Go 程序崩了?还不快用 PProf 工具来救火!
这次分享《[Go 语言编程之旅] 》中的性能分析大杀器 PProf,文章字数有 1w3+ 字,我想应该是目前业界比较全的 PProf 文章了。
希望借此让更多的 Go 语言爱好者搞懂 PProf 的使用,以便在成为救火队长时,都能够脱颖而出,成为团队核心主力,实现晚上 7 点下班。
本文目录如下:

觉得不错的话,欢迎点赞和转发给更多小伙伴们看到,感谢。
前言
应用程序在运行时,总是会出现一些你所意料不到的问题,像是跑着跑着突然报警,监控提示你进程 CPU 使用率过高、内存占用不断增大(疑似泄露)、临时内存大量申请后长时间内不滑,又或是 Goroutine 泄露、出现 Goroutine 数量暴涨,并且持续保持,甚至是莫名其妙在某次迭代发布后的数小时内出现了应用程序无法提供服务的问题...
这发生起来的话,是多么的让人感到担忧,那么除了在我们平时要做好各类防护以外,在问题正在发生时,我们又有什么办法排查呢,因此在这个章节,我们将介绍排查办法之一,也就是 Go 语言的性能剖析大杀器 PProf 工具链,它是 Go 语言中必知必会的技能点。
PProf 是什么
在 Go 语言中,PProf 是用于可视化和分析性能分析数据的工具,PProf 以 profile.proto 读取分析样本的集合,并生成报告以可视化并帮助分析数据(支持文本和图形报告)。
而刚刚提到的 profile.proto 是一个 Protobuf v3 的描述文件,它描述了一组 callstack 和 symbolization 信息, 作用是统计分析的一组采样的调用栈,是很常见的 stacktrace 配置文件格式。
有哪几种采样方式
- runtime/pprof:采集程序(非 Server)的指定区块的运行数据进行分析。
- net/http/pprof:基于HTTP Server运行,并且可以采集运行时数据进行分析。
- go test:通过运行测试用例,并指定所需标识来进行采集。
支持什么使用模式
- Report generation:报告生成。
- Interactive terminal use:交互式终端使用。
- Web interface:Web 界面。
可以做什么
- CPU Profiling:CPU 分析,按照一定的频率采集所监听的应用程序 CPU(含寄存器)的使用情况,可确定应用程序在主动消耗 CPU 周期时花费时间的位置。
- Memory Profiling:内存分析,在应用程序进行堆分配时记录堆栈跟踪,用于监视当前和历史内存使用情况,以及检查内存泄漏。
- Block Profiling:阻塞分析,记录Goroutine阻塞等待同步(包括定时器通道)的位置,默认不开启,需要调用
runtime.SetBlockProfileRate进行设置。 - Mutex Profiling:互斥锁分析,报告互斥锁的竞争情况,默认不开启,需要调用
runtime.SetMutexProfileFraction进行设置。 - Goroutine Profiling:Goroutine 分析,可以对当前应用程序正在运行的 Goroutine 进行堆栈跟踪和分析。
其中像是 Goroutine Profiling 这项功能会在实际排查中会经常用到。
因为很多问题出现时的表象就是 Goroutine 暴增,而这时候我们要做的事情之一就是查看应用程序中的 Goroutine 正在做什么事情,因为什么阻塞了,然后再进行下一步。
介绍和使用
一个简单的例子
我们新建一个 main.go 文件,用于后续的应用程序分析和示例展示,写入如下代码:
var datas []string
func main() {
go func() {
for {
log.Printf("len: %d", Add("go-programming-tour-book"))
time.Sleep(time.Millisecond * 10)
}
}()
_ = http.ListenAndServe("0.0.0.0:6060", nil)
}
func Add(str string) int {
data := []byte(str)
datas = append(datas, string(data))
return len(datas)
}接下来最重要的一步,就是在 import 中添加 _ "net/http/pprof" 的引用,如下:
import (
_ "net/http/pprof"
...
