16 毫秒的挑战:图表库渲染优化
在 ApacheCon Asia 2021] 大会的“数据可视化论坛”上,Apache ECharts PMC 成员宿爽发表了题为“16 毫秒的挑战:图表库渲染优化”的演讲。本文是这次演讲的内容总结。

今天我演讲的主题叫做“16 毫秒挑战:图表库渲染优化”。
标题里的 16 毫秒是怎么来的呢?因为 UI 系统最常见的刷新频率是 60hz,也就是每一帧在约 16 毫秒内渲染完成就会比较流畅,交互不会有卡顿感。
后一部分叫“图表库渲染优化”。图表库是数据可视化的领域,涉及很丰富的呈现、动画、以及交互等等;同时它会遇到比较大量的数据,从而延缓我们的渲染过程,这就是一个挑战。
我来自 ECharts 团队,所以今天讲的内容都是 ECharts 在这个课题中所遇到的部分经历。ECharts 是一个数据可视化图表库,主要在浏览器环境下运行,我们今天所讲的也都是在浏览器中运行 JS 来进行渲染时的优化经验。
1大数据渲染为何放在前端?
首先我们看看为什么要在前端进行大数据渲染。这里的前端就是通常意义上的浏览器环境。为什么我们不在后端先进行数据降级处理,然后再返回到浏览器?
有两点考虑,一是在后端处理需要额外的计算资源,本来在客户端的分布式计算全都挪到后端,会需要额外的资源,比较麻烦。
第二是不易交互。可视化分析时,你不光要看数据整体,可能还需要缩放,看各种细节。如果后端数据降级了返回给前端,细节就丢掉了,不太容易做这种比较流畅的交互。所以能在前端做的还是尽量在前端,如果做不到再到后端进行数据降级处理。
2前端处理交互时的挑战
前端处理交互会面临哪些挑战?浏览器环境有性能限制,还会有实时性要求。不仅要求交互很流畅,而且有时实时数据每隔一秒钟或者几百毫秒全量刷新一次,这需要图表库做到性能足够优化。为了做这些事情我们需要解决三点问题:
- 渲染的时间不能太长,比如说浏览器弹出一个窗口说你的一个长的执行脚本是不是要杀掉?那不行。
- 交互不卡顿。
- 呈现效果流畅,不能渲染了半天才把整个东西呈现给用户,如果有可能就要渲染了多少就赶紧呈现多少。
3优化要点
下面我们挑一些优化点来给大家分析。
降采样
