字节工程师自研基于 IntelliJ 的终极文档套件
前言
众所周知,程序员最讨厌的四件事:写注释、写文档、别人不写注释、别人不写文档。因此,想办法降低文档的编写和维护成本是很有必要的。当前写技术文档的模式如图:
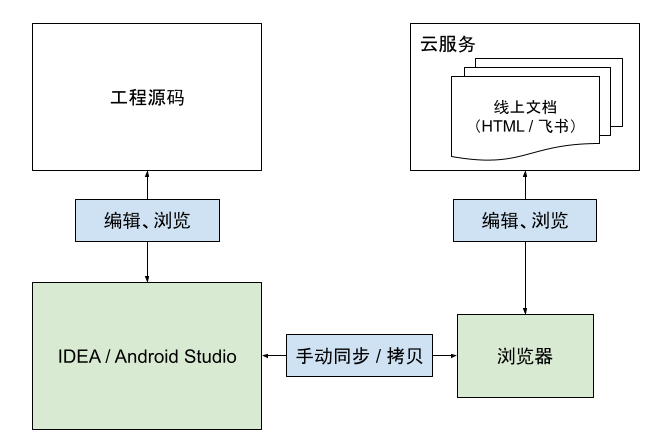
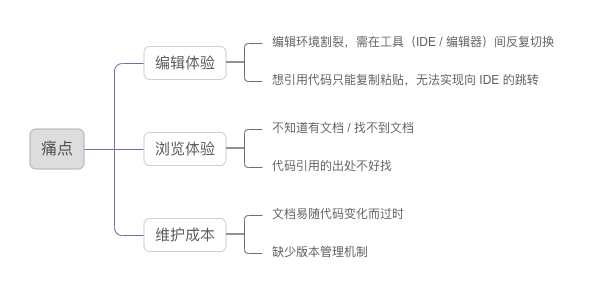
- 本地的编辑、浏览工作收敛至 IDE,提供沉浸式体验;
- 在文档、代码间建立强关联,减少拷贝,提升联动性,同时提升文档的触达率;
- 代码与文档同属一个 Git 仓库,借助版本管理,避免因业务迭代导致的文档版本与代码不匹配;
- 制作可将文档导出到线上的工具,可利用浏览器做到随时访问;
方案总览
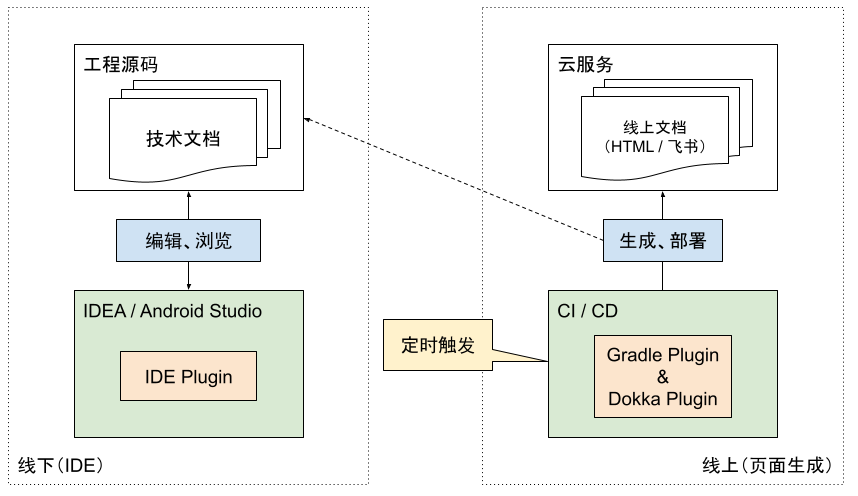
与原始模式相比,新方案可以做到完全脱离浏览器 / 文档编辑器,线上页面的同步完全交给定时触发的自动化部署。
图中橙色部分是方案的重点,按照分工,划分为线下、线上两部分,职责如下:
-
线下:IDEA Plugin
-
实现自定义语言的解析、分析;
-
提供文档内容的预览器、编辑器;
-
提供一系列实用功能,关联代码与文档;
-
线上:Gradle / Dokka Plugin
-
桥接、复用 IDE Plugin 的语义分析、预览内容生成能力;
-
扩展 Dokka Renderer,实现 HTML 与飞书文档的导出能力;
方案建设使用了不少有意思的技术,放到后面详细介绍。
线下效果
IDEA Plugin 提供一个侧边栏和强大的编辑器。下面分别从编辑、浏览两个角度介绍。
编辑体验
假设存在源码如下:
public class ClassA {
public static final String TAG = "tag";
ClassB b;
/**
* method document here.
*
* @param params input string
*/
public static void invoke(@NotNull String params) {
System.out.println("invoke method!");
System.out.println("this is method body: " + params);
}
public ClassA() {
System.out.println("create new instance!");
}
private static final class ChildClass {
/**
* This is a method from inner class.
*/
void innerInvoke() {
System.out.println("invoke method from child!");
}
}
}文档中添加该类的引用就是这个效果:
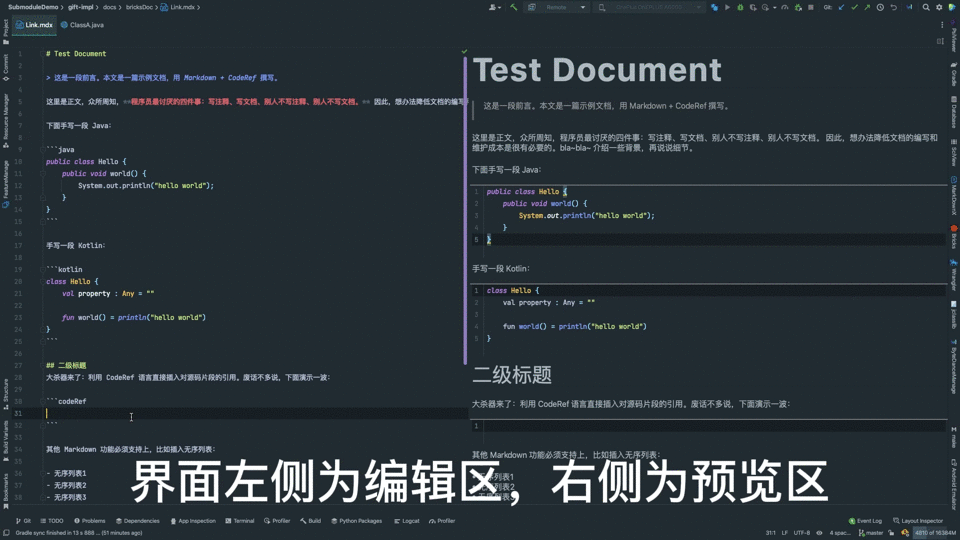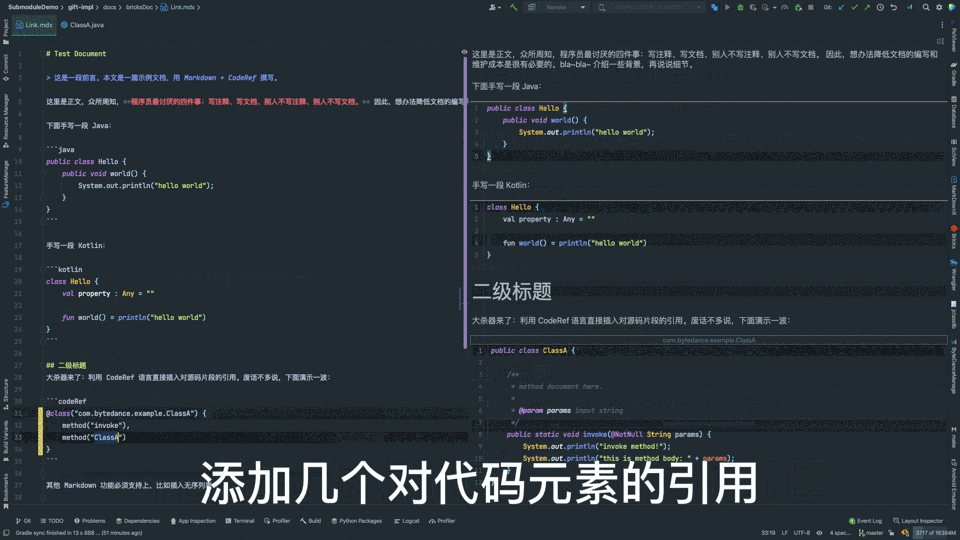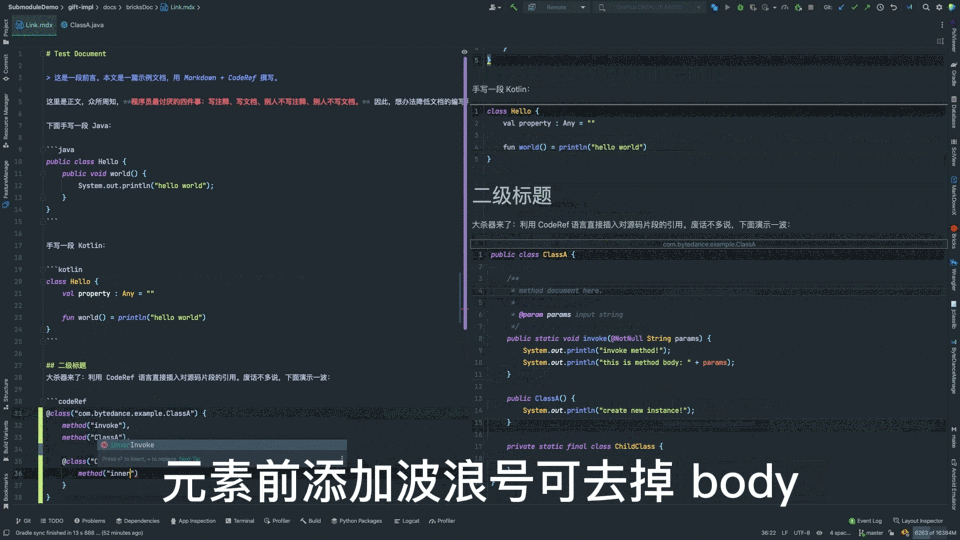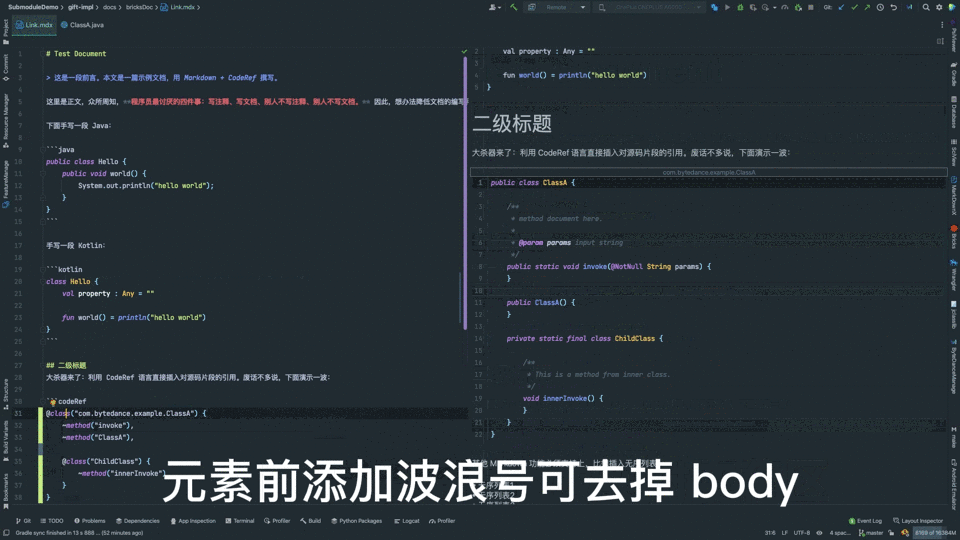
不同于复制、粘贴代码,新方案有如下优势:
- 关联性更强,预览会随代码片段的变更时时改变;
- 易于重构,被引用的类名、方法名、字段名发生重命名时,文档内容会自动随之变化,防止引用失效;
- 更加直观,编辑、浏览时能更快速地找到代码出处;
- 输入更流畅,有完善的补全能力;
浏览体验
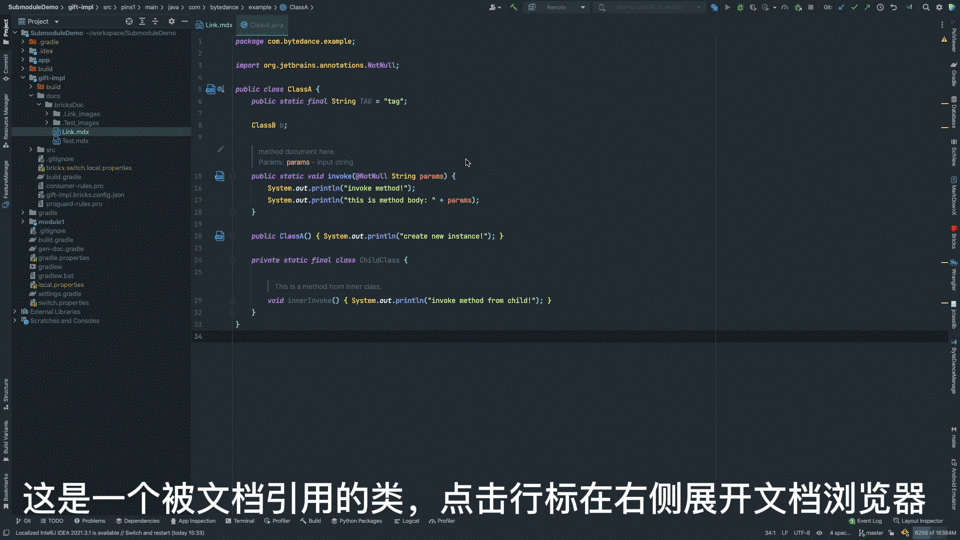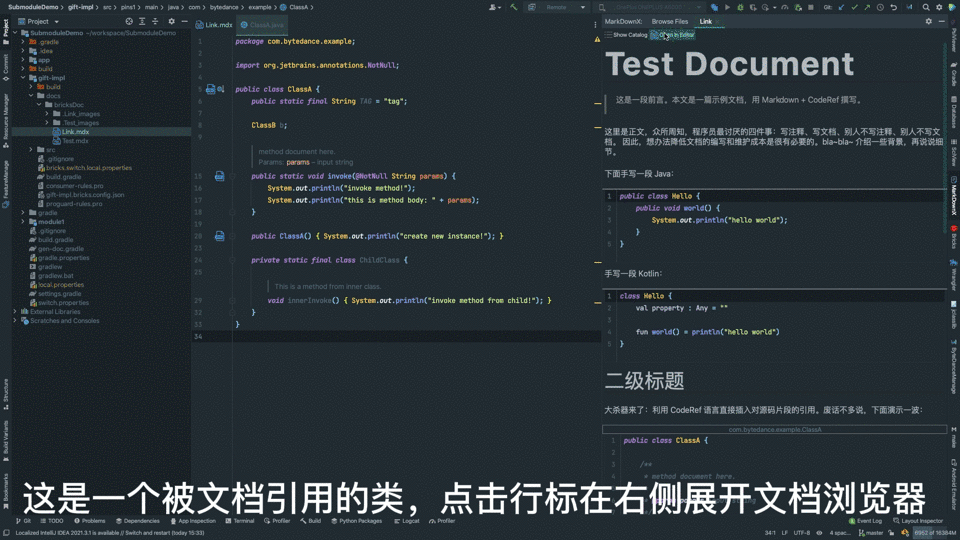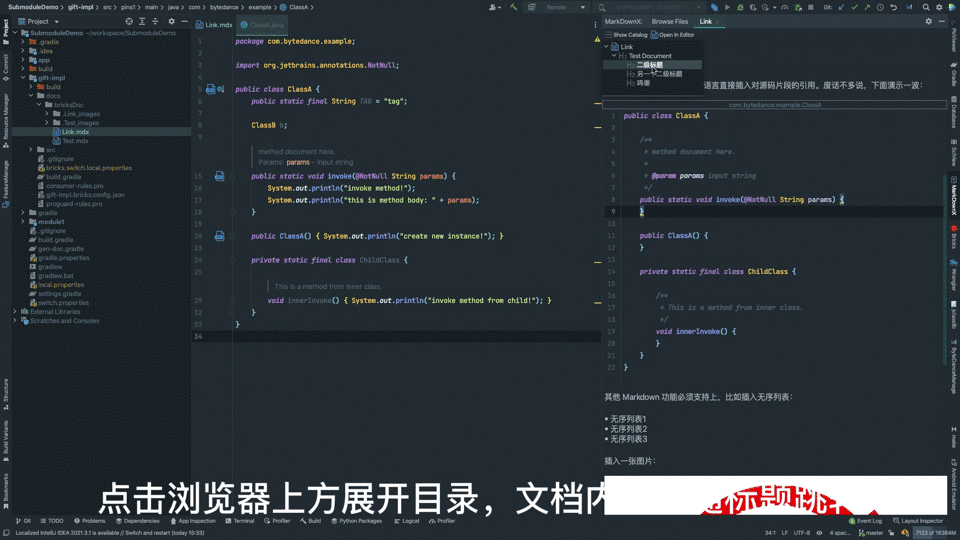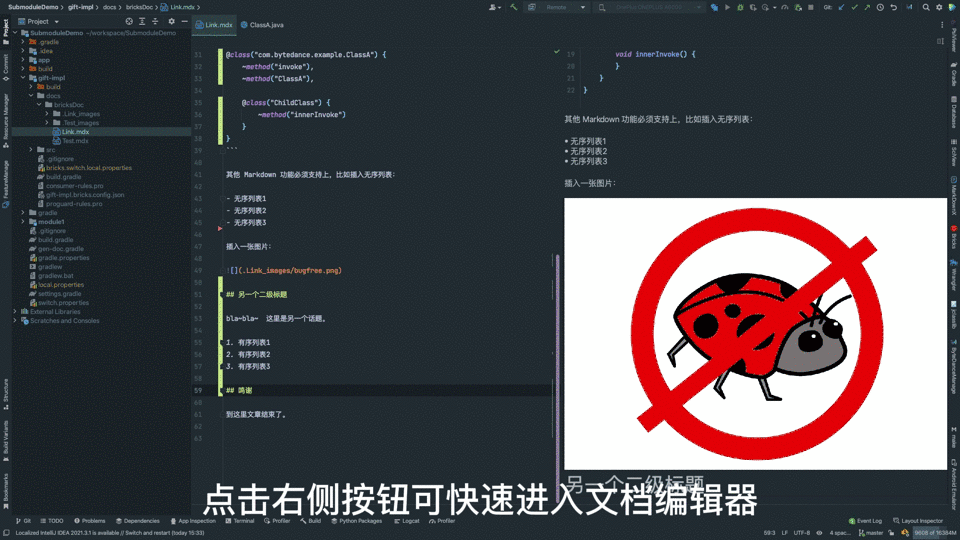
相对于普通 Markdown,新方案用起来更加友善:
- 沉浸式使用,界面内嵌在 IDE 内,无需跳转到其他应用;
- 被提及的源码旁均有行标,点击一键查阅文档;
- 文档“浏览器”支持与 IDE 一致的代码高亮、引用跳转;
线上效果
代码中文档会定期自动部署到远端。以一篇真实业务文档举例,HTML 部署到轻服务后长这样:
