从0到1让你彻底掌握零拷贝!
原始
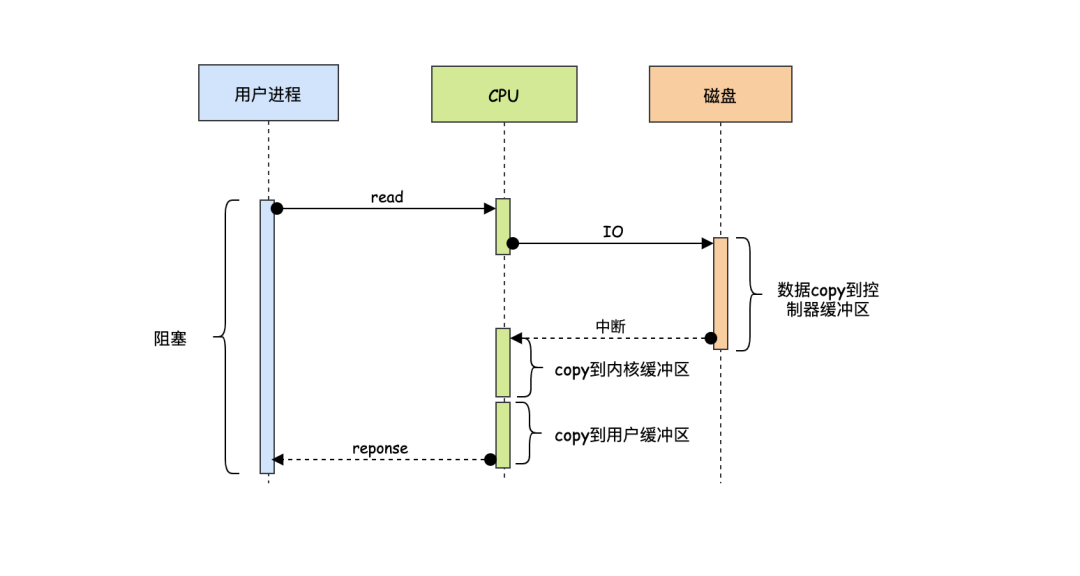
你们知道当程序需要读取或者写入数据的时候,CPU是如何操作我们的磁盘的吗?首先CPU肯定是要把读写数据的命令告诉给磁盘,这个命令可以通过IO总线传给磁盘,那这里有个细节,其实我们常说的磁盘不仅仅是只包含存储数据的媒介,还有接口,接口相信大家都熟悉,接口的意义不仅仅是为了连接到IO总线上的,其实这个接口里还有个叫做控制器的东西,控制器才是真正控制磁盘读写的东西,当CPU发出读写指令的时候,这个指令其实是告诉磁盘控制器的。以读为例,当控制器收到读的请求时,它告诉磁盘:“你把xx数据给我吧”,当机械硬盘经过转动、寻道找到目标扇区后,把目标数据给磁盘控制器:“哥,这是你要的数据”,控制器收到数据之后,其实不会立马通知CPU,因为需要读的数据可能涉及到多个扇区,如果每读一个扇区的数据就通知,会导致效率低下。
CPU:“控制器老弟,你这是搞事啊,我很忙的,每次搞这么点数据就通知我,能不能把我需要的数据都准备好,再通知我”。 “控制器”:“好的,CPU老哥”。
于是控制器内部就搞了个缓冲区,把读到的数据先缓存起来,然后通知CPU来取数据,但是问题又发生了...
