为什么 Eslint 可以检查和修复格式问题,而 Babel 不可以?
Eslint 可以检查出代码中的错误和一些格式问题,并能自动修复,它的实现原理就是基于 AST (抽象语法树)。
通过 Parser 把源码解析成 AST 对象树,源码字符串中的各种信息就被保存到了这个对象树里,然后遍历 AST,对每一部分做检查就能实现 Lint 的功能,而自动 fix 的功能则是基于字符串替换实现的,指定某一段 range,替换成另一段文本即可。
说起来,Babel 也是基于 AST 实现的代码分析和转换,但是却不能检查和修复格式的问题,这是为什么呢?为什么 Eslint 可以检查格式而 Babel 不可以呢?
我们先写一个 Eslint 的 rule 来感受下 Eslint 是怎么检查和修复格式问题的。
Eslint 检查格式的 rule
大括号有两种主流写法,一种是同一行写:
if (name === 'guang') {
}另一种是新开一行写:
if (name === 'guang')
{
}我们写一个 eslint 的 rule 来检查大括号的格式并自动修复成同一行的格式。
思路分析
Eslint 的检查是基于 AST,我们要检查的 AST 是块语句 BlockStatement。
关于什么代码是什么 AST 可以用 astexplorer.net 可视化的查看,parser 选择 espree (Eslint 默认的 parser):
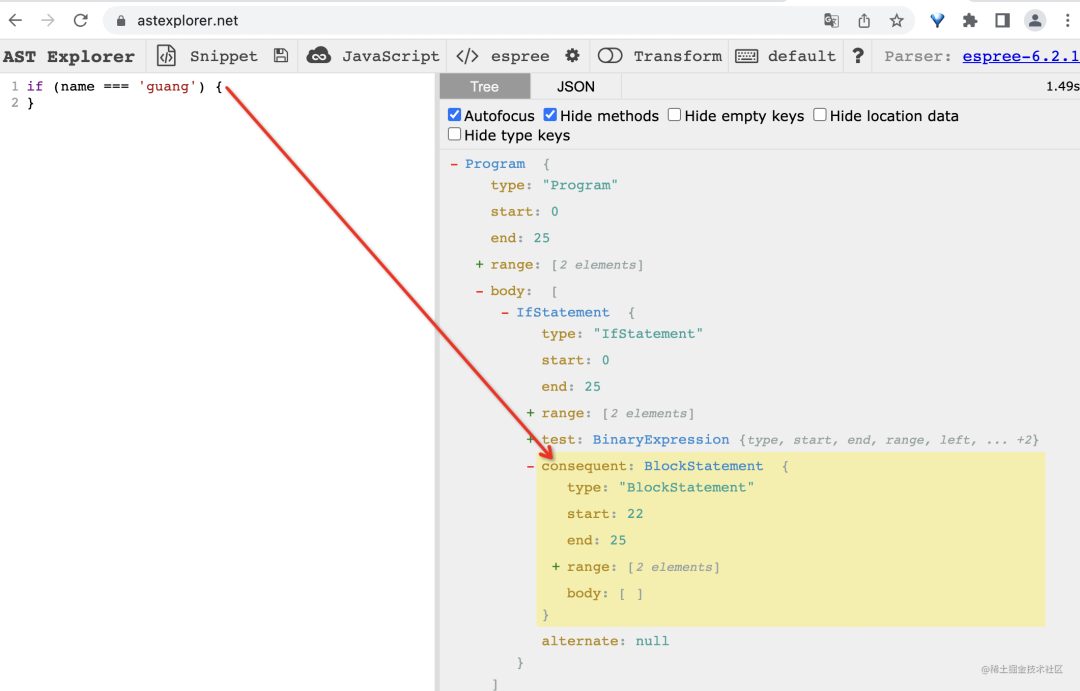
{ 的行号,是不是和它前一个 token 在同一行。(token 是指最小的不可再细分的单词,比如关键字、变量名等标识符、各种分隔符等)
如果是同一行,则说明了是符合规范的。当然我们还可以进一步检查一下大括号 { 和前一个 token 之间有没有空格。
思路理清了,我们来写下代码:
代码实现
Eslint 的 rule 的格式是这样的:
module.exports = {
meta: {
docs: {
description: "enforce consistent brace style for blocks"
},
fixable: true
},
create(context) {
return {
BlockStatement(node) {
}
}
}
};分为 meta 和 create 两部分:
