使用 VideoToolbox 探索低延迟视频编码
本文讲述通过 VideoToolbox 最新功能实现低延迟 H.264 硬件编码,最大限度地减少端到端的延迟,并提高性能,实现最佳的实时通信和高质量的视频播放。
知识目录:
- 视频工具箱和硬件加速 - ObjC 中国[1]:详细介绍了 VideoToolbox。
- WWDC20 10090 - 使用 AVFoundation 和 VideoToolBox 做视频处理 - 小专栏[2]:详细介绍了视频解码整个过程及其相关概念。
- H264 Encode And Decode Using VideoToolBox - Mobisoft Infotech[3]:详细介绍了 VideoToolbox 的具体使用。
当然,由于 VideoToolbox 是直接对视频进行编解码,如果要详细配置各个参数,各种支持的视频格式编解码细节也要有一定的了解。
低延迟编码的目标
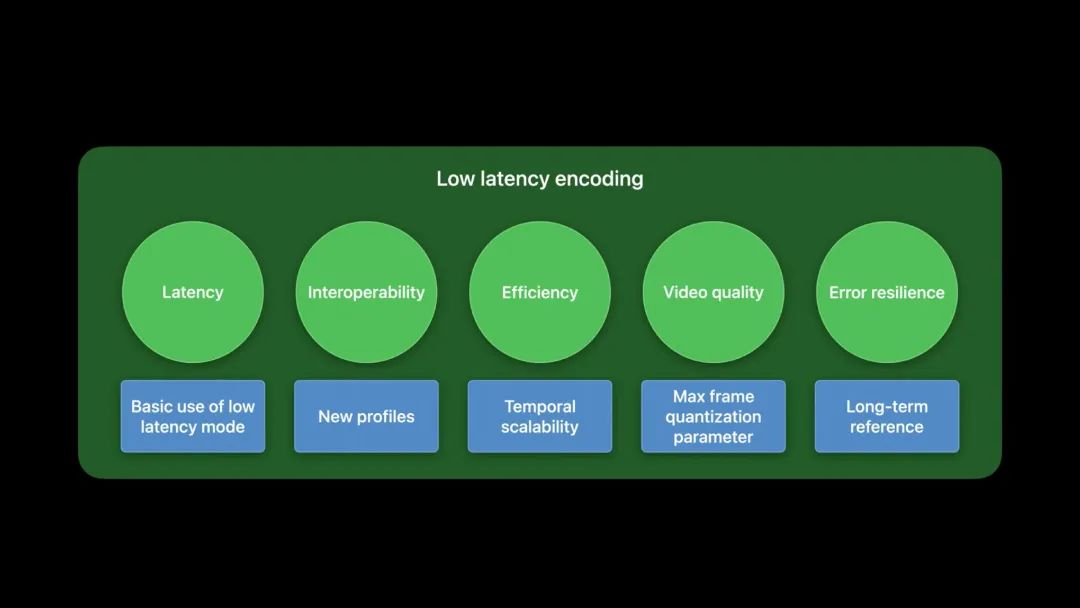
低延迟编码对许多视频 App 非常重要,尤其是实时视频通信 App。VideoToolbox 带来一种新的编码模式,以实现低延迟编码,其目标是为实时 App 优化现有的编码管线。首先,我们确定最终优化的目标。
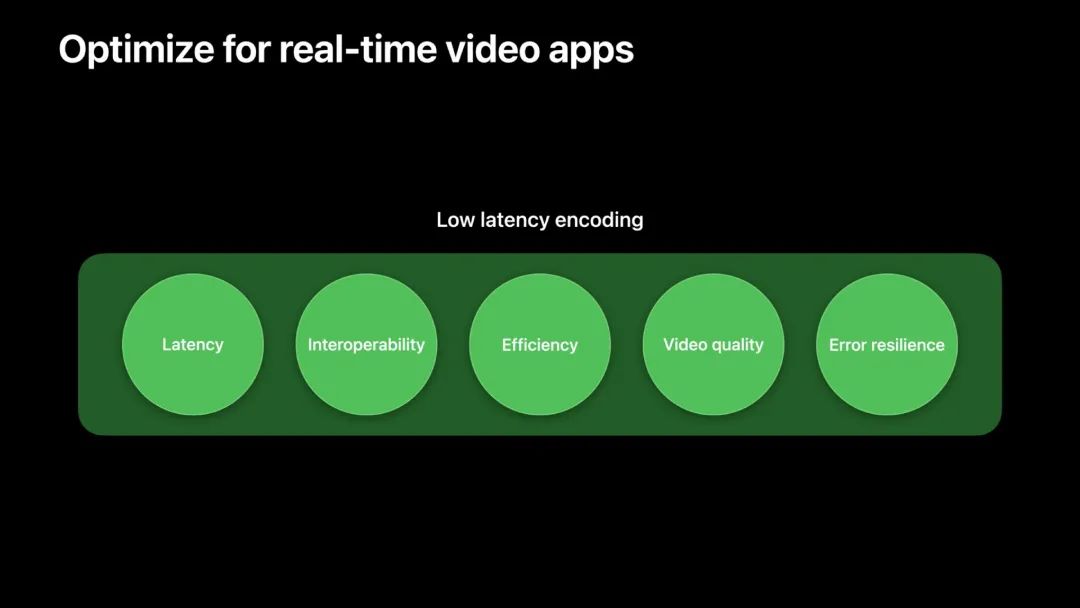
- 低延迟:把通信中端到端的延迟降到最低。
- 通信交互:通过视频 App 能与更多设备进行通信来增强相互操作性。
- 高效:当通信中有多个接收者时,编码器管线应是高效的。
- 高画质:App 以最佳画质呈现视频。
- 容错:通过一个可靠的机制,从网络丢包中恢复通信。
本文将阐述以上所有方面的优化技术,通过低延迟模式,实时 App 可以达到新的性能水平。
低延迟视频编码概述
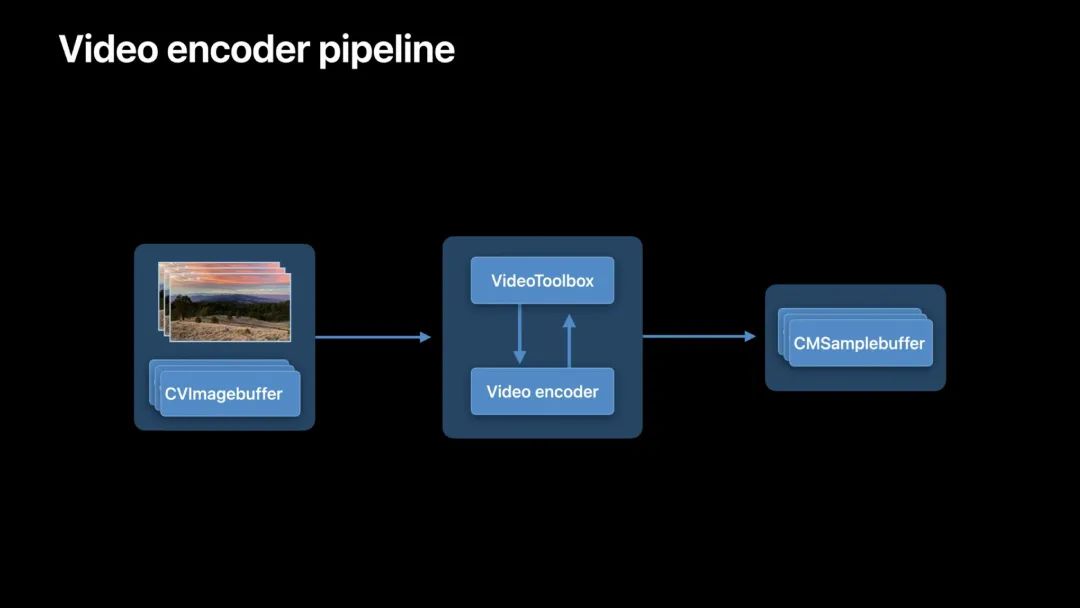
从上面的图可以注意到,端到端的延迟会受两个因素影响:
- 处理时间
- 网络传输时间
低延迟模式的解决方案:

