内存虚拟化(内存地址转换)
前言
操作系统中的内存管理很复杂,涉及到了很多知识,最重要的就是虚拟内存。虚拟内存一方面是用来扩充空间,使进程拥有”更多的内存“,另一方面,他为每个进程提供了一个一致、私有的地址空间,让进程似乎在“独享主存”。在虚拟机中运行的操作系统的虚拟内存似乎和操作系统的虚拟内存不同,一个需要通过虚拟化技术来对virtual memory(虚拟内存)进行虚拟化,一个则是virtual memory(虚拟内存)。
地址转换
在Linux中的地址转换通常是Virtual Address(虚拟地址)通过MMU和页表转换得到Physical Address(物理地址)。
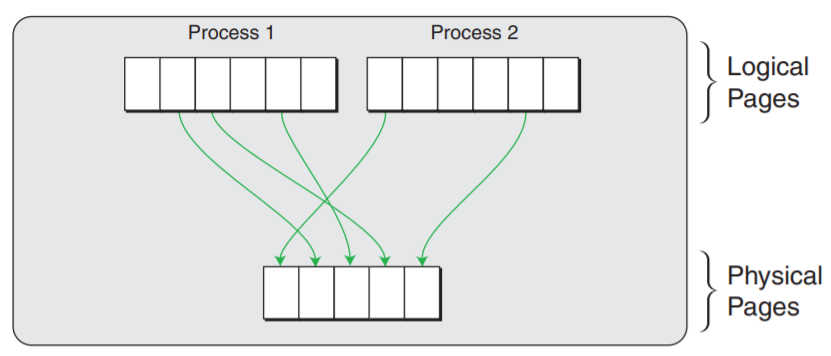
之所以不直接用物理地址是因为:
- 多个进程同时运行时,他们的映像文件地址可能会一致,发生冲突。
- 直接使用物理地址,不便于对进程地址空间进行隔离
- 物理内存有限,使用虚拟地址,在内存紧张时可以通过分时方式让多个进程共享页面
MMU
MMU是处理器/核(processer)中的一个硬件单元,通常每个核有一个MMU。MMU由两部分组成:TLB(Translation Lookaside Buffer)和table walk unit。
TLB
快表,直译为旁路快表缓冲,也可以理解为页表缓冲,地址变换高速缓存。
由于页表存放在主存中,因此程序每次访存至少需要两次:一次访存获取物理地址,第二次访存才获得数据。提高访存性能的关键在于依靠页表的访问局部性。当一个转换的虚拟页号被使用时,它可能在不久的将来再次被使用到,。
TLB是一种高速缓存,内存管理硬件使用它来改善虚拟地址到物理地址的转换速度。当前所有的个人桌面,笔记本和服务器处理器都使用TLB来进行虚拟地址到物理地址的映射。使用TLB内核可以快速的找到虚拟地址指向物理地址,而不需要请求RAM内存获取虚拟地址到物理地址的映射关系。
table walk
- 从协处理器CP15的寄存器2(TTB寄存器,translation table base register ARM架构,X86中是CR3)中取出保存在其中的第一级页表(translation table)的基地址。这个基地址指的是PA,也就是说页表是直接按照这个地址保存在物理内存中的。
