Uber系统架构设计
Uber 一开始是单体架构,后来逐渐演化为面向服务的架构。Uber 最早只为旧金山提供服务,他们称之为 UberBlack。后来随着核心领域模型的增长以及引入了越来越多的新特性,组件的耦合非常严重,持续集成变成了沉重的负担,每次部署都意味着需要一次性部署所有的东西。在单一代码库中添加新功能、修复 bug、解决技术债务变得非常困难,这也是为什么 Uber 后来采用面向服务的架构的原因,这也促使 Uber 工程团队重构了新的 Uber 应用。
新应用程序增加了 UberPool、预约出行和促销车辆的视图。
目标
- 实现优步核心出行体验 99.99%的可靠性(每年最多 1 小时的停机时间,每周最多 1 分钟,换句话说,每 10000 次运营一次只能出现 1 次故障)
- 代码库拆分成两部分:核心代码和可选代码。核心代码被用于乘客注册、呼叫、完成或取消出行要求时,任何对核心代码的修改都必须经过严格的审查。可选代码很少被审查,并且可以在任何时候被动态关闭。这鼓励了代码级别上的相互独立,允许我们尝试新特性并随时停止它们。
- 核心架构:类名、业务逻辑单元之间的继承关系、主业务逻辑、插件点(名称、依赖关系、结构等)、响应式编程链(响应式编程之间的关系)、统一平台组件(统一的平台级模块)