第一个是降采样。降采样是普遍采用的一种优化方式。比如说我这里一个例子是一千万折现图的 LTTB 降采样。
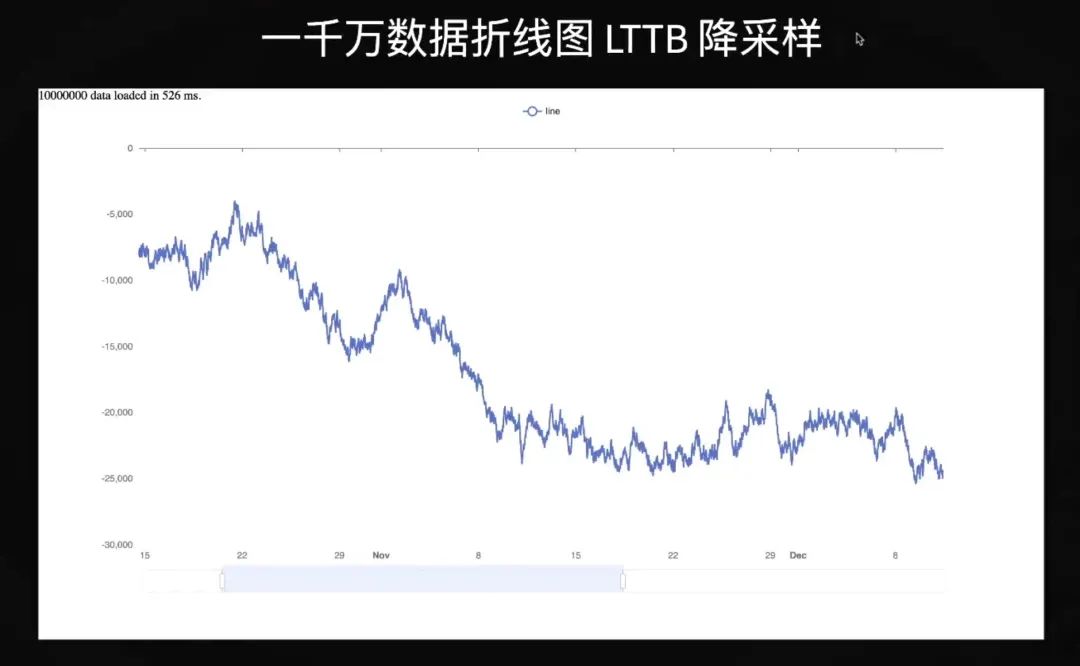
虽然这里面有一千万个点,但是我们屏幕的尺寸没有那么大,至多也就一千多个像素,所以大部分像素点如果要画出来都是重叠的,你没必要把所有点全都进行数据到视觉的映射,然后 Layer out。你可以选一个窗口,在这个窗口内挑一些代表的点来渲染,这就是降采样。这样就会极大优化性能。
另一件事就是你怎么挑这个点?你需要保留足够的局部特征,比如说局部最大值最小值要保留,因为这些细节往往是需要人关注的,不能够抹去。LTTB 算法就起到这个作用,经过这种优化以后缩放会比较流畅。
但降采样也并非能够解决所有的事情,它有一定的要求,需要你的数据有一定的局部性:你的数据的排序和你最后屏幕上展现出来的顺序是一致的。要换成散点图,点是分散在各处的,你就不太容易去选择这些点,因为它根本就没有重叠性了。第二个要求图形展示的特征是能够真的完全重叠的,比如要是一个平行坐标系,这些都是线,不能完全重叠,就不太容易去采样。
减少 Canvas 状态切换
下一件事情是减少 Canvas 状态切换。ECharts 底层可以用 Canvas 渲染,也可以用 SVG 渲染,但我们在做大数据渲染的时候基本上都会用 Canvas。Canvas 的 API 设计足够基础,也足够快,能够承载大数据的渲染。即便如此我们仍需要对它的 API 进行一定的优化。
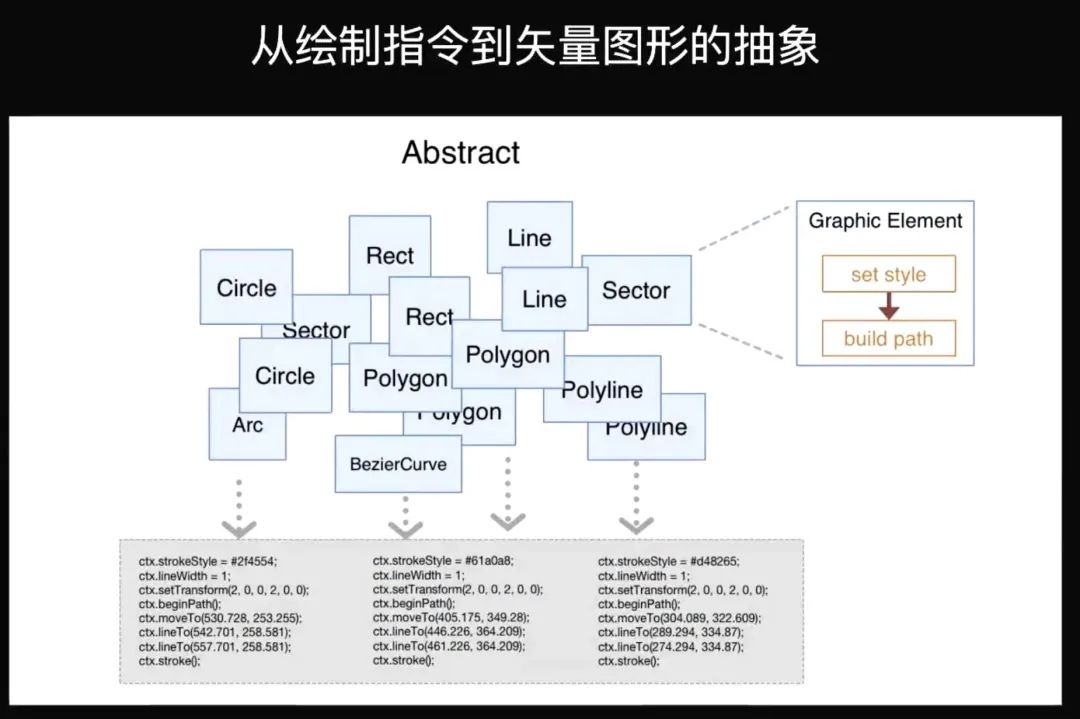
先讲一下 ECharts 和 ECharts 所基于的库是怎么样去使用 Canvas 的。
最下面这个灰框里面是 Canvas 的 API。作为一个比较复杂的应用来说,它一般不会去直接在这些最原始的,命令式 API 之上进行业务逻辑开发,一般还是会抽象一层,就把这些需要绘制的东西抽象成一个个元素实例。每一个元素自己会维护我们需要绘制的这个元素上面的各种属性,比如说它的缩放尺寸 scale X 跟 Y 之类的东西,全都作为元素这个实例的属性维护着。每一帧的时候遍历这些元素对它排序,然后让它自己去绘制自己,也就是说把这些属性最终转换为 Canvas 的渲染指令,然后输出给浏览器,让浏览器绘制。
