初探 Swift 算法和集合
前言
程序 = 算法 + 数据结构。Swift 的标准库实现了三种通用的数据结构:Array,Set,Dictionary,使用与这些集合相匹配的 sort,map, fliter 等多个算法函数,能够使得代码更加简洁,易读,而且性能更好,也成为了 Swift 最强大特性之一。今年更是发布了一个 Swift 算法和集合的开源包,在其中更新了更多的算法函数和数据结构。本文基于 Session 10256[1] 梳理,文章简单介绍其中一些算法和数据结构。需要提前了解的有:
- 内联闭包的参数名称缩写(跳转 SwiftGG - 闭包[2] 了解)
- Copy On Write 特性
- “懒”点儿好[3] Lazy sequences 部分
Algorithms
到目前为止,开源包里的算法可以分为以下几个大类:
- Combinations / permutations
- Mutating algorithms
- Combining collections
- Subsetting operations
- Partial sorting
- Other useful operations
具体用法和效果可查阅开源地址:Swift Algorithms[4]。下面是算法列表的截图:

分块算法函数
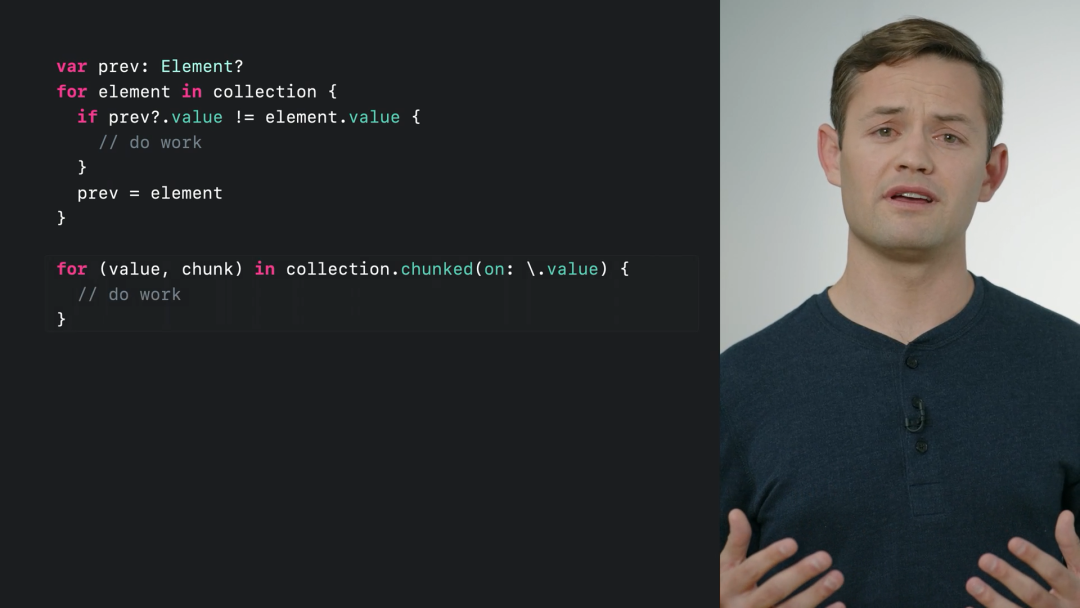
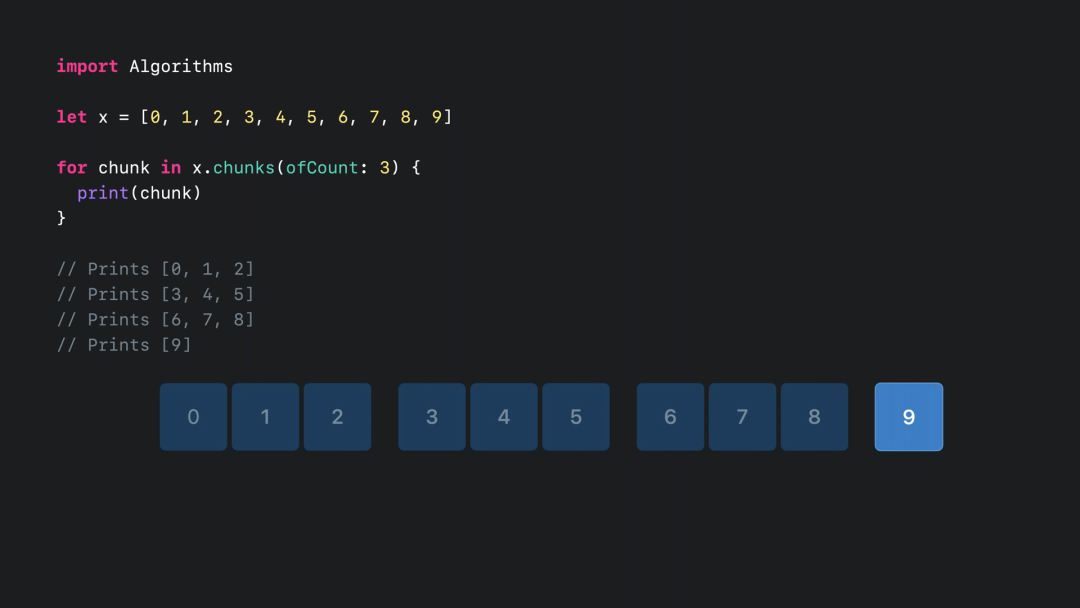
根据 chunks 函数的参数,当前元素与前一个元素“不同”时,这时候就需要分块。比如前后元素的某个值不相等:

窗口算法函数
windows(ofCount:) 窗口算法,会以窗口的形式遍历和输出:
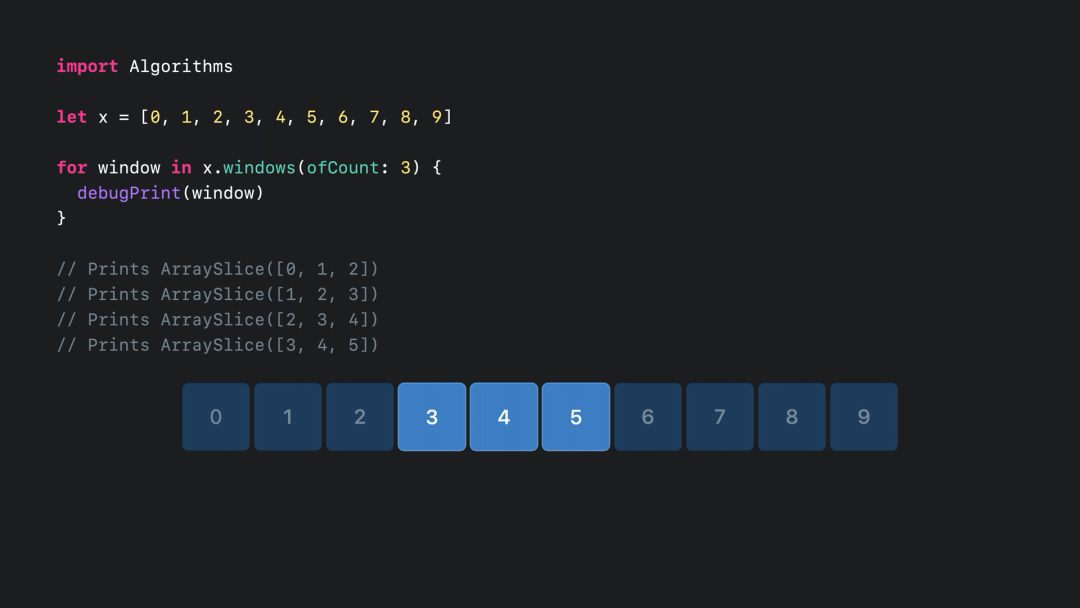