CPU:“控制器老弟,数据你是准备好了,但是你给我的数据已经是损坏的,玩我呢!” “控制器”:“CPU老哥,俺错了,下次一定不会”。
于是控制器为了判断读到的数据是否发生了损坏,会先计算下校验和,如果校验和不通过,那么就不会通知CPU来取坏的数据了。
当缓冲区快要满了或者需要读的数据已经读完了并且校验数据也是OK的,这时控制器就会发出个中断:“CPU老哥,你要的数据好了,过来取吧”,于是CPU屁颠屁颠的过来拿数据,当然它也是分批拿的,每次从控制器的缓冲区中一个字节一个字节的拿,直至取完。整个过程看起来还不错,但是有个很严重的效率问题:CPU每次取数据的单位有点小(一个字节),这样势必造成CPU多次往返,那有什么办法解决这个问题呢?我们接着往下看。
缓冲
在讲缓冲之前,我们先了解一下当我们的程序发出read的时候,数据是怎么返回的,首先和设备打交道的时候,需要发起系统调用,系统调用会导致进入内核态,然后CPU去读数据,读到数据后,在把数据返给用户程序,这时又回到用户态。
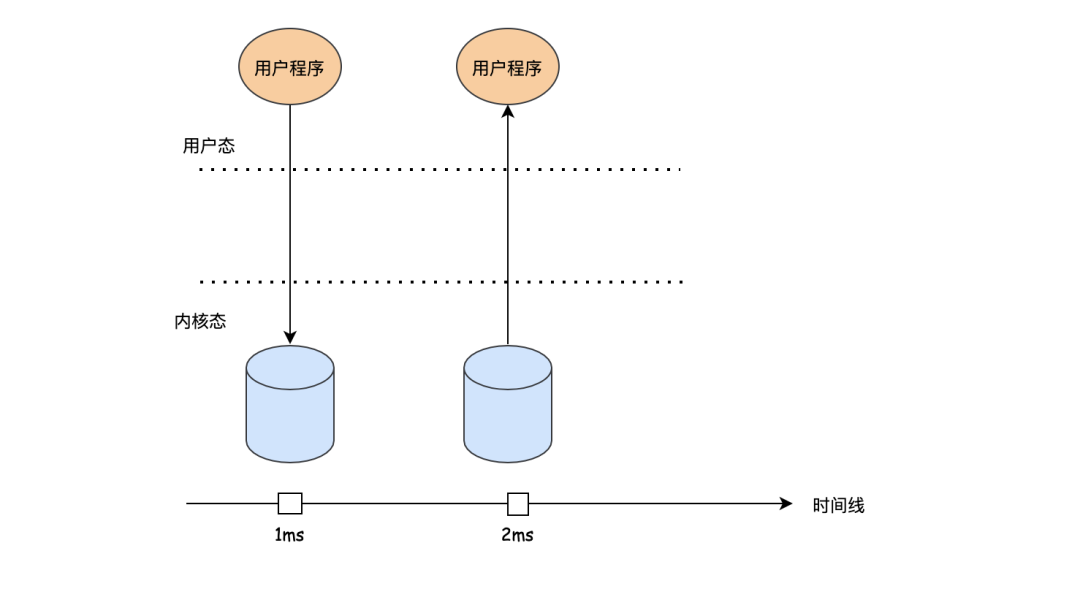
1 . 每次读到一个字节后立马发出中断,然后由中断程序把每个字节交给用户进程,用户进程收到数据之后,再发起下个字节的读取,就这样不停的循环...,直至把数据读完。这种模式的问题在于每个字节都要唤起进程,然后用户进程继续阻塞等待下个字节的到来,很傻很低效。
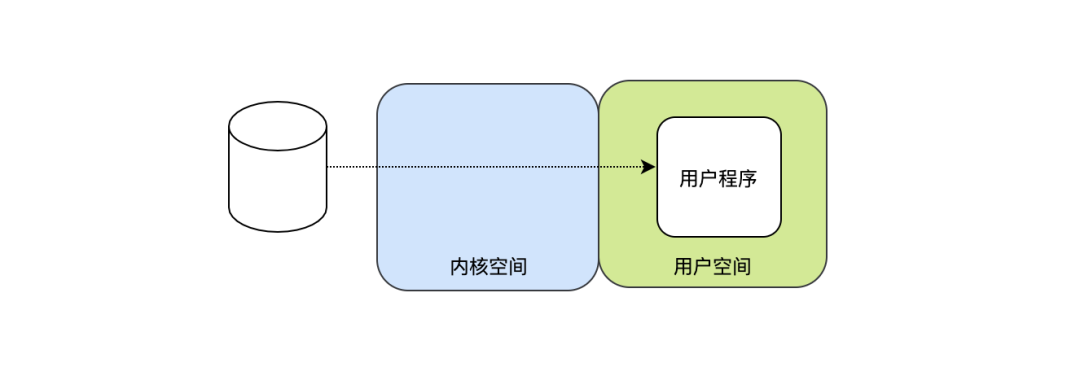