解决方案
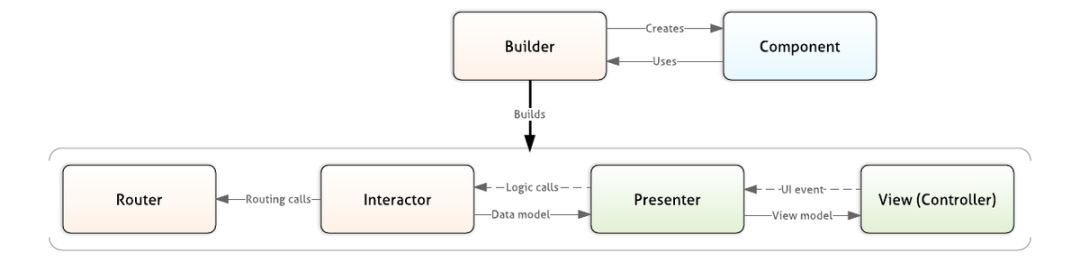
- 应用 iOS 架构(从 MVC 到 VIPER,并创建 Riblets)
功能性需求
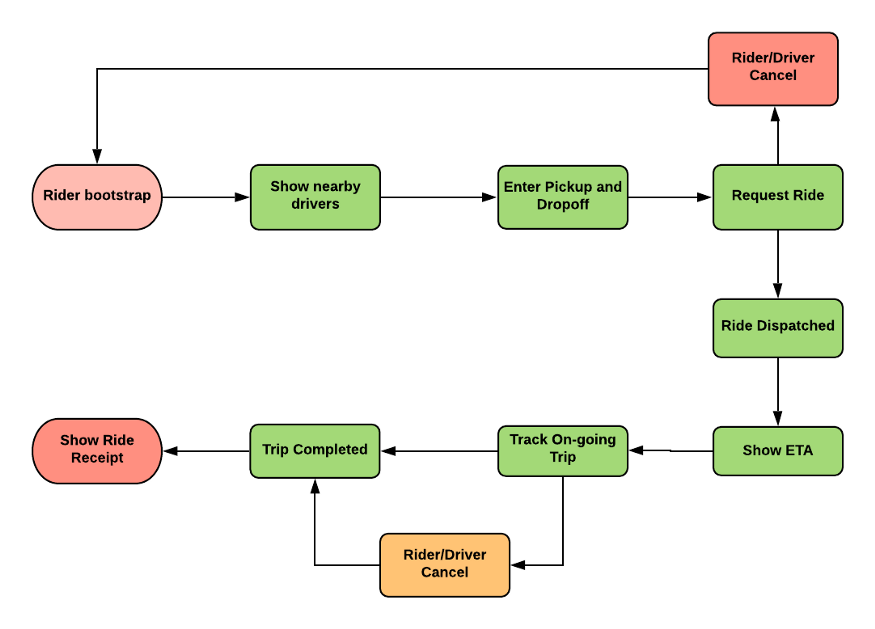
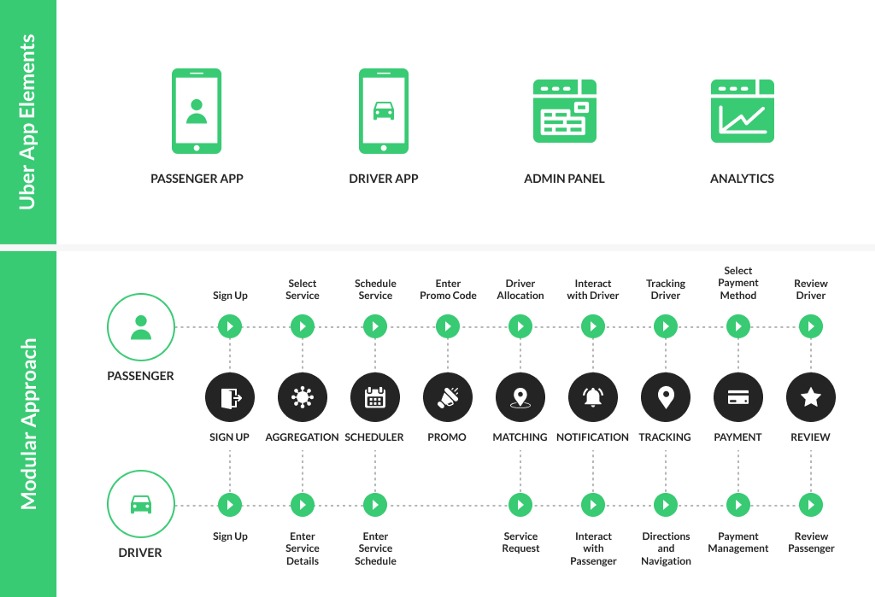
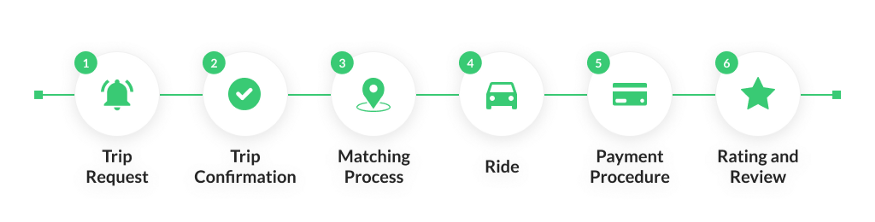
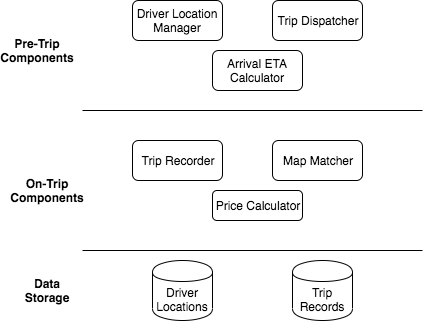
- 乘客可以查看附近的司机
- 乘客可以发起乘车请求
- 乘客可以查看司机的预计到达时间和预计价格
- 司机如果接受请求,直到整个行程结束,乘客都可以查看司机的位置并与之沟通
- 乘客可以预定出租车
- 可以自动匹配乘客和司机
- 可以看到附近的出租车
- 位置跟踪
- 事后操作:评价、发送电子邮件、更新数据库、付款
- 价格和激励:在预测算法的帮助下,当需求增加而供给减少时,价格会上升。据 Uber 称,激励有助于满足供给需求,通过提高价格,当需求增加时,路上会有更多的出租车。
非功能性需求
- 全球化
- 低时延
- 高可用
- 高一致性
- 可扩展性