)接下来我们运行这个程序,访问 http://127.0.0.1:6060/debug/pprof/ 地址,检查是否正常响应。
通过浏览器访问
第一种方式,我们可以直接通过浏览器,进行查看,那么在第一步我们可以先查看总览页面,也就是访问 http://127.0.0.1:6060/debug/pprof/,如下:
/debug/pprof/
Types of profiles available:
Count Profile
3 allocs
0 block
0 cmdline
8 goroutine
3 heap
0 mutex
0 profile
11 threadcreate
0 trace
full goroutine stack dump- allocs:查看过去所有内存分配的样本,访问路径为
$HOST/debug/pprof/allocs。 - block:查看导致阻塞同步的堆栈跟踪,访问路径为
$HOST/debug/pprof/block。 - cmdline:当前程序的命令行的完整调用路径。
- goroutine:查看当前所有运行的 goroutines 堆栈跟踪,访问路径为
$HOST/debug/pprof/goroutine。 - heap:查看活动对象的内存分配情况, 访问路径为
$HOST/debug/pprof/heap。 - mutex:查看导致互斥锁的竞争持有者的堆栈跟踪,访问路径为
$HOST/debug/pprof/mutex。 - profile:默认进行 30s 的 CPU Profiling,得到一个分析用的 profile 文件,访问路径为
$HOST/debug/pprof/profile。 - threadcreate:查看创建新OS线程的堆栈跟踪,访问路径为
$HOST/debug/pprof/threadcreate。
如果你在对应的访问路径上新增 ?debug=1 的话,就可以直接在浏览器访问,如下:
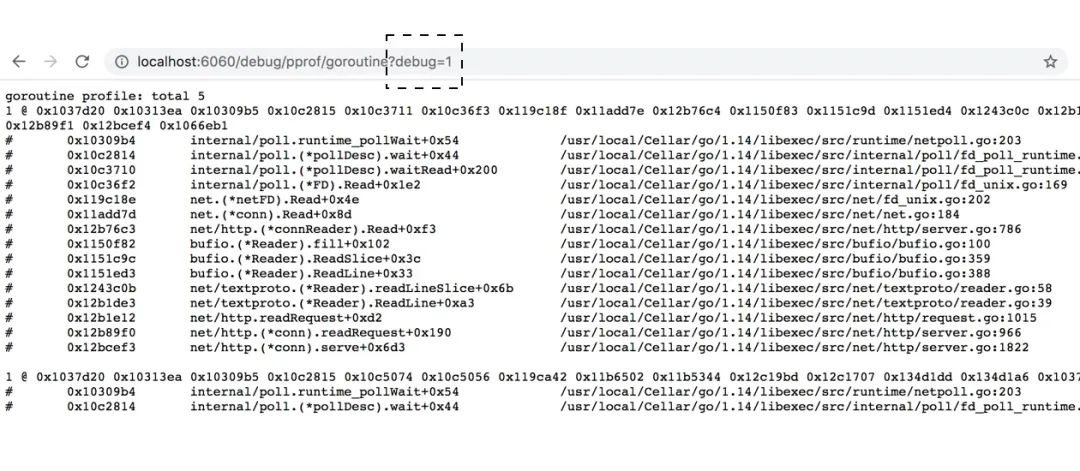
若不新增 debug 参数,那么将会直接下载对应的profile文件。
再展开来讲,在部署环境中,我们为了网络安全,通常不会直接对外网暴露 pprof 的相关端口,因此会通过 curl、wget 等方式进行 profile 文件的间接拉取。
另外还有一点需要注意,debug 的访问方式是具有时效性的,在实际场景中,我们常常需要及时将当前状态下的 profile 文件给存储下来,便于二次分析。
通过交互式终端使用
第二种方式,我们可以直接通过命令行,来完成对正在运行的应用程序 pprof 的抓取和分析。
CPU Profiling
$ go tool pprof http://localhost:6060/debug/pprof/profile\?seconds\=60
Fetching profile over HTTP from http://localhost:6060/debug/pprof/profile?seconds=60
Saved profile in /Users/eddycjy/pprof/pprof.samples.cpu.002.pb.gz
Type: cpu
Duration: 1mins, Total samples = 37.25s (61.97%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)执行该命令后,需等待 60 秒(可调整 seconds 的值),pprof 会进行 CPU Profiling,结束后将默认进入 pprof 的命令行交互式模式,可以对分析的结果进行查看或导出。另外如果你所启动的 HTTP Server 是 TLS 的方式,那么在调用 go tool pprof 时,需要将调用路径改为:go tool pprof https+insecure://localhost:6060/debug/pprof/profile\?seconds\=60。
接下来我们输入查询命令 top10 ,以此查看对应资源开销(例如:CPU 就是执行耗时/开销、Memory 就是内存占用大小)排名前十的函数,如下:
(pprof) top10
Showing nodes accounting for 36.23s, 97.26% of 37.25s total
Dropped 80 nodes (cum <= 0.19s)
Showing top 10 nodes out of 34
flat flat% sum% cum cum% Name
32.63s 87.60% 87.60% 32.70s 87.79% syscall.syscall
0.87s 2.34% 89.93% 0.88s 2.36% runtime.stringtoslicebyte
0.69s 1.85% 91.79% 0.69s 1.85% runtime.memmove
0.52s 1.40% 93.18% 0.52s 1.40% runtime.nanotime
...