2 . 用户程序可以每次多读点数据,比如每次告诉CPU:“我要读n个字节”,CPU收到指令后去磁盘把数据读到,当然这里肯定不是一个字节一个字节的发起中断,不然和1无区别,由于一开始已经告诉CPU要读n个字节,所以要等读满n个字节后才能发起中断,那如何知道读满n个字节了呢?这就需要缓冲了,可以在用户空间开辟一个n个字节的缓冲区,当缓冲区满了,再发起中断,相比第一种n次中断,这里只需要一次中断,是不是效率提高了许多。
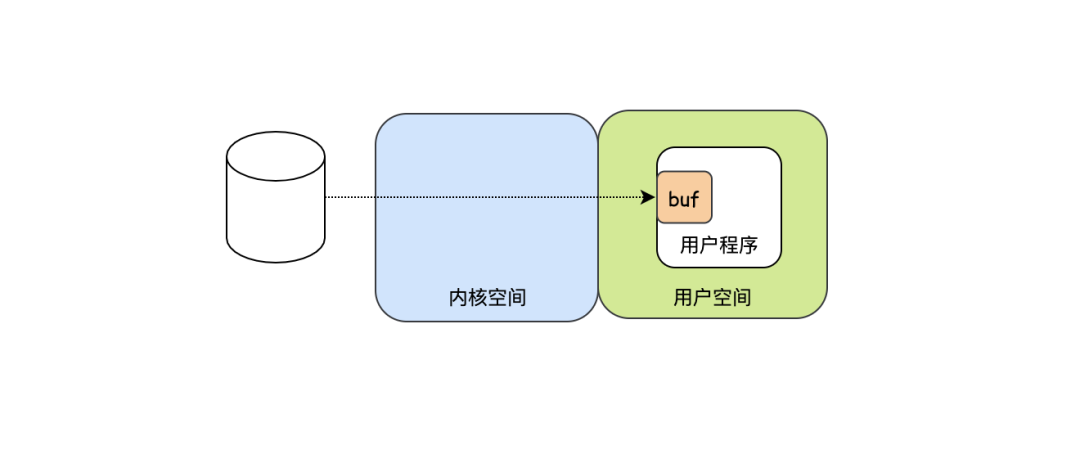
3 . 第二种方法解决了用户程序低效的问题,但是不要忘记了还有CPU,CPU还是一个字节一个字节的把数据搬运到用户的缓冲区中,这样看CPU还是挺辛苦的,不仅要读取数据,还要低效的把数据从内核空间搬运到用户空间,注意这个在内核空间和用户空间之间的切换还是挺耗费时间的,于是为了减少切换开销,内核空间干脆也搞个缓冲区,等缓冲区有足够多的数据之后,一次性的给到用户程序,这样是不是就高效多了。
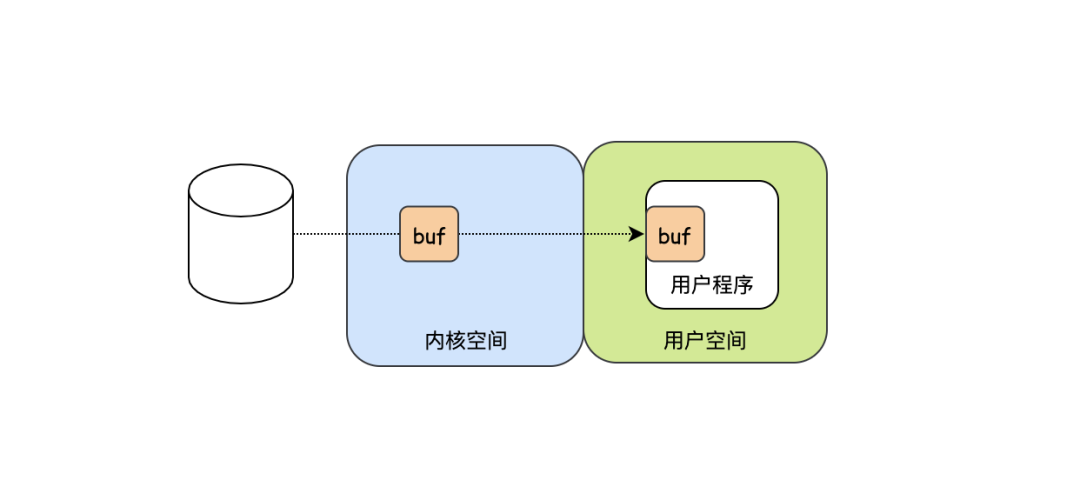
进阶-DMA
“我堂堂CPU,竟然要为了缓慢的磁盘而卑躬屈膝,能不能给我安排个下手呀,和低等磁盘打交道的任务就交给下手去做吧,还有其他很多进程在等着我调度呢”。于是设计者们就意识到这个问题,为了让CPU全身心的投入到调度、计算等工作中,后来就搞了个DMA(Direct Memory Access),中文名叫直接存取器存取,中文名挺抽象的,别急,我们接着往下看。