在真正渲染的时候,我们已经有了元素,上面有很多我们配置好的属性,然后它先把这些属性值,set 到 Canvas2D 的这个 context 上面去。下一步 built Path,就是根据 path 相关的属性,把整个路径给 Built 出来。
Canvas 这些接口虽然足够快,但还是有一定开销的。因为我们需要挑战的数据量本身可能会是百万、千万的数据,这个 fillStyle 开销累积起来还是很明显的,百万次可以达到 100ms 以上。所以我们需要对这里进行优化。
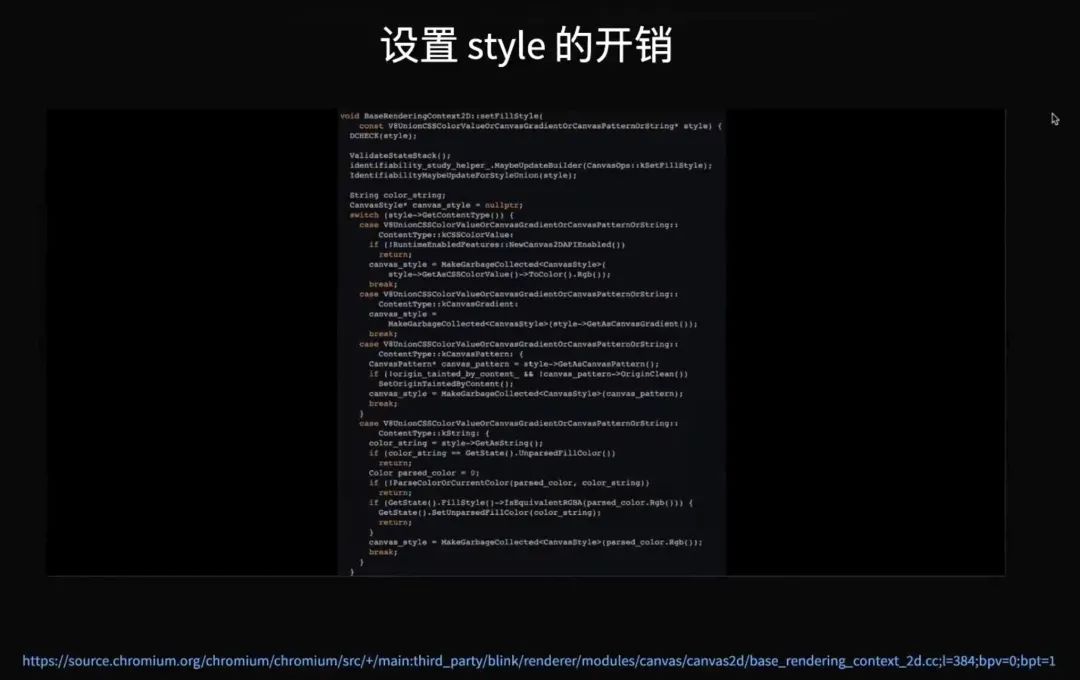
那么 fillStyle 为什么会有这些开销?可以去看一看浏览器的实现,比如说这个是 Blink 的实现,在 fillStyle 里它可能会需要对字符串表达的颜色进行解析,有一定开销。为了优化、避免掉这些东西,如果这次的 style 和上次的 style 相同的话,就不再向 Canvas 的 context 上设置。在海量数据绘制的场景下,前后的这些属性会有差异的情况并不多,大多数会用同样的颜色,因为数据量大的时候用各种差异性的东西已经不太能够看清了。
合并
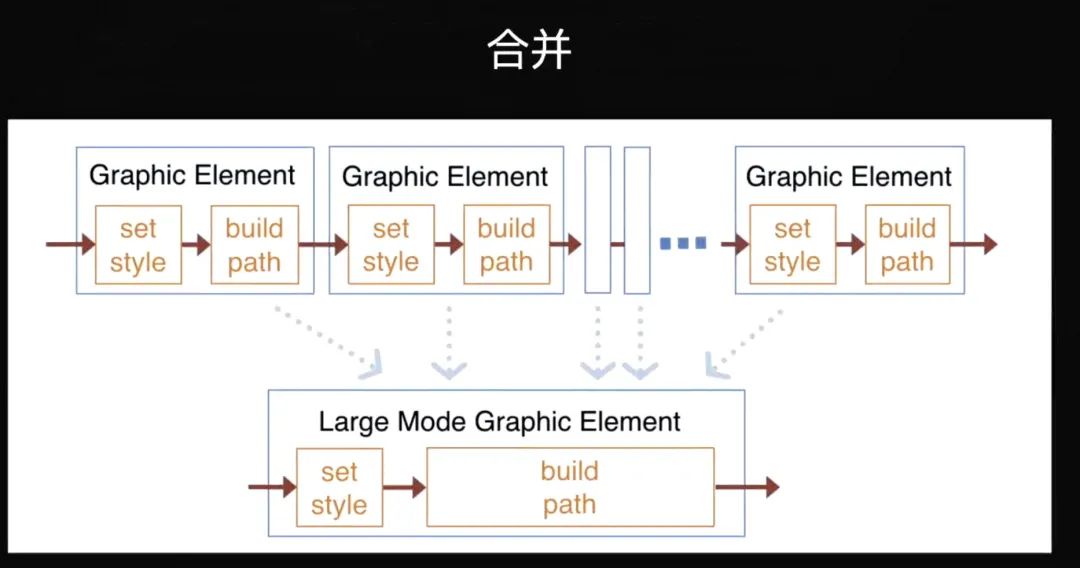
下一件事是合并。比如说我上面一行显示的是绘制的过程中多个 set style,再 build path,再 set style,以此类推。但如果强制把它合并掉,从业务层就认为它们的 Style 完全相同,只 set style 一次就可以了,连比较都不需要比较。这样就不需要在每个 element 里维护一个 build path 的结果,而是用一个数组来存放结果,就减少了很多内存开销以及 JS 开销等等。这种方式也是有限制的,就是它并不支持多个不同 style 的场景。
一维数组和 TypedArray
下一个优化方式非常常见和重要,就是用一维数组或者 TypedArray。因为我们在渲染图表的时候,绝大多数都是在渲染一些二维表,比如说每一行都是一条条数据项,每一列是一个一个纬度。就数据来说,我们最直观的就是用二维数组来表达,或者有可能还用 Object 组成的数组来表达。这些表达非常直观,但是它会占用更多内存,因为每一项都是一个数组、一个对象。