windows(ofCount: 2) 的操作特别常用,所以苹果工程师专门为它提供了一个便利方法 adjacentPairs,而它的返回值是一个元组(而不是一个序列),这样让元素的访问变得更加方便。

CompactMap
compactMap 方法用来过滤集合中的 nils 并映射到解包之后结果集合。compactMap 方法是 filter 和 map 两个方法的合体,其中 filter 方法筛选符合条件的元素集合,map 是映射出一个新的集合。
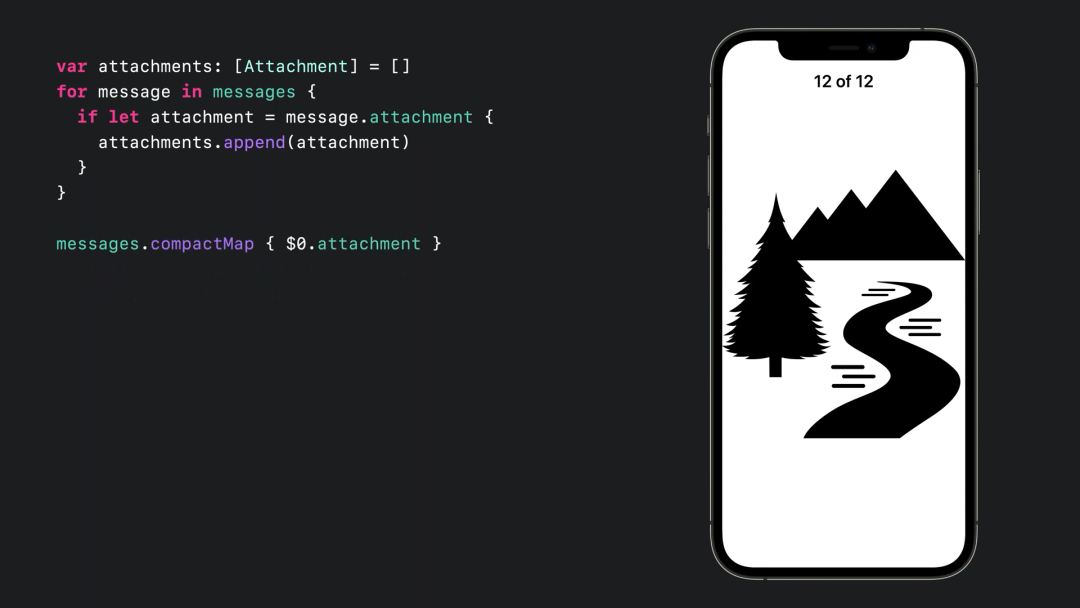
messages
.filter { $0.attachment != nil }
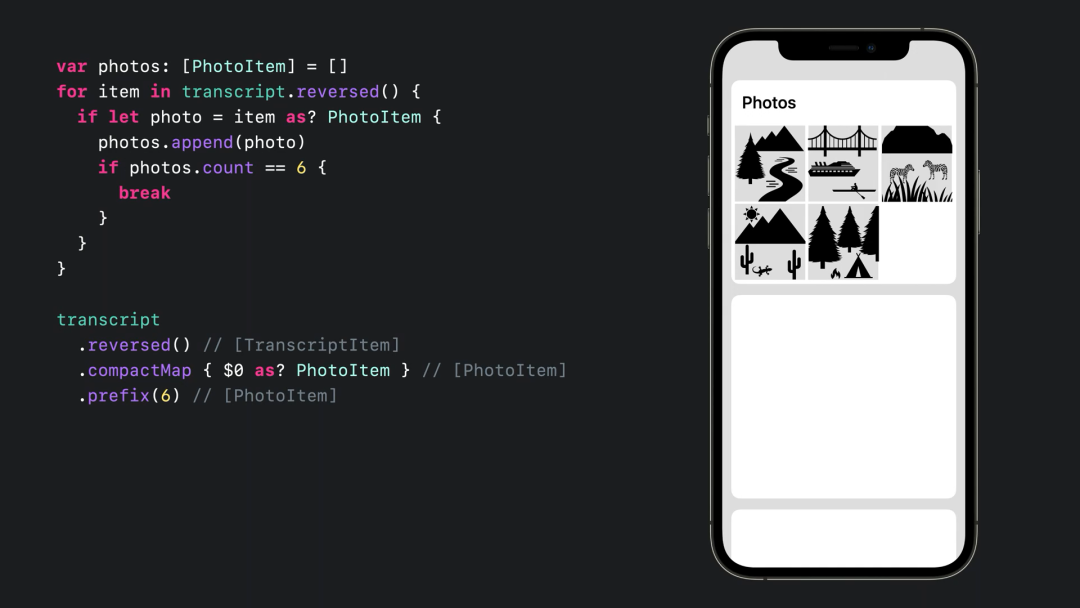
.map { $0.attachment! }业务场景:图片列表按从新到旧排列,最大个数为 6 个
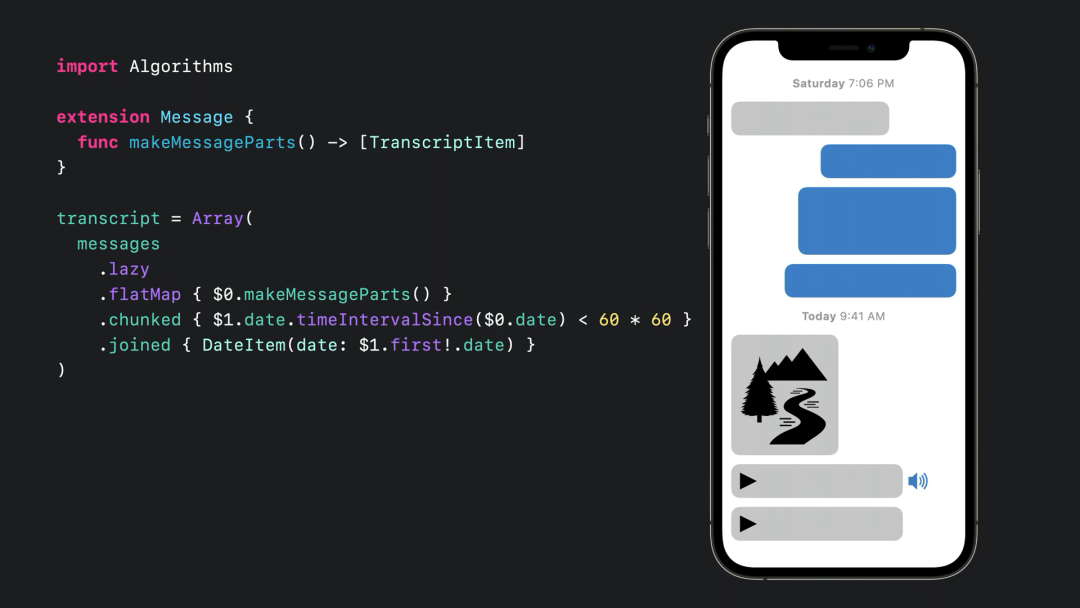
FlatMap
FlatMap 将集合中的元素都映射到单层的集合中。
