聊聊前端截长图这件破事
为啥说前端截图是件破事呢?因为它相比与移动端来说,太难了,移动端一个 API 搞定!
前端截图主要有两个思路:
思路一:canvas、svg
利用原生 api 直接导出图片,有 canvas、svg,也就是说如果你想导出图片,前提是页面是通过 canvas 或者是 svg 实现的,或者能够转换成这两种。
先说 canvas
canvas 相当于给你提供了一个画布,然后需要你把想要显示的内容画到这个画布上。这种方式对于简单的页面还好,如果对于复杂页面来说,实现成本就太高了。
但是现实中,我们的前端页面使用的都是 HTML,那么如何把 HTML 转换成 canvas?最为典型的开源库是 html2canvas,它的原理就是把 DOM 转换成 canvas。但它处理复杂的 DOM 结构无法正常工作。
canvas 可支持转换成 data:url 和 Blob 对象:
var canvas = document.getElementById('canvas');
canvas.toBlob(function(blob) {
var newImg = document.createElement('img'),
url = URL.createObjectURL(blob);
newImg.onload = function() {
// no longer need to read the blob so it's revoked
URL.revokeObjectURL(url);
};
newImg.src = url;
document.body.appendChild(newImg);
});var canvas = document.getElementById('canvas');
var dataURL = canvas.toDataURL();
console.log(dataURL);
// "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAUAAAAFCAYAAACNby
// blAAAADElEQVQImWNgoBMAAABpAAFEI8ARAAAAAElFTkSuQmCC"再谈 svg
svg 可以转换成 data:url,有了 data:url 就可以转换成图片。但网页大多数都是 HTML,想要导出图片,必须要把 HTML 转换成 SVG。SVG 中提供了
<body>
<svg viewBox="0 0 200 200" xmlns="http://www.w3.org/2000/svg">
<style>
div {
color: white;
font: 18px serif;
}
</style>
<polygon points="5,5 195,10 185,185 10,195" />
<!-- 把HTML嵌入到 svg 中 -->
<foreignObject x="20" y="20" width="160" height="160">
<div xmlns="http://www.w3.org/1999/xhtml">
和素燕一起学习前端,《前端小课》帮助10W人入门并进阶前端
</div>
</foreignObject>
</svg>
</body> 
利用这一特性就可以把 DOM 嵌入到 SVG,从而可以实现导出图片。业界有现成的方案 dom-to-image,它比 html2canvas 好多了,对于结构复杂的 HTML,它表现更好。唯一的缺点是兼容性不是很好,不支持 IE。关于 IE 兼容的讨论,以前写过:[微软365将放弃IE11,你却仍支持IE9?]
canvas 和 svg 的方式各有自己的优缺点,开源方案都不能在小程序中使用,但 svg 的方式比 canvas 好一些,svg 有兼容问题。除了在前端截图外,其实还可以在后端使用「无头浏览器截图」。
比如谷歌浏览器截图,点击下面按钮即可截取一张长图,如果我们能够调用这个能力,那截图就容易多了,但是前端根本没有提供这个 api:
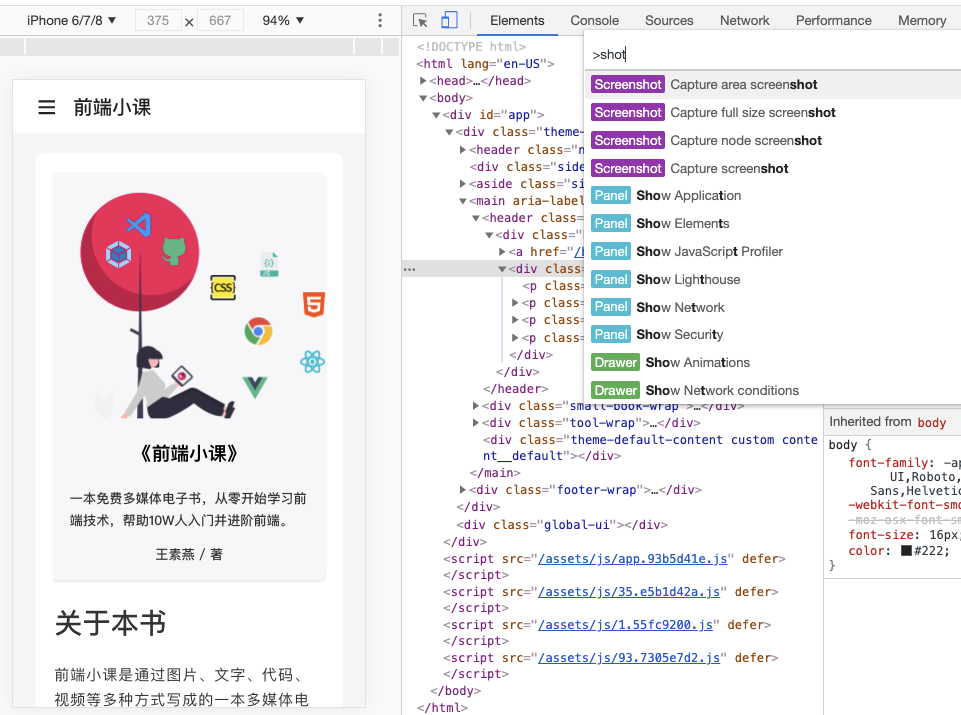
思路二:无头浏览器
先来普及下啥是个无头(headless)浏览器。顾名思义,就是一个你看不到任何界面的浏览器,可以通过一些命令来操作浏览器,来模拟用户的行为,我举个截图的例子,以 puppteer 为例:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
await page.screenshot({ path: 'example.png' });
await browser.close();
})();有了它能做什么?