- meta:描述各种元信息,比如文档描述、是否可自动修复等
- create:实现对各种 AST 检查的代码,rule 的主体部分
我们在 create 里声明了对 BlockStatement 节点的检查,它的参数就是对应的节点对象。
但是我们要检查的是 token,这个用 context 里的一个 api:
create(context) {
const sourceCode = context.getSourceCode();
return {
BlockStatement(node) {
const firstToken = sourceCode.getFirstToken(node);
const beforFirstToken = sourceCode.getTokenBefore(node);
}
}
}我们从 context 中拿到了 sourceCode 的 api,它就是用来取 token 的。
我们用 getFirstToken 拿到了当前 node 的开始 token,也就是 {,
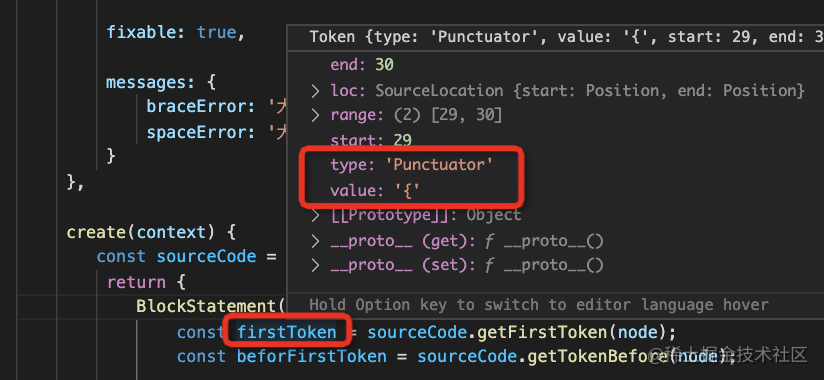
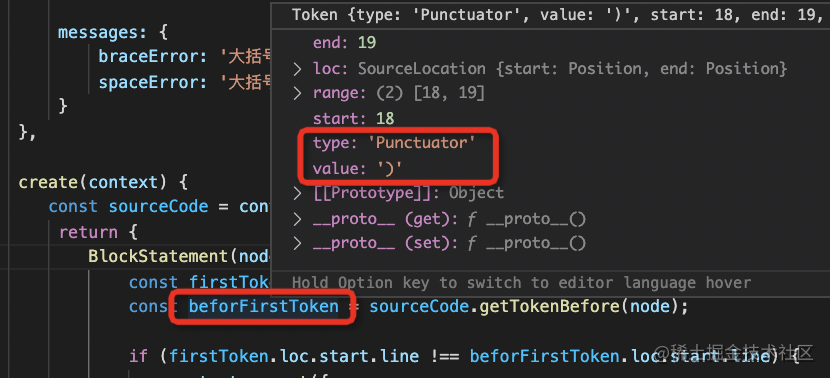
如果 { 所在的行和 ) 所在的行不是同一行,就报错
if (firstToken.loc.start.line !== beforFirstToken.loc.start.line) {
context.report({
node,
loc: firstToken.loc,
message: '大括号格式不对'
});
} 修复的方式自然就是把 { 和 ) 之间的部分替换成一个空格,这个使用 fixer 提供的 api:replaceTextRange:
if (firstToken.loc.start.line !== beforFirstToken.loc.start.line) {
context.report({
node,
loc: firstToken.loc,
message: '大括号格式不对'
fix: fixer => {
return fixer.replaceTextRange([beforFirstToken.range[1], firstToken.range[0]], ' ');
}
});
