天天讲路由,那 Linux 路由到底咋实现的!?
容器是一种新的虚拟化技术,每一个容器都是一个[逻辑上独立的网络环境] 。Linux 上提供了软件虚拟出来的二层交换机 [Bridge] 可以解决同一个宿主机上多个容器之间互连的问题,但这是不够的。二层交换无法解决容器和宿主机外部网络的互通。
容器肯定是需要和宿主机以外的外部网络互通才具备实用价值的。比如在 Kubernets 中,就要求所有的 pod 之间都可以互通。相当于在原先物理机所组成的网络之上,要再建一个互通的虚拟网络出来。这就是 Overlay 网络的概念,用一个简单的示例图表示如下。
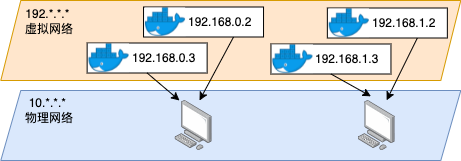
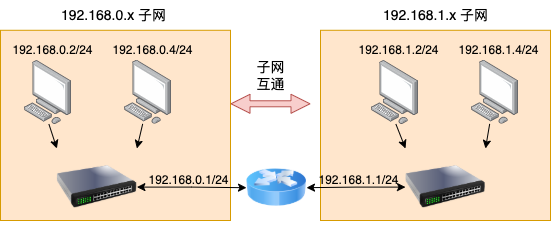
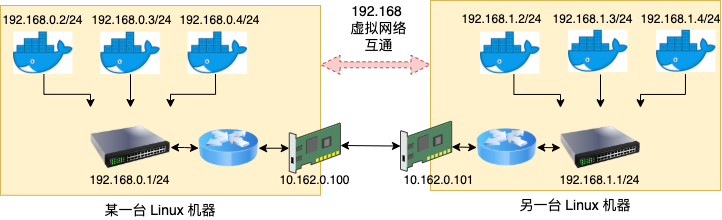
回想在传统物理物理网络中,不同子网之间的服务器是如何互联起来的呢,没错,就是在三层工作的路由器,也叫网关。路由器使得数据包可以从一个子网中传输到另一个子网中,进而实现更大范围的网络互通。如下图所示,一台路由器将 192.168.0.x 和 192.168.1.x 两个子网连接了起来。
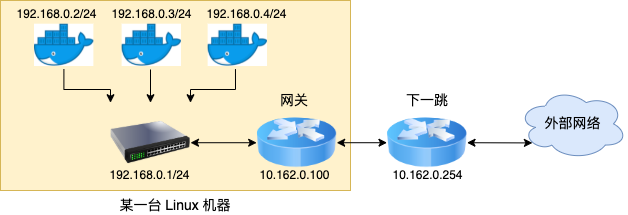
在容器虚拟化网络中,自然也需要这么一个角色,将容器和宿主机以外的网络连接起来。其实 Linux 天生就具备路由的功能,只是在云原生时代,它的路由功能再一次找到了用武之地。在容器和外部网络通信的过程中,Linux 就又承担起路由器的角色,实现容器数据包的正确转发和投递。
在各种基于容器的云原生技术盛行的今天,再次回头深刻理解路由工作原理显得非常有必要,而且也非常的有价值。今天,我们就再来强化一下 Linux 上的路由知识!
一、什么时候需要路由
先来聊聊 Linux 在什么情况下需要路由过程。其实在发送数据时和接收数据时都会涉及到路由选择,为什么?我们挨个来看。
1.1 发送数据时选路
Linux 之所以在发送数据包的时候需要进行路由选择,这是因为服务器上是可能会有多张网卡设备存在的。数据包在发送的时候,一路通过用户态、TCP 层到了 IP 层的时候,就要进行路由选择,以决定使用哪张网卡设备把数据包送出去。详细过程参见[25 张图,一万字,拆解 Linux 网络包发送过程]
来大致过一下路由相关源码源码。网络层发送的入口函数是 ip_queue_xmit。
//file: net/ipv4/ip_output.c
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl)
{
// 路由选择过程
// 选择完后记录路由信息到 skb 上
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (rt == NULL) {
// 没有缓存则查找路由项
rt = ip_route_output_ports(...);
sk_setup_caps(sk, &rt->dst);
}
skb_dst_set_noref(skb, &rt->dst);
...