1、把网页保存成图片或者PDF;
2、爬虫,很多爬虫都是基于这个实现;
3、表单自动提交、UI测试、模拟用户输入;
4、测试 Chrome 插件;
关于无头浏览器我主要说两个:
PhantomJS
很早以前这个比较火,但目前该项目已不再维护,可通过命令行的方式对网页进行截图。下载 mac 版本,通过命令行来截取一下前端小课的网站:
./bin/phantomjs ./examples/rasterize.js http://lefex.gitee.io/ ./suyan.png
结果让人很失望,猜测原因是我的网站使用了 flex 布局 [6k 字总结 flexbox 布局 ,收藏就行] ,而 phantomJS 采用的浏览器内核不支持该特性:
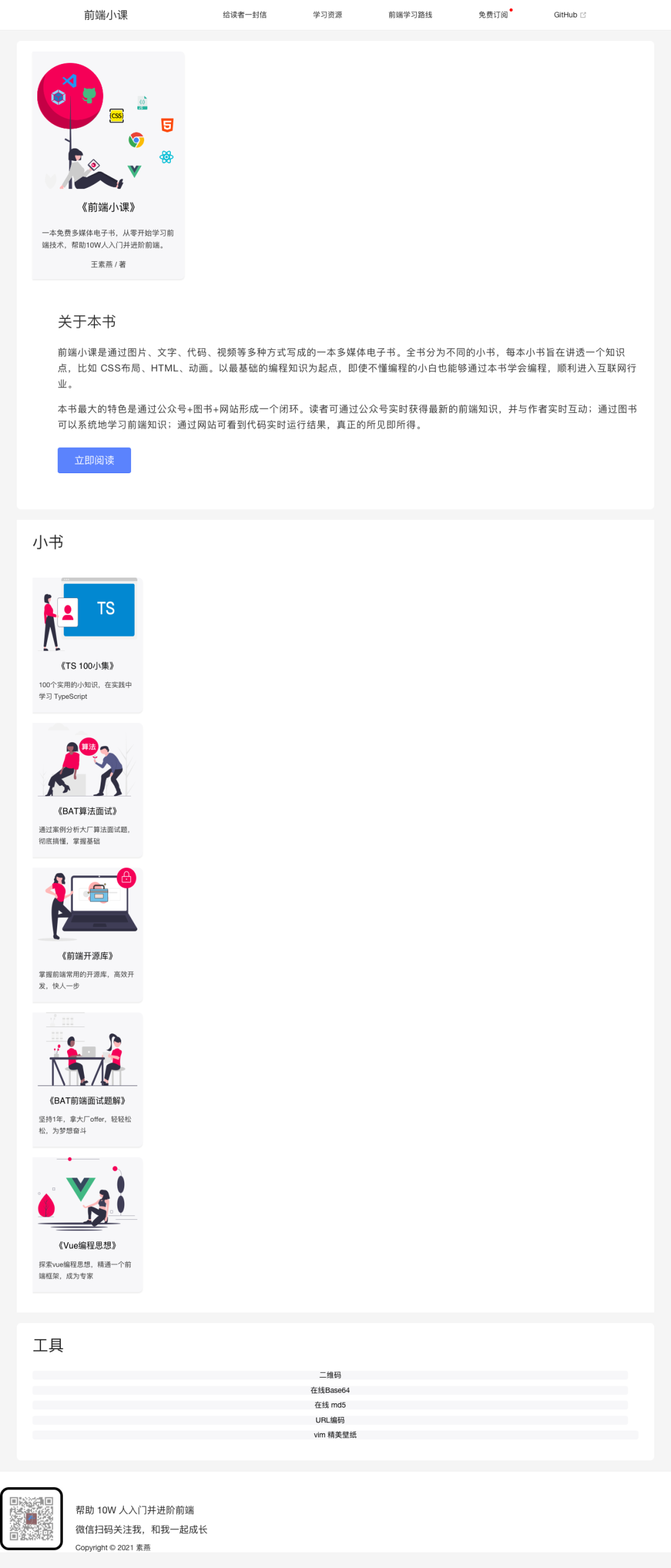
可能还会有很多问题,只能遇到问题不断解决,它唯一的优点是在 Linux 上部署简单。
Puppeteer
由 Chrome 开发团队在 2017 年发布的一个 Node.js 包,在 Mac 上安装非常简单,可通过 npm 直接安装:
npm 比较慢,可以换成 cnpm
npm i puppeteer同样我们来截一下前端小课网站的图:
const websiteUrl = 'https://lefex.github.io/';
(async () => {
// 启动 puppeteer
const browser = await puppeteer.launch({