- 数据中心故障:用于处理意外的级联故障或上游网络提供商的失效。Uber 维护了一个备份数据中心,交换机已经准备好将所有数据都路由到备份数据中心,唯一的问题是正在进行的行程的数据可能没有备份。
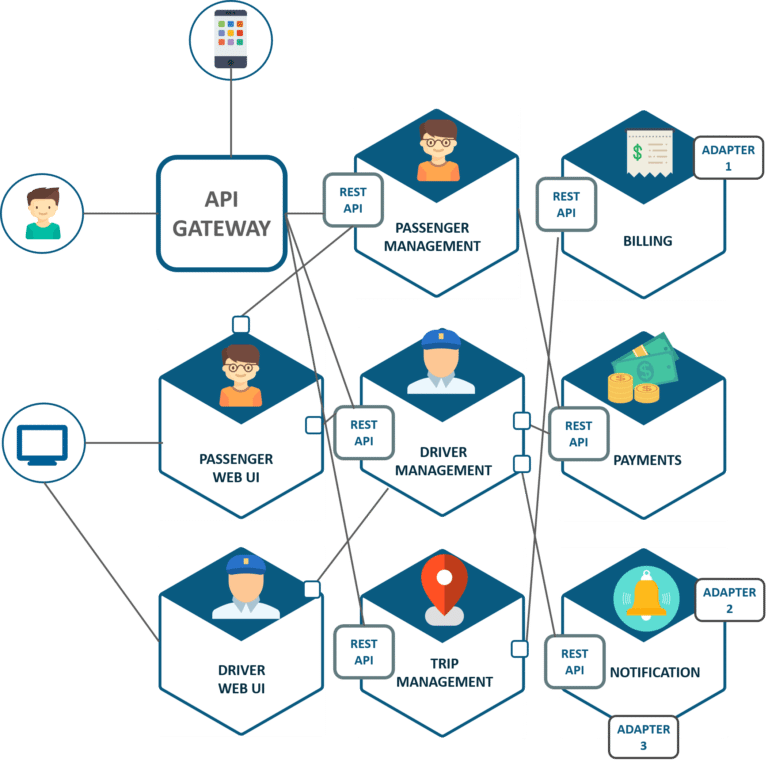
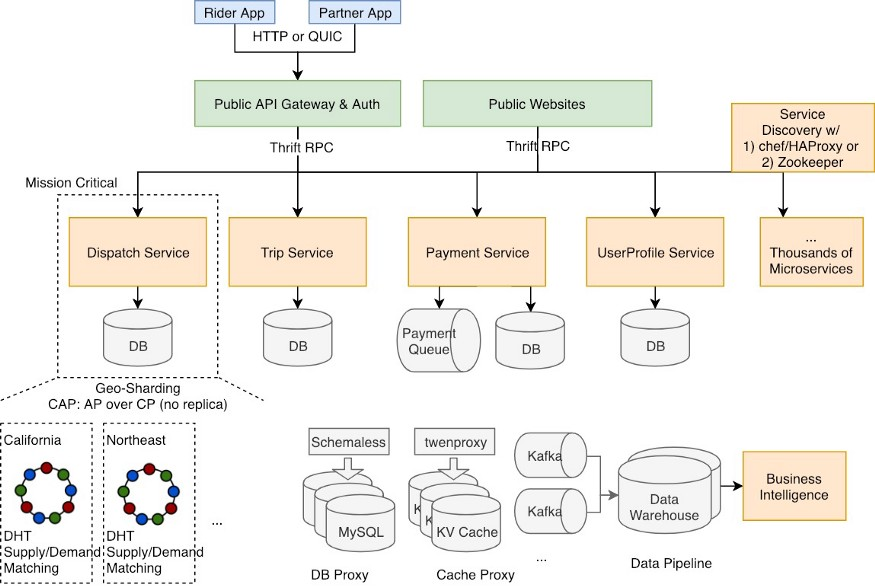
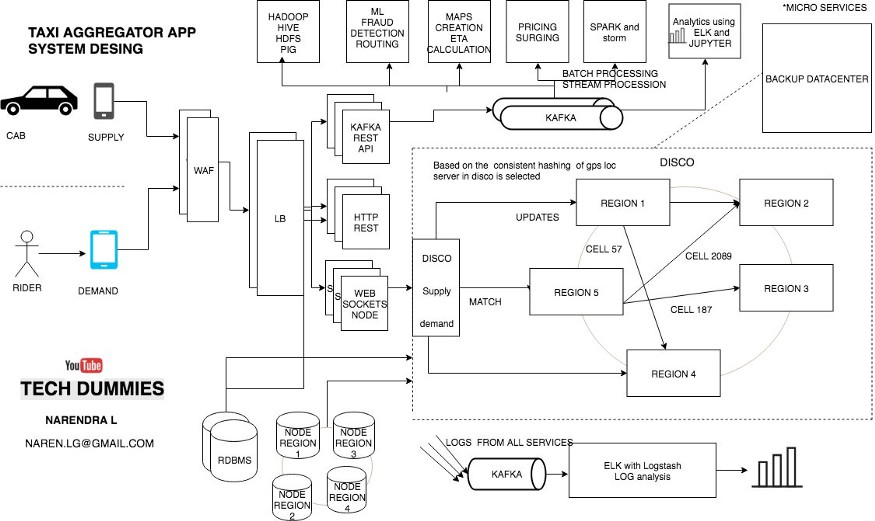
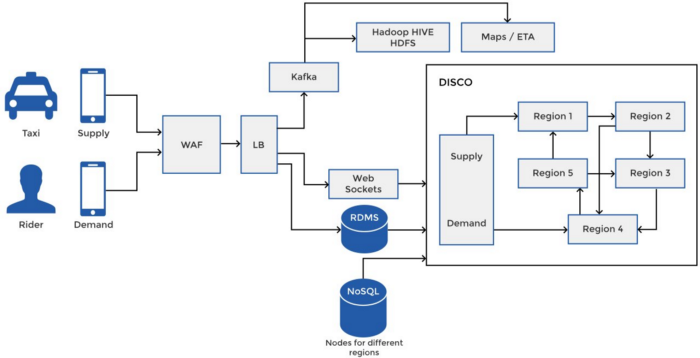
DISCO — Uber 系统的基础
- 供给服务(在司机端操作)
- 请求服务(在乘客端操作)
调度优化(或称 DISCO,Dispatch optimization)是 Uber 系统的一部分,用于基于位置数据匹配需求和供给。在匹配司机和乘客时,DISCO 保持最小化总服务时间和驾驶时间。与简单地使用纬度和经度来定位乘客和司机不同,DISCO 使用了更精确的谷歌 S2 库,它将地图划分为多个小单元。例如根据需求,可以在地图上设置 1 平方公里的单元格,每个单元分配唯一的 ID,因此在分布式系统中可以通过 ID 更方便的存储和访问单元数据,并且可以使用一致性哈希来存储单元数据。