//发送
ip_local_out(skb);
}在 ip_queue_xmit 里我们开头就看到了路由项查找, ip_route_output_ports 这个函数中完成路由选择。路由选择就是到路由表中进行匹配,然后决定使用哪个网卡发送出去。
Linux 中最多可以有 255 张路由表,其中默认情况下有 local 和 main 两张。使用 ip 命令可以查看路由表的具体配置。拿 local 路由表来举例。
#ip route list table local
local 10.143.x.y dev eth0 proto kernel scope host src 10.143.x.y
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.11.2 接收数据时选路
没错,接收数据包的时候也需要进行路由选择。这是因为 Linux 可能会像路由器一样工作,将收到的数据包通过合适的网卡将其转发出去。
Linux 在 IP 层的接收入口 ip_rcv 执行后调用到 ip_rcv_finish。在这里展开路由选择。如果发现确实就是本设备的网络包,那么就通过 ip_local_deliver 送到更上层的 TCP 层进行处理。
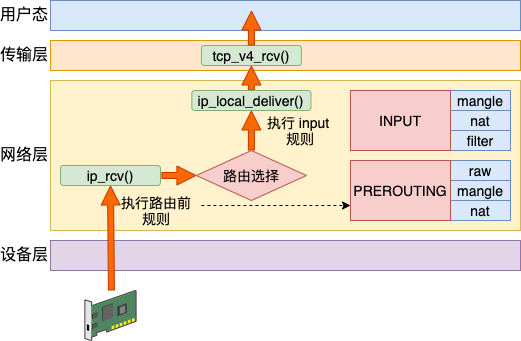
如果路由后发现非本设备的网络包,那就进入到 ip_forward 进行转发,最后通过 ip_output 发送出去。
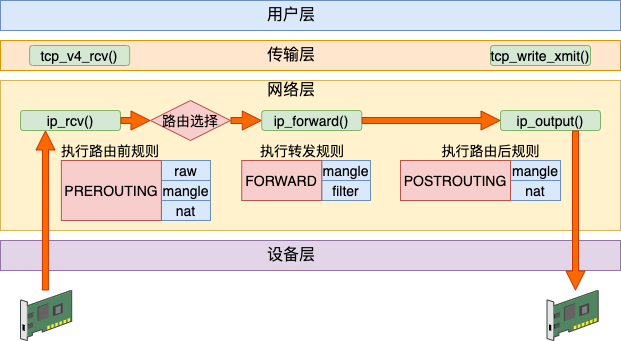
具体的代码如下。
//file: net/ipv4/ip_input.c
static int ip_rcv_finish(struct sk_buff *skb){
...
if (!skb_dst(skb)) {
int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
iph->tos, skb->dev);
...
}
...
return dst_input(skb);
}其中 ip_route_input_noref 就是在进行路由查找。
//file: net/ipv4/route.c
int ip_route_input_noref(struct sk_buff *skb, __be32 daddr, __be32 saddr,
u8 tos, struct net_device *dev)
{
...
res = ip_route_input_slow(skb, daddr, saddr, tos, dev);
return res;
}这里记着 ip_route_input_slow 就行了,后面我们再看。
1.3 linux 路由小结
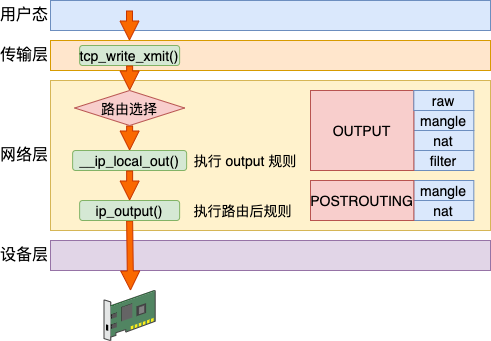
路由在内核协议栈中的位置可以用如下一张图来表示。
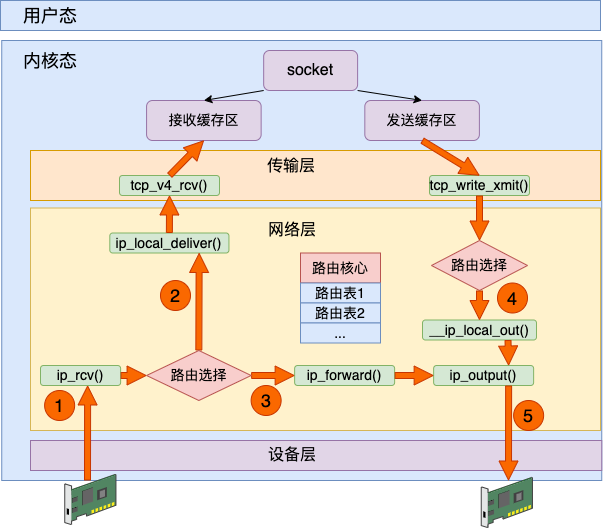
网络包在发送的时候,需要从本机的多个网卡设备中选择一个合适的发送出去。网络包在接收的时候,也需要进行路由选择,如果是属于本设备的包就往上层送到网络层、传输层直到 socket 的接收缓存区中。如果不是本设备上的包,就选择合适的设备将其转发出去。
二、Linux 的路由实现
2.1 路由表
路由表(routing table)在内核源码中的另外一个叫法是转发信息库(Forwarding Information Base,FIB)。所以你在源码中看到的 fib 开头的定义基本上就是和路由表相关的功能。
其中路由表本身是用 struct fib_table 来表示的。
//file: include/net/ip_fib.h
struct fib_table {
struct hlist_node tb_hlist;
u32 tb_id;
int tb_default;
int tb_num_default;
unsigned long tb_data[0];
};所有的路由表都通过一个 hash - fib_table_hash 来组织和管理。它是放在网络命名空间 net 下的。这也就说明每个命名空间都有自己独立的路由表。

//file:include/net/net_namespace.h
struct net {
struct netns_ipv4 ipv4;
...