args: ['--no-sandbox']
});
// 打开浏览器后,创建一个新的页面
const page = await browser.newPage();
// 设置页面的尺寸,可以模拟手机、PC不同的设备
await page.setViewport({
width: 1280,
height: 1400
});
// 打开一个页面
await page.goto(websiteUrl);
// 页面渲染完毕后,开始截图,全屏
await page.screenshot({
path: './shot.jpeg',
fullPage: true,
type: 'jpeg',
quality: 100
});
})();截出来的效果如下,发现结果很完美:
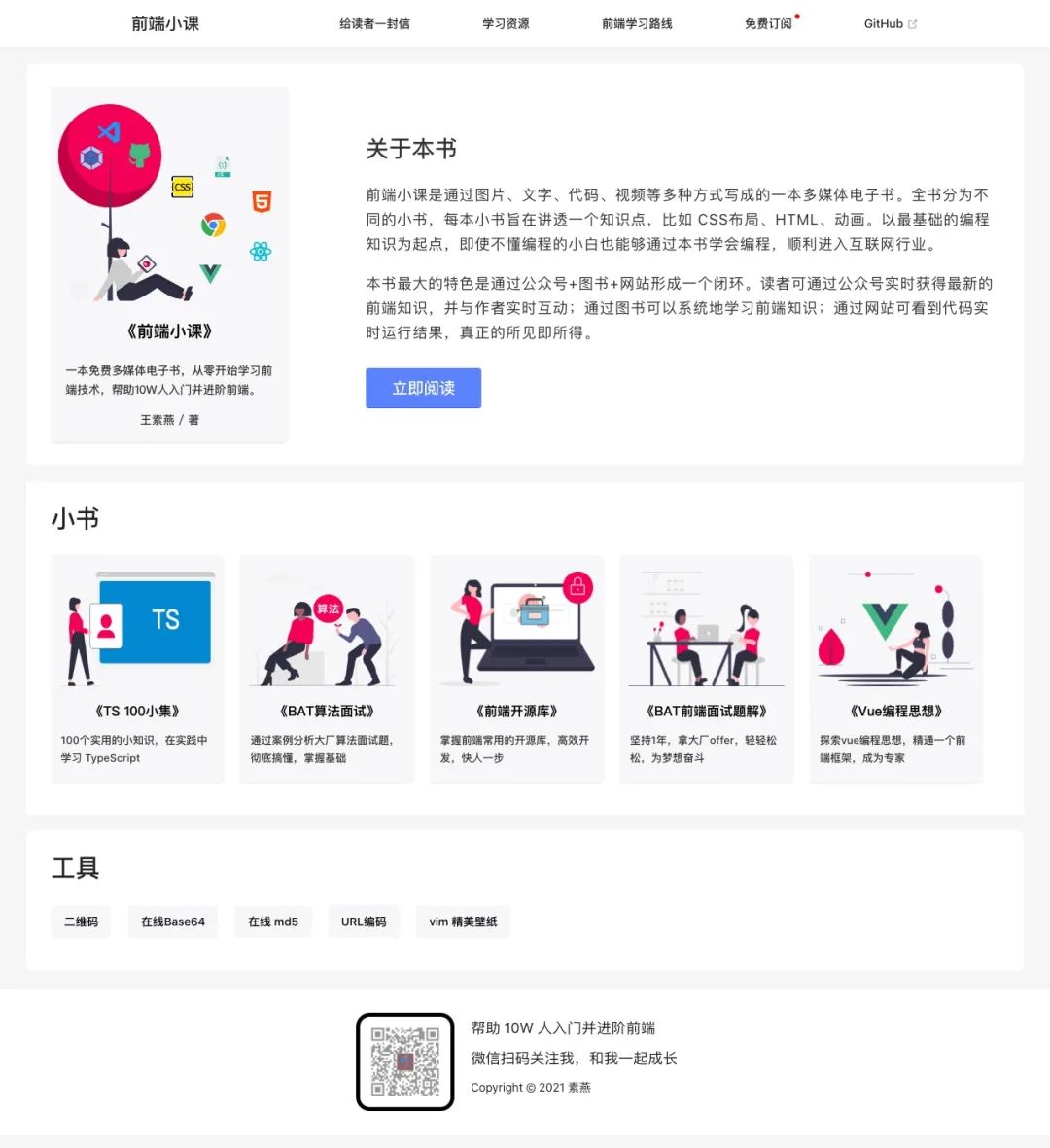
但是它在 Linux 部署起来有点吃力,如果对于单台物理机器还好,如果是集群,只能进行自动化部署。不过可以借助于 Docker 镜像来部署:
https://hub.docker.com/r/alekzonder/puppeteer/。
无头浏览器的方式虽好,但是截图比较慢,我统计了下截取一张长图大约 3-4s,当然取决于测试的机器。
关于截图,以前也写过几篇文章:
[FGD · 把网页截图分享]
[还不知道 Puppeteer 的注意了,它能干大事]
总之,截图真是一件破事,大家加油!!!!
最后,请教一下大家,你的 Puppteer 采用的是哪种部署方式,欢迎交流讨论。