调度系统基于 NodeJS 实现,提供基于事件的异步机制,允许在任何时候通过 WebSocket 和应用程序进行交互。Uber 使用一致性哈希环来扩展其 DISCO 服务器,从而在服务器之间有效分配负载,并自动检测集群中是否有新节点被添加或是否有节点从集群中移除,从而通过 SWIM/Gossip 协议重新分配工作负载。服务器之间通过 RPC 进行通信。
请求服务
- 乘客请求搭乘出租车
- 可以获得乘客发起请求的位置
- 微服务通过 WebSocket 获取乘客发起的请求
- 跟踪乘客的 GPS 位置
- 接受乘客的特定需求
- 将请求以及其他需求移交给调度系统,以将其连接到供给服务
供给服务
-
为司机端提供服务
-
使用经纬度数据(地理位置)跟踪出租车
-
所有在线的出租车每 5 秒过 Web 应用程序防火墙向负载均衡器发送一次它们的位置
-
负载均衡器将出租车的 GPS 位置定向到 Kafka REST API。
-
出租车的位置信息被更新到 Kafka,同时副本被发送到数据库和 DISCO,这样每个服务都可以使用最新的出租车位置信息
-
DISCO — 调度优化
- 减少司机驾驶时间
- 减少乘客等待时间
- 最小化总服务时间
出行数据
-
出租车位置数据
-
出行完成后的计费数据,包括出行开始和结束的时间戳,这样 Uber 可以计算车费并向乘客收费