}
//file: include/net/netns/ipv4.h
struct netns_ipv4 {
// 所有路由表
struct hlist_head *fib_table_hash;
// netfilter
...
}在默认情况下,Linux 只有 local 和 main 两个路由表。如果内核编译时支持策略路由,那么管理员最多可以配置 255 个独立的路由表。
如果你的服务器上创建了多个网络命名空间的话,那么就会存在多套路由表。以除了默认命名网络空间外,又创了了一个新网络命名空间的情况为例,路由表在整个内核数据结构中的关联关系总结如下图所示。
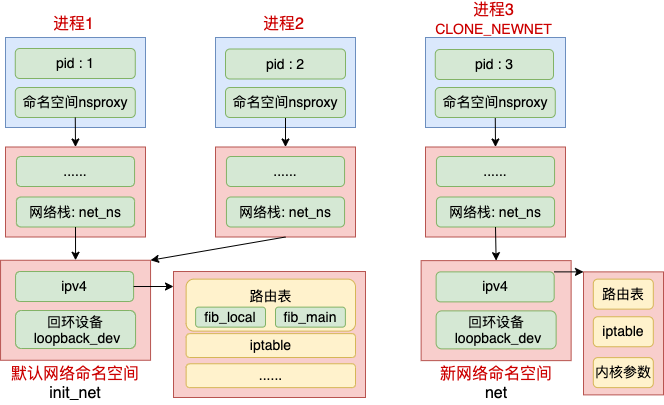
2.2 路由查找
在上面的小节中我们看到,发送过程调用 ip_route_output_ports 来查找路由,接收过程调用 ip_route_input_slow 来查找。但其实这两个函数都又最终会调用到 fib_lookup 这个核心函数,源码如下。
//file: net/ipv4/route.c
struct rtable *__ip_route_output_key(struct net *net, struct flowi4 *fl4)
{
...
// 进入 fib_lookup
if (fib_lookup(net, fl4, &res)) {
}
}
//file: net/ipv4/route.c
static int ip_route_input_slow(struct sk_buff *skb, __be32 daddr, __be32 saddr,
u8 tos, struct net_device *dev)
{
...