当我们减少延迟时,可以实现更高效的编码管线,用于视频会议和直播实时通信。另外,低延迟模式总是使用硬件加速的视频编码器,以节省电量。低延迟模式支持在 iOS 和 macOS 上的 H.264 视频编解码器类型。
使用 VTCompressionSession API 实现低延迟模式
在使用低延迟模式之前,我们先回顾下 VTCompressionSession API 的使用。
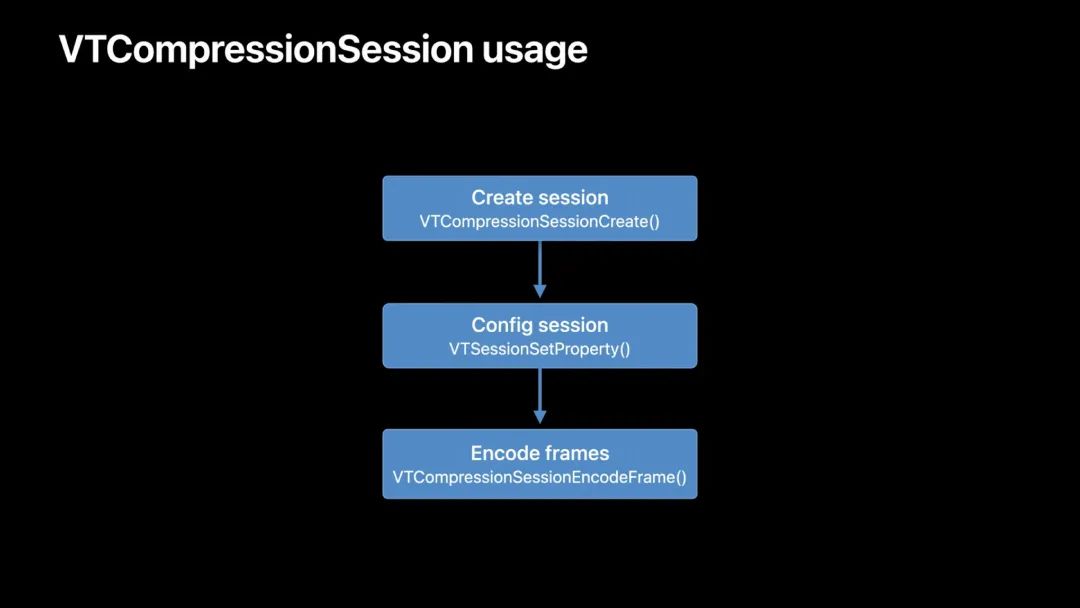
- 使用
VTCompressionSessionCreate()创建VTCompressionSession。 - 使用
VTSessionSetProperty()配置会话,如目标码率。可选,若不设置时,编码器以默认行为运行。 - 通过
VTCompressionSessionEncodeFrame()把CVImageBuffer传递给会话。 - 从创建会话时提供的输出 handler 中获取编码后的结果。
更多详细内容可参阅 VTCompressionSession 官方文档[4] 中的创建过程。
在压缩会话中启用低延迟编码很简单,只需修改会话的创建方式:
// VTCompressionSession creation
let encoderSpecification = [
kVTVideoEncoderSpecification_EnableLowLatencyRateControl: true
]
var compressionSession: VTCompressionSession? = nil
VTCompressionSessionCreate(
allocator: kCFAllocatorDefault,
width: width, height: height,
codecType: kCMVideoCodecType_H264,
encoderSpecification: encoderSpecification as CFDictionary,
imageBufferAttributes: nil,
compressedDataAllocator: nil,
outputCallback: outputHandler,
refcon: nil,