- 以TTB中的内容为基地址,以VA[31:20]为索引值在一级页表中查找对应表项。这个页表项保存着第二级页表(coarse page table)的基地址,这同样是物理地址,也就是说第二级页表也是直接按这个地址存储在物理内存中的。
- 以VA[19:12]为索引值在第二级页表中查出表项,这个表项中就保存着物理页面的基地址,我们知道虚拟内存管理是以页为单位的,一个虚拟内存的页映射到一个物理内存的页框,从这里就可以得到印证,因为查表是以页为单位来查的。
- 有了物理页面的基地址之后,加上VA[11:0]这个偏移量就可以取出相应地址上的数据了。
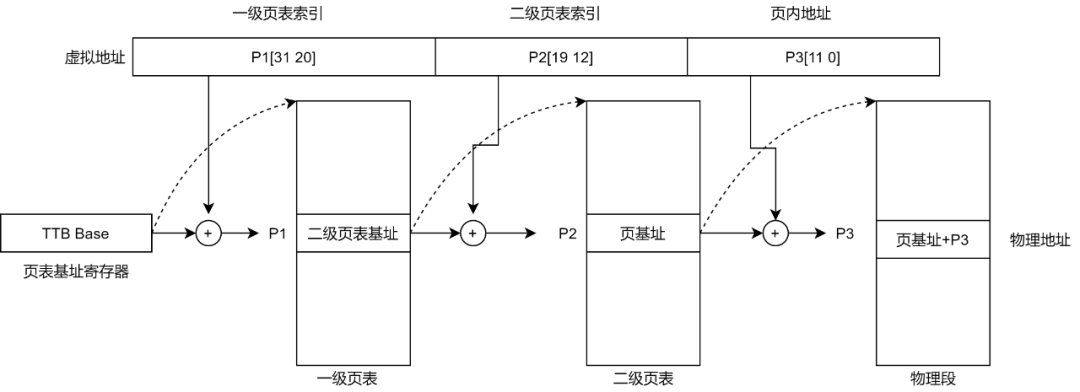
这个过程称为Translation Table Walk,Walk这个词用得非常形象。从TTB走到一级页表,又走到二级页表,又走到物理页面,一次寻址其实是三次访问物理内存。注意这个“走”的过程完全是硬件做的,每次CPU寻址时MMU就自动完成以上四步,不需要编写指令指示MMU去做,前提是操作系统要维护页表项的正确性,每次分配内存时填写相应的页表项,每次释放内存时清除相应的页表项,在必要的时候分配或释放整个页表。
页表
page table是每个进程独有的,是软件实现的,是存储在main memory(比如DDR)中的。
因为访问内存中的页表相对耗时,尤其是在现在普遍使用多级页表的情况下,需要多次的内存访问,为了加快访问速度,系统设计人员为page table设计了一个硬件缓存 - TLB,CPU会首先在TLB中查找,因为在TLB中找起来很快。TLB之所以快,一是因为它含有的entries的数目较少,二是TLB是集成进CPU的,它几乎可以按照CPU的速度运行。
如果在TLB中找到了含有该虚拟地址的entry(TLB hit),则可从该entry中直接获取对应的物理地址,否则就不幸地TLB miss了,就得去查找当前进程的page table。这个时候,组成MMU的另一个部分table walk unit就被召唤出来了,这里面的table就是page table。