(pprof) - flat:函数自身的运行耗时。
- flat%:函数自身在 CPU 运行耗时总比例。
- sum%:函数自身累积使用 CPU 总比例。
- cum:函数自身及其调用函数的运行总耗时。
- cum%:函数自身及其调用函数的运行耗时总比例。
- Name:函数名。
在大多数的情况下,我们可以通过这五列得出一个应用程序的运行情况,知道当前是什么函数,正在做什么事情,占用了多少资源,谁又是占用资源的大头,以此来得到一个初步的分析方向。
另外在交互命令行中,pprof 还支持了大量的其它命令,具体可执行 pprof help 查看帮助说明。
Heap Profiling
$ go tool pprof http://localhost:6060/debug/pprof/heap
Fetching profile over HTTP from http://localhost:6060/debug/pprof/heap
Saved profile in /Users/eddycjy/pprof/pprof.alloc_objects.alloc_space.inuse_objects.inuse_space.011.pb.gz
Type: inuse_space
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)执行该命令后,能够很快的拉取到其结果,因为它不需要像 CPU Profiling 做采样等待,这里需要注意的一点是 Type 这一个选项,你可以看到它默认显示的是 inuse_space,实际上可以针对多种内存概况进行分析,常用的类别如下:
- inuse_space:分析应用程序的常驻内存占用情况。
$ go tool pprof -inuse_space http://localhost:6060/debug/pprof/heap
(pprof) top
Showing nodes accounting for 4.01GB, 100% of 4.01GB total
flat flat% sum% cum cum%
4.01GB 100% 100% 4.01GB 100% main.Add
0 0% 100% 4.01GB 100% main.main.func1- alloc_objects:分析应用程序的内存临时分配情况。
$ go tool pprof -alloc_objects http://localhost:6060/debug/pprof/heap
(pprof) top
Showing nodes accounting for 215552550, 100% of 215560746 total
Dropped 14 nodes (cum <= 1077803)
flat flat% sum% cum cum%
86510197 40.13% 40.13% 86510197 40.13% main.Add
85984544 39.89% 80.02% 85984544 39.89% fmt.Sprintf
43057809 19.97% 100% 215552550 100% main.main.func1
0 0% 100% 85984544 39.89% log.Printf另外还有 inuse_objects 和 alloc_space 类别,分别对应查看每个函数所分别的对象数量和查看分配的内存空间大小,具体可根据情况选用。
Goroutine Profiling
$ go tool pprof http://localhost:6060/debug/pprof/goroutine
Fetching profile over HTTP from http://localhost:6060/debug/pprof/goroutine
Saved profile in /Users/eddycjy/pprof/pprof.goroutine.003.pb.gz
Type: goroutine