-
数据库架构
-
支持应用频繁读写
-
因为出租车每 5 秒更新一次位置信息,因此会有频繁的写操作。同时有很多出行请求,意味着读操作也会很频繁。
-
从关系型数据库 PostgreSQL 到建立在 MySQL 之上的无模式 NoSQL 数据库
-
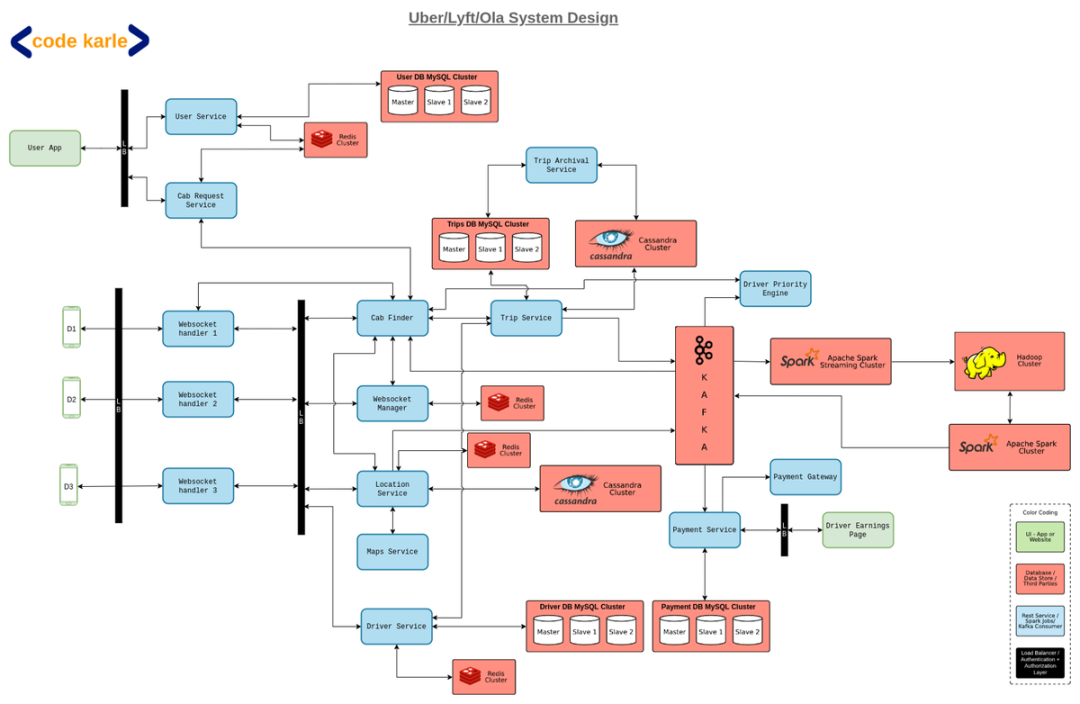
系统架构
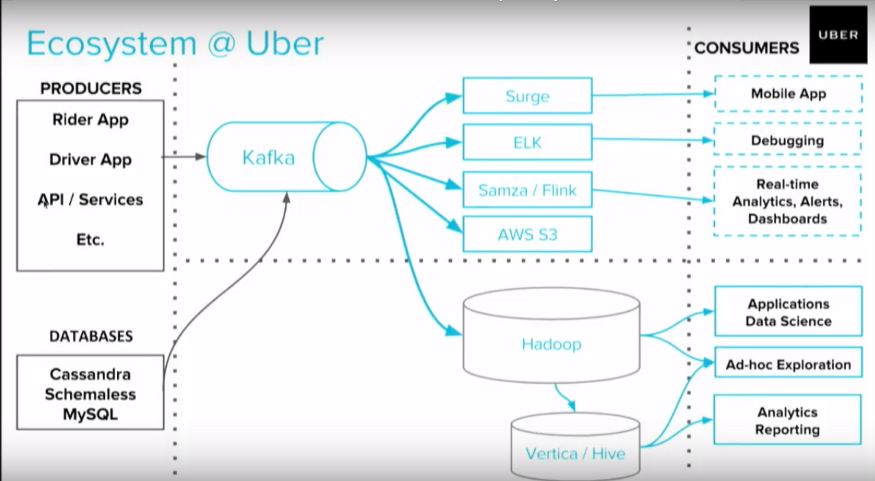
系统组件
地图 — 把出租车位置发送给乘客
- 乘客发出出行请求,应用程序会在地图上显示附近所有司机的位置。当客户打开地图时,会向服务器发送查找附件所有司机的查询。
- Kafka 提供的实时位置数据将用于计算司机到达时间,这样乘客就可以知道车辆什么时候会来,同时还会告诉乘客到达目的地的预计时间。
- Dijkstra 算法可以用来在有公路网的地图上找到最短路径。由于最短路径(按距离计算)并不总是最快路径(繁忙的交通可能会影响到达时间),更复杂的人工智能算法也可以用来估算最短行驶时间。
Web 应用防火墙
- 出于安全原因会设置防火墙,用来拦截来自可疑来源或服务不支持地区的请求。
负载均衡