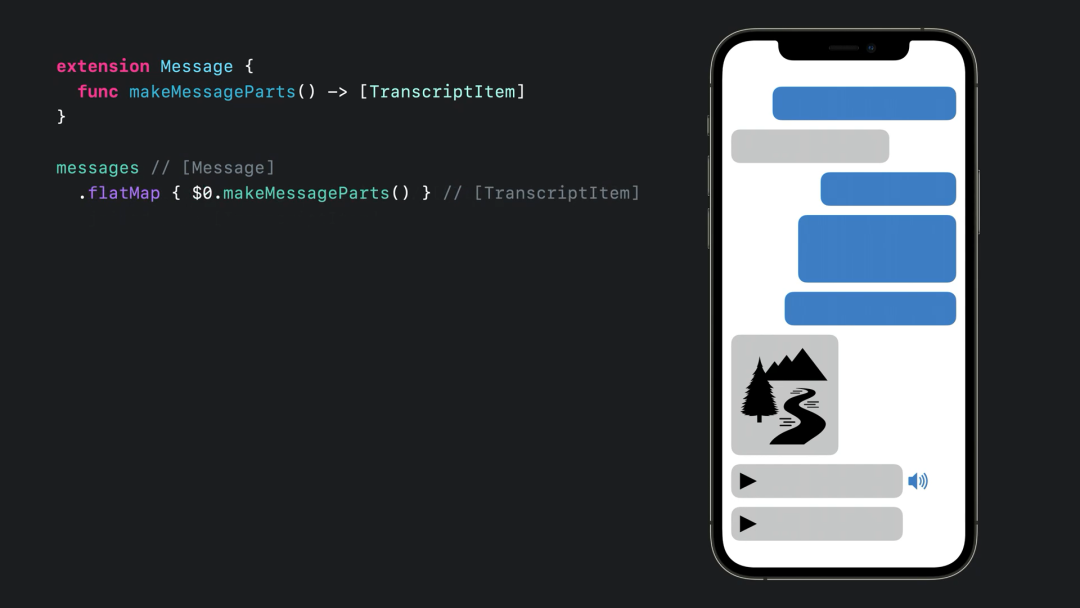
messages
.map { $0.makeMessageParts() }
.joined()算法链
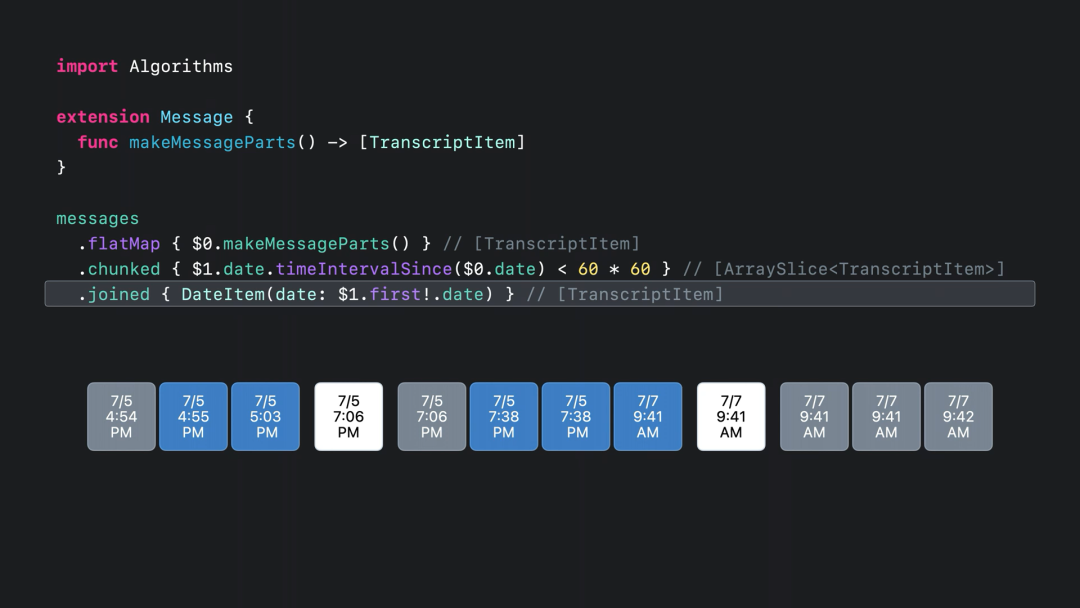
在下图中的注释会发现 join 方法并没有返回预期中的 [TransriptItem] 数组,而是返回了一个 FlattenSequence 类型:
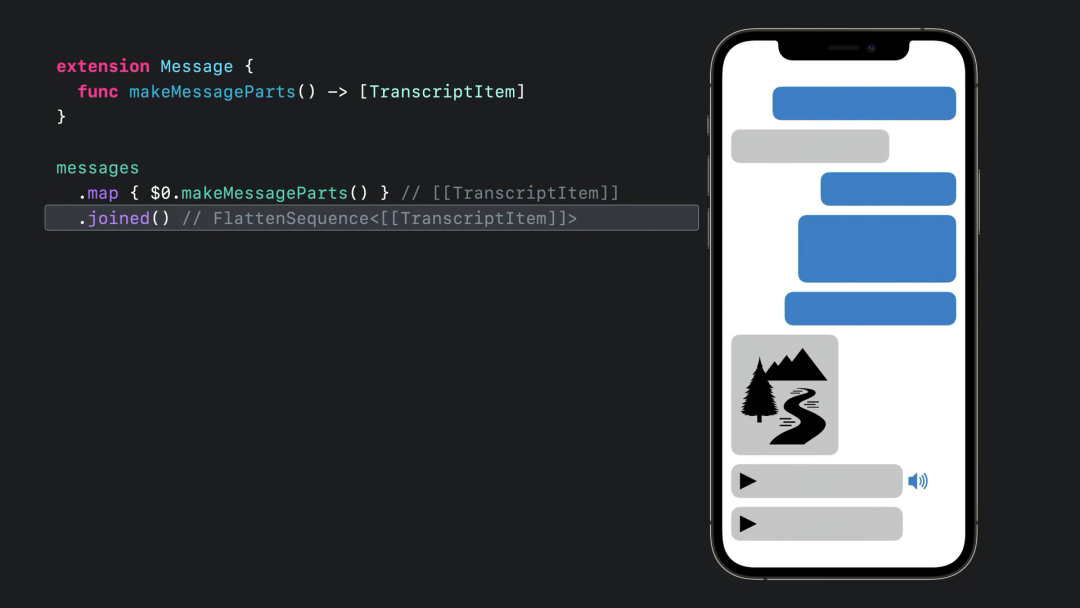
lazy 特性,这个特性的作用是按需处理元素,而不是预先处理好所有的工作,Swift 中的 Copy On Write 也是类似的表现。像 FlattenSequence 这样的惰性适配器就起到了算法链具有与原始 for 循环接近的性能表现
上面提到 compactMap 函数里,直接返回的是 Array 类型。那么这时候可以手动加上 lazy 的特性么?

