了解Linux的I/O模型
I/O是input/output的缩写,表示计算机与外接设备之间的数据传输。最常见的I/O类型有磁盘I/O、网络IO。IO和CPU比起来是非常低效的,为了保障应用程序的运行效率,Linux支持多种IO模型。
I/O模型是面试中经常被问到到技术点,也是软件开发过程中经常需要处理到问题。本文主要分析Linux操作系统中I/O模型的分类及各自的特点。我们主要以网络IO为例来分析。
在Linux中常见的I/O模型有:阻塞I/O、非阻塞I/O、多路复用I/O、信号驱动I/O和异步I/O。
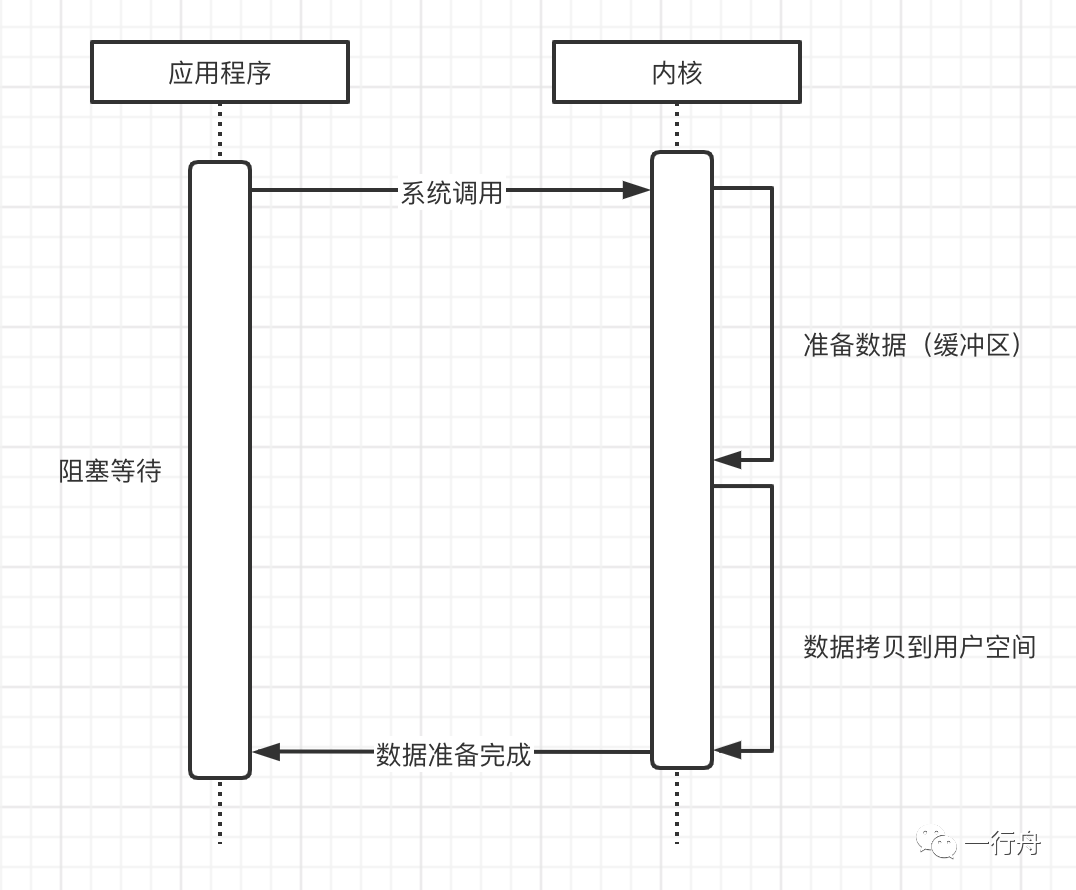
阻塞IO
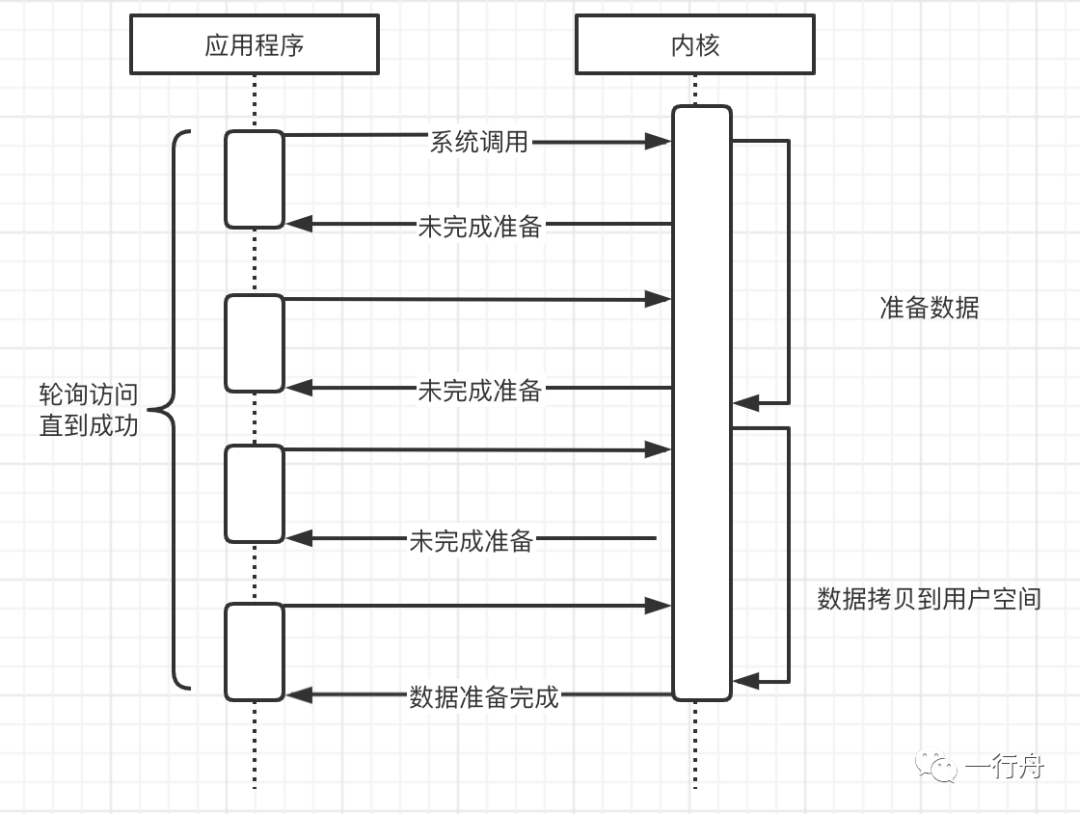
非阻塞IO
和阻塞IO相反,应用程序发起请求之后内核态会立刻返回未准备完成的状态给应用程序(不会一直等待数据复制完成)。应用程序通过轮询访问数据,直到数据返回。
多路复用IO
在并发环境下,一秒钟可能有成千上万的请求发送到服务器,不管是堵塞IO还是非堵塞IO模型都需要创建非常多的进程去处理请求。但是创建进程成本巨大,而且跨进程的数据交换也相对复杂。这就诞生了IO复用技术,一个进程就可以服务多个客户端。