} 同理,也可以检查出 { 和 ) 之间没有空格的格式错误,修复方式一样:
if (firstToken.loc.start.column === beforFirstToken.loc.start.column + 1){
context.report({
node,
loc: firstToken.loc,
message: '大括号前缺少空格',
fix: fixer => {
return fixer.replaceTextRange([beforFirstToken.range[1], firstToken.range[0]], ' ');
}
});
}这样就实现了大括号格式的检查和自动修复。
我们来试下效果:
测试 rule
Eslint 除了提供命令行外,也提供了 api,我们调用它的 api 来测试 rule:
先创建 ESLint 对象,指定 rulePaths 也就是查找 rule 的目录为当前目录:
const { ESLint } = require("eslint");
const engine = new ESLint({
fix: false,
overrideConfig: {
parserOptions: {
ecmaVersion: 6,
},
rules: {
'my-brace-style': ['error']
}
},
rulePaths: [__dirname],
useEslintrc: false
});useEslintrc 为 false 是不查找配置文件, fix 为 false 是不自动修复。
然后调用它的 lintText 代码来测试,返回的结果使用 formatter 打印:
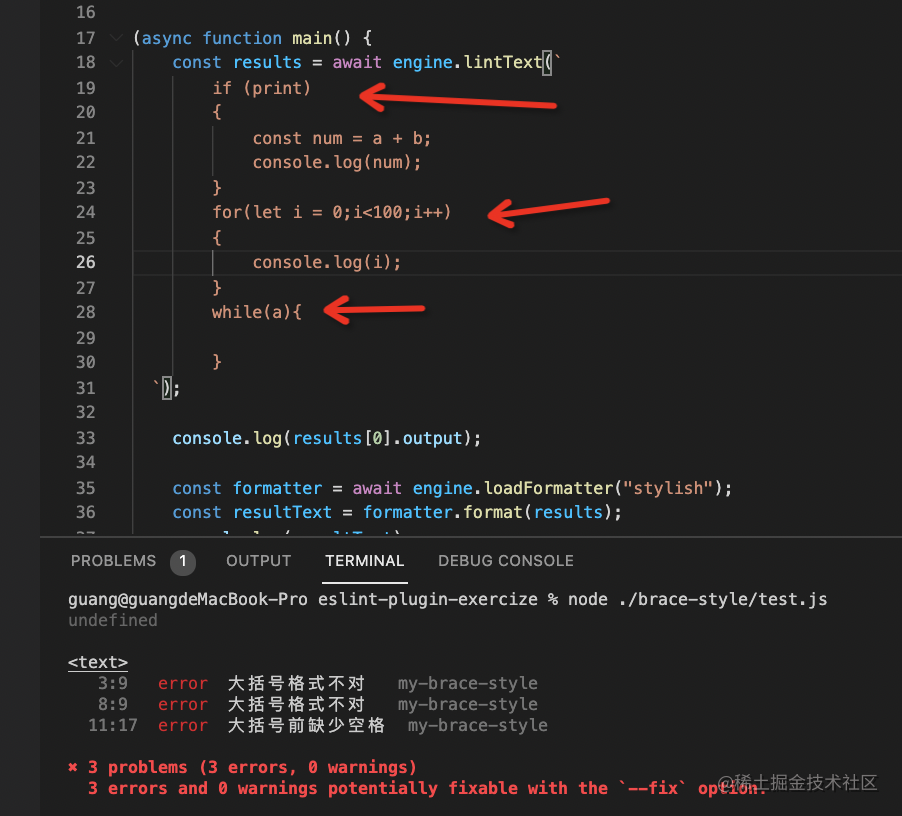
(async function main() {
const results = await engine.lintText(`
if (print)
{
const num = a + b;
console.log(num);
}
for(let i = 0;i<100;i++)
{
console.log(i);
}
`);
console.log(results[0].output);
const formatter = await engine.loadFormatter("stylish");