compressionSessionOut: &compressionSession
)- 创建
CFMutableDictionary作为 encoderSpecification。encoderSpecification 用于指定会话中必须使用的视频编码器。 - 在 encoderSpecification 中设置
EnableLowLatencyRateControl标志。 - 把 encoderSpecification 传入
VTCompressionSessionCreate函数创建会话。
这样创建的压缩会话就会在低延迟模式下运行。
配置步骤没有在上面列出,和原来使用流程的一样,例如可以用 AverageBitRate 属性设置目标码率。详细配置可参阅 官方文档[5]。
低延迟模式下引入的多种新功能
在开启基本的低延迟模式后,通过使用低延迟模式下引入的多种新功能来进一步降低延迟与提高性能。
- 新的 profile:在管线中新增两个 profile 来增强通信中的交互性。
- 时域分层(temporal scalability)。
- 最大帧量化参数(max frame quantization parameter):可以对画质进行细粒度的控制。
- 长参考帧(long-term reference):以此来提高容错能力。
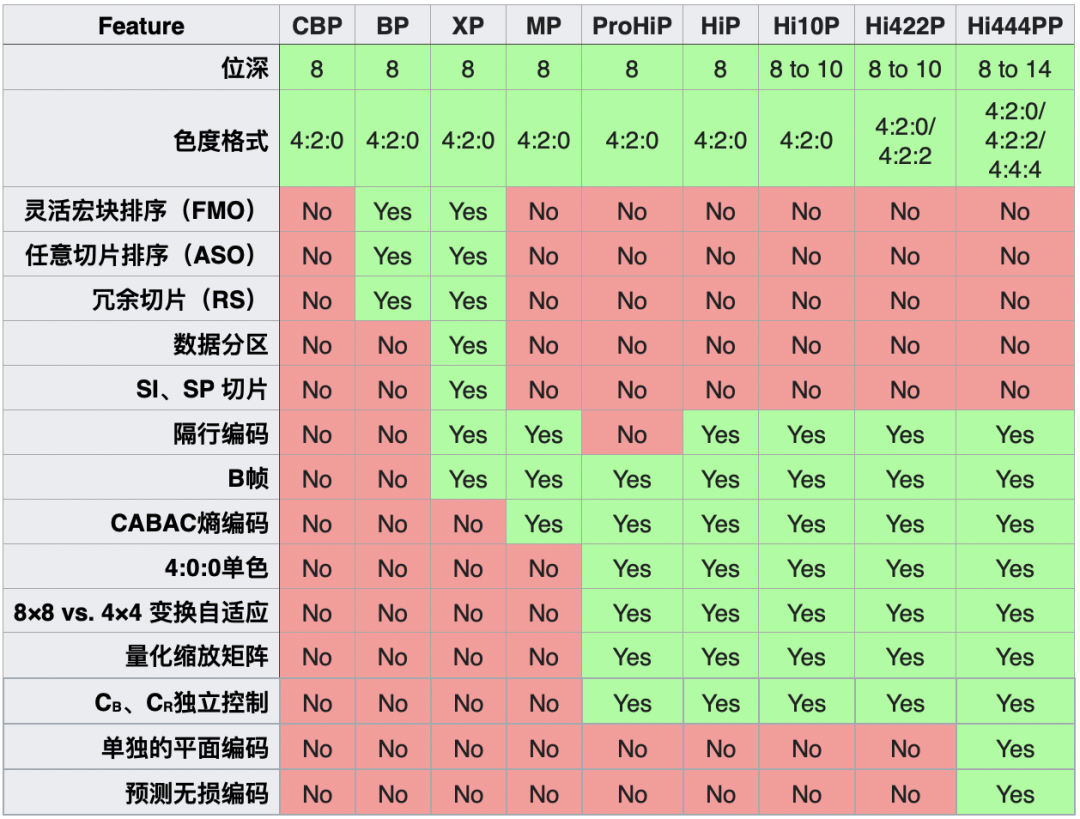
CBP & CHP
profile 定义了解码器能够支持的一组编码算法。为了与接收方通信,编码后的码流应符合解码器支持的特定 profile。
原有支持的的 profile:Baseline Profile、Main Profile 和 High Profile。现引入了两个新的 profile:
- Constrained Baseline Profile (CBP)
- Constrained High Profile (CHP)
CBP 主要用于低功耗(low-cost)的 App;而 CHP 有更先进的算法以获得更好的压缩率。使用前应先检查解码器的能力,以便知道应该使用哪种 profile。
// 请求 CBP