使用table walk unit硬件单元来查找page table的方式被称为hardware TLB miss handling,通常被CISC架构的处理器(比如IA-32)所采用。它要在page table中查找不到,出现page fault的时候才会交由软件(操作系统)处理。
与之相对的通常被RISC架构的处理器(比如Alpha)采用的software TLB miss handling,TLB miss后CPU就不再参与了,由操作系统通过软件的方式来查找page table。使用硬件的方式更快,而使用软件的方式灵活性更强。IA-64提供了一种混合模式,可以兼顾两者的优点。
虚拟机地址转换
如果这个操作系统是运行在虚拟机上的,那么这只是一个中间的物理地址(Intermediate Phyical Address - IPA),需要经过VMM/hypervisor的转换,才能得到最终的物理地址(Host Phyical Address - HPA)。从VMM的角度,guest VM中的虚拟地址就成了GVA(Guest Virtual Address),IPA就成了GPA(Guest Phyical Address)。
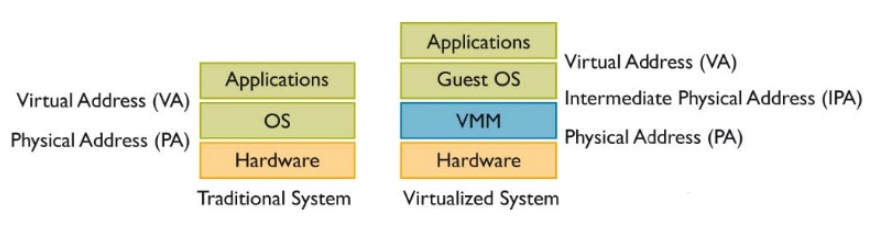
可见,如果使用VMM,并且guest VM中的程序使用虚拟地址(如果guest VM中运行的是不支持虚拟地址的RTOS,则在虚拟机层面不需要地址转换),那么就需要两次地址转换。
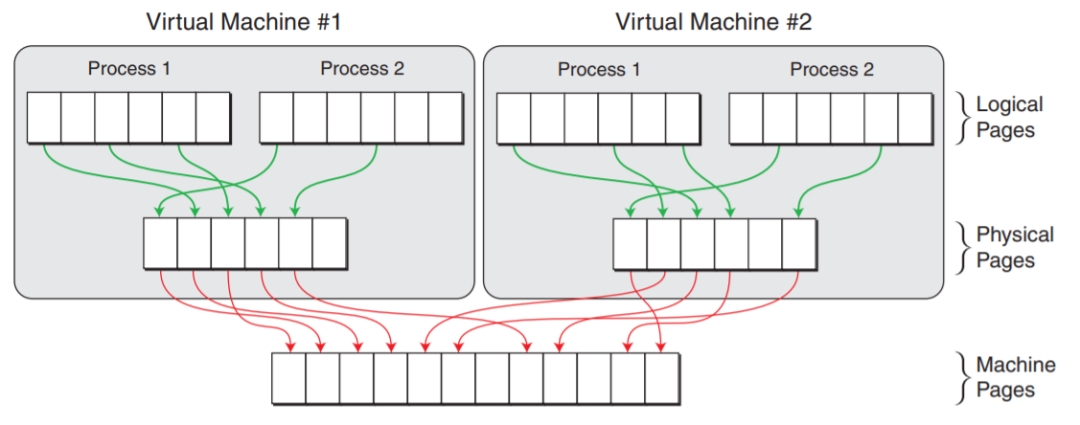
但是传统的IA32(x86_32)架构从硬件上只支持一次地址转换,即由CR3寄存器指向进程第一级页表的首地址,通过MMU查询进程的各级页表,获得物理地址。
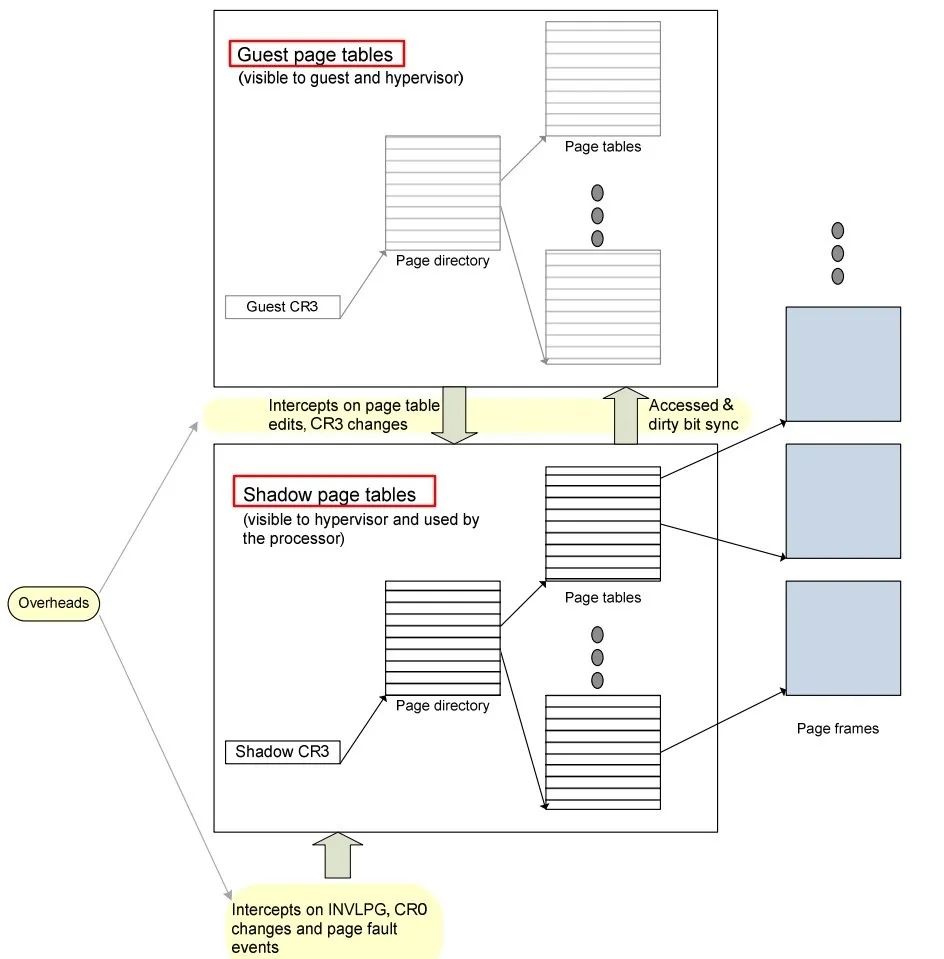
软件实现-影子页表