处理大数据的时候把它降维,降成一维的,那么读写的时候也就稍微加一点计算量,但并不多,这样的话会节省很多内存,并且速度会快很多。比如说我下面这一个图里面演示用二维数组来绘制一个折线图,大概五百万数据,初始化时间用了将近 5 秒钟。
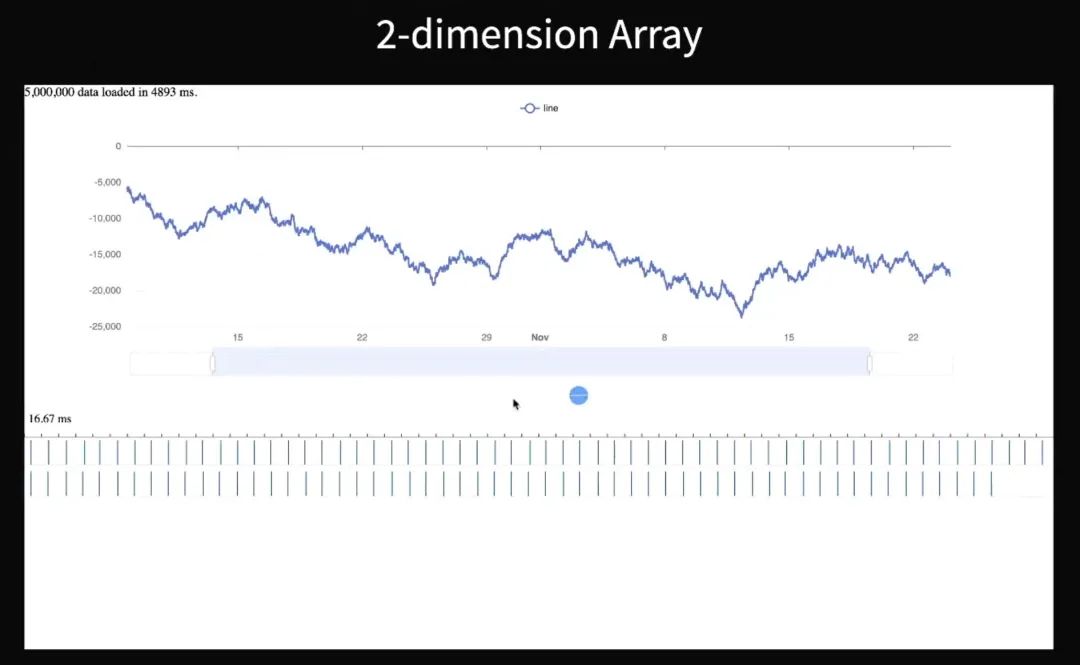
下面这个滚动的小球相当于额外的一个动画,这个动画只是想演示出来在 ECharts 进行交互改变的时候,是不是会影响到页面其他部分额外动画的流畅度。比如说我上面进行缩放,下面的这个动画就很卡,那就是影响到了。
最下面这个竖线表示它是一帧一帧的长度,上面一个格大概是 16.7 毫秒。如果这个竖线间隔变得很长,就说明一帧的时间变得很长。对于五百万数据,二维数组还是相对来说比较卡,但如果换成一维数组就会好很多。首先它初始化时间大概只有 400 多毫秒,并且交互的卡顿时间就会好很多,虽然仍然每一帧的时间稍微长一点,但已经足够可以接受。但它也稍微有一点弊端,就是它非常大的时候可能会崩掉。比如在我的机器上,一个数组到了三千万浏览器就会崩掉。
最好的情况下还是 TypedArray,它申请的时候就是定长了,相当于你完全自己管理这个内存空间,并且每一个数据项都是固定类型的,所以有更好的稳定性。当然它的弊端是你自己要去管理它,要记录它的长度,如果超长的话,你自己重新申请一片空间把原来的复制过来,要去自己实现这些数据结构。
GC 减少GC 是不可忽视的一个因素,因为在数据量大的时候,GC 在每一帧中的消耗可能会很影响流畅度。
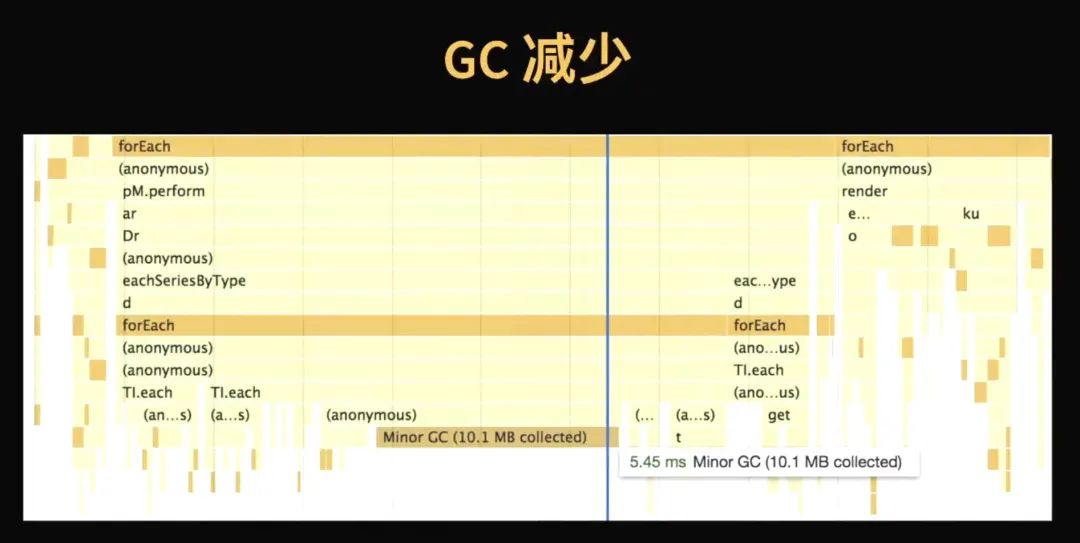
上面贴了一个图,Minor GC 就花了 5 毫秒,可是你一帧也就几十毫秒,或者十几毫秒。想要 GC 能够可控、减的很少,可能有很多不太确定的方式。在我们优化中使用过的方式有及时释放,意思就是说,临时的一个小对象对性能情况影响比较小,比如说我在函数里声明一个临时的对象,这个对象也没有挂在哪,用完了后就释放掉了,没有太大的影响。