- Uber 使用三层负载均衡器,分别用于处理网络的三层、四层和七层协议。L3 是基于 IP 的负载均衡,L4 用于基于 DNS 的负载均衡,L7 处理应用程序负载均衡。
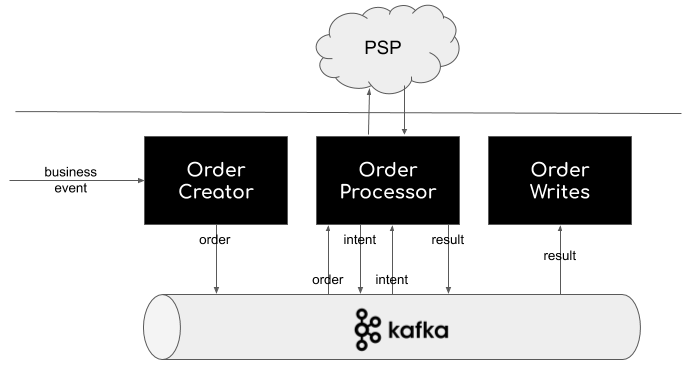
Kafka
- Kafka 为 Uber 提供了日志层。它可以立即将更新记录到某个存储位置,从而可以被不同微服务使用。Kafka 提取所有这些实时更新并保证没有信息丢失。在实现上,通过一个 Kafka 服务器集群来达成这个目的。
Web Sockets
- 在这种类型的应用程序中,客户端(包括乘客应用和司机应用)和服务器之间的通信可以通过 Web Sockets 来完成,从而可以保持客户端与服务器之间的长连接。
Hadoop
- Uber 通过分析数据来改善服务。Kafka 会定期在 Hadoop 中存储和归档数据,这些数据在分析应用程序的不同使用趋势时很有帮助。例如,可以知道何时何地有更多的 Uber 司机或更多的出行请求。
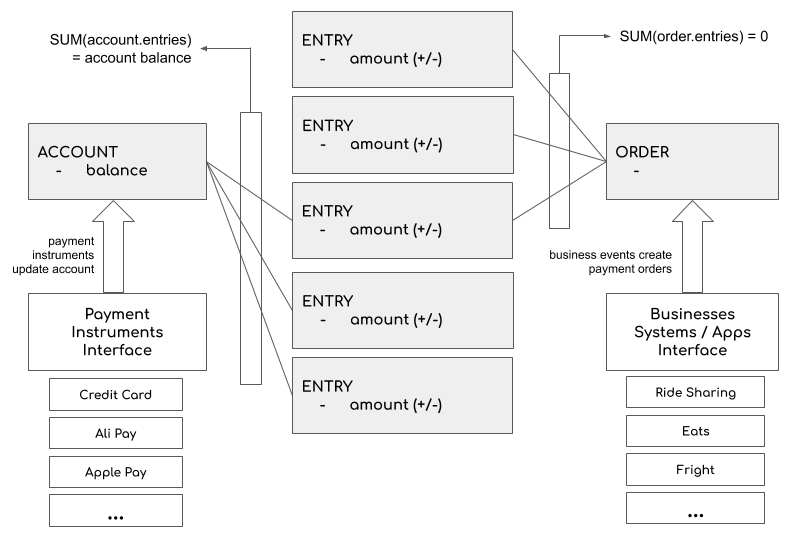
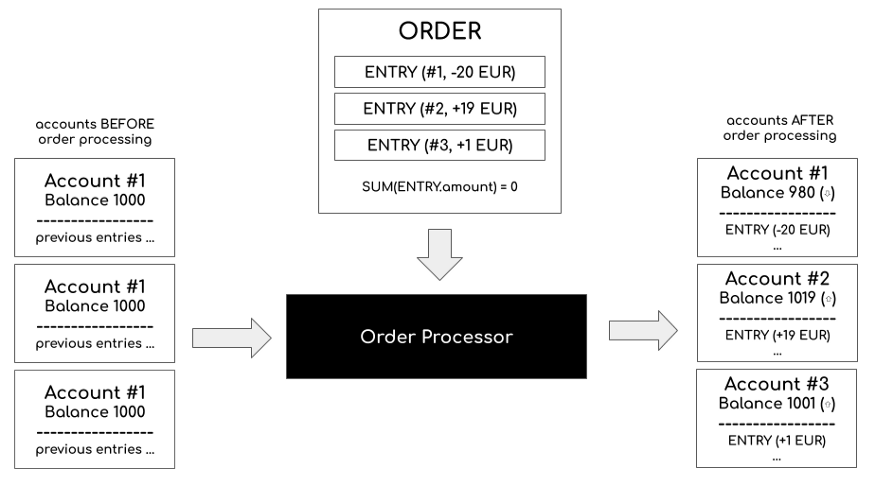
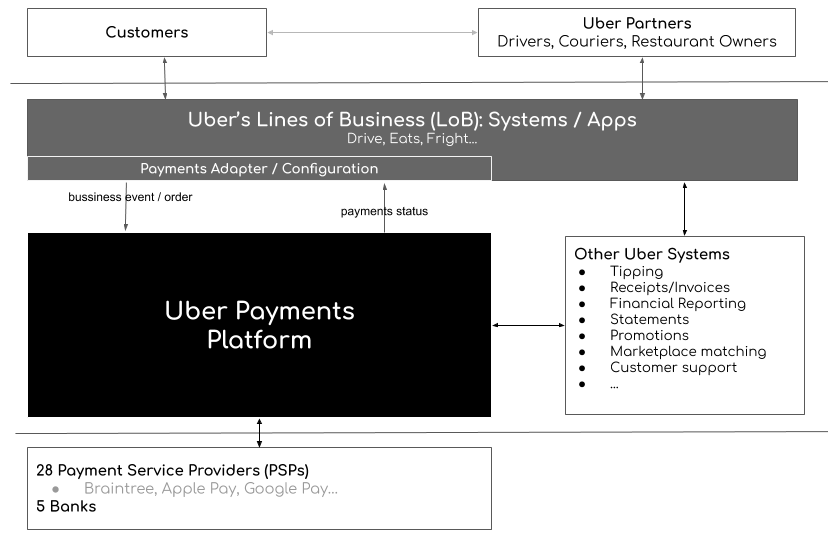