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) 在查看 goroutine 时,我们可以使用traces命令,这个命令会打印出对应的所有调用栈,以及指标信息,可以让我们很便捷的查看到整个调用链路有什么,分别在哪里使用了多少个 goroutine,并且能够通过分析查看到谁才是真正的调用方,输出结果如下:
(pprof) traces
Type: goroutine
-----------+-------------------------------------------------------
2 runtime.gopark
runtime.netpollblock
internal/poll.runtime_pollWait
...
-----------+-------------------------------------------------------
1 runtime.gopark
runtime.netpollblock
...
net/http.ListenAndServe
main.main
runtime.main在调用栈上来讲,其展示顺序是自下而上的,也就是 runtime.main 方法调用了 main.main 方法,main.main 方法又调用了 net/http.ListenAndServe 方法,这里对应的也就是我们所使用的示例代码了,排查起来会非常方便。
每个调用堆栈信息用 ----------- 分割,函数方法前的就是指标数据,像 Goroutine Profiling 展示是就是该方法占用的 goroutine 的数量。而 Heap Profiling 展示的就是占用的内存大小,如下:
$ go tool pprof http://localhost:6060/debug/pprof/heap
...
Type: inuse_space
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) traces
Type: inuse_space
-----------+-------------------------------------------------------
bytes: 13.55MB
13.55MB main.Add
main.main.func1
-----------+-------------------------------------------------------实际上 pprof 中的所有功能都会根据不同的 Profile 类型展示不同的对应结果。
Mutex Profiling
怎么样的情况下会造成阻塞呢,一般有如下方式:调用 chan(通道)、调用 sync.Mutex (同步锁)、调用 time.Sleep() 等等。那么为了验证互斥锁的竞争持有者的堆栈跟踪,我们可以根据以上的 sync.Mutex 方式,来调整先前的示例代码,代码如下:
func init() {
runtime.SetMutexProfileFraction(1)
}
func main() {
var m sync.Mutex
var datas = make(map[int]struct{})
for i := 0; i < 999; i++ {
go func(i int) {
m.Lock()
defer m.Unlock()
datas[i] = struct{}{}
}(i)
}
_ = http.ListenAndServe(":6061", nil)
}需要特别注意的是 runtime.SetMutexProfileFraction 语句,如果未来希望进行互斥锁的采集,那么需要通过调用该方法来设置采集频率,若不设置或没有设置大于 0 的数值,默认是不进行采集的。
接下来我们进行调用 go tool pprof 进行分析,如下:
$ go tool pprof http://localhost:6061/debug/pprof/mutex