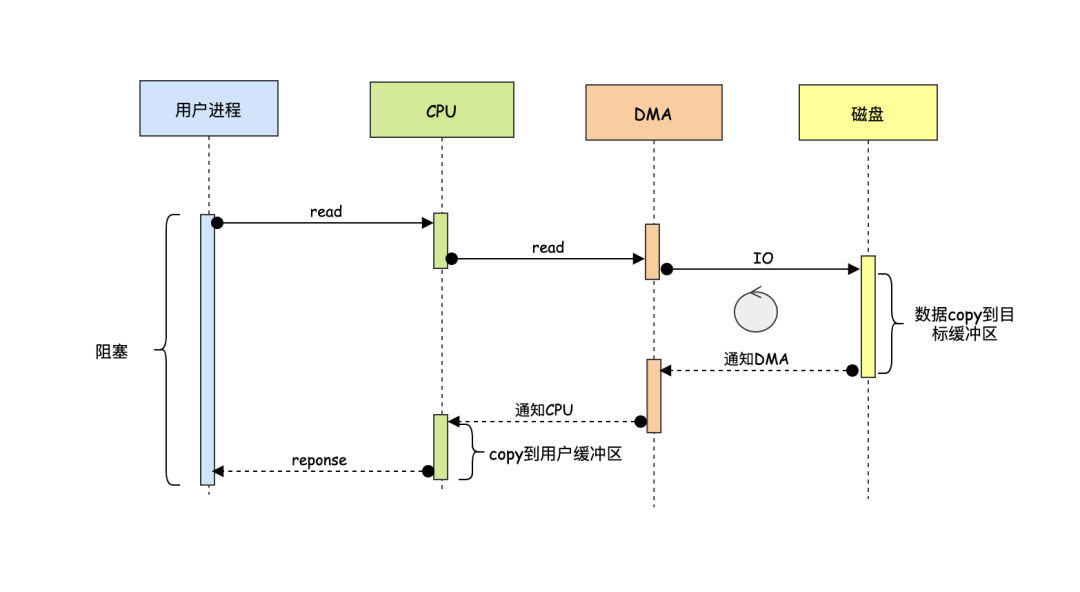
首先这个DMA它内部也有些寄存器,这些寄存器可以存什么呢?答案是内存地址,严格来说是内核缓冲区的地址。有了DMA后,read操作不再由CPU告诉磁盘,而是由CPU告诉DMA:“DMA同学现在某个程序员要读xx数据,你把xx数据放到内存地址是0x1234的内存里去吧”,DMA收到老大CPU的通知后:“收到了老大,这种小事交给小弟吧,你去忙吧”,到这里CPU就去忙别的事了,然后DMA就去通知我们的磁盘控制器了:“你先把xx数据的这一部分直接读到0x1234内存里去吧,读完告诉我一下,我这边还有xx数据的另一部分”,磁盘控制器:“好的,老大哥”,就这样每次控制器读完一部分数据之后就会通知DMA,然后DMA让它再读下一个数据,直至把需要读的数据读完,在读完了数据之后,肯定不能完事呀,这时得告诉老大哥CPU,于是DMA发出一个中断:“CPU大哥,数据已读取完毕,请享用~”,CPU收到通知后,发现数据已经在内核缓冲区了,不需要亲自干一个字节一个字节搬运的鸟事了,而且这期间CPU指挥了三次交通(调度)、扶了四个老奶奶过了马路(计算)。
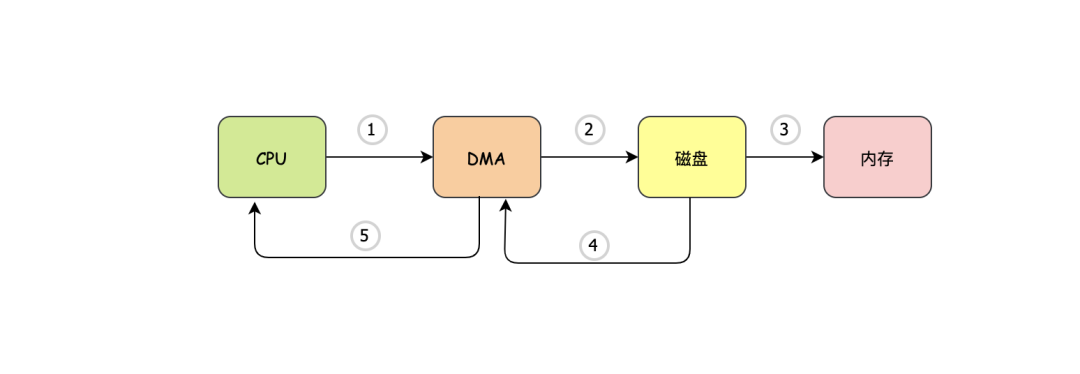
- CPU告诉DMA
- DMA告诉磁盘
- 磁盘读完之后告诉DMA
- DMA如果还需要读的话,会重复2,3步骤
- DMA干完活之后通知CPU
DMA的出现无疑是帮助了CPU很多,特别是和IO设备打交道这块。
那有什么办法能省掉这次的开销呢?