为了支持GVA->GPA->HPA的两次转换,可以计算出GVA->HPA的映射关系,将其写入一个单独的影子页表(sPT - shadow Page Table)。在一个运行Linux的guest VM中,每个进程有一个由内核维护的页表,用于GVA->GPA的转换,这里我们把它称作gPT(guest Page Table)。
VMM层的软件会将gPT本身使用的物理页面设为write protected的,那么每当gPT有变动的时候(比如添加或删除了一个页表项),就会产生被VMM截获的page fault异常,之后VMM需要重新计算GVA->HPA的映射,更改sPT中对应的页表项。可见,这种纯软件的方法虽然能够解决问题,但是其存在两个缺点:
- 实现较为复杂,需要为每个guest VM中的每个进程的gPT都维护一个对应的sPT,增加了内存的开销。
- VMM使用的截获方法增多了page fault和trap/vm-exit的数量,加重了CPU的负担。
在一些场景下,这种影子页表机制造成的开销可以占到整个VMM软件负载的75%。
硬件实现-EPT/NPT
为此,各大CPU厂商相继推出了硬件辅助的内存虚拟化技术,比如Intel的EPT(Extended Page Table)和AMD的NPT(Nested Page Table),它们都能够从硬件上同时支持GVA->GPA和GPA->HPA的地址转换的技术。
GVA->GPA的转换依然是通过查找gPT页表完成的,而GPA->HPA的转换则通过查找nPT页表来实现,每个guest VM有一个由VMM维护的nPT。其实,EPT/NPT就是一种扩展的MMU(以下称EPT/NPT MMU),它可以交叉地查找gPT和nPT两个页表:
假设gPT和nPT都是4级页表,那么EPT/NPT MMU完成一次地址转换的过程是这样的(不考虑TLB):
首先说明gCR3和nCR3,他们分别是客户机和主机CR3的拷贝。
首先它会查找guest VM中CR3寄存器(gCR3)指向的PML4页表,由于gCR3中存储的地址是GPA,因此CPU需要查找nPT来获取gCR3的GPA对应的HPA。nPT的查找和前面的页表查找方法是一样的,这里我们称一次nPT的查找过程为一次nested walk。