Fetching profile over HTTP from http://localhost:6061/debug/pprof/mutex
Saved profile in /Users/eddycjy/pprof/pprof.contentions.delay.010.pb.gz
Type: delay
Entering interactive mode (type "help" for commands, "o" for options)我们查看调用 top 命令,查看互斥量的排名:
(pprof) top
Showing nodes accounting for 653.79us, 100% of 653.79us total
flat flat% sum% cum cum%
653.79us 100% 100% 653.79us 100% sync.(*Mutex).Unlock
0 0% 100% 653.79us 100% main.main.func1接下来我们可以调用 list 命令,看到指定函数的代码情况(包含特定的指标信息,例如:耗时),若函数名不明确,默认会对函数名进行模糊匹配,如下:
(pprof) list main
Total: 653.79us
ROUTINE ======================== main.main.func1 in /eddycjy/main.go
0 653.79us (flat, cum) 100% of Total
. . 40: go func(i int) {
. . 41: m.Lock()
. . 42: defer m.Unlock()
. . 43:
. . 44: datas[i] = struct{}{}
. 653.79us 45: }(i)
. . 46: }
. . 47:
. . 48: err := http.ListenAndServe(":6061", nil)
. . 49: if err != nil {
. . 50: log.Fatalf("http.ListenAndServe err: %v", err)
(pprof) 我们可以在输出的分析中比较准确的看到引起互斥锁的函数在哪里,锁开销在哪里,在本例中是第 45 行。
Block Profiling
与 Mutex 的 runtime.SetMutexProfileFraction 相似,Block 也需要调用 runtime.SetBlockProfileRate() 进行采集量的设置,否则默认关闭,若设置的值小于等于 0 也会认为是关闭。
与上小节 Mutex 相比,主体代码不变,仅是新增 runtime.SetBlockProfileRate() 的调用,如下:
func init() {
runtime.SetBlockProfileRate(1)
...
}我们查看调用 top 命令,查看阻塞情况的排名:
$ go tool pprof http://localhost:6061/debug/pprof/block
Fetching profile over HTTP from http://localhost:6061/debug/pprof/block
Saved profile in /Users/eddycjy/pprof/pprof.contentions.delay.017.pb.gz
Type: delay
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 74.54ms, 100% of 74.54ms total
flat flat% sum% cum cum%
74.54ms 100% 100% 74.54ms 100% sync.(*Mutex).Lock
0 0% 100% 74.54ms 100% main.main.func1同样的,我们也可以调用 list 命令查看具体的阻塞情况,执行方式和排查模式与先前概述的一致。