但是另一种情况有影响,就是我这个临时对象实际上挂了一个什么东西上,我在下一个阶段可能又使用了它,再在下一个阶段才准备把它释放掉,这时候它的释放可能就会影响很多了。GC 的时间是非常快的,但是你如果几次的清扫都没有能够释放,这种临时的小对象存着就很影响机器的开销,但如果把它都存成一个整个的 TypedArray 就会好很多。
前面讲的这些手段都是在尽量减少一些开销。但从理论上说,数据可视化的过程就是从用户的数据转换成最终渲染的指令的过程。数据越多指令就越多,渲染的时间就越长。但 UI 系统允许不可打断的渲染时长是有限的,它需要 60hz,或者降低一点的 20hz,转换成时间的话可能 16 毫秒、50 毫秒,或者更长一点 100 毫秒都还能接受,再长一点就明显卡顿了。这里的有限和前面说的数据增长是矛盾,这个上限就导致了我们再怎么优化总归会到一个瓶颈。下面所讲的一些手段就是要打破这个瓶颈。
并发
我们可能会想到用并发的手段,比如说我利用操作系统本身提供的多线程机制,或者把数据整个持续的渲染任务分成顺序不太相关的一些子任务,自己来调度。
首先来说多线程的尝试,在浏览器里面多线程是只能用 Web Worker。在讲这个之前先看一下 ECharts 的渲染管线。

最左边是用户输入,然后是一系列的阶段,进行渲染形成 Elements,最后转换成渲染指令。这流程很长,是 CPU 密集型过程。如果用多线程,用 Web Worker 尝试,就把流程都放到 Worker 里进行,主的 JS 线程只做用户输入,或者把那些最后得到的 Canvas 渲染指令输出出来,然后用户的鼠标之类的交互又传给 Worker 线程,得到结果再传给主线程。
这个结构是可以工作,但是它也有问题:它的交互可能不同步,大数据渲染实际上还是很慢的。虽然用户交互没有阻塞,但是没有真的解决 Worker 线程里渲染慢的这个问题,看起来这个结果还是不很好。而且比如说拖动时它很不跟手,虽然用户交互不阻塞,但用户的交互响应还是在 Worker 线程,响应完了还是要更新视图,这个 Worker 线程忙于计算,它就没有足够短的时间来响应这些用户交互了,结果效果还是不行。所以说尽管多线程可以在主线程里不会影响到其他,但是渲染问题还是避免不了要在单线程上面解决。