VTSessionSetProperty(compressionSession,
kVTCompressionPropertyKey_ProfileLevel,
kVTProfileLevel_H264_ConstrainedBaseline_AutoLevel)
// 请求 CHP
VTSessionSetProperty(compressionSession,
kVTCompressionPropertyKey_ProfileLevel,
kVTProfileLevel_H264_ConstrainedHigh_AutoLevel)要使用 CBP,只需把 ProfileLevel 会话属性设置为 ContrainedBaseLine_AutoLevel。类似地,使用 CHP 则将其设置为 ContrainedHigh_AutoLevel。
Profile 是 H.264 定义的一套功能集。每个 Profile 都是为特定的应用场景设计的。例如上述的 CBP 就是为低功耗的视频会议和移动 App 设计的。不同的 H.264 编码器有自己不同的实现,VideoToolbox 只是其中一种。与本文的其他技术一样,这些技术并不是苹果提出的,准确地说是苹果实现的。更多详细信息可参阅 Advanced Video Coding - Wikipedia[6]。
下面是不同 profile 之间支持的特性差别:
时域分层
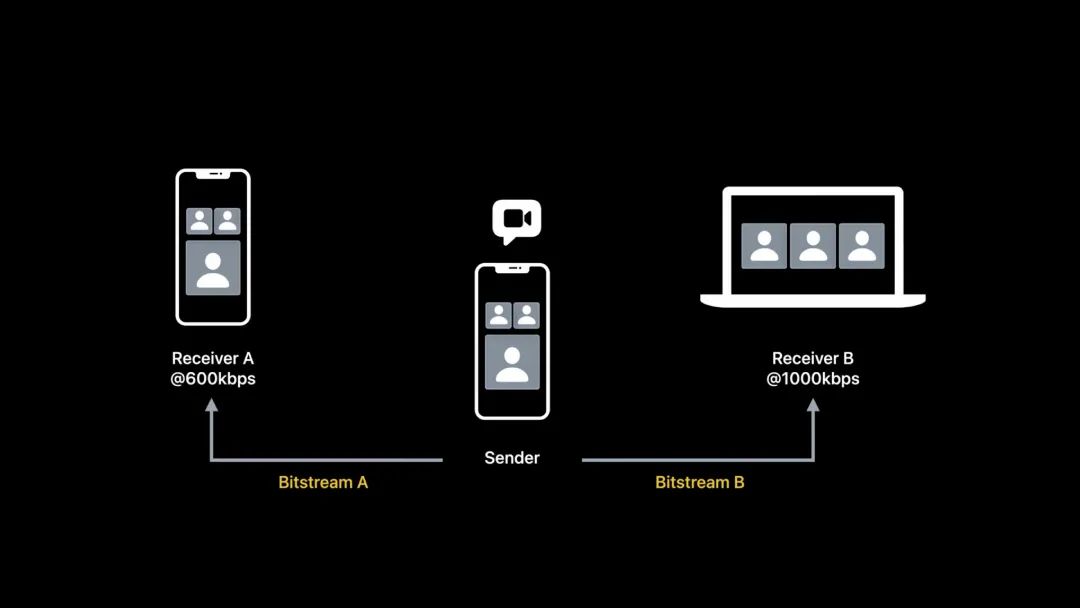
使用时域分层,可以提高多方视频通话的效率。一次编码,(在多方会话时)以不同码率传输。
假设有一个简单的三方视频会议的场景。在这个场景中,接收方 A 带宽较低,为 600 kbps,接收方 B 带宽较高,为 1,000 kbps。
使用时域分层可以让以上场景传输更加高效。发送方只需要编码一个码率,但可以分成两层传输给多个接收方。
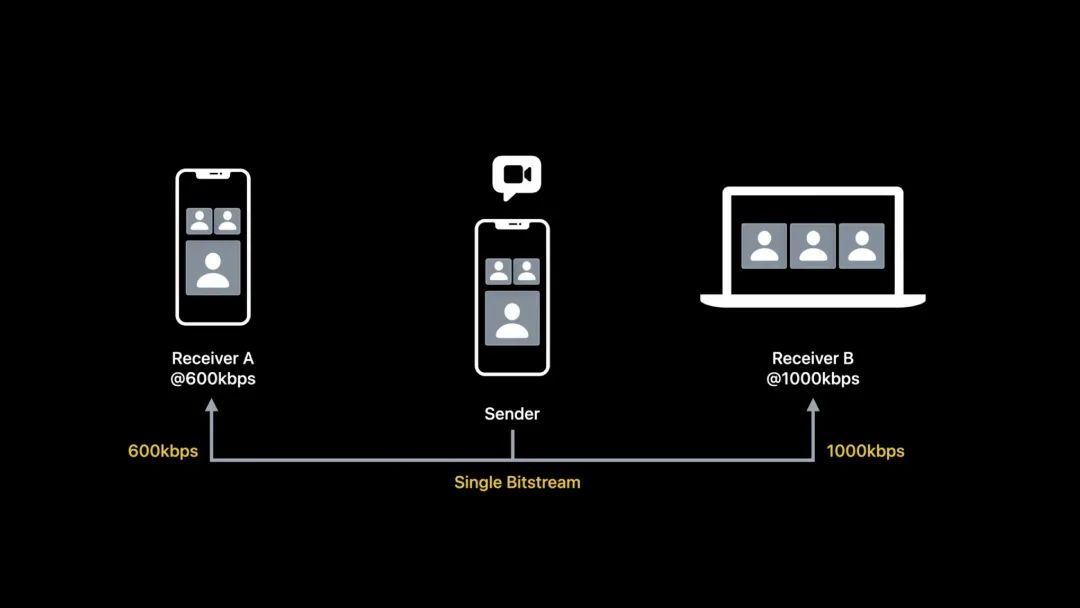

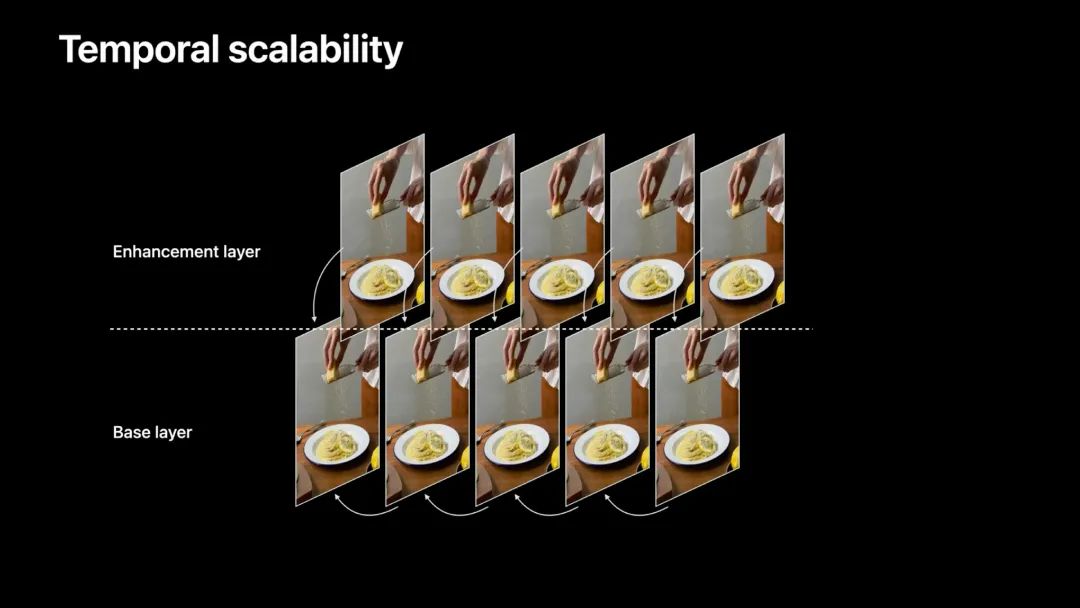
原来的一层成为基础层(base layer),而新构建的层称为增强层(enhancement layer)。