升华
mmap + write
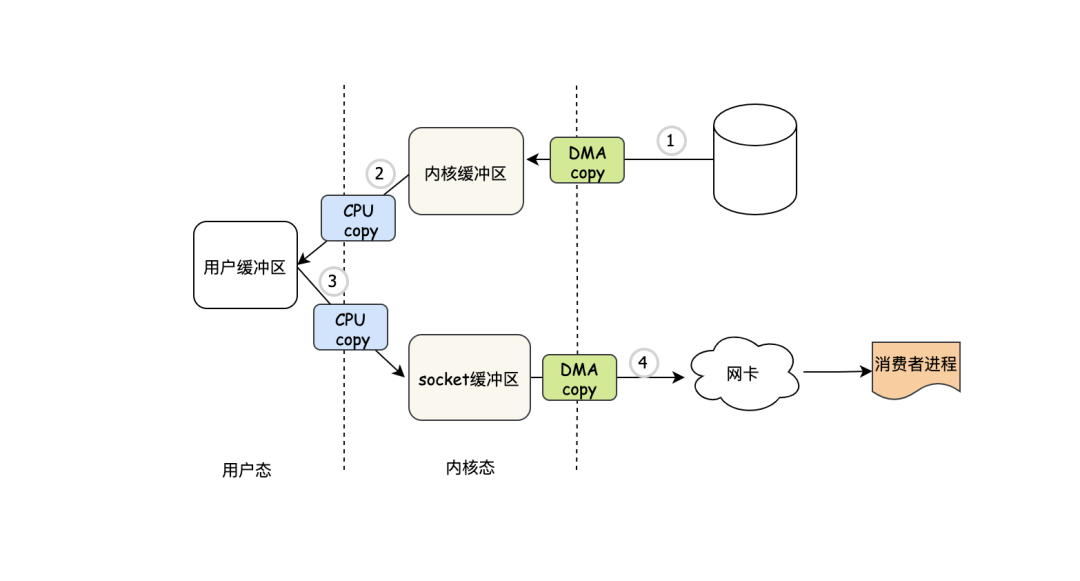
其实明眼人都看出来了,没必要把一份数据copy来copy去的,直接用内核态的缓冲区不就行了,这就是mmap(内存映射),我们还是先来看个例子,通过例子你就明白mmap的好处了:
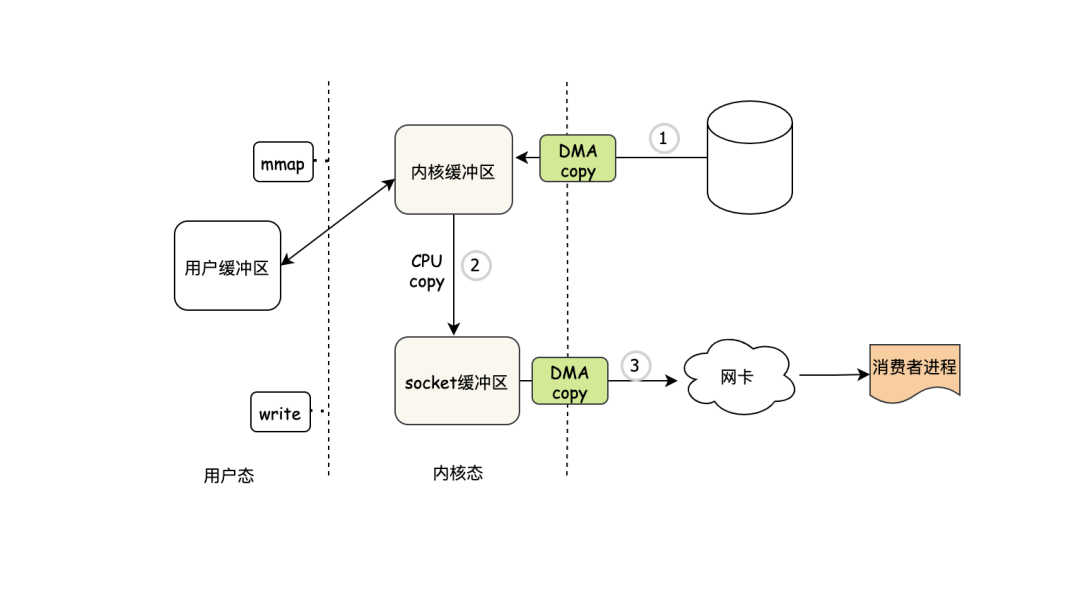
- 首先肯定是程序发出mmap系统调用请求,然后DMA把数据copy到内核缓冲区去
- DMA copy完之后,把内核缓冲区映射到用户缓冲区,注意映射和copy不一样,比copy的开销小
- 然后用户程序再次发起write请求
- 这时系统会把内核缓冲区的数据直接发到socket缓冲区
- DMA copy socket缓冲区数据到网卡
通过 mmap + write 的方式可以发现少了一次CPU copy,但是系统调用并没有减少,有没有什么办法让系统调用再少些?