还有些其他的问题。JS 多线程有一个很大的弊端就是它的内存不共享。渲染的过程中有需要给用户以回调,回调用户程序,这种回调如果放在一个多线程的环境下不能共享,它就只能来回传输,不光是要跨线程,而且要有传输开销。基于这些东西来说,这个多线程渲染后续没有真的落实到产品中,因为它可能带来的收益有限,只是作为一个尝试的过程,而最根本的还是要去解决单线程中渲染的优化。
渐进渲染
接下来讲的是渐进渲染方式。渐进渲染能做到第一不阻塞交互,第二尽快渲染出效果,意思就是说它把用户的长任务分割成一些各种各样的短任务,然后做调度,然后实现一部分短任务,然后让它响应一下用户的交互,再执行下一步。

这就是长任务,两个红线表示的是帧。把这个任务分割成多个子任务就能响应很多次用户。
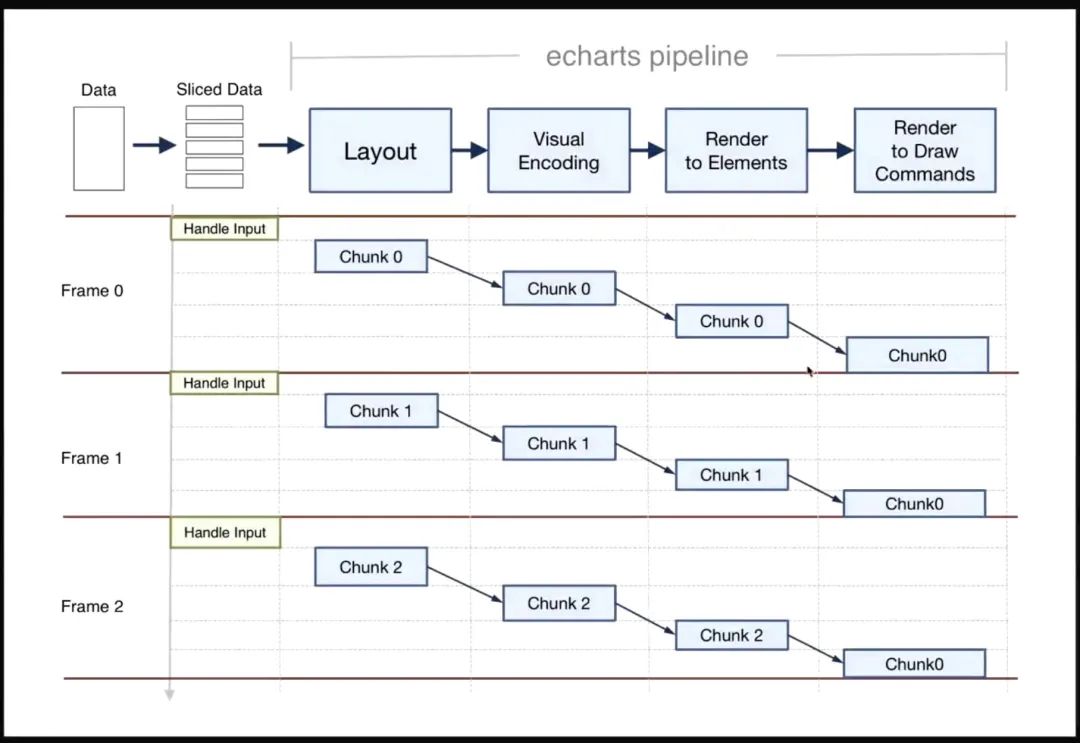
没有渐进渲染之前,整个 data 走完这四个过程最后才上屏,这一帧会比较长。如果有了渐进渲染,就把整个 data 分成好多好多 chunk,每个 chunk 走完这四个过程就直接上屏了,而且这一个帧比较短的情况下,就能够响应下一次的用户交互。

渐进渲染里面可能会涉及一些程序结构的调整。在没有渐进渲染之前,以这个 layout 过程为例,它就是从 0 一直取到 data 的末尾。

而有了渐进渲染,所有的转化过程没变,但它只是从 start 处理到 end,这是由外层的调度器来决定的。
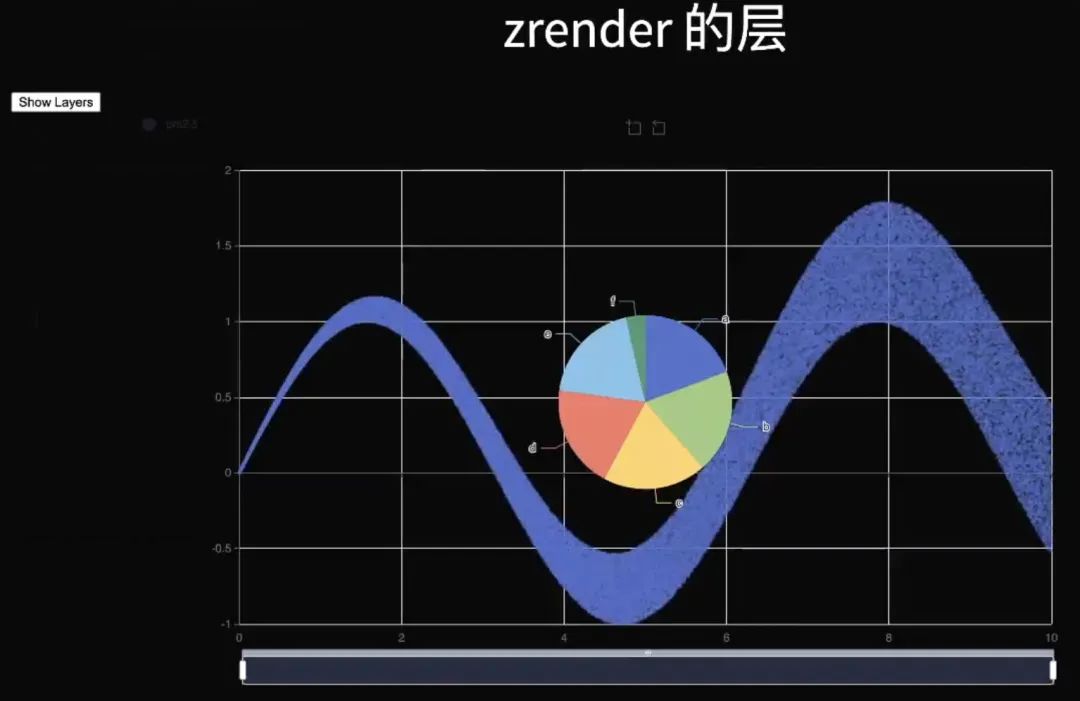
这里还有一点就是层的问题,因为它是在多帧中逐渐出来后续效果的。这里就是一个渐进渲染的例子,中间这个波浪的中间线就是一大堆散点,但是上面放了一个饼图作为另一个层,意思是让饼图遮盖着它。如果是不分层,你后续出来的这个点就会覆盖到饼图上面。所以渐进渲染要有单独的层,上面不渐进渲染的东西和底下的东西都会分多层。
分片
渐进渲染的下一个问题就是分片,每一片分多大?最开始都是用自己的配置,比如说我配置成每片三千,这个在很多场景都是可以用的,因为大家需要处理大数据的这些机器性能也都不错。但它没办法适应不同的环境,CPU 慢下来帧率就明显降下来了,这就是一个弊端。