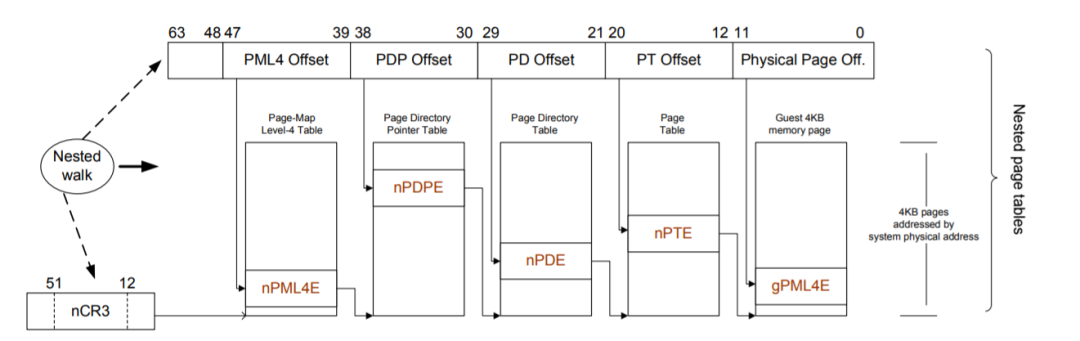
如果在nPT中没有找到,则产生EPT violation异常(可理解为VMM层的page fault)。如果找到了,也就是获得了PML4页表的物理地址后,就可以用GVA中的bit位子集作为PML4页表的索引,得到PDPE页表的GPA。接下来又是通过一次nested walk进行PDPE页表的GPA->HPA转换,然后重复上述过程,依次查找PD和PE页表,最终获得该GVA对应的HPA。
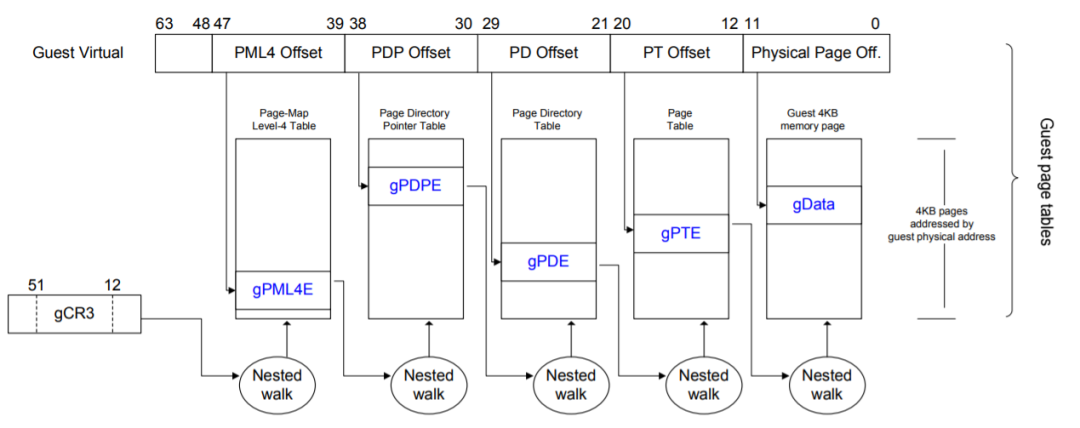
不同于影子页表是一个进程需要一个sPT,EPT/NPT MMU解耦了GVA->GPA转换和GPA->HPA转换之间的依赖关系,一个VM只需要一个nPT,减少了内存开销。如果guest VM中发生了page fault,可直接由guest OS处理,不会产生vm-exit,减少了CPU的开销。可以说,EPT/NPT MMU这种硬件辅助的内存虚拟化技术解决了纯软件实现存在的两个问题。
EPT/NPT MMU优化
事实上,EPT/NPT MMU作为传统MMU的扩展,自然也是有TLB的,它在查找gPT和nPT之前,会先去查找自己的TLB(前面为了描述的方便省略了这一步)。但这里的TLB存储的并不是一个GVA->GPA的映射关系,也不是一个GPA->HPA的映射关系,而是最终的转换结果,也就是GVA->HPA的映射。
不同的进程可能会有相同的虚拟地址,为了避免进程切换的时候flush所有的TLB,可通过给TLB entry加上一个标识进程的PCID(x86)/ASID(ARM)的tag来区分。同样地,不同的guest VM也会有相同的GVA,为了flush的时候有所区分,需要再加上一个标识虚拟机的tag,这个tag在ARM体系中被叫做VMID,在Intel体系中则被叫做VPID。
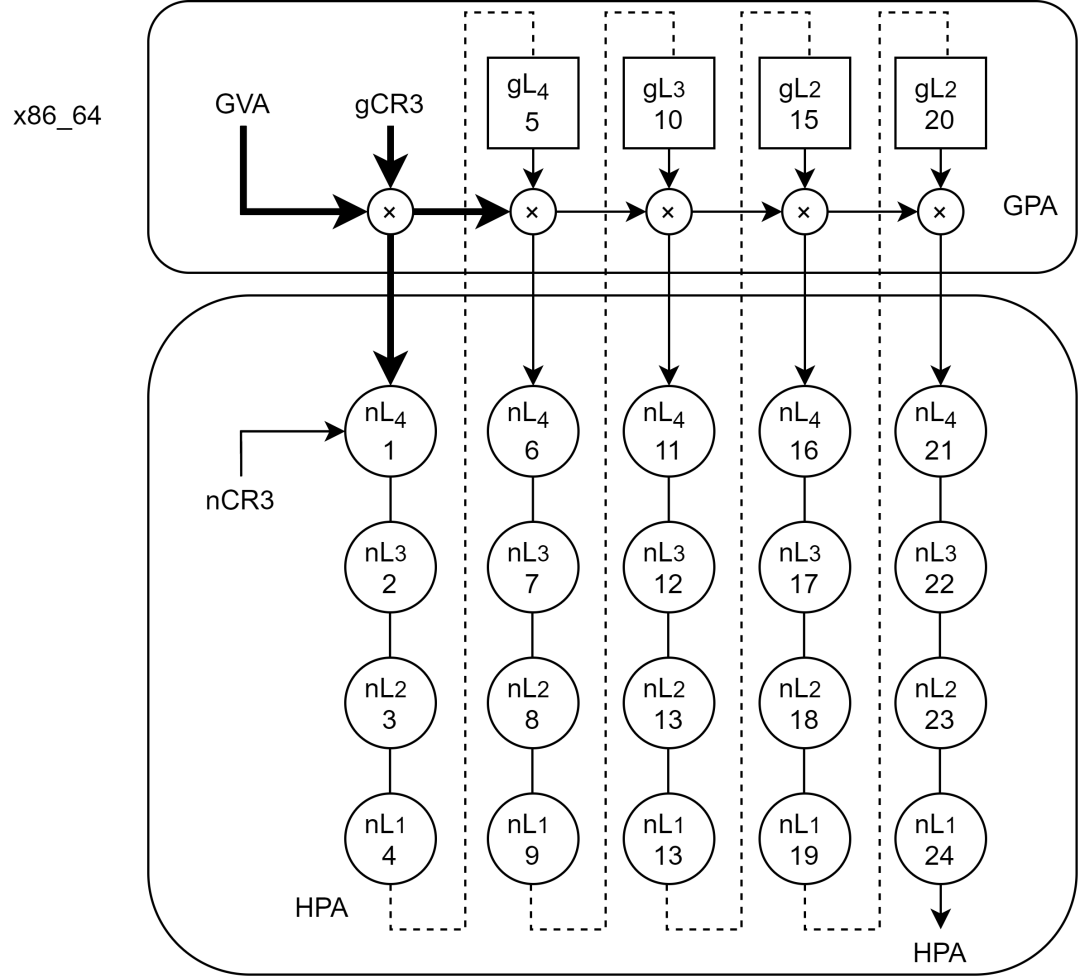