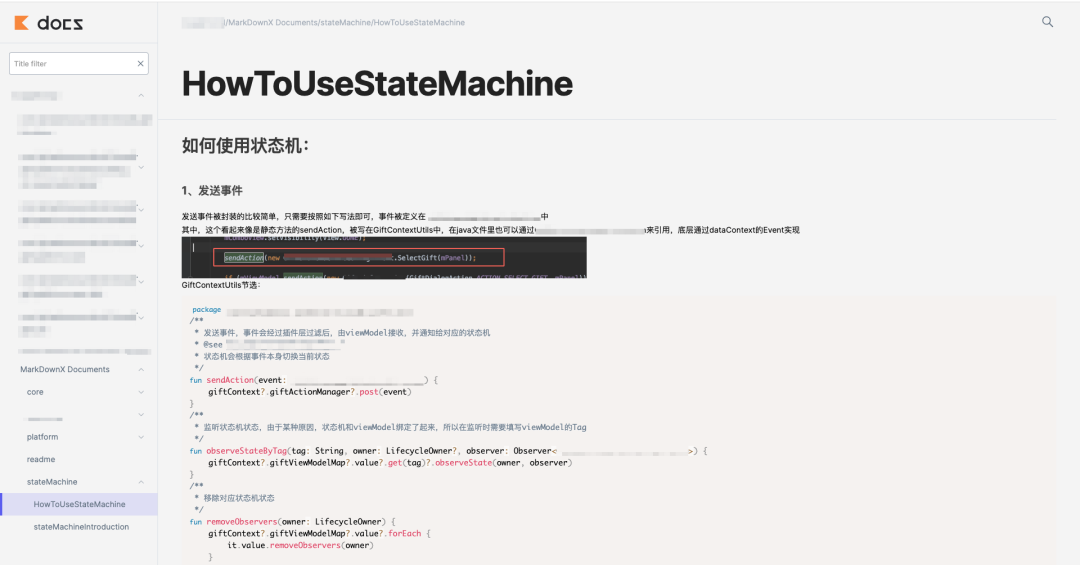
这些线上页面主要面向非当前团队的读者,内容由 CI 定时同步,暂不提供跳转到 IDE 的能力。
技术实现
项目的架构如图所示:
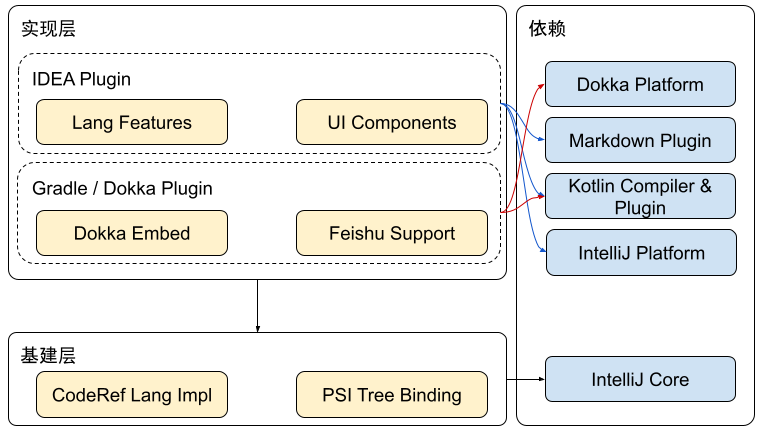
- 基建层
- IDEA Plugin
- Gradle / Dokka Plugin
通用逻辑(语言实现相关)封装在基建层,仅依赖 IntelliJ Core。相对于 IntelliJ Platform,IntelliJ Core 仅保留语言相关的能力,精简了 codeInsight、UI 组件等代码,被广泛用于 IntelliJ 各大产品中(包括图中的 Kotlin、Dokka 等)。
下面将针对这三个主要模块展开介绍。
基建
纵观整个方案,基建层是所有功能的基石,其最核心的能力是建立代码与文档关联。这里我们设计实现了一套标记语言 CodeRef,满足以下几个需求:
- 语法简洁,结构上与源码一一对应;
- 指向精准,即必须满足一对一的关系;
- 支持仅保留声明(去掉 body),提升信噪比;
- 有扩展性,方便后续迭代新功能;
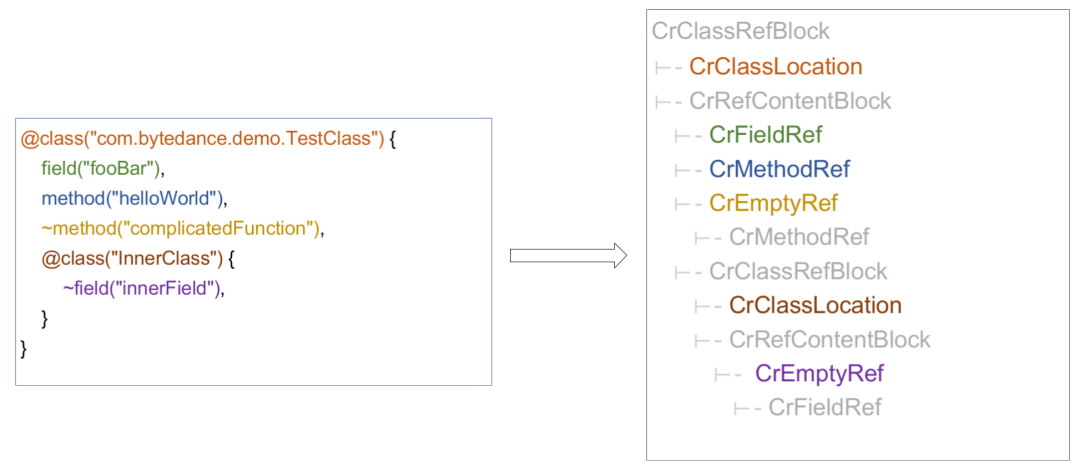
CodeRef 语言并不复杂,采用类似 Kotlin/Java 的风格,用关键字、字符串、括号构成语句和代码块,代码块中每个节点都有与之对应的源码节点。下图是一个简单的示例,对应关系用着色文字标识:

- 设计语法,编写语言实现;
- 结合现有能力(IntelliJ Core、Kotlin Plugin)获取双边语法树,从而建立文档节点到源码节点的单向对应关系;
- 结合现有能力(Markdown Parser)生成用于渲染的文档文本;
语言基础实现
基于 IntelliJ Platform,实现一个自定义语言起码要做以下几件事:
- 编写 BNF 定义,描述语法;
- 借助 Grammar Kit 生成
Parser、PsiElement接口、flex 定义等; - 基于生成的 flex 文件和 JFlex 生成
Lexer; - 编写 Mixin 类用
PsiTreeUtil等工具实现 PSI 中声明的自定义方法;
BNF 是后面一切的基础,每个定义、值的选择都至关重要。一小段示例:
{
/* ...一些必要的 Context */
tokens = [
/* ...一些 Token,转换为代码中的 IElementType */
AT='@'
CLASS='class'
]
/* ...一些规则 */
extends("class_ref_block|direct_ref|empty_ref") = ref
extends("package_location|class_location") = ref_location
extends("class_ref|method_ref|field_ref") = direct_ref
}
ref_location ::= package_location | class_location
package_location ::= AT package_def {
pin=2 // 只有 '@' 和 package_def 一起出现时,才把整个 element 视为 package_location
}
class_location ::= AT class_def {
pin=2 // 只有 '@' 和 class_def 一起出现时,才把整个 element 视为 class_location
}
direct_ref ::= class_ref | method_ref | field_ref | empty_ref {
methods = [ // 一些自定义的 method,需要在下面指定的 mixin class 中给出实现
getNameStringLiteral
getReferencedElement
getOptionalArgs
]
mixin="com.bytedance.lang.codeRef.psi.impl.CodeRefDirectRefMixin"
}
class_ref ::= CLASS L_PAREN string_literal [COMMA ref_args_element*] R_PAREN {