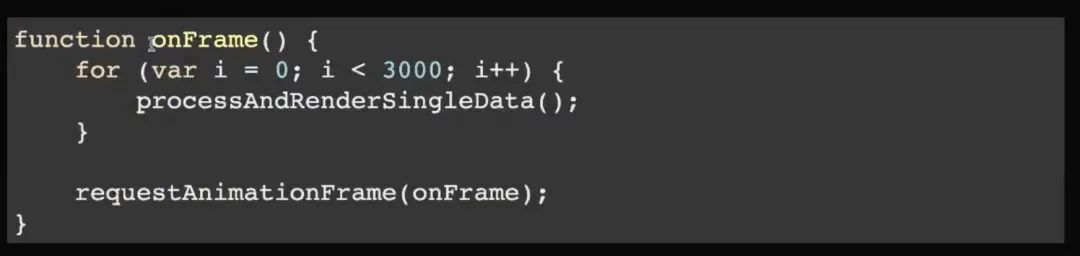
如何解决这个弊端呢?我们先把整个渲染流程抽象成一个最简单的结构,就是 onFrame。每个 onFrame 从 0 走到 3000,里面处理单个数据项,处理完了 3000 个以后 break 出来,再申请下一个 frame,继续这个过程,这是固定值的过程。
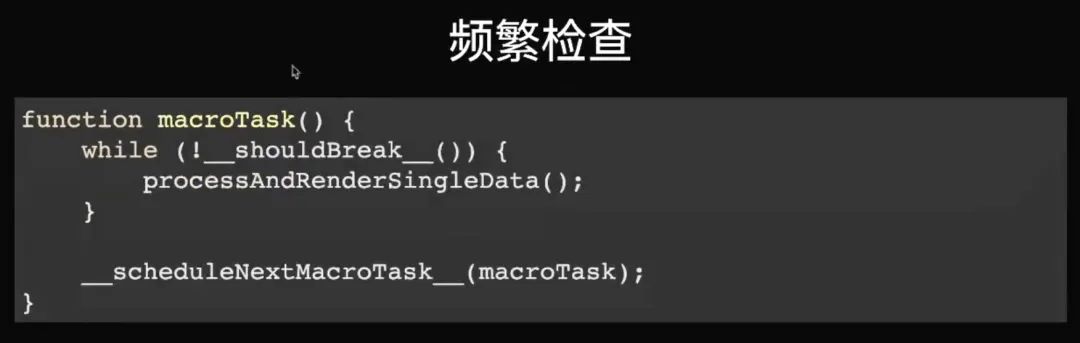
但是如果我们要不固定值,那么我们先把这个过程改成这么一个抽象。就是一个 task 先一直循环,循环不是固定三千,而是一直在检查是不是应该 break,是的话就跳出来,不是的话就时序处理一个一个的单点。
那么怎么来判断我是不是应该跳出来呢?有 requestIdleCallback 能够让你知道现在还有多少时间剩余,你可以边进行你的工作,边用 API 得到更短的剩余时间,看看是不是应该 break。这就能够保证帧率是非常稳定并且非常快的。但这个看起来理想,但它是有问题的。第一个它并不足够积极,因为它更多是为了后台任务来设计的,它优先保证帧率,而并不优先保证你得到回调的机会。比如说它在有些安卓手机上面滑动的时候甚至得不到回调,对于一个 UI 来说这样就不太合适了,如果你滑了半天,UI 不进行任何更新那是不行的。第二个就是它的兼容性还一直是有问题的。
如果用另一种方式,每次就是一直计时间,如果到了 16 毫秒就 break,然后继续申请下一帧,这样行不行?这个也不完全行,因为我们现在的浏览器做的处理用户输入以及后续过程都是按照帧来驱动的,每一帧以固定的流程来做这些。给 JS 执行这些事情只是这个流程的一部分,它还有很多别的工作。就比如说我现在 JS 提交了很多 Canvas 指令,它还需要把这些 Canvas 指令转成绘制指令去绘制,这些东西也是耗时的,要想为这些东西预留时间也不容易。