增强层作为基础层的补充,用于提高帧率。
如上图,分拆成两层后,增强层的帧参考对象没有变化,改变参考对象的是基础层,即由原来的逐帧参考改成每次跳过一帧参考。基础层由于修改了参考的对象,基础层是可以独立解码的。而增强层的帧永远是参考基础层的帧,这句话有两层意思:
- 增强层的帧必须是在基础层帧的基础上才能解码。
- 增强层在本层中各个帧不存在参考依赖关系。下面会谈到这种特性的好处。
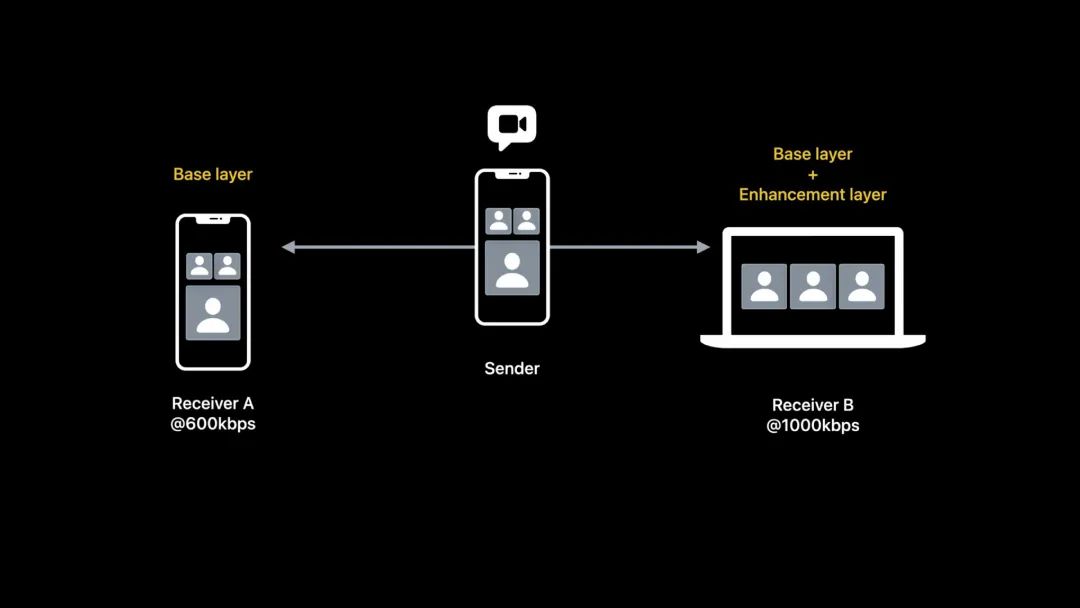
而接收方 B,因为有足够的带宽,所以传输基础层帧+增强层帧,这样接收方 B 可以享受更流畅的视频体验。
可前往 WWDC 视频 10:28 处[7] 对比以上场景中只编码基础层的视频和编码基础层+增强层的视频的差异。两个视频的区别主要体现上帧率的差异。只编码基础层的视频本身可以正常播放,但会比编码基础层+增强层的视频流畅度会差些。
只编码基础层的视频只有 50% 的输入帧率,使用 60% 的目标码率。这两路视频流只需要编码器一次编码单一的比特流。这样在进行多方视频会议时,发送方更省电。
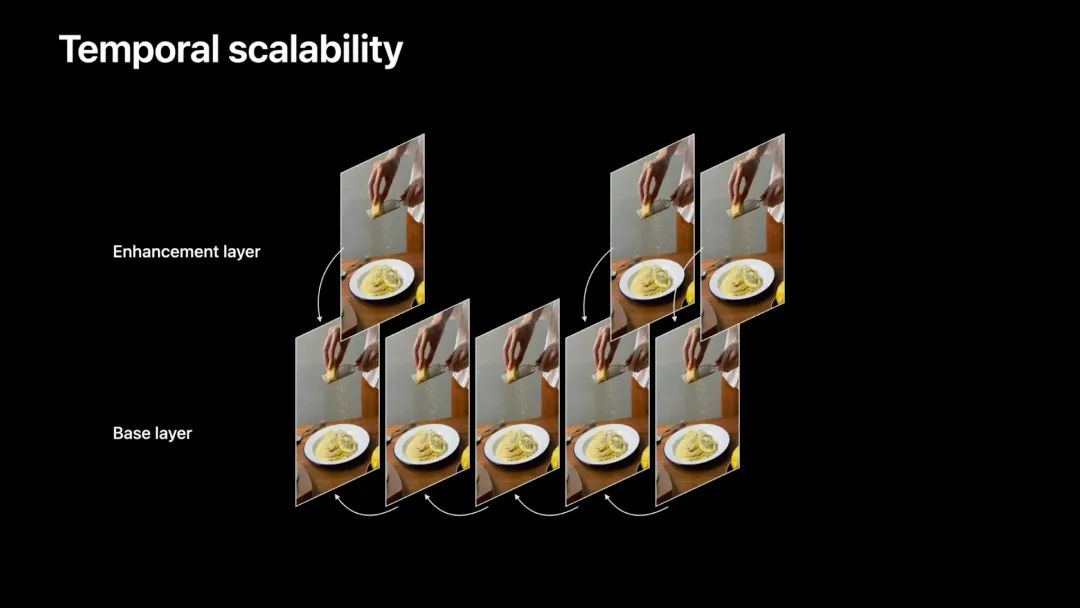
时域分层的容错性
时域分层也给视频带来一定的容错性。
API 使用
启用时域分层:
kVTCompressionPropertyKey_BaseLayerFrameRateFraction,设为 0.5。
使用时域分层的方法非常直接,在低延迟模式下设置 BaseLayerFrameRateFraction 会话属性为 0.5,这意味着一半的输入帧被分配到基础层,剩下的分配到增强层。
设置后,通过查询 kCMSampleAttachmentKey_IsDependedOnByOthers key 来验证结果,该 key-value 是 sample buffer sample-level 的一个 attachment,当为基础层的帧时,值为 true,而当为增强层的帧时,值为 false。查询方式如下:
var sampleBuffer: CMSampleBuffer!