methods = [
property_value=""
]
pin=1 // 即遇到第一个元素 class 后,就将当前 element 匹配为 class_ref
}上面的小片段中定义了
@class("")、@package("")、class("", ...)语法。实战中比较关键的是pin和recoverWhile,前者影响一段“未完成”的代码的类型,后者控制一段规则何时结束。具体参考 Grammar-Kit。
编写完成后,我们就可以使用 Grammar-Kit 生成 Parser 和 Lexer 了,前者负责最基础的语法高亮,后者负责输出 PSI 树。将二者注册在自定义的 ParserDefinition,再结合自定义的 LanguageFileType,相应类型文件就会被 IDE 解析成由 PsiElement 构成的树。示意如图:
Formatter、CompletionContributor 等组件的实现受上述过程影响极大,实现不好必然面临返工。而偏偏这里面又有不少“坑”需要一一淌过,这部分限于篇幅没办法写得太细,有兴趣看看语言特性“相对简单”的 Fortran 的 BNF 定义感受一下。
语法树单向对应
考虑到 IDE 内置了对 Java、Kotlin 语言的支持,有了上一步的成果,我们就得到了两颗语法树,是时候把两棵树的节点关联起来了:
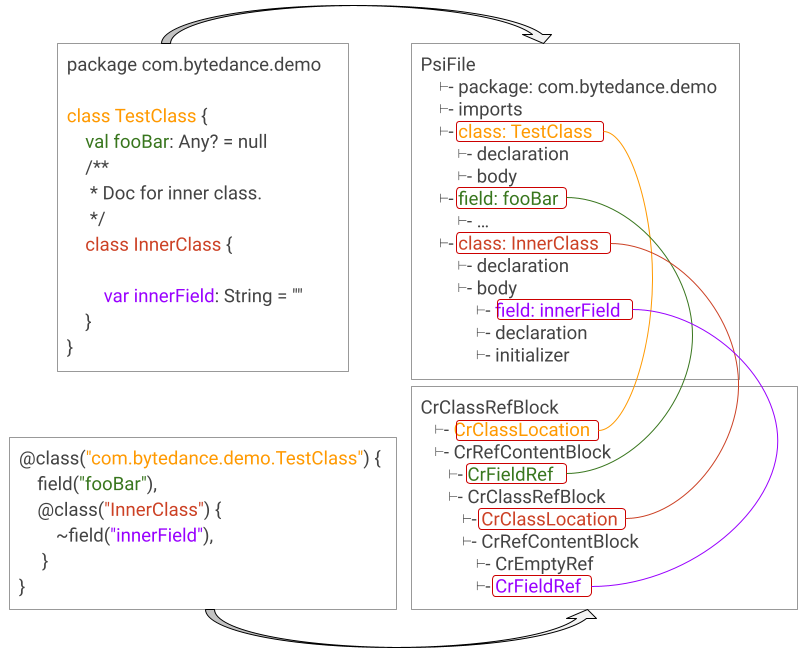
PsiReferenceContributor(官方文档) 注册 CrElement(即 CodeRef 语言 PsiElement 的基类)向源码 PsiElement 的引用,依据便是每行双引号内的内容(字符串)。如何找到每个字符串对应的元素呢?遵循以下三步:
- 除根节点外,每个节点需要向上递归找到每一级 parent 直至根节点;
- 根节点是给定 full-qualified-name 的 package 或 class,由上一步的结果可确定元素在该 package 或 class 中的位置;
- 通过
JavaPsiFacade和一系列查找方法确定源码中对应的PsiElement;> 注意:Kotlin Plugin 提供一套针对 Java 的 “Light”PsiElement实现,因此这里我们考虑 Java 即可。
生成文档文本
有了语法树对应关系,就可以生成用于预览的文本了。这部分比较常规,时刻注意读写环境,按照以下步骤实现即可:
- 为每个 CodeRef 语法树根节点指向的源码文件创建副本;
- 遍历该 CodeRef 树中每个 Ref 或 Location,创建或定位副本中对应位置,将源码文件中的元素(修饰后)复制到副本中;
- 导出副本字符串;> 考虑到 IDE 中 PSI 和文件是实时映射的,为不影响原文件内容,必须在副本环境中进行语法树的增删改。
这部分虽然难度不大,繁琐程度却是最高的。一方面,由于要深入到细节,使得前文提到的 Kotlin Light PSI 不再适用,因此必须针对 Java 和 Kotlin 分别编写实现。另一方面,如何保证复制后的代码格式仍是正确的也是个大问题,尤其是涉及元素之间穿插注释的情况。最后,文本内容生成的工作在不停的断点、调试的循环中玄学般地完成了。
至此,基建层的任务——将 CodeRef 还原成代码段——便全部完成了。
IDEA Plugin
有了前面的基础,IDEA Plugin 主要负责把方案的本地使用体验做到可用、易用。具体来说,插件的功能分为两类:
- 面向 CodeRef,丰富语言功能;
- 面向 Markdown,提升编辑、阅读体验;
接下来分别从以上角度介绍。
语言优化
对于一门“新语言”,从体验层面来看,PSI 的完成只是第一步,自动补全、关键字高亮、格式化等功能对可用性的影响也是决定性的。尤其是在 CodeRef 的语法下,指望用户能不依赖提示手动输入正确的包名、类名、方法名,无疑过于硬核了。下面挑几个有意思的展开说说。
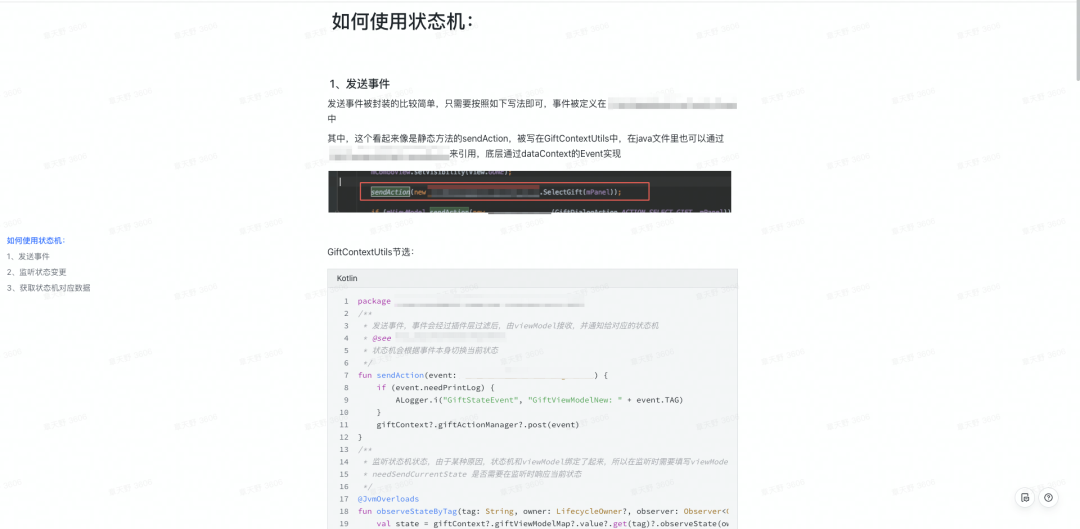
代码补全
在 IDEA 中,大部分(不太复杂的)代码补全使用 Pattern 模式注册。所谓 Pattern 相当于一个 Filter,在当前光标位置满足该 Pattern 时就会触发对应的 CompletionContributor。