lazy 特性:
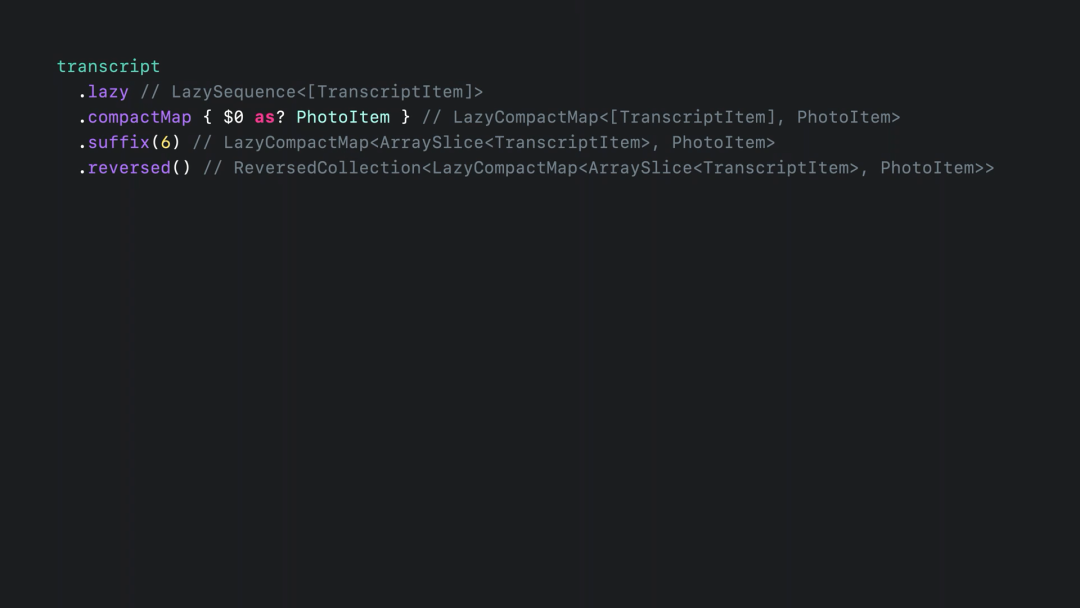
Array() 里就能得到具体类型的数组。在序列只做一次迭代时,利用 lazy 可以节省一些不需要工作。但是需要多次迭代序列的时候就不要适合。此时就可以像 lazy 修饰的存储属性一样,懒加载之后作为属性保存结果。
需要注意的是:将 Array 类型转化成惰性适配器是是不可以的。
Collection
开源包里新增的三种数据结构:
- Deque 双端队列
- OrderedSet 有序集合
- OrderedDictionary 有序字典
这三种也是常见的数据结构类型,而且也是标准集合类型的变体。开源地址:Swift Collection[5]

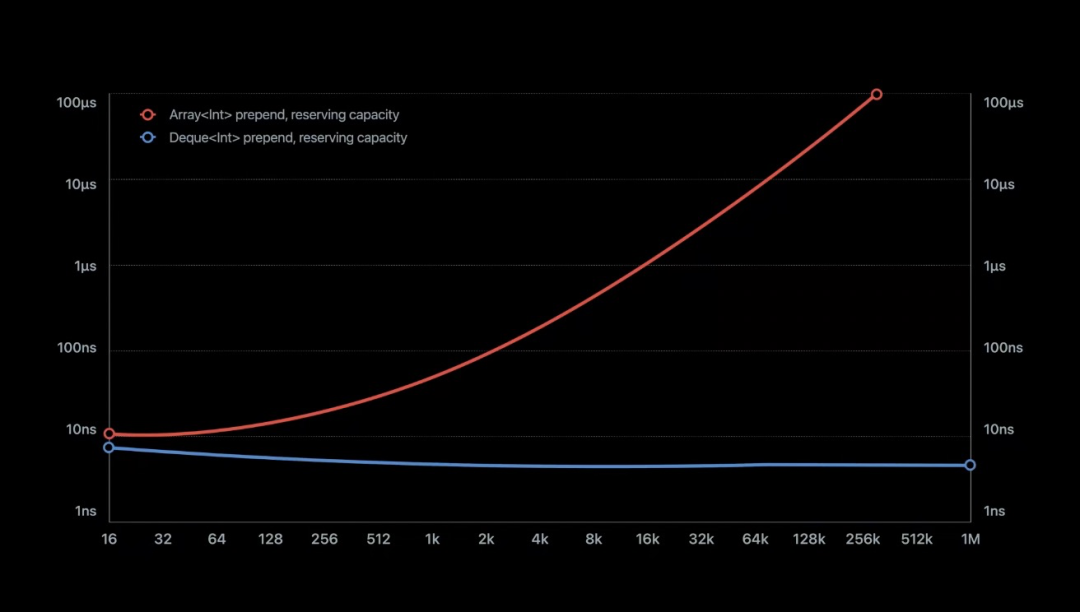
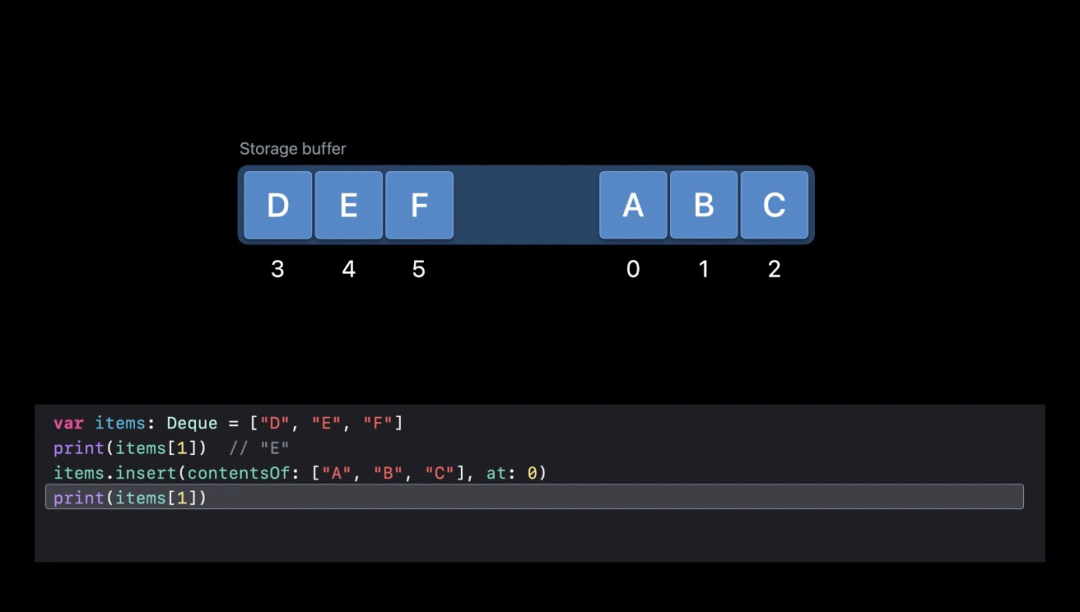