sendfile
没有什么能阻止进步的脚步,于是出现了sendfile,有了sendfile函数之后,首先它不需要进行两次系统调用,只需要一次系统调用,当我们sendfile之后等于告诉系统:“帮我把xx数据直接发出去吧,别再copy或者映射进来了,俺不需要,直接发出去就好”。
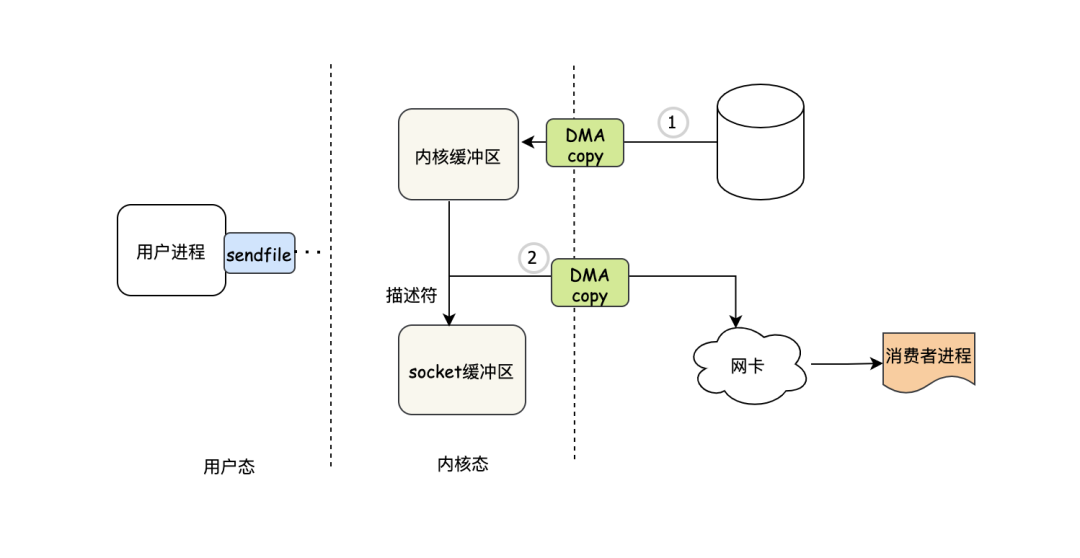
- 当我们发起sendfile之后,首先会切到内核态
- 然后DMA把数据copy到内核缓冲区
- DMA把socket描述符等传到socket缓冲区
- 同时DMA把数据直接从内核缓冲区copy到网卡
可以发现这种方式是目前最优的方式了,通过sendfile+DMA技术可以实现真正的零拷贝,整个过程都不要cpu搬运数据,也没有上下文切换,kafka就是利用这种方式来提供吞吐的。