下一个思路是,我既然不能够留时间,我就把这个粒度缩的更小一点,比如我每五毫秒为一个单位去 break,break 就留出了系统调度的时间。你可能会立刻去调度下一个 5 毫秒的宏任务,也可能就到了一个帧的边界,你就会去进行下一帧的周期来响应用户输入。这种方式用的是 MessageChannel,因为它是一种最快的申请宏任务的方式。如果 MessageChannel 里什么都不干,它在一个帧里面能一直申请无数个任务。
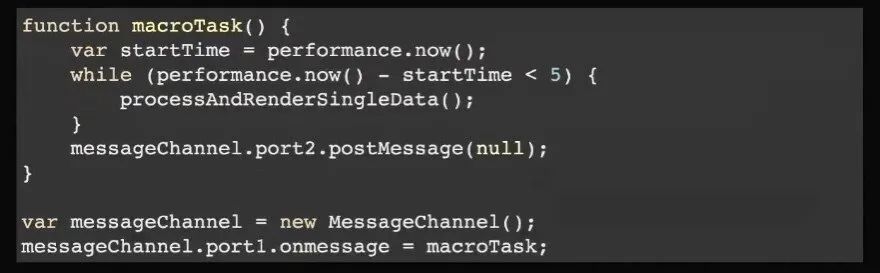
如果是这样的方式来实现,刚才的代码就变成这样,while 的条件变成是否小于 5 毫秒。如果是 5 毫秒之内就执行每一个数据处理,如果跳出来就申请下一个宏任务。这种节奏看起来挺好,但是它也有一些弊端,它对程序结构是有一定要求的,就是在实践中它渲染总的时长会变多,为什么?因为它粒度小导致一些重复工作的开销。因为现实中不一定能抽象得那么好,可能每次渲染之前需要做一些别的工作,这些工作不一定全能拆开来循环。这些工作占用的时间过多的话,可能会导致总的渲染时长变长。如果是没有这种制约的话,用这种方式也是挺好的。
朴素方法:自动调整片的尺寸
再换一种方式就是朴素的自动调整片的尺寸。我还是用一个固定的 step 值来渲染,但是这个 step 值是自动调整的。我边渲染边统计时间,大概估摸着这个 step 调整成多少,这个帧率能够逼近于多少这么一个状态,来做自动调整。这就主要看你的公式做得是不是足够好了。
4总结
总体来说,各种各样的优化方案都有各种利弊,我们要根据具体的场景选择合适的方法。
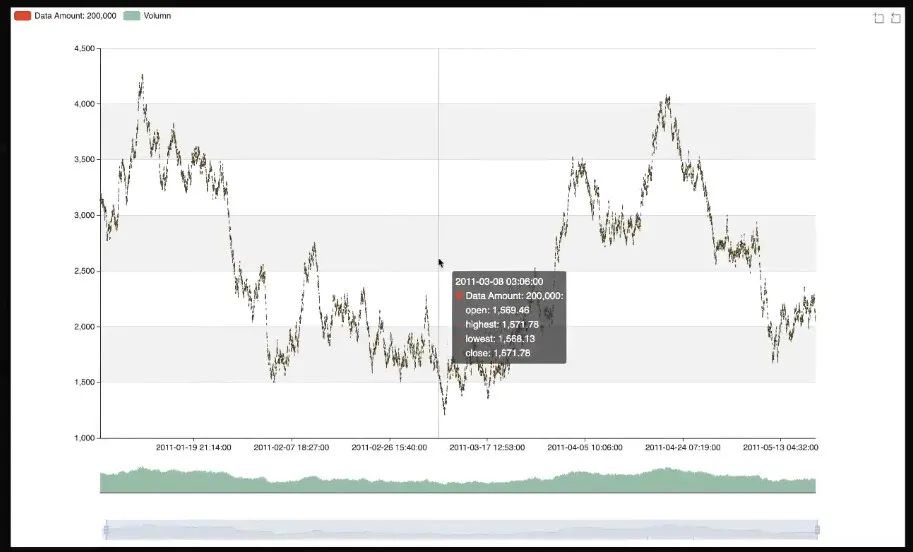
最后还有一些小要点,就是渲染中会有一些重绘的体验优化。比如说一个 K 线图的渐进渲染,如果每次都是从左到右渲染就挺傻的。但如果我只是做一个简单的变化,把渐进渲染片的执行顺序变成了取一个模,这样体验就好很多。

这是一个路线图的渲染,每次我拖动的时候因为破坏了原来的环境,它就必须重新渲染,这样体验也不是很好。这个在 2D 渲染里不太好解决,但如果是用 EChartsGL 来变成 3D 就好办,因为它机制不一样。它进行这个 zoom 是通过摄像头改变,实际上已有的数据不必擦除,可以重用了,这样的话就会好很多。
今天的演讲就到这里,谢谢大家。