Excel在线协作方案设计
写在前面:文中的 「消息」 是指:用户对excel内容每一次的修改操作。为了方便行文,我们下文统称为消息。 文中客户端和服务端的链接都采用 「WebSocket」 协议
书接上回,我们介绍了[如何实现在线Excel多人协作] 的整体设计。其中很重要的一点“如何保证用户消息有序、不丢、不重”我们没有做过多的解释。本文我们分析下如何保证协作编辑的场景下,消息 「有序」 「不丢」 「不重」 。
消息有序
当前场景中,如果发送给不同用户的消息无法保证顺序,会导致不同用户看到同一个表格的内容不同。
举个例子: A用户修改单元格C1:1的值为 「10」,这次操作为<消息1> B用户修改单元格C1:1的值为 「20」,这次操作为<消息2> 这两条消息发送给C用户时,顺序为<消息1> <消息2> 发送给D用户时顺序为 <消息2> <消息1> 此时C看到单元格的数据是「20」 ,D看到单元格的数据为「10」
如何保证消息有序呢?
实现方案:
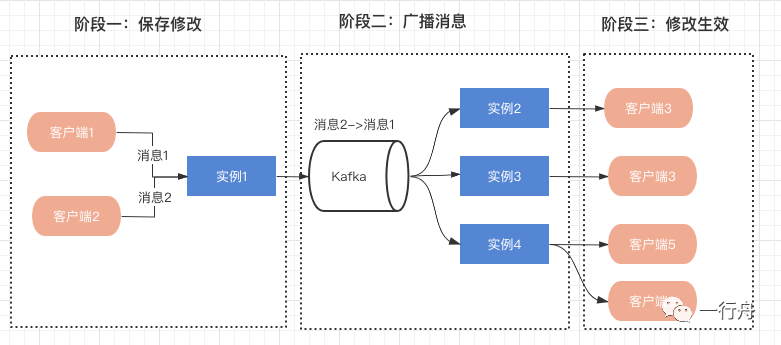
阶段一
对不同客户端发送的消息,根据到达服务端的先后顺序,生成单个excel单调递增的唯一ID,并保存到数据库中。
对于同一个客户端往服务端发送的消息如果出现后发送的先到达的情况如何处理呢?
一种方案是采用同步机制,每一次操作都需要ACK确认。 另外一种异步的方案,因为同一个客户端时钟顺序是递增的,客户端发送的每一条消息携带客户端生成的时间戳,服务端维护一个接收消息的队列,在生成全局递增ID前,看下队列中对同一个客户端的消息是否有比自己早的,按照时间先后顺序生成递增ID,然后执行入库操作。
阶段二
采用RocketMQ/Kafka生成有序队列。这两种消息队列都有自己有序消息的方案,我们这里只谈一下Kafka的方案。单个Excel的所有消息,保证走同一个Partition既可。可以采用根据Excel的UUID取模的方式来实现Partition的路由。
阶段三
消息顺序消费通常依赖单进程或者全局的分布式锁实现。当前场景下,我们有两种方案可以选择:
- 单个excel采用单进程消费。
- 依赖全局分布式锁完成顺序消费。
服务端每消费一条消息还需要把消息同步到客户端。因为客户端和服务端基于WebSocket长链接通讯,为了保证客户端接收到消息,所以还要自己实现一个ACK机制。客户端正常收到消息之后,服务端再消费下一条消息。客户端把收到的消息和本地的数据合并。
上述方案存在的问题:
- 从阶段二到阶段三基本上属于顺序执行,效率较低。
- 阶段三中,如果消息推送失败会阻碍后面所有的环节。
消息不丢
阶段一
阶段一中,出现任何保存失败的情况(比如:数据库修改失败、偶发的断网等),都实时反馈给当前用户保存失败就可以了。后续流程不再进行。
阶段二
消息一旦到了阶段二就不允许再丢失了,因为用户修改的内容已经在数据库生效,再丢失消息会出现不同客户端看到的数据不一致。
分析一下阶段二,Kafka默认配置下数据是存在操作系统Page cache中,如果此时出现机器宕机会丢失消息。不过Kafka也支持配置每一条消息都落入磁盘,这种情况下可以做到消息不丢,但是系统的吞吐量和实效性都受到很大影响。
消费Kafka的消息时也有可能丢失数据,比如一条消息消费完了,但是实例报错了,等实例重新启动后这条消息就丢失了。
结论:阶段二当前存在丢失消息的可能性。(先不考虑重传、验证消费成功等降低丢失几率的方案)
阶段三
服务端往客户端发送消息,可以通过ACK机制确保消息能送达。但是如果客户端断网或者其他原因导致的延迟,消息推送时会出现长时间的等待,这就会造成后面的消息积压,消息同步变慢,进而会影响整个系统的响应速率。
通过对阶段二和阶段三的分析,主动推送存在很多丢失消息的可能。除了通过一些手段降低消息丢失的几率外,还可以增加消息拉取的逻辑作为补偿。
消息幂等
对于幂等性我们主要看阶段二和阶段三。阶段二中Kafka本身可以设置允许消息重复的次数,如果设置成永远不重复,那丢失消息的概率会变大。
根据 「SMC定理」 ,消息不丢、不重是不可能的。我们为了不丢消息必然会有重复发送的消息,所以客户端在接收推送消息时,要能处理重复消息。处理重复消息的前提每一条消息需要有唯一标识。所以我们在阶段一保存消息时,要为每一条消息生成一个唯一ID,同时为了配合有序消息的实现我们生成的唯一ID是单调递增的。
总结
综上所述,我们的最终方案是:
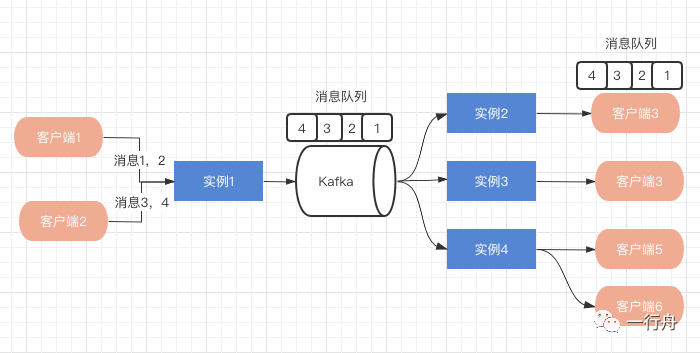
阶段二,根据excel的UUID取模,同一个excel消息路由到同一个Partition,顺序发送。
阶段三的消费策略需要改进,消费端消费完消息之后,推送到客户端,不用等待ACK完成,立马消费下一条消息,然后给客户端推送。
客户端需要自己保证消息顺序合并。我们在阶段一中生成的单调递增ID就派上用场了。客户端在自己本地维护一个接收消息的队列,当发现消息ID不连续递增了,说明服务端推送消息没有顺序到达,或者是有的消息推送失败了。此时客户端可以主动发送请求,去服务端拉取消息,以保证消息有序。当然拉取之前可以先短暂的等待几十毫秒,因为丢失的那条消息可能还在推送的路上。
推而广之,在很多协作、长链接的场景中,我们都可以采用类似的方案,保证消息的可靠性。
如果你对文中的方案有什么问题或建议,欢迎私信交流。