我们可以使用 PlatformPatterns 的若干内置方法描述一个 Pattern。比如一段 CodeRef 代码:method("helloWorld"),其 PSI 树长这样子:
- CrMethodRef // text: method("helloWorld")
- CrStringLiteral // text: "helloWorld"
- LeafPsiElement // text: helloWorldPattern 因此为:
val pattern = PlatformPatterns.psiElement()
.withParent(CrStringLiteral::class.java)
.withSuperParent(2, CrMethodRef::class.java)对应每个 Pattern,我们需要实现一个 CompletionProvider 给出补全信息,比如一个固定返回关键字补全的 Provider:
val keywords = setOf("package", "class", "lang")
class KeywordCompletionProvider : CompletionProvider<CompletionParameters>() {
override fun addCompletions(
parameters: CompletionParameters,
context: ProcessingContext,
result: CompletionResultSet
) {
keywords.forEach { keyword ->
if (result.prefixMatcher.prefixMatches(keyword)) {
// 添加一个 LookupElementBuilder,可以指定简单的样式
result.addElement(LookupElementBuilder.create(keyword).bold())
}
}
}
}掌握上述技能,诸如 class、package、method 等关键字,乃至方法名和字段名的补全就都很容易实现了。
比较 trick 的是包名和带有包名的类名的补全,它们形如
a.b.c.DEF。不同的是,每次输入 '.' 都会触发一次补全,而且要求在字符串开头直接输入“DE”也能正确联想并补全。限于篇幅不展开介绍了,详见com.intellij.codeInsight.completion.JavaClassNameCompletionContributor的实现。
格式化
格式化这件事上,IDEA 并没有直接使用 PSI 或者 ASTNode,而是基于二者建立了一套“Block”体系。所有缩进、间距的调整都是以 Block 为最小粒度进行的(一些复杂语言拆的太细,这样设计可以很好地降低实现复杂度,妙啊)。
这里的概念也不多,列举如下:
- ASTBlock:我们用现有的 ASTNode 树构建 Block,因此继承此基类;
- Indent:控制每行的缩进;
- Spacing:控制每个 Block 之间的间距策略(最小、最大空格,是否强制换行 / 不换行等);
- Wrap:单行长度过长时的折行策略;
- Alignment:自己在 Parent Block 中的对齐方向;
实际敲代码时,大部分时间花在 getSpacing 方法上,写出来效果类似这样:
override fun getSpacing(child1: Block?, child2: Block): Spacing? {
/*...*/
return when {
// between ',' and ref
node1?.elementType == CodeRefElementTypes.COMMA && psi2 is CrRef ->
Spacing.createSpacing(/*minSpaces*/0, /*maxSpaces*/0, /*minLineFeeds*/1, /*keepLineBreaks*/true, /*keepBlankLines*/1)
// between '[', literal, ']'
node1?.elementType == CodeRefElementTypes.L_BRACKET && psi2 is CrStringLiteral ||