查看可视化界面
接下来我们继续使用前面的示例程序,将其重新运行起来,然后在其它窗口执行下述命令:
$ wget http://127.0.0.1:6060/debug/pprof/profile
默认需要等待 30 秒,执行完毕后可在当前目录下发现采集的文件 profile,针对可视化界面我们有两种方式可进行下一步分析:
1 . 方法一(推荐):该命令将在所指定的端口号运行一个 PProf 的分析用的站点。
$ go tool pprof -http=:6001 profile
2 . 方法二:通过 web 命令将以 svg 的文件格式写入图形,然后在 Web 浏览器中将其打开。
$ go tool pprof profile
Type: cpu
Time: Feb 1, 2020 at 12:09pm (CST)
Duration: 30s, Total samples = 60ms ( 0.2%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) web如果出现错误提示 Could not execute dot; may need to install graphviz.,那么意味着你需要安装 graphviz组件。
另外方法一所运行的站点,实际上包含了方法二的内容(svg图片),并且更灵活,因此非特殊情况,我们会直接使用方法一的方式运行站点来做观察和分析。
剖析内容
通过 PProf 所提供的可视化界面,我们能够更方便、更直观的看到 Go 应用程序的调用链、使用情况等。另外在 View 菜单栏中,PProf 还支持多种分析方式的切换,如下:
接下来我们将基于 CPU Profiling 所抓取的 Profile 进行一一介绍,而其它 Profile 类型的分析模式也是互通的,只要我们了解了一种,其余的也就会了。
Top
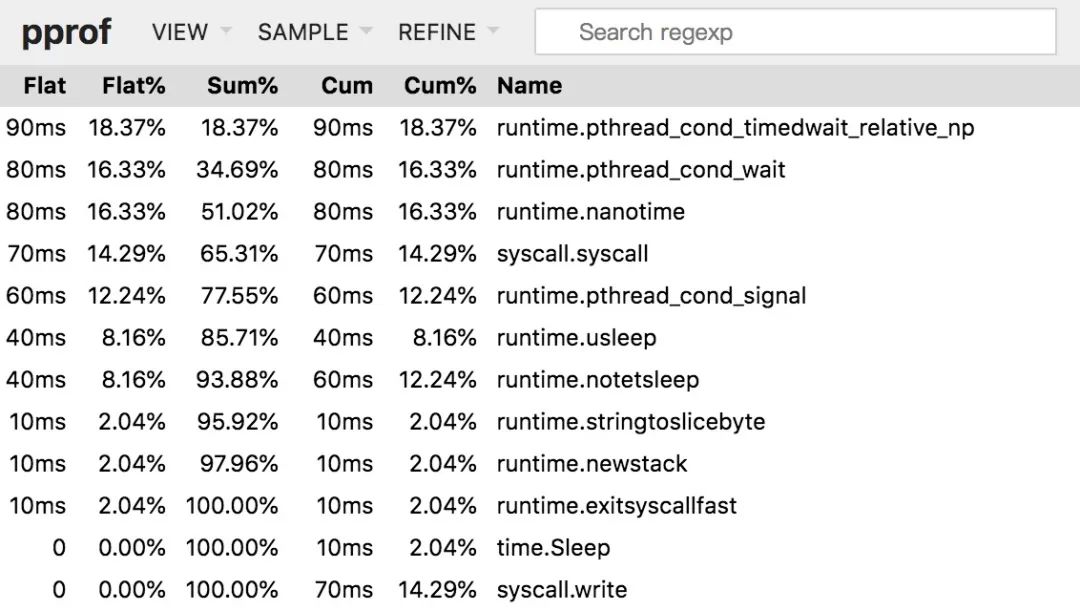
该视图与前面所讲解的 top 子命令的作用和含义是一样的,因此不再赘述。
Graph
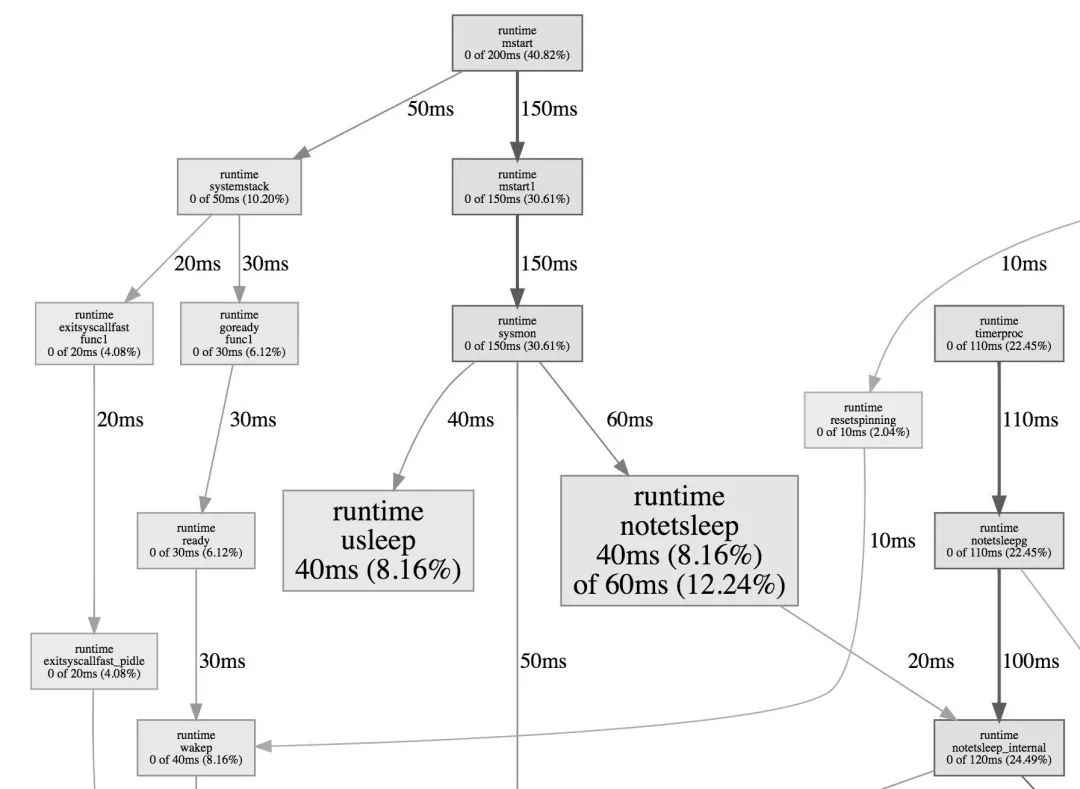
该视图展示的为整体的函数调用流程,框越大、线越粗、框颜色越鲜艳(红色)就代表它占用的时间越久,开销越大。相反若框颜色越淡,越小则代表在整体的函数调用流程中,它的开销是相对较小的。
因此我们可以用此视图去分析谁才是开销大头,它又是因为什么调用流程而被调用的。
Peek
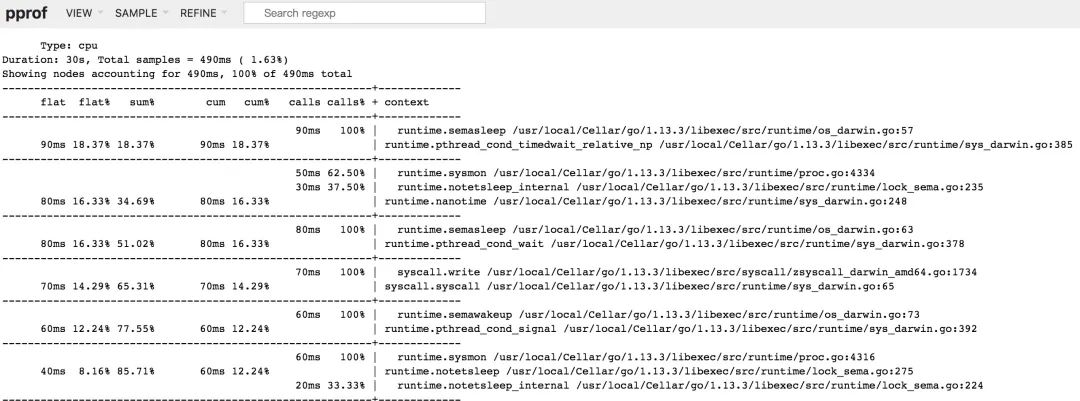
此视图相较于 Top 视图,增加了所属的上下文信息的展示,也就是函数的输出调用者/被调用者。
Source
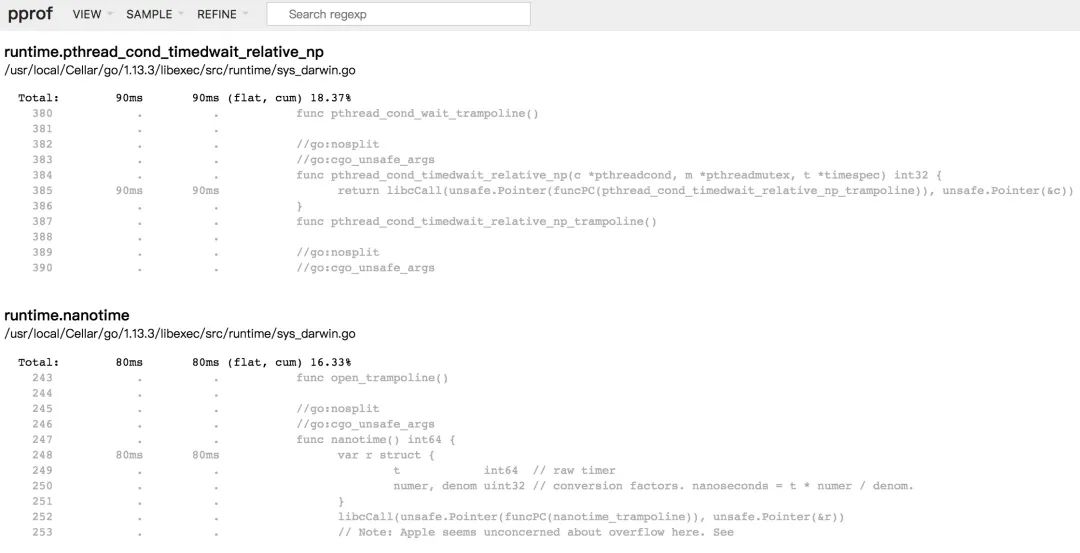
该视图主要是增加了面向源代码的追踪和分析,可以看到其开销主要消耗在哪里。
Flame Graph
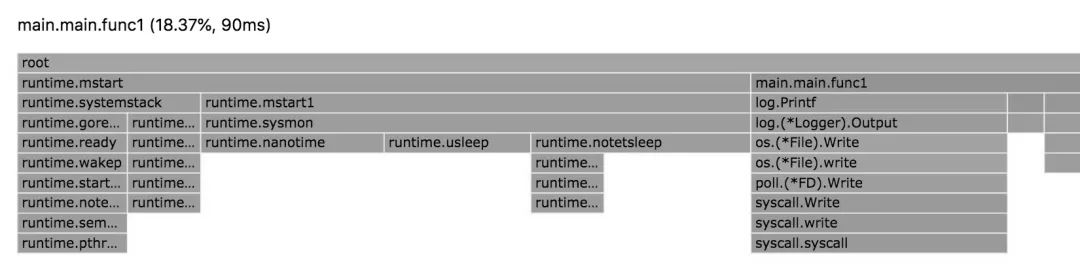
Flame Graph(火焰图)它是可动态的,调用顺序由上到下(A -> B -> C -> D),每一块代表一个函数、颜色越鲜艳(红)、区块越大代表占用 CPU 的时间更长。同时它也支持点击块深入进行分析。
我们选择页面上的 main.main.func1 区块,将会进入到其属下的下一层级,如下:

这样子我们就可以根据不同函数的多维度层级进行分析,能够更好的观察其流转并发现问题。
通过测试用例做剖析
在上述章节中,我们是通过在应用程序中埋入方法进行采集的,那么还有一种方式,能够更精准的剖析到你所想要分析的流程或函数。
首先我们将先前所编写的 Add 方法挪到独立的 package 中,命名为 add.go 文件,然后新建 add_test.go 文件,写入如下测试用例代码:
func TestAdd(t *testing.T) {
_ = Add("go-programming-tour-book")
}