const resultText = formatter.format(results);
console.log(resultText);
})();我们来试一下效果:
然后把 fix 设为 true,来测试下自动修复:
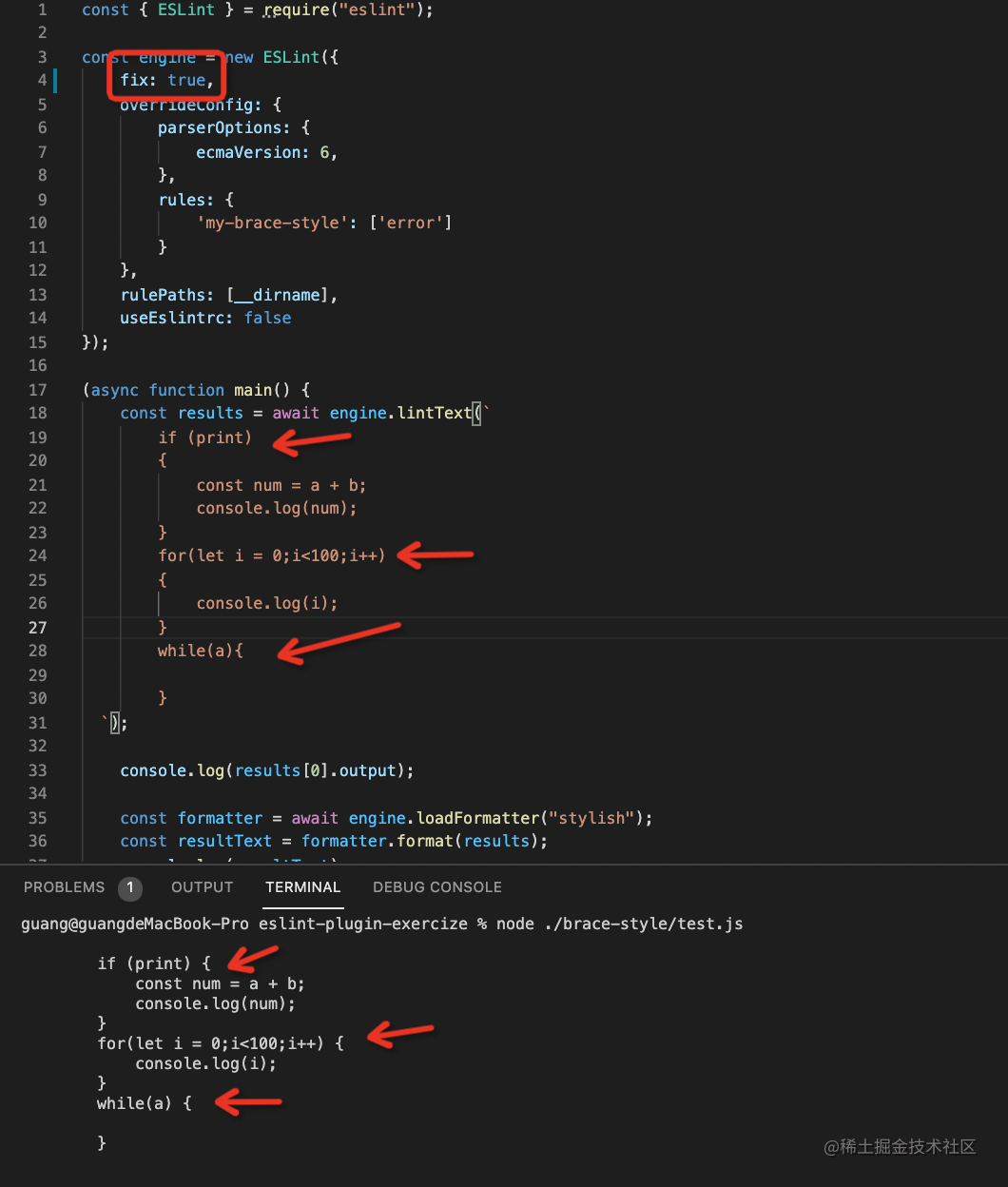
这样我们就通过 Eslint 的 rule 实现了代码格式的检查和自动修复。
代码上传到了 github:https://github.com/QuarkGluonPlasma/eslint-plugin-exercize
那么再回到最开始的问题,为什么 Eslint 可以检查代码格式,而 Babel 不可以呢?
为什么 Eslint 可以检查格式 Babel 不可以
我们写了一个检查大括号格式的 rule,可以发现能够做格式检查关键是能找到关联的 token。
Eslint 的 AST 记录了所有的 token,token 中有行列号信息,而且 AST 中也保存了 range,也就是当前节点的开始结束位置。并且还提供了 SourceCode 的 api 可以根据 range 去查询 token。这是它能实现格式检查的原因。
而 Babel 其实也支持 range 和 token,但是却没有提供根据 range 查询 token 的 api,这是它不能做格式检查的原因。
其实 Babel 和 Eslint 原理差不多,但是 Eslint 是被设计来做代码错误和格式检查与修复的,而 Babel 是被设计用来做代码分析和转换的,目的不同,所以也就提供了不同的 api,能够做不同的事情。
总结
Eslint 是用来检查代码中的错误和格式问题的,基于 AST,Babel 也是基于 AST 做的代码分析和转换,但是却不能检查格式。
为了探究原因,我们写了一个 EsLint 的检查大括号格式的 rule,通过 SourceCode 的 api 拿到 { 和 ) 的 token,对比下行列号来做检查。并且通过 fixer 的字符串替换做了自动修复。
写完之后,我们发现 EsLint 能做格式检查的原因是因为 AST 中记录了 range,也保留了 token信息,并且提供了根据 range 查询 token 的 api,而 Babel 没有。
EsLint 和 Babel 原理大同小异,但是有不同的设计目的,所以提供了不同的 api,有着不同的功能。