psi1 is CrStringLiteral && node2?.elementType == CodeRefElementTypes.R_BRACKET ->
Spacing.createSpacing(/*minSpaces*/0, /*maxSpaces*/0, /*minLineFeeds*/0, /*keepLineBreaks*/false, /*keepBlankLines*/0)
}
}格式化属于说起来很简单,实现起来很头痛的东西。实操过程中,被迫把前面写好的 BNF 做了一波不小的调整,才达到理想效果。好在我们的语言比较简陋简洁,没踩到什么大坑,如果面向更复杂的语言,工作量将是指数级提升(参考
com.intellij.psi.formatter.java包下的代码量)。
MarkdownX
上面罗列这么多内容,说白了只是对 Markdown 中代码块的增强方案,接下来 CodeRef 和 Markdown 终于要合体了。
实际上官方一直有对 Markdown 的支持(IDEA 内置,AS 可选安装),包含一整套语言实现和编辑器、预览器。这里重点说说其预览的生成流程,如图:
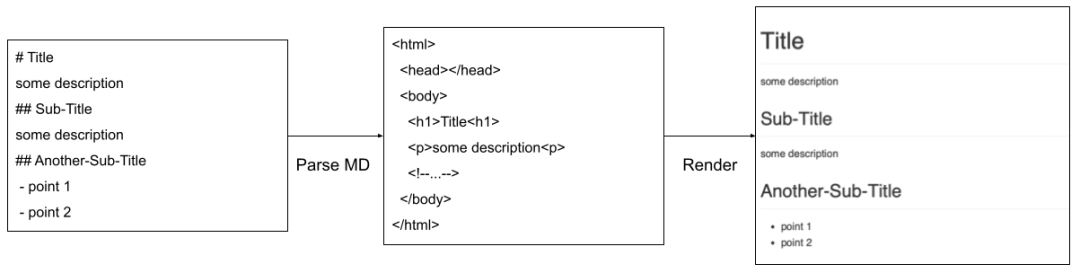
org.jetbrains:markdown 依赖中,未开源):
- 利用
MarkdownParser将文本解析成若干 ASTNode; - 利用
HtmlGenerator内置的 visitor 访问每个 ASTNode 生成 HTML 文本; - 将生成的 HTML Document 设置给内置浏览器(如果有),最终呈现在屏幕上;
交代个背景:在本项目启动之初,IDEA 正处于 JavaFX-WebView 到 JCEF 的过渡期(直接导致了 AndroidStudio 4.0 左右的版本没有可用的内置 WebView 实现)。
上述方案总结有以下问题:
- 兼容性较差,部分 IDE 版本无法看到预览;
- 每次 MD 的变更都会触发全量 generateHtml,如果文档内容复杂度较高,将有性能瓶颈;
- 将 HTML 文本 set 给浏览器时没有 diff 逻辑,会触发页面 reload,同样可能导致性能问题(后来针对带有 JCEF 的 IDE 增加了 diff 能力,但并不是所有 IDE 都内置 JCEF);
综合考虑下,我们决定不直接使用原生插件,而是基于其创建新的语言“MarkdownX”,最大程度复用原本的能力,追加对 CodeRef 的支持,同时基于 Swing 自制一套类似 RecyclerView 的机制改善预览性能。
优化后的方案流程类似这样:

- 内存占用更低(浏览器 vs. JComponent)
- 性能更佳(局部刷新、控件复用等)
- 体验更佳(浏览器内置对``标签的支持过于基础,无法实现代码高亮、引用跳转等功能,原生控件不存在这些限制)
- 兼容性更佳(不解释)
CodeRef 支持
MarkdownX 只是表现为“新语言”,实现上依然复用 MarkdownParser 和 HtmlGenerator,主要区别只有文件扩展名和对 code-fence 的处理。
所谓 code-fence,即 Markdown 中使用 「```」 符号包裹的代码块。不同于原生实现,我们需要在生成预览时替换代码块的内容,并使内容随代码变化而变化。
实操上,我们需要实现一个 org.intellij.markdown.html.GeneratingProvider,简写如下:
class MarkDownXCodeFenceGeneratingProvider : GeneratingProvider {
override fun processNode(visitor: HtmlGenerator.HtmlGeneratingVisitor, text: String, node: ASTNode) {
visitor.consumeHtml("<pre>")
var state = 0 // 用于后面遍历 children 的时候暂存状态
/* ...一些变量定义 */
for(child in childrenToConsider) {
if (state == 1 && child.type in listOf(MarkdownTokenTypes.CODE_FENCE_CONTENT, MarkdownTokenTypes.EOL)) {