Deque
"double-ended queue" 双端队列,苹果工程师在项目中缩写为了 Deque。双端队列相比较于一般队列的先进先出单个方向的操作,提供了对称性的操作。而在 LeetCode 上就有一道算法题 设计循环双端队列[6] 。

OrderedSet
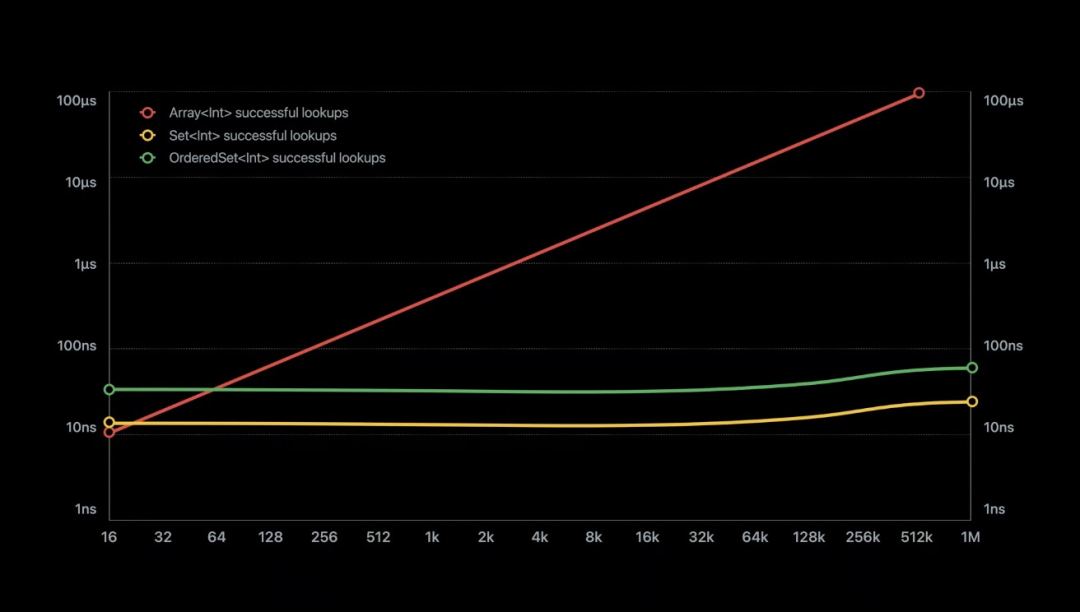
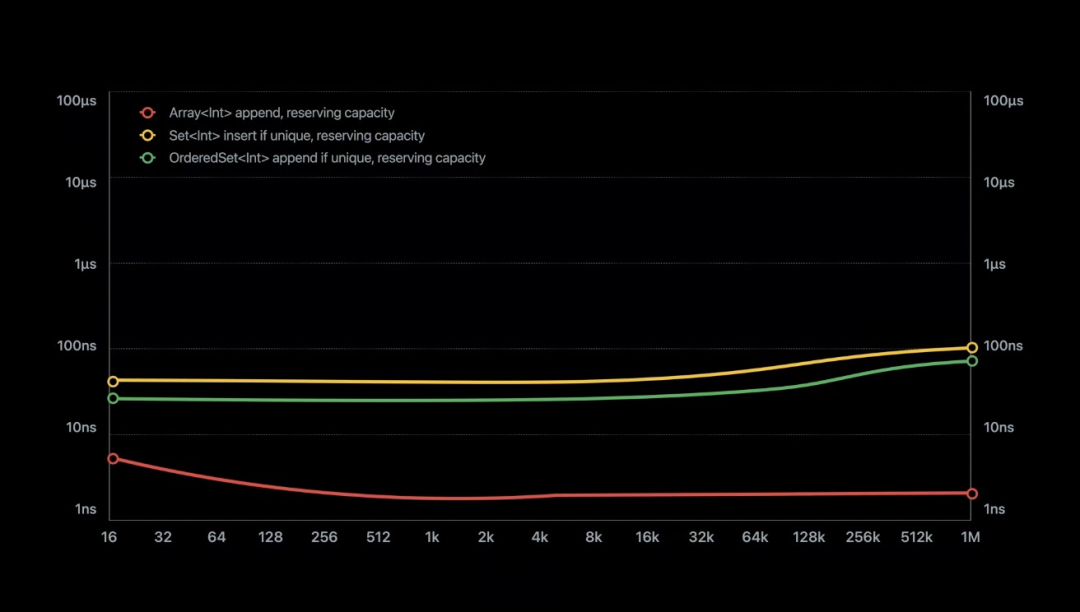
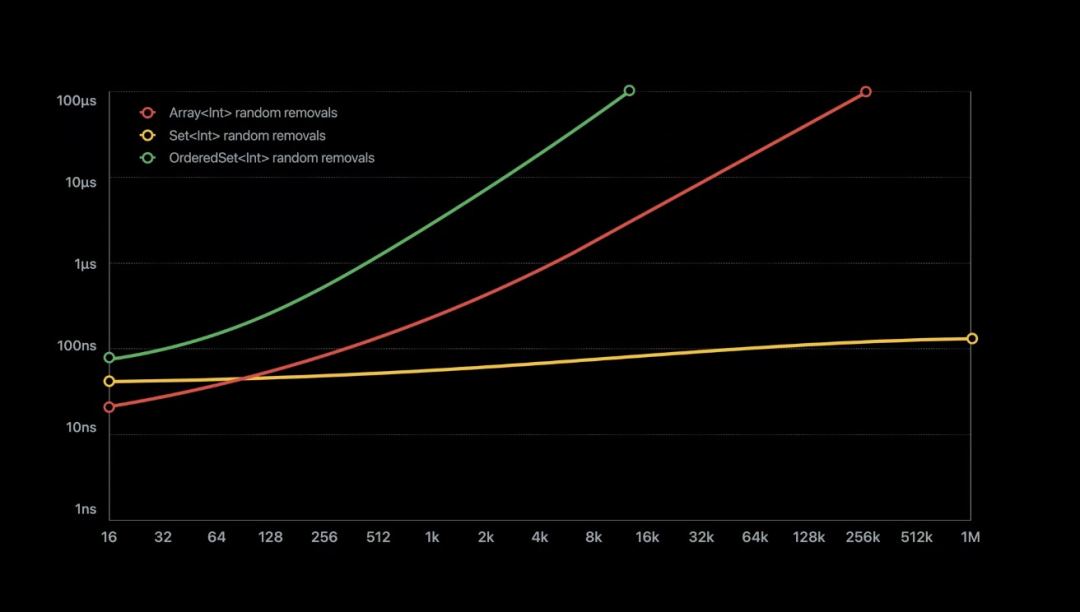
一般的 Set 通过 hash 函数将元素直接存储在哈希表里,这样能保证元素的唯一性,在查找元素上也有很好的性能,但是元素之间的顺序却是不确定的。而在某些特别的情况下,需要对 Set 中的元素设置一定的顺序。
Swift 实现的 OrderedSet,具体的元素放到了数组里,而原来的哈希表用来存储元素在数组中的索引。索引的范围受哈希表的大小限制,所以通过将整数值换成二进制的方法来压缩表。