// 进入 fib_lookup
err = fib_lookup(net, &fl4, &res);
}我们来看下 fib_loopup 都干了啥。为了容易理解,我们只看一下不支持多路由表版本的 fib_lookup。
//file: include/net/ip_fib.h
static inline int fib_lookup(struct net *net, const struct flowi4 *flp,
struct fib_result *res)
{
struct fib_table *table;
table = fib_get_table(net, RT_TABLE_LOCAL);
if (!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF))
return 0;
table = fib_get_table(net, RT_TABLE_MAIN);
if (!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF))
return 0;
return -ENETUNREACH;
}这个函数就是依次到 local 和 main 表中进行匹配,匹配到后就返回,不会继续往下匹配。从上面可以看到 local 表的优先级要高于 main 表,如果 local 表中找到了规则,则路由过程就结束了。
这也就是很多同学说为什么 ping 本机的时候在 eth0 上抓不到包的根本原因。所有命中 local 表的包都会被送往 loopback 设置,不会过 eth0。
三、路由的使用方法
3.1 开启转发路由
在默认情况下,Linux 上的转发功能是关闭的,这时候 Linux 发现收到的网络包不属于自己就会将其丢弃。
但在某些场景下,例如对于容器网络来说,Linux 需要转发本机上其它网络命名空间中过来的数据包,需要手工开启转发。如下这两种方法都可以。
# sysctl -w net.ipv4.ip_forward=1
# sysctl net.ipv4.conf.all.forwarding=1开启后,Linux 就能像路由器一样对不属于本机(严格地说是本网络命名空间)的 IP 数据包进行路由转发了。
3.2 查看路由表
在默认情况下,Linux 只有 local 和 main 两个路由表。如果内核编译时支持策略路由,那么管理员最多可以配置 255 个独立的路由表。在 centos 上可以通过以下方式查看是否开启了 CONFIG_IP_MULTIPLE_TABLES 多路由表支持。
# cat /boot/config-3.10.0-693.el7.x86_64
CONFIG_IP_MULTIPLE_TABLES=y
...所有的路由表按照从 0 - 255 进行编号,每个编号都有一个别名。编号和别名的对应关系在 /etc/iproute2/rt_tables 这个文件里可以查到。
# cat /etc/iproute2/rt_tables
255 local
254 main
253 default
0 unspec
200 eth0_table查看某个路由表的配置,通过使用 ip route list table {表名} 来查看。
#ip route list table local
local 10.143.x.y dev eth0 proto kernel scope host src 10.143.x.y
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1如果是查看 main 路由表,也可以直接使用 route 命令
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.0.0.0 10.*.*.254 255.0.0.0 UG 0 0 0 eth0
10.*.*.0 0.0.0.0 255.255.248.0 U 0 0 0 eth0上面字段中的含义如下
- Destination:目的地址,可以是一个具体的 IP,也可以是一个网段,和 Genmask 一起表示。
- Gateway:网关地址,如果是 0.0.0.0 表示不需要经过网关。
- Flags: U 表示有效,G 表示连接路由,H 这条规则是主机路由,而不是网络路由。
- Iface:网卡设备,使用哪个网卡将包送过去。
上述结果中输出的第一条路由规则表示这台机器下,确切地说这个网络环境下,所有目标为 10.0.0.0/8(Genmask 255.0.0.0 表示前 8 位为子网掩码) 网段的网络包都要通过 eth0 设备送到 10...254 这个网关,由它再帮助转发。
第二条路由规则表示,如果目的地址是 10...0/21(Genmask 255.255.248.0 表示前 21 位为子网掩码)则直接通过 eth0 发出即可,不需要经过网关就可通信。
3.3 修改路由表
默认的 local 路由表是内核根据当前机器的网卡设备配置自动生成的,不需要手工维护。对于main 的路由表配置我们一般只需要使用 route add 命令就可以了,删除使用 route del。
修改主机路由
# route add -host 192.168.0.100 dev eth0 //直连不用网关
# route add -host 192.168.1.100 dev eth0 gw 192.168.0.254 //下一跳网关修改网络路由
# route add -net 192.168.1.0/24 dev eth0 //直连不用网关
# route add -net 192.168.1.0/24 dev eth0 gw 10.162.132.110 //下一跳网关也可以指定一条默认规则,不命中其它规则的时候会执行到这条。
# route add default gw 192.168.0.1 eth0
对于其它编号的路由表想要修改的话,就需要使用 ip route 命令了。这里不过多展开,只用 main 表举一个例子,有更多使用需求的同学请自行搜索。
# ip route add 192.168.5.0/24 via 10.*.*.110 dev eth0 table main
3.4 路由规则测试
在配置了一系列路由规则后,为了快速校验是否符合预期,可以通过 ip route get 命令来确认。
# ip route get 192.168.2.25
192.168.2.25 via 10.*.*.110 dev eth0 src 10.*.*.161
cache本文总结
在现如今各种网络虚拟化技术里,到处都能看着对路由功能的灵活应用。所以我们今天专门深入研究了一下 Linux 路由工作原理。
在 Linux 内核中,对于发送过程和接收过程都会涉及路由选择,其中接收过程的路由选择是为了判断是该本地接收还是将它转发出去。
默认有 local 和 main 两个路由表,不过如果安装的 linux 开启了 CONFIG_IP_MULTIPLE_TABLES 选项的话,最多能支持 255 张路由表。
路由选择过程其实不复杂,就是根据各个路由表的配置找到合适的网卡设备,以及下一跳的地址,然后把包转发出去就算是完事。
通过合适地配置路由规则,容器中的网络环境和外部的通信不再是难事。通过大量地干预路由规则就可以实现虚拟网络互通。
好了,今天的分享就到这里了 ~~