在最坏的情况下(也就是TLB完全没有命中),gPT中的每一级转换都需要一次nested walk,而每次nested walk需要4次内存访问,因此5次nested walk总共需要(4+1)*5-1=24次内存访问(就像一个5x5的二维矩阵一样):
虽然这24次内存访问都是由硬件自动完成的,不需要软件的参与,但是内存访问的速度毕竟不能与CPU的运行速度同日而语,而且内存访问还涉及到对总线的争夺,次数自然是越少越好。
要想减少内存访问次数,要么是增大EPT/NPT TLB的容量,增加TLB的命中率,要么是减少gPT和nPT的级数。gPT是为guest VM中的进程服务的,通常采用4KB粒度的页,那么在64位系统下使用4级页表是非常合适的。
而nPT是为guset VM服务的,对于划分给一个VM的内存,粒度不用太小。64位的x86_64支持2MB和1GB的large page,假设创建一个VM的时候申请的是2G物理内存,那么只需要给这个VM分配2个1G的large pages就可以了(这2个large pages不用相邻,但large page内部的物理内存是连续的),这样nPT只需要2级(nPML4和nPDPE)。
如果现在物理内存中确实找不到2个连续的1G内存区域,那么就退而求其次,使用2MB的large page,这样nPT就是3级(nPML4, nPDPE和nPD)。
总结
不管是影子页表还是EPT/NPT的优化都能看得出,虚拟化中的地址转换所依托的还是虚拟内存中的地址转换方式。相比于影子页表硬件层面的EPT/NPT技术显然更胜一筹,速度更快,开销更少,由于虚拟化本身的属性,它所依托的还是真实的物理机,所以要理解这一部分还是需要先了解OS内存管理中的地址转换是如何进行的。
参考资料
https://zhuanlan.zhihu.com/p/69828213
https://zhuanlan.zhihu.com/p/66971714
https://www.vmware.com/pdf/Perf_ESX_Intel-EPT-eval.pdf
http://developer.amd.com/wordpress/media/2012/10/NPT-WP-1%201-final-TM.pdf

END