于此同时会将 v 的值 置为 DLOCK_ONCE_DONE(下次就不会在进入到调用block流程)。所以保证了单利的唯一性。
_dispatch_once_callout
static void
_dispatch_once_callout(dispatch_once_gate_t l, void *ctxt,
dispatch_function_t func)
{
_dispatch_client_callout(ctxt, func);
// 处理完成之后 进行广播
_dispatch_once_gate_broadcast(l);
}
...
static inline void
_dispatch_once_gate_broadcast(dispatch_once_gate_t l)
{
dispatch_lock value_self = _dispatch_lock_value_for_self();
uintptr_t v;
#if DISPATCH_ONCE_USE_QUIESCENT_COUNTER
v = _dispatch_once_mark_quiescing(l);
#else
v = _dispatch_once_mark_done(l);
#endif
if (likely((dispatch_lock)v == value_self)) return;
_dispatch_gate_broadcast_slow(&l->dgo_gate, (dispatch_lock)v);
}
...
static inline uintptr_t
_dispatch_once_mark_done(dispatch_once_gate_t dgo)
{
// 先匹配 再改变为 DLOCK_ONCE_DONE 的状态
// 下次 判断为 DLOCK_ONCE_DONE 状态,就无法进来
return os_atomic_xchg(&dgo->dgo_once, DLOCK_ONCE_DONE, release);
}_dispatch_once_gate_broadcast
static inline void
_dispatch_once_gate_broadcast(dispatch_once_gate_t l)
{
dispatch_lock value_self = _dispatch_lock_value_for_self();
uintptr_t v;
#if DISPATCH_ONCE_USE_QUIESCENT_COUNTER
v = _dispatch_once_mark_quiescing(l);
#else
v = _dispatch_once_mark_done(l);
#endif
if (likely((dispatch_lock)v == value_self)) return;