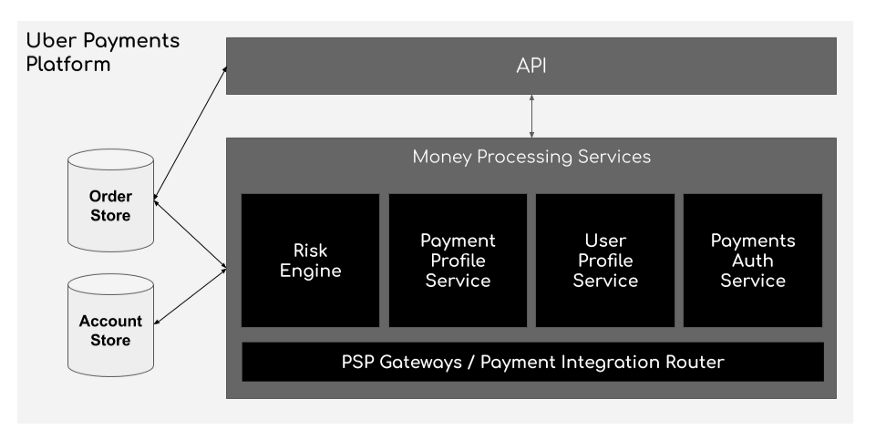
基于 MySQL 的支付数据库
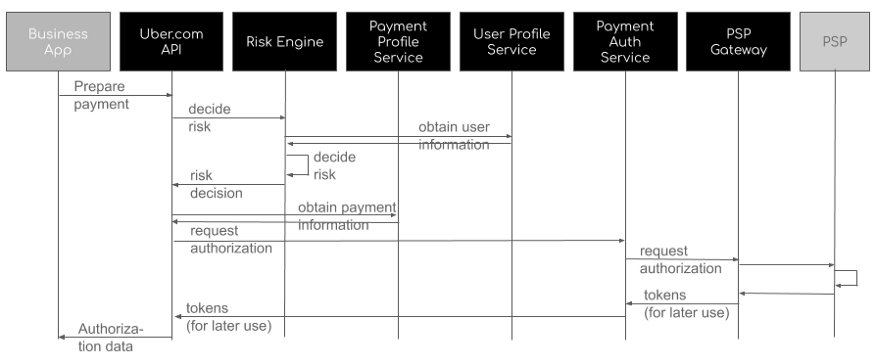
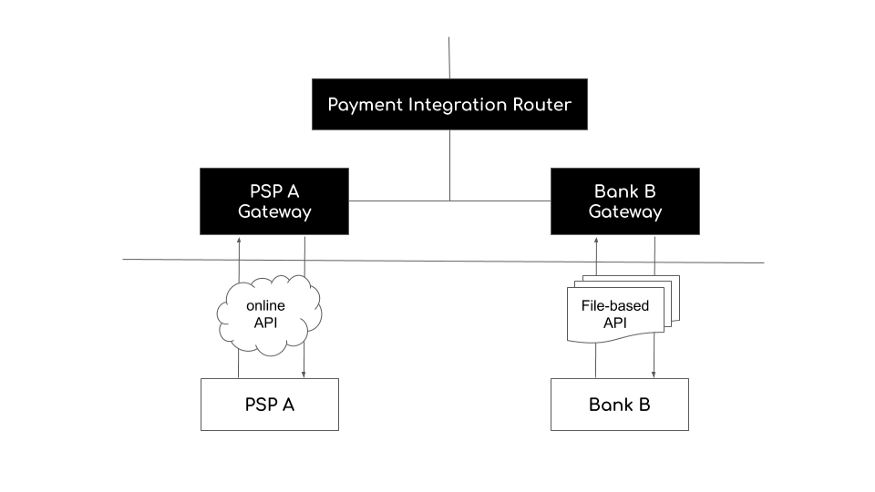
- 支付服务基于 Kafka,在出行服务完成后被触发。一旦出行完成,基于距离、时间等信息,计算出需要支付金额,并将所有这些信息插入支付 MySQL 数据库中。如果需要的话,支付服务也将与支付网关对接。此外还提供开放 API,以供查询客户或司机帐户所有与支付相关的信息。
- 支付选项,方便用户添加新的支付配置文件
- 对交易进行支付预授权,保证有一定数量的金额可供支付
- 取消付款,退款
- 获取客户账户并收费,将金额从用户账户转移到 Uber
- 删除支付选项和配置文件
- 小费
- 预约服务
- 促销
- 按期清偿未付款项
- 在服务期间切换支付方式
- 默认支付方式,支持回退或选择
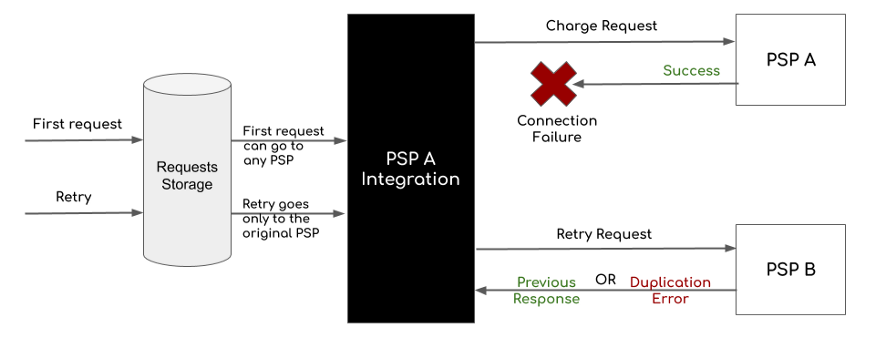
- 重复支付
- 不正确的货币转换
- 错误的付款
- 缺失的付款
- 空授权


Spark 流处理集群