OrderedDictionary
常规的字典使用两个单独的哈希表来存储键值对,而有序字典则是使用单个哈希表和两个数组。

dict[0] 应该取 key 等于 0 的 value,还是取索引为 0 的 key-value 键值对?Swift 开发工程师认为基于 key 取值是字典的常用操作,所以有序字典里没有提供直接使用索引的操作,而且有序字典也只符合了序列的协议。而符合集合协议的下标操作,通过了 elements 来实现

总结
个人认为,对于算法和数据结构需要做到知其然知其所以然。不同的数据结构有不同的优缺点,Swift 推出更多的类型也是帮助我们能够有更好更多的选择范围。因为是面向协议的实现方式,即使是新增的算法也能在原先数据结构上使用。算法链的使用,包括他的 lazy 特性,也是为了写出更 Swift 化 -- 简洁易懂的代码。
参考资料
[1]Session 10256: https://developer.apple.com/videos/play/wwdc2021/10256/
[2]SwiftGG - 闭包: https://swiftgg.gitbook.io/swift/swift-jiao-cheng/07_closures#shorthand-argument-names
[3]“懒”点儿好: https://swift.gg/2016/03/25/being-lazy/
[4]Swift Algorithms: https://github.com/apple/swift-algorithms
[5]Swift Collection: https://github.com/apple/swift-collections
[6]设计循环双端队列: https://leetcode-cn.com/problems/design-circular-deque/