if let attachments = CMSampleBufferGetSampleAttachmentsArray(
sampleBuffer, createIfNecessary: false
) as? [[CFString: Any]], let attachment = attachments.first {
let isDependedOnByOthers = attachment[kCMSampleAttachmentKey_IsDependedOnByOthers] as? Bool
}当然这是用传统的方式获取,iOS 13.0 或 macOS 10.15 之后,这些操作可以从全局的 C 函数转移到 CMSampleBuffer 对象属性中,获取 attachment 更加方便。但目前 CMSampleBuffer 该类文档不全,要查用法还是需用通过上面的 API 查询。上面的代码可以转变为:
let value = sampleBuffer.sampleAttachments.first?[.isDependedOnByOthers] as? Bool
为各层设置目标码率:
kVTCompressionPropertyKey_AverageBitRate,目标码率(CFNumber)。kVTCompressionPropertyKey_BaseLayerBitRateFraction,控制基础层需要的码率占比,默认 60%。
另外还可以选择为每一层设置目标码率,使用 AverageBitRate 会话属性配置。另外设置 BaseLayerBitRateFraction 属性控制基础层需要的目标码率的占比。BaseLayerBitRateFraction 属性,默认 0.6,建议值在 0.6 到 0.8 之间。
最大帧 QP
最大帧 QP 全称是最大帧量化参数,max frame quantization parameter。帧 QP 用于调节图像质量和码率。


在低延迟模式下,编码器使用诸如图像复杂度、输入帧率、视频运动等因素来调整帧 QP,以便在目标比特率约束下产生最佳的视觉质量。因此,建议依靠编码器的默认行为来调整帧 QP。
但在某些情况下,如果对视频质量有特殊要求,也允许控制编码器使用的最大帧 QP。