/* ...拼接每行内容 */
}
if (state == 0 && child.type == MarkdownTokenTypes.FENCE_LANG) {
/* ...记录当前 code-fence 的语言 */
applicablePlugin = firstApplicablePlugin(language) // 找到可以处理当前语言的“插件”
}
if (state == 0 && child.type == MarkdownTokenTypes.EOL) {
/* ...进入代码段,设置状态 */
state = 1
}
}
if (state == 1) {
visitor.consumeTagOpen(node, "code", *attributes.toTypedArray())
if (language != null && applicablePlugin != null) {
/* ...命中自定义处理逻辑(即 CodeRef)*/
visitor.consumeHtml(content) // 即由自定义逻辑生成的 Html
} else {
visitor.consumeHtml(codeFenceContent) // 默认内容
}
}
/* ...一些收尾 */
}
}可以看到,在遍历 node 的 children 后,就可以确定当前代码段的语言。如果语言为 CodeRef,就会走到前文提到的“预览文本生成”逻辑中,最后通过 visitor(相当于一个 HTML Builder)将自定义的内容拼接到 Html 中。
预览性能优化
考虑到 JList 并没有“item 回收”能力,在 List 实现上我们选择直接使用 Box。处理流程如下图:
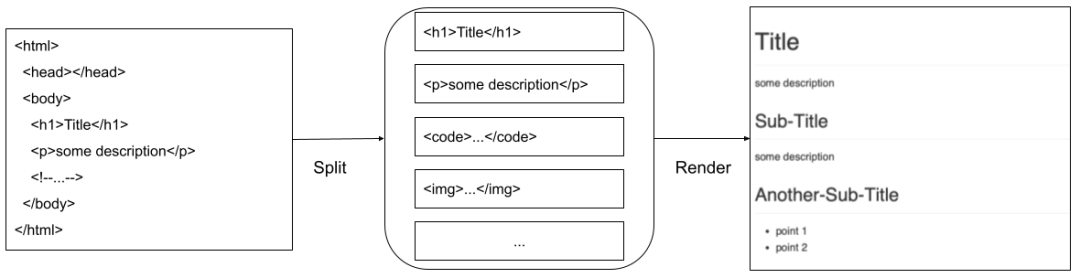
- Data 层将 HTML 的 body 拆分成若干部分,diff 后将变更通知给 View 层;
- View 层将变更的数据设置到 List 对应位置上,并尽可能复用已有的
ViewHolder。过程可能涉及ViewHolder的创建和删除;
目前我们针对文本、图片和代码创建了三种 ViewHolder:
- 文本:使用
JTextPane配合 HTML + CSS 完成文字样式的还原; - 图片:自定义
JComponent进行缩放、绘制,保证图片居中且完整展示; - 代码:以 IDE 提供的
Editor作为基础,进行必要的设置与逻辑精简;
这里对 Editor 的处理花费了大量精力:
- 使用原代码文件作为 context 创建
PsiCodeFragment作为内容填充Editor,以保证代码中对原文件 import 过的类、方法、字段可被正常 resolve(这点很重要,如果用 Mock 的Document作为内容,绝大部分代码高亮和跳转都是不生效的); - 设置合适的
HighlightingFilter,确保“没有报红”(将原文件作为 context 的代价是,当前代码片段的类极有可能被认为是类重复,并且代码结构也不一定合法,因此需要禁用“报红”级别的代码分析); - 禁用
Intention,设置只读(提升性能,降低干扰); - 禁用
Inspection和ExternalAnnotator;(两者是性能消耗的大户,后者包括 Android Lint 相关逻辑)
经过上述优化,实测大部分情况下预览都可以流畅展示 & 刷新了。但如果同时打开多个文档,或者“操作速度惊人”,还是会时不时出现长时间卡顿。分析一波发现,性能消耗主要出在 HTML 生成上。
由于 Markdown 语法限制(节点深度低),常规的 MD 转 HTML 性能开销有限。但回顾上文,我们对 codeRef 的处理会伴随大量 PSI resolve,复杂度暴涨,频繁的全量 generate 就不那么合适了。一个很自然的想法是为每段 codeRef 添加缓存,内容不变时直接使用缓存的内容。这样在修改文字段落时可以完全避开其他文件的语法解析,修改 codeRef 段落时也仅会刷新当前代码块的内容。
那么问题来了:若用户修改的不是文档文件,而是被引用的代码,则在缓存的作用下,预览并不会立刻改变。那么更进一步,如果向所引用的所有文件注册监听,在变更时刷新缓存,问题可否得解呢?事实上,这样做问题确实解决了,但引入了新的问题:如何释放文件监听?