Linux中实现IO多路复用有三种方式:select、pool、epool。

- 调用select函数后,需要对所有文件描述符循环监听。
- 每次调用select函数都需要传递监视对象信息。 epool函数刚好解决了select的两大问题,性能较好。(1G的内存能监听接近10万个端口号)
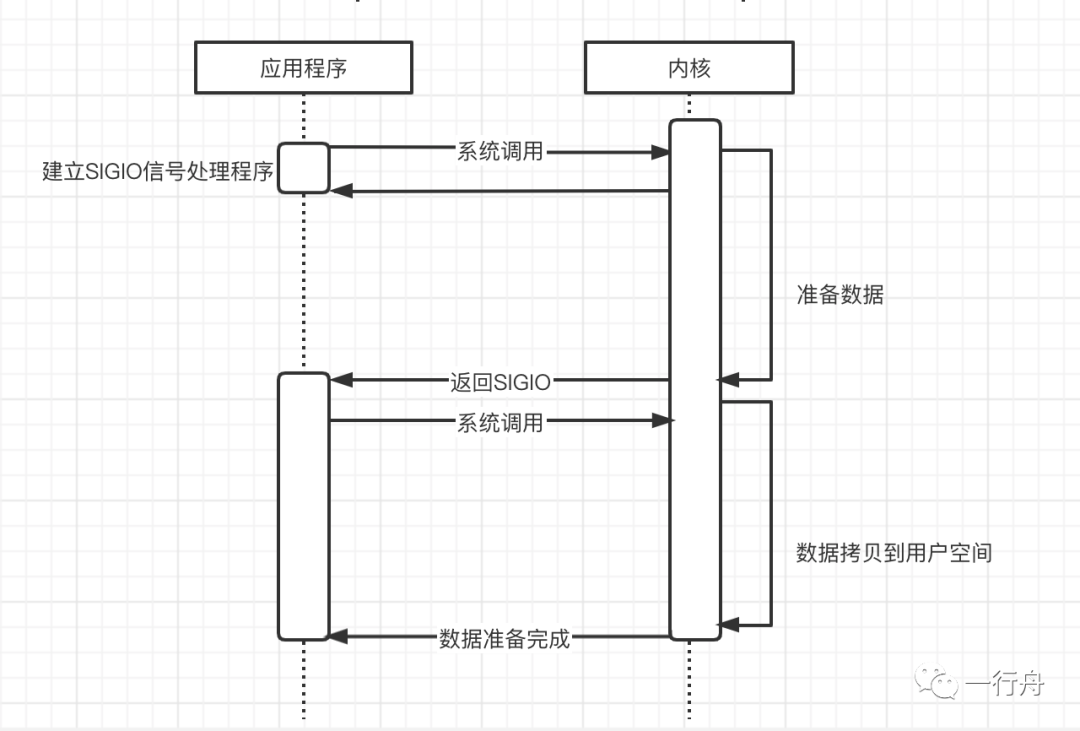
信号驱动IO
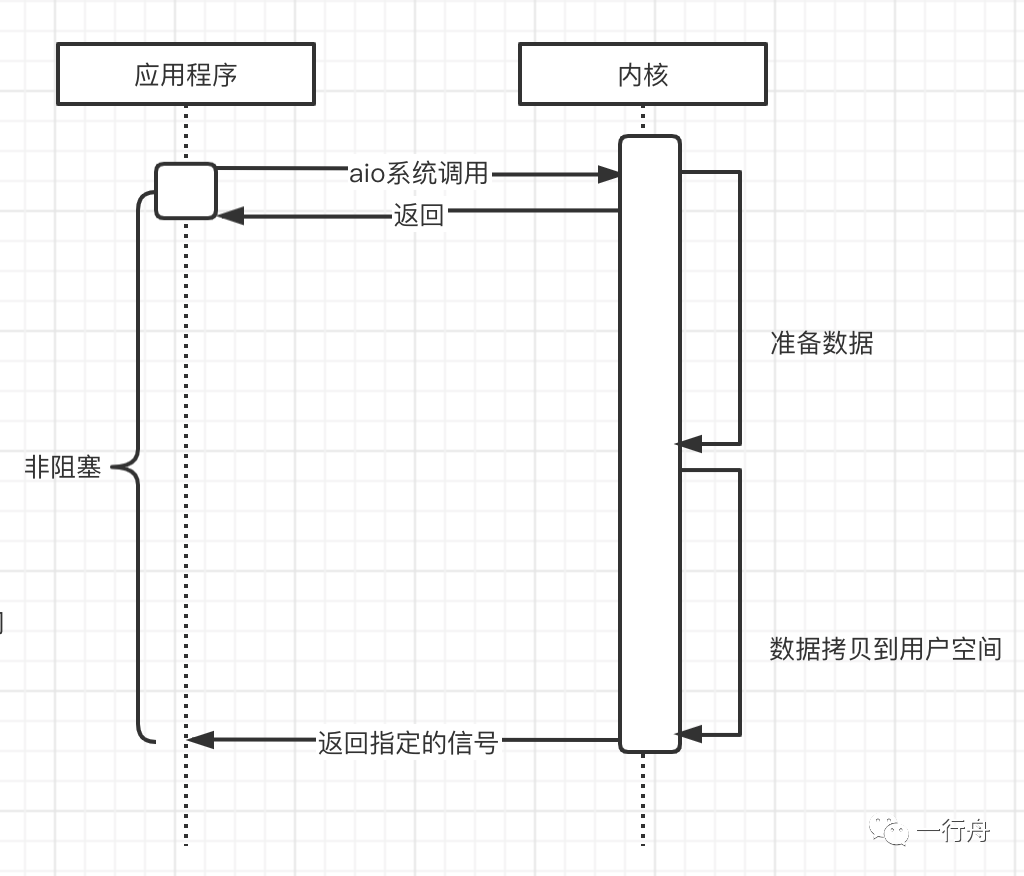
异步IO
参考资料:《TCP/IP网络编程》