- 跟踪基本事件,例如找不到司机,识别缺少司机的区域,以及其他基本分析。Spark 集群还会转储 Hadoop 集群中的所有事件,以便进行进一步分析,如用户分析、司机行为分析等,从而可以将客户或司机划分为高级、常规等不同等级。
司机资料引擎
- 基于评价、服务时间精度等信息对司机进行分类
欺诈引擎
- 如果同一司机总是接同一用户的单子,他们很有可能是朋友,或者他试图利用 Uber 提供的激励计划。我们还可以使用相同的数据来获取交通或道路状况信息,从而进一步支持地图服务。
Kibana/Graphana - Elastic search
-
日志分析
-
跟踪 HTTP API,管理配置文件,收集反馈和评价,促销和优惠券,欺诈检测,支付欺诈,激励滥用,被盗账户
-
最后,
大数据
大数据是一个必须要发展的更好的解决方案。
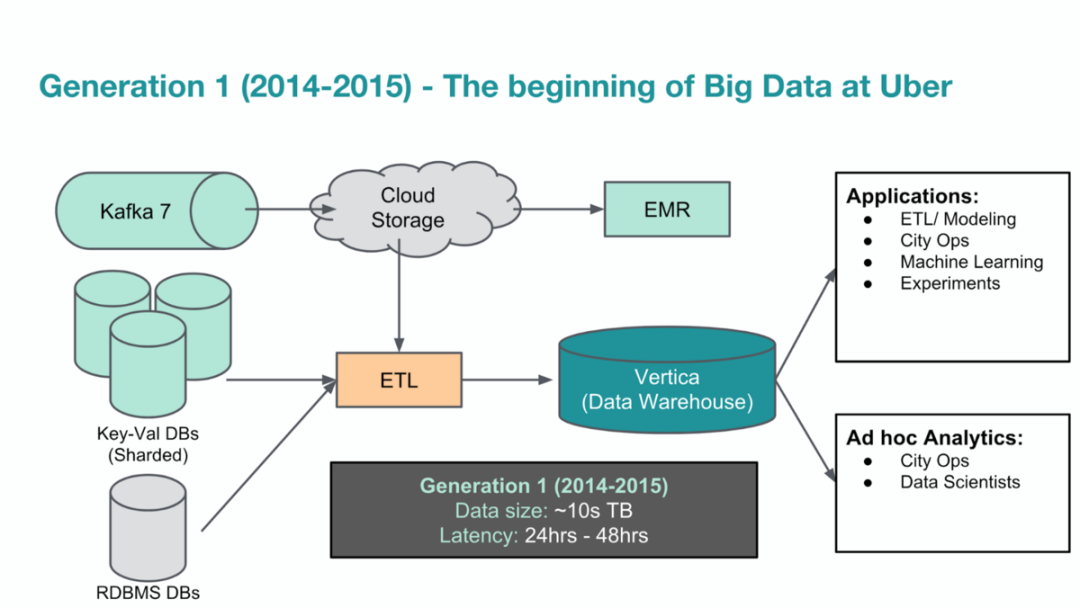
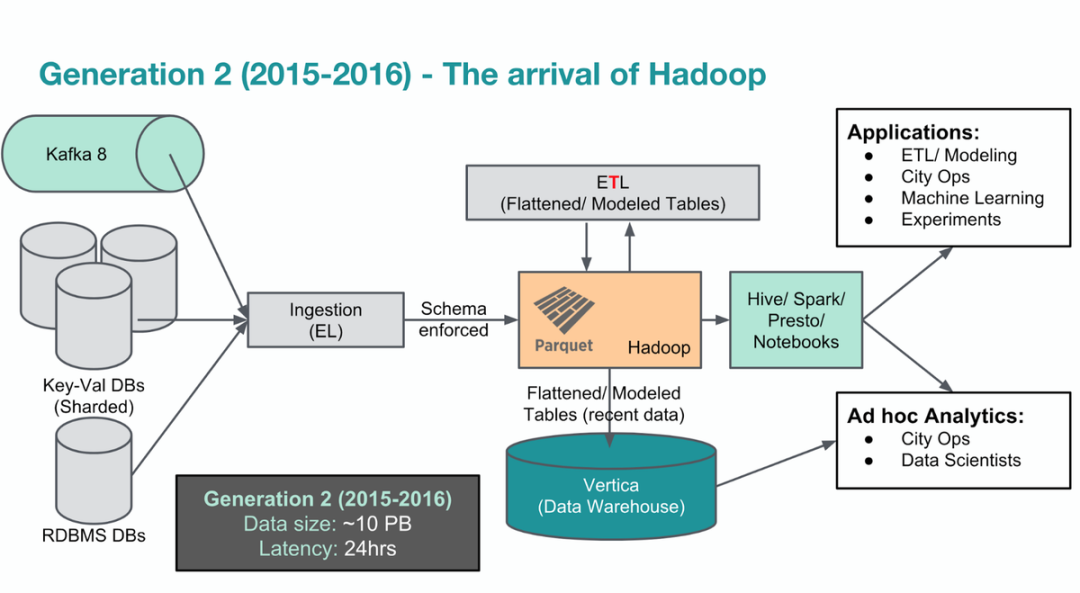
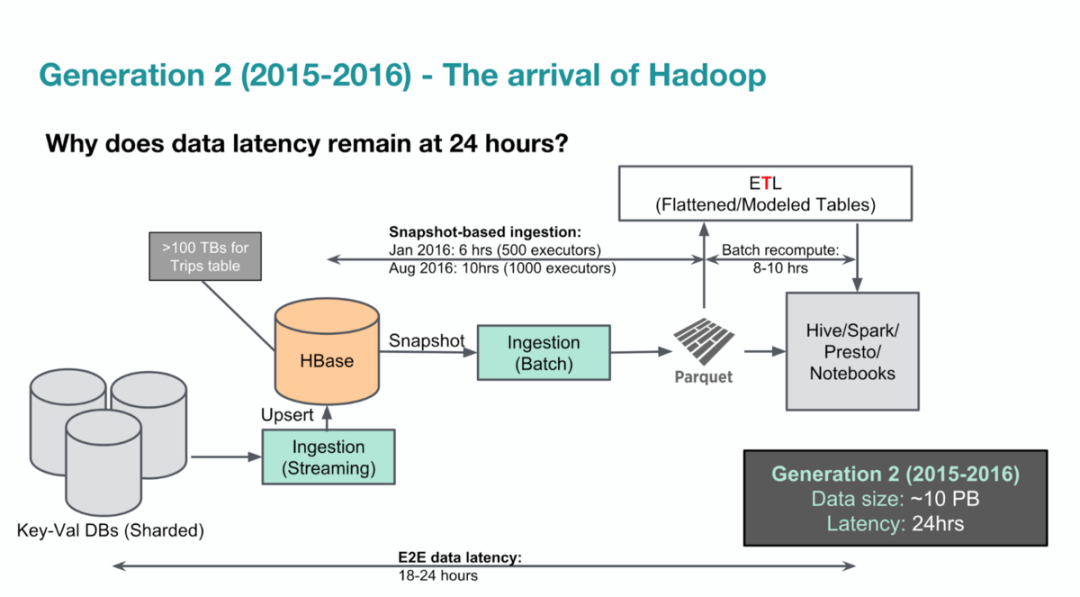
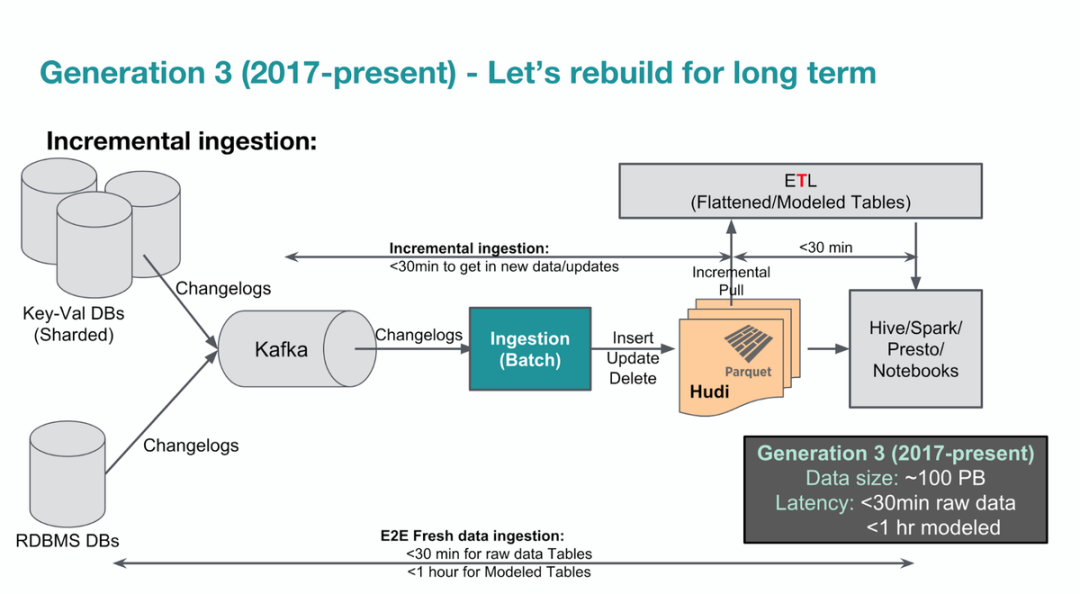
出处:https://xie.infoq.cn/article/c7c4c0fb77b70d1ea3c8c5e0b