此处插入背景:对
code-fence内容的干预是基于 Visitor 模式回调完成的,因此作为 generator 本身是不知道本次处理的代码块与前一次、后一次回调是否由同一个变更引起。举个例子:一个文档中有 A、B、C 三个codeRef块,则在一次 HTML 生成过程中,generator 会收到三次回调,且没有任何手段可以得知这三次回调的关联性。
目前,我们只能在一次 HTML 生成前后通知 generator,在 generator 内部维护一个队列 + 计数器,不那么优雅地解决泄漏问题。
至此,插件的整体性能表现终于落到可接受范围内。
Gradle / Dokka Plugin
为了让受众更广、内容随时可读,把文档做到可导出、可自动化部署是非常必要的。方案上,我们选用同为 IntelliJ 出品的 Dokka 作为基础框架,利用其完善的数据流变换能力,高效地适配多输出格式的场景。
Dokka 流程扩展
Dokka 作为同时兼容 Kotlin 和 Java 的文档框架,“数据流水线”的思想和极强的可扩展性是其特点。代码转换到文档页面的流程如下:

每个节点都有至少一个 Extension Point,扩展起来非常灵活。
图中几个主要角色列举如下:
- Env:包含基于 Kotlin Compiler 和 IntelliJ-Core 扩展的代码分析器(用于输出 Document Models)、开发者自定义的插件等组件;
- Document Models:对 module、package、class、function、fields 等元素的抽象,呈树形组织,本质是一些 data class;
- Page Models:由
PageCreator以 Document Models 为输入,创建的一系列对象,是对“页面”的封装,描述“页面”的结构; - Renderer:用于将 Page Models 渲染成某种格式的产物(Dokka 内置的有 HTML、Markdown 等);
从上述内容可以看出,Dokka 原本的作用只是将代码转换为文档页面,并不原生支持转换文档文件(也确实没必要)。但在我们的场景下,MarkdownX 的渲染是依赖源码信息的,也就正好能用到 Dokka 的这部分能力。
通过重写 PageCreator,我们将含有 MarkdownX 文档的工程变成类似这样的节点树:
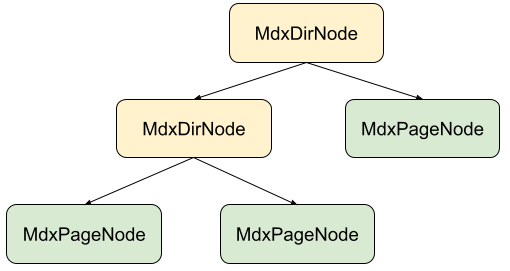
- MdxDirNode 对应文件夹节点,页面内容是当前文件夹的目录,点击链接可跳转至下一级;
- MdxPageNode 对应 MarkdownX 文档内容,包含若干类型的 children 分别代表不同类型的内容片段;
在创建 MdxPageNode 时,我们用类似前文 IDEA-Plugin 的做法,重写一个 org.jetbrains.dokka.base.parsers.Parser 并修改对 code-fence 的处理,改为调用到「基建」部分中生成 CodeRef 预览文本的代码,最终得到所需的文档文本。
飞书适配
得到页面内容后,结合 Dokka 自带的 HtmlRenderer,输出一份可用于部署的 HTML 产物就轻而易举了。但现状是,我们更希望能把文档收敛在飞书上,这就需要再编写一份针对飞书的自定义 Renderer。
考虑到自己处理页面的树形结构过于复杂,实际上我们基于内置的 DefaultRenderer 基类进行扩展:
abstract class DefaultRenderer<T>(
protected val context: DokkaContext
) : Renderer {
abstract fun T.buildHeader(level: Int, node: ContentHeader, content: T.() -> Unit)
abstract fun T.buildLink(address: String, content: T.() -> Unit)
abstract fun T.buildList(
node: ContentList,
pageContext: ContentPage,
sourceSetRestriction: Set<DisplaySourceSet>? = null