_dispatch_gate_broadcast_slow(&l->dgo_gate, (dispatch_lock)v);
}
...
static inline uintptr_t
_dispatch_once_mark_done(dispatch_once_gate_t dgo)
{
return os_atomic_xchg(&dgo->dgo_once, DLOCK_ONCE_DONE, release);
}如何销毁 ?
我们稍微修改下单例的内部实现:
+ (instancetype)shareSM {
static SMObject *class = nil;
static dispatch_once_t predicate;
NSLog(@"1:%ld", predicate);
predicate = 0;
NSLog(@"1-1 :%ld", predicate);
dispatch_once(&predicate, ^{
NSLog(@"2:%ld", predicate);
class = [[SMObject alloc] init];
});
NSLog(@"3:%ld", predicate);
return class;
}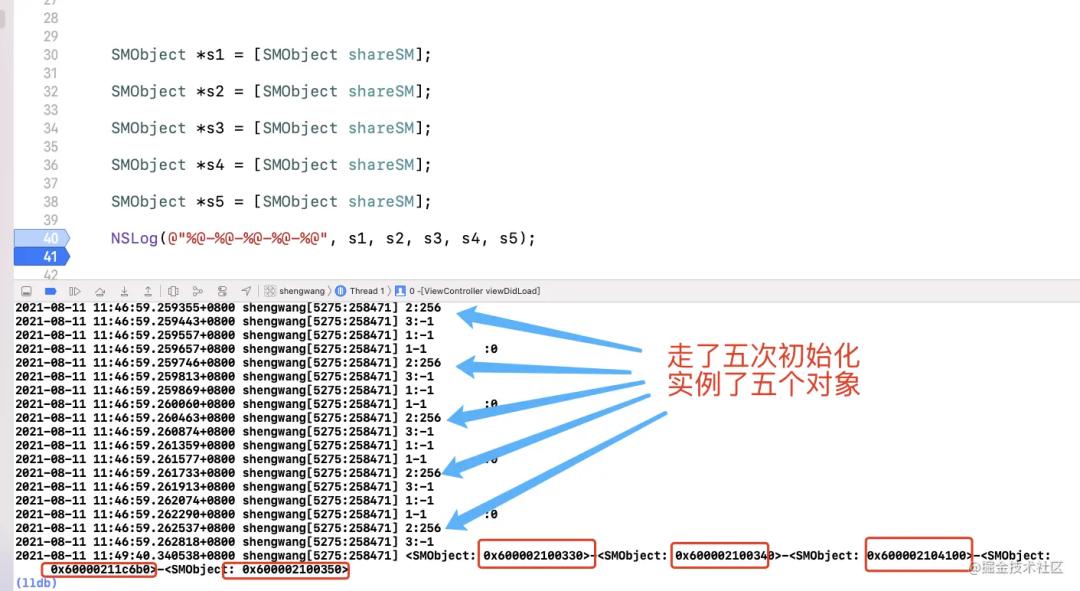
通过日志内容可以发现:修改predicate 的 值 之后,每一次都会初始化一个新的对象。那么, 我们就可以通过设置predicate的值,来达到控制单例初始化次数的目的。
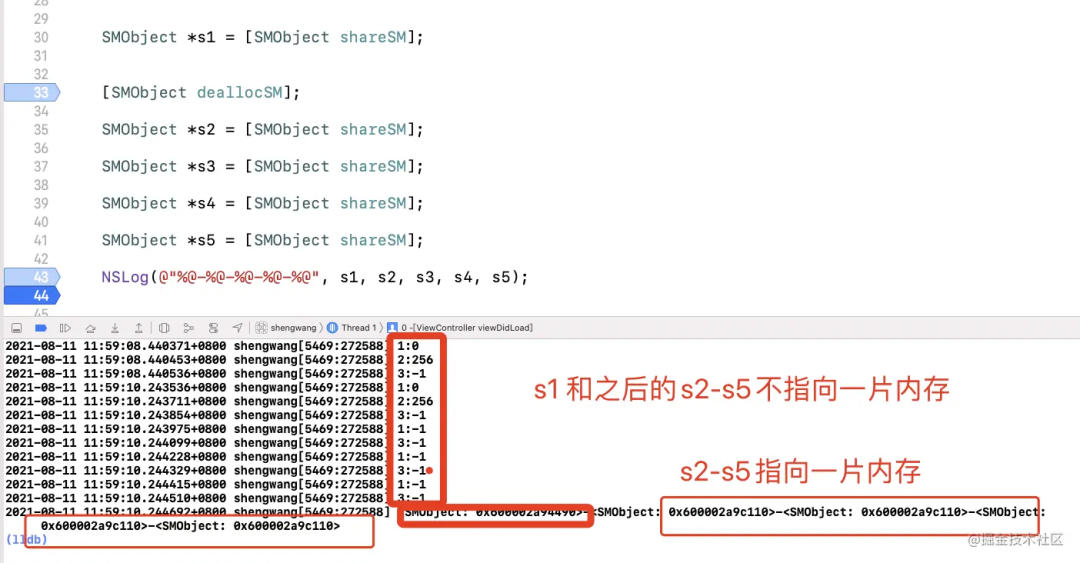
那么, dealocSM 方法如何实现的呢?
+ (void)deallocSM {
predicate = 0;
class = nil;
}同时 , 这两部分需要 从 shareSM 中提取出来,放到类中:
static SMObject *class = nil;
static dispatch_once_t predicate;这样,就可以实现单例的销毁。
线程安全吗?
_dispatch_once_gate_tryenter(l)
static inline bool
_dispatch_once_gate_tryenter(dispatch_once_gate_t l)
{
return os_atomic_cmpxchg(&l->dgo_once, DLOCK_ONCE_UNLOCKED,
(uintptr_t)_dispatch_lock_value_for_self(), relaxed);
}这里是原子操作,对于锁的处理,并且对线程操作进行控制。_dispatch_lock_value_for_self 对于当前自己队列中的线程空间的锁,防止多线程操作 。为了保证线程的安全性把自己锁起来,保证当前任务执行的唯一,防止相同的onceToken进行多次执行。是对多线程的封装处理。