值得一提的是,即使指定了最大帧数 QP,设置的常规码率控制仍然有效。如果编码器达到了最大帧数 QP 的上限,但码率预算已经用完,它将开始丢帧,以保持目标码率。
使用这一功能的场景是在一个糟糕的网络上传输屏幕共享内容视频。设置最大帧 QP 通过牺牲帧率来保持发送清晰的屏幕内容图像。
API 使用
kVTCompressionPropertyKey_MaxAllowedFrameQP,最大帧 QP,取值为 1~51。
使用 MaxAllowedFrameQP 会话属性来设置最大帧 QP,取值范围必须在 1 到 51 之间。
LTR
长参考帧,long-term reference,LTR,是用于容错的技术。
在之前,假设在一个连接不良的网络下进行视频通信,其整个管线可能是这样的。
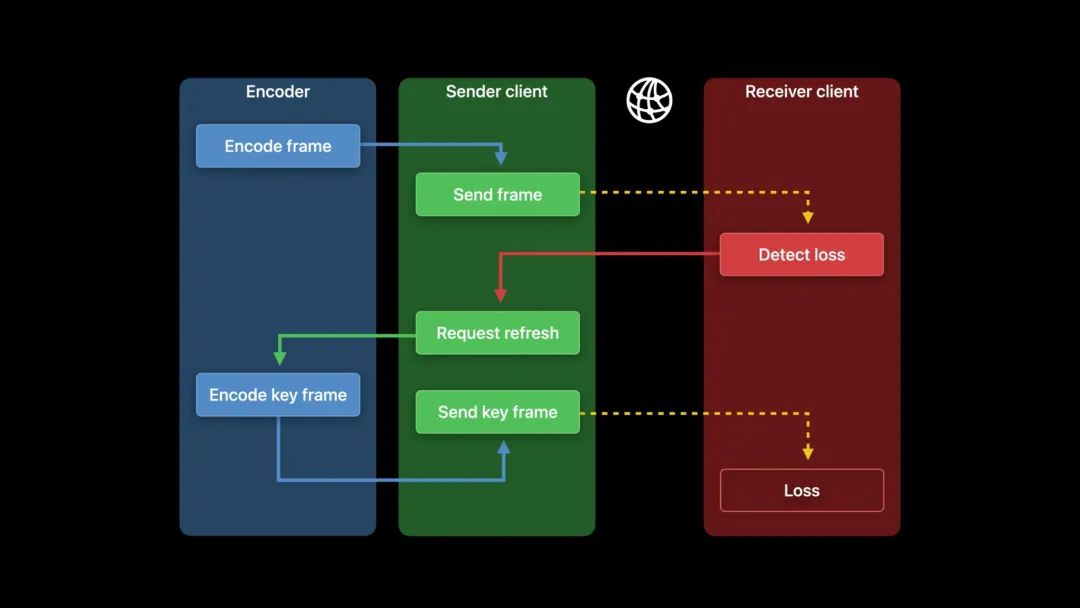
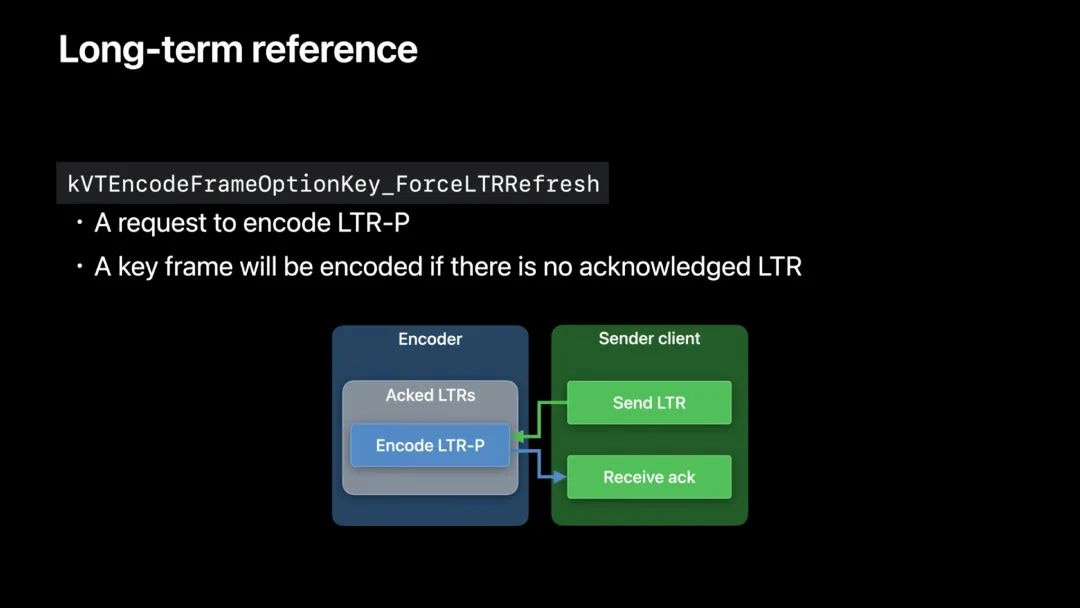
这里,我们可以用预测帧代替关键帧进行刷新。它的工作原理是这样的:
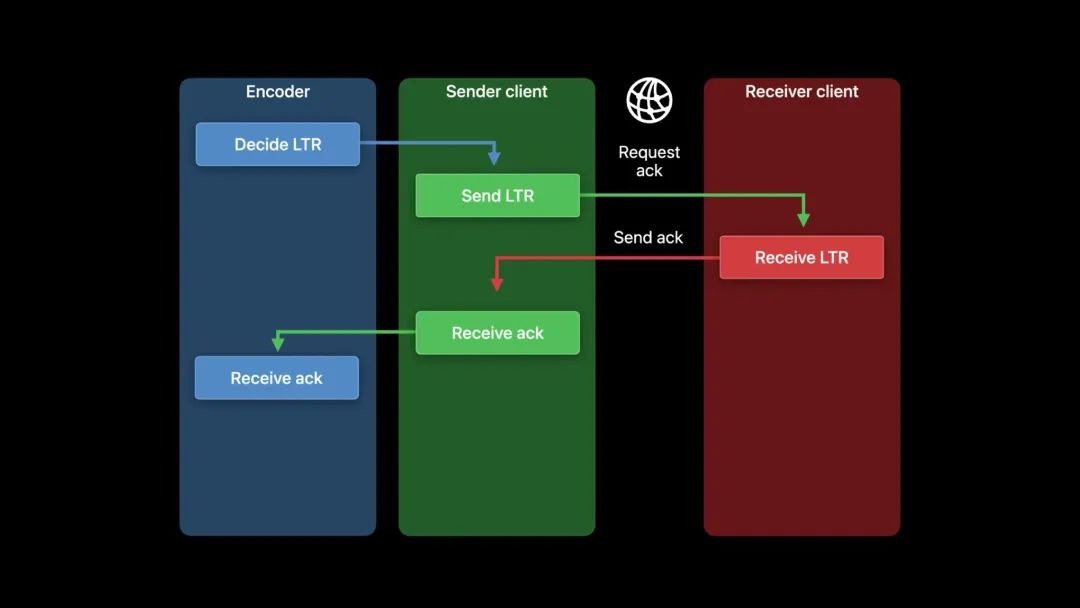
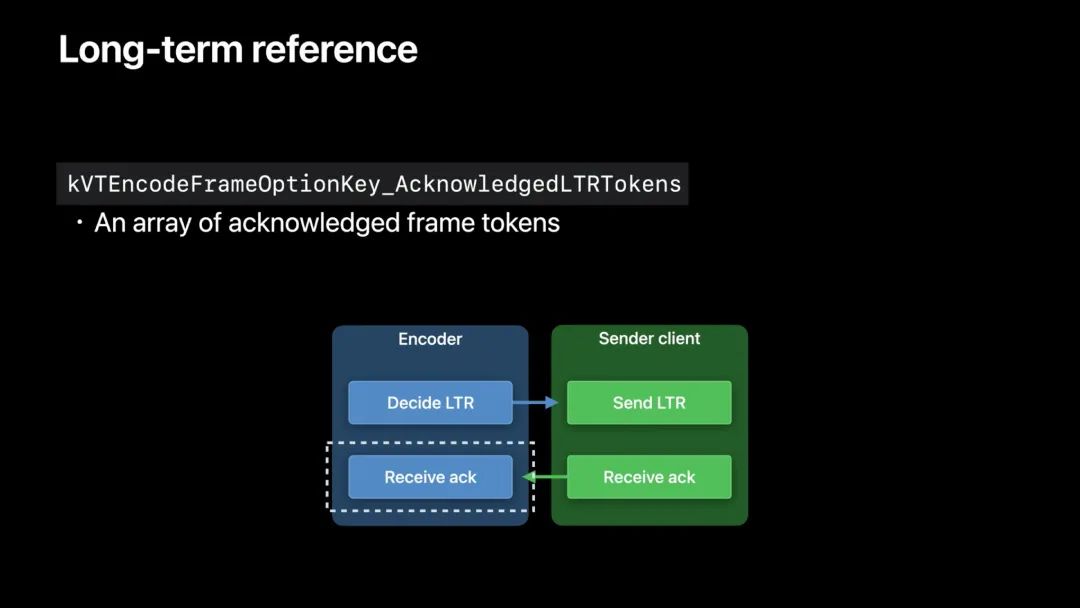
如果 LTR 帧被成功接收,接收方需发送一个确认(acknowledgement)。
一旦发送方得到确认,并将该信息传递给编码器,编码器就知道对方已经收到了哪些 LTR 帧。
另外,假如处在一个糟糕的网络环境。
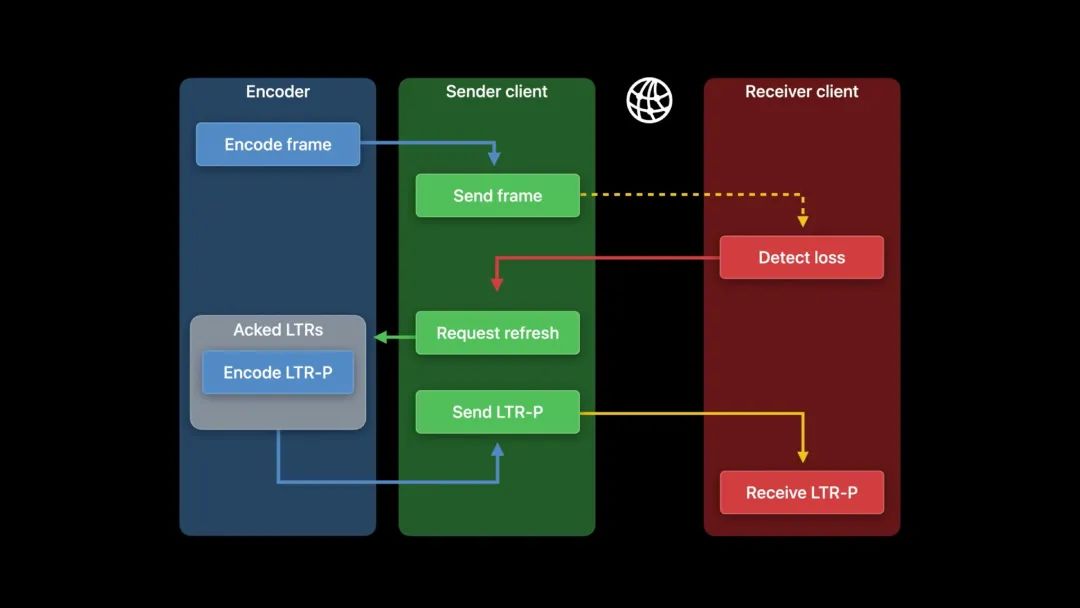
通常情况下,LTR-P 与关键帧相比,其编码帧的大小要小得多,所以它更容易传输。
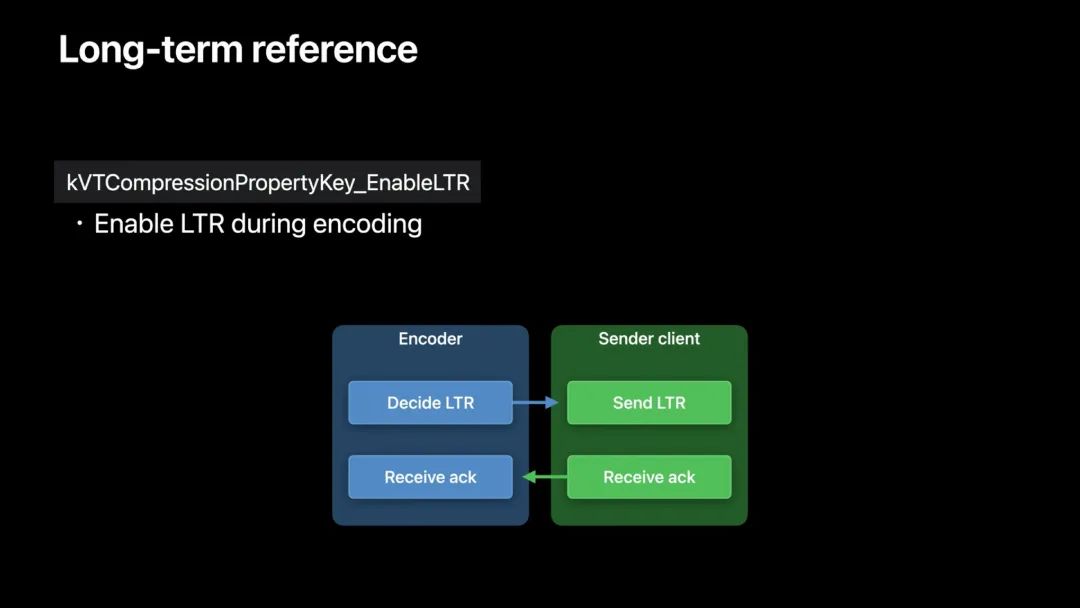
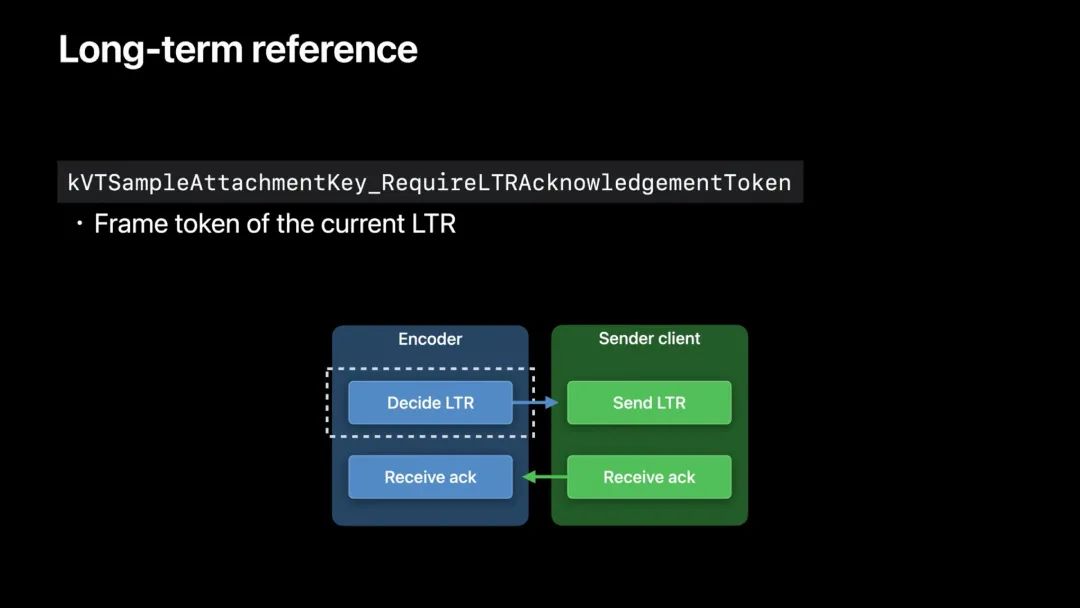
API 实现
注意,帧的确认需要由 App 来处理。它可以通过 RTP 控制协议中的 RPSI 消息等机制完成。这里只关注编码器和发送方在该过程中的通信方式。
LTR 小结
LTR 技术是低延迟模式中流程和使用都比较复杂的技术。首先,这里出现了两个名词:LTR 帧、LTR-P 帧。首先,这两者并没有突破 H.264 基础的 I、P、B 帧的概念,只是在这些帧的基础上加了些料罢了。