)
abstract fun T.buildNewLine()
abstract fun T.buildResource(node: ContentEmbeddedResource, pageContext: ContentPage)
abstract fun T.buildTable(
node: ContentTable,
pageContext: ContentPage,
sourceSetRestriction: Set<DisplaySourceSet>? = null
)
abstract fun T.buildText(textNode: ContentText)
abstract fun T.buildNavigation(page: PageNode)
abstract fun buildPage(page: ContentPage, content: (T, ContentPage) -> Unit): String
abstract fun buildError(node: ContentNode)
}上面只列出一部分了回调方法。
可以看到,该类的接口方式比较新颖:用 Visitor 的方式遍历页面节点树,再提供一系列 Builder/DSL 风格的待实现方法给开发者。对于这些 abstract function,内置的 HtmlRenderer 采用 kotlinx.html(一个 DSL 风格的 HTML 构建器)实现,这意味着我们也要实现一套 DSL 风格的飞书文档构建器。
飞书开放平台文档查看链接:https://open.feishu.cn/document/home/index。
DSL 的部分就不详述了,这里主要说说飞书的文档结构。众所周知,Markdown 在设计之初就是面向 Web 的,因此与 HTML 天生具有互转的能力。然而飞书文档的数据结构相对更像 Pdf、Docx 这类文件,拥有有限层级,相对扁平。举个例子,同样的文档内容,MdxPageNode 中结构长这样:
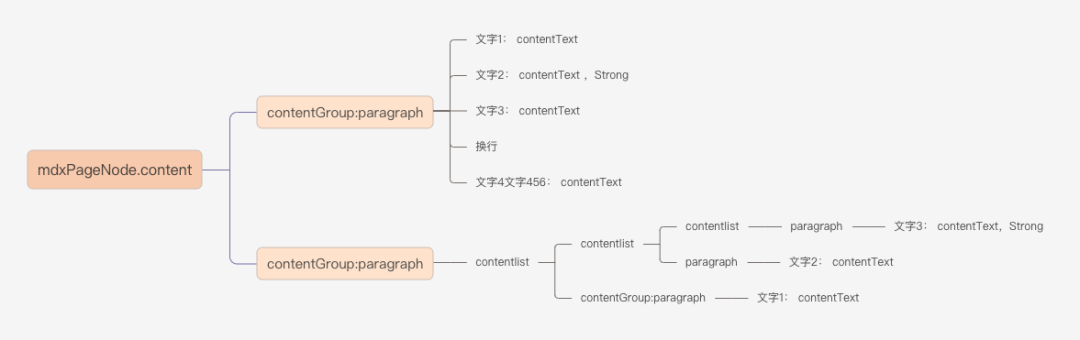
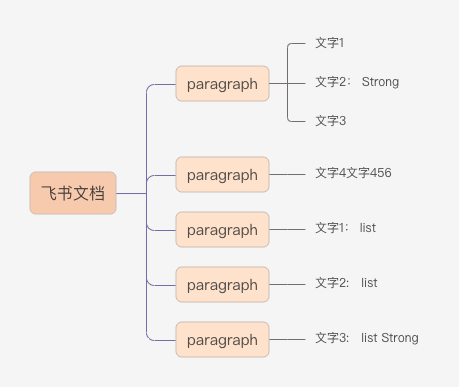
FeishuRenderer,具体做法只能 case by case 介绍,限于篇幅就不展开了,大体思路就是对不兼容的节点进行展开或合并,穿插必要的子树遍历。
下面提两个特殊点的处理:图片和链接。
文档链接
写 Markdown 文档时,往往需要插入链接,指向其他的 Markdown 文档(一般使用相对路径)。这时,我们需要想办法把相对路径映射成飞书链接,而且需要在 Render 步骤之后进行,因为映射的时候需要知道对应文档的飞书链接是什么。
第一反应肯定就是对文档做拓扑排序了,按照依赖关系一个个上传文档。但这样需要文档间没有循环依赖,显然这是不能保证的(两篇文档相互引用还蛮常见的)。幸好,飞书文档提供了修改文档的接口,因此我们可以提前创建一批空文档,获取到空文档的链接后,再做相对路径的替换。换句话说,处理文档上传流程为:创建空文档-> 替换相对路径为对应文档链接 -> 修改文档内容。
图片
图片在 Markdown 中可以和文本并列,属于 Paragraph 的一种。而飞书文档结构中,图片属于 Gallery,只能独占一行,无法和文字同行。两种格式从实现上无法完全兼容。当前初步实现方案是在 Paragraph 的 Group 入口向下 DFS,找到所有图片,单提出来放在文本前面。效果嘛,只能忍忍了。
顺便一提,图片也需要上传并替换的逻辑,这部分与文档链接相似,不赘述了。
结语
以上就是文档套件的全部内容:我们基于 IntelliJ 技术栈,通过设计新语言、编写 IDE 插件、Gradle / Dokka 插件,形成一套完整的文档辅助解决方案,有效建立了文档与代码的关联性,大幅提升编写、阅读体验。
未来,我们会为框架引入更多实用性改进,包括:
- 添加图形化的代码元素选择器,降低语言学习、使用成本;
- 优化预览渲染效果,对齐 WebView;
- 探索针对部分框架(Dagger、Retrofit 等)的文档自动生成能力;
目前框架尚处内测阶段,正逐步扩大范围推广。待方案成熟、功能稳定后,我们会将方案整体开源,以服务更多用户,同时吸取来自社区的 Idea,敬请期待!