func BenchmarkAdd(b *testing.B) {
for i := 0; i < b.N; i++ {
Add("go-programming-tour-book")
}
}在完成代码编写后,我们回到命令行窗口执行如下采集命令:
$ go test -bench=. -cpuprofile=cpu.profile
执行完毕后会在当前命令生成 cpu.profile 文件,然后只需执行 go tool pprof 命令就可以进行查看了,如下图:
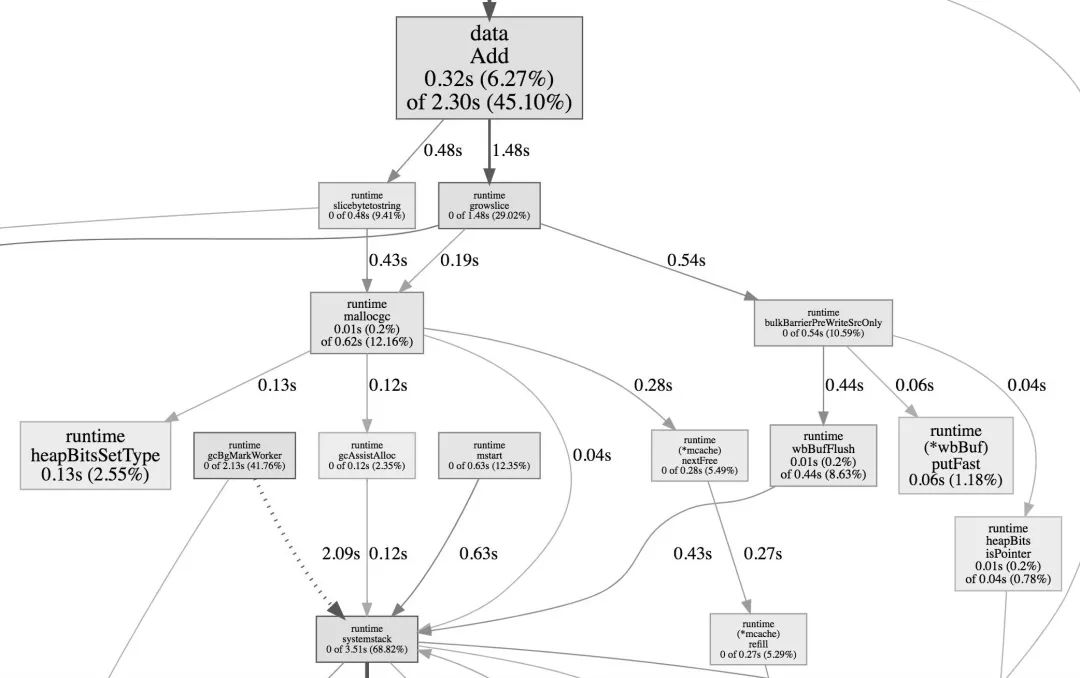
另外除了对 CPU 进行剖析以外,我们还可以调整选项,对内存情况进行分析,如下采集命令:
$ go test -bench=. -memprofile=mem.profile
接下来和上面一样,执行 go tool pprof 命令进行查看,如下图:
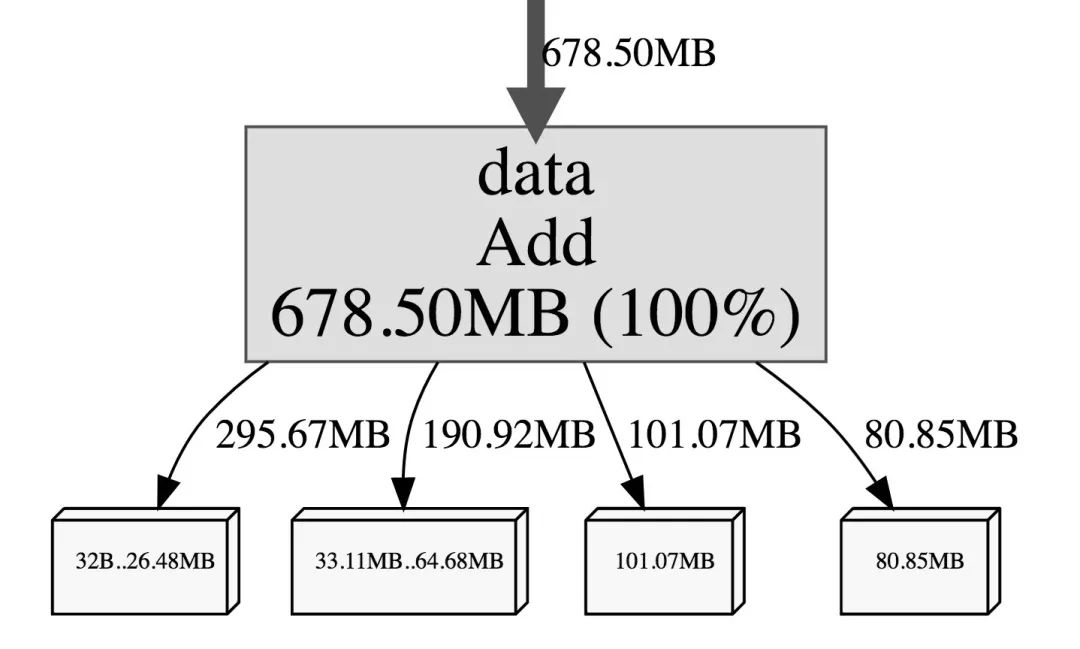
通过 Lookup 写入文件做剖析
除了注入 http handler 和 go test 以外,我们还可以在程序中通过 pprof 所提供的 Lookup 方法来进行相关内容的采集和调用。
其一共支持六种类型,分别是:
- goroutine。
- threadcreate。
- heap。
- block。
- mutex。
具体代码如下:
type LookupType int8
const (
LookupGoroutine LookupType = iota
LookupThreadcreate
LookupHeap
LookupAllocs
LookupBlock
LookupMutex
)
func pprofLookup(lookupType LookupType, w io.Writer) error {
var err error
switch lookupType {
case LookupGoroutine:
p := pprof.Lookup("goroutine")
err = p.WriteTo(w, 2)
case LookupThreadcreate:
p := pprof.Lookup("threadcreate")
err = p.WriteTo(w, 2)
case LookupHeap:
p := pprof.Lookup("heap")
err = p.WriteTo(w, 2)
case LookupAllocs:
p := pprof.Lookup("allocs")
err = p.WriteTo(w, 2)
case LookupBlock:
p := pprof.Lookup("block")
err = p.WriteTo(w, 2)
case LookupMutex:
p := pprof.Lookup("mutex")
err = p.WriteTo(w, 2)
}
return err
}接下来我们只需要对该方法进行调用就好了,其提供了 io.Writer 接口,也就是只要实现了对应的 Write 方法,我们可以将其写到任何支持地方去,如下:
...
func init() {
runtime.SetMutexProfileFraction(1)
runtime.SetBlockProfileRate(1)
}
func main() {
http.HandleFunc("/lookup/heap", func(w http.ResponseWriter, r *http.Request) {
_ = pprofLookup(LookupHeap, os.Stdout)
})
http.HandleFunc("/lookup/threadcreate", func(w http.ResponseWriter, r *http.Request) {
_ = pprofLookup(LookupThreadcreate, os.Stdout)
})