LTR 帧,就是普通帧+LTR 标记,这个标记用于发送方与接收方之间的通信确认。好处:发送方及时知道每一个帧的接收情况。坏处,也不能说是坏处,准确地说是给接收方客户端的挑战,即需要在接收到帧的时候给发送方发送一个确认。另外,发送方也需要开辟更大的缓存空间来存放确认的 LTR 帧。
LTR-P 帧,就是 P 帧+LTR 标记,去掉 LTR 标记也就是个普通的 P 帧,特殊的是它产生的方式。LTR-P 帧是从已确认的 LTR 帧生成的。LTR-P 帧的好处是当发生网络错误,发生丢帧,要恢复画面时,不需要发送 I 帧,而是用之前确认的 LTR 帧生成一个 P 帧发送。由于 P 帧是使用帧间编码生成的,只包含运动估计和残差信息,相比帧内编码的 I 帧,数据量小很多。LTR 帧极大地降低传输的数据量并提高接收方恢复画面的速度。当然如果没有已确认的 LTR 帧,还是会生成一个 I 帧进行发送啦…
当然,使用 LTR 技术,如果编解码器不支持可能需要发送方和接收方都要修改对应的逻辑。
组合使用
我们可以把时域分层和最大帧 QP 用于群组屏幕共享 App。时域分层可以为每个接收方有效地生成输出视频,而我们可以降低最大帧 QP 以获得更清晰的图像。
如果通信通过一个糟糕的网络,并且需要一个刷新帧来恢复错误,可以使用 LTR。而如果接收方只能解码 constrained profile,我们可以使用 CBP 或 CHP 进行编码。
总结
本文内容可以总结为以下几点:
-
低延迟视频编码概述
-
实时顺序编码
-
码率控制器对网络变化响应速度的提升
-
总是使用硬件加速的视频编码器
-
支持 H.264 视频编解码器类型
-
低延迟编码的目标:低延迟、通信交互、高效、高画质、容错
-
低延迟模式解决方案:
-
VTCompressionSession API 实现
-
低延迟模式下引入的新功能及其使用:
-
CBP & CHP
-
时域分层,实现一路视频输出可按层分发
-
最大帧量化参数,实现画质与码率控制
-
长参考帧,实现在糟糕网络下用 P 帧恢复会话
-
组合使用
这次 VideoToolbox 带来的新特性极大地提升了在 H.264 直播中的画质和通信稳定性,也是疫情环境下催生(倒逼)的新技术。而在这次 WWDC 中也很容易让人想到,这项技术就是为 FaceTime 和 SharePlay 准备的,当然把这项技术公开给开发者,也可以让大家做出更稳定的、更高效的实时互动直播。