http.HandleFunc("/lookup/block", func(w http.ResponseWriter, r *http.Request) {
_ = pprofLookup(LookupBlock, os.Stdout)
})
http.HandleFunc("/lookup/goroutine", func(w http.ResponseWriter, r *http.Request) {
_ = pprofLookup(LookupGoroutine, os.Stdout)
})
_ = http.ListenAndServe("0.0.0.0:6060", nil)
}在上述代码中,我们将采集结果写入到了控制台上,我们可以进行一下验证,调用 http://127.0.0.1:6060/lookup/heap,控制台输出结果如下:
$ go run main.go
heap profile: 0: 0 [0: 0] @ heap/1048576
# runtime.MemStats
# Alloc = 180632
# TotalAlloc = 180632
# Sys = 69928960
# Lookups = 0
...为什么要初始化net/http/pprof
在我们的例子中,你会发现我们在引用上对 net/http/pprof 包进行了默认的初始化(也就是 _),如果你曾经漏了,或者没加,你会发现压根调用不了 pprof 的相关接口,这是为什么呢,我们一起看看下面该包的初始化方法,如下:
func init() {
http.HandleFunc("/debug/pprof/", Index)
http.HandleFunc("/debug/pprof/cmdline", Cmdline)
http.HandleFunc("/debug/pprof/profile", Profile)
http.HandleFunc("/debug/pprof/symbol", Symbol)
http.HandleFunc("/debug/pprof/trace", Trace)
}实际上 net/http/pprof 会在初始化函数中对标准库中 net/http 所默认提供的 DefaultServeMux 进行路由注册,源码如下:
var DefaultServeMux = &defaultServeMux
var defaultServeMux ServeMux
func HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
DefaultServeMux.HandleFunc(pattern, handler)
}而我们在例子中使用的 HTTP Server,也是使用的标准库中默认提供的,因此便完美的结合在了一起,这也恰好也是最小示例的模式。
这时候你可能会注意到另外一个问题,那就是我们的实际项目中,都是有相对独立的 ServeMux 的,这时候我们只要仿照着将 pprof 对应的路由注册进去就好了,如下:
mux := http.NewServeMux()
mux.HandleFunc("/debug/pprof/", pprof.Index)
mux.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)
mux.HandleFunc("/debug/pprof/profile", pprof.Profile)
mux.HandleFunc("/debug/pprof/symbol", pprof.Symbol)
mux.HandleFunc("/debug/pprof/trace", pprof.Trace)总结
在本文中我们详细的介绍了 Go 语言中 pprof 的使用,针对一些常用的套件均进行了说明。而 pprof 在我们平时的性能剖析,问题排查上都占据着非常重要的角色。
在日常只需要根据合理的排查思路,相信你一定能够根据在 pprof 中的蛛丝马迹,解决那些或大或小的问题,实现准点下班!