brpc小课堂:有界队列BoundedQueue
开场白
什么是有界队列?
brpc实现了一个“有界队列”的类模板BoundedQueue。先说一下什么是有界队列。 所谓有界队列表示的就是一个队列其中的容量是有限的(固定的),不能动态扩容的队列。这种听起来没有vector那种自动扩容能力的容器,主要还是全面为了性能考虑的。一般也是用作生产者和消费者模式,当队列容量已满的时候,一般就表示超过了这个队列的最大吞吐能力,故而拒绝加入新的任务。
在实践中有界队列一般是基于ring buffer(环形缓冲区)来实现的。或者说有界队列就是ring buffer的别名也不为过。ring buffer也被称为circular buffer或circular queue。 整体思路就是用一段固定大小的线性连续空间来模拟循环的队列。详细的定义可以阅读维基百科:
https://en.wikipedia.org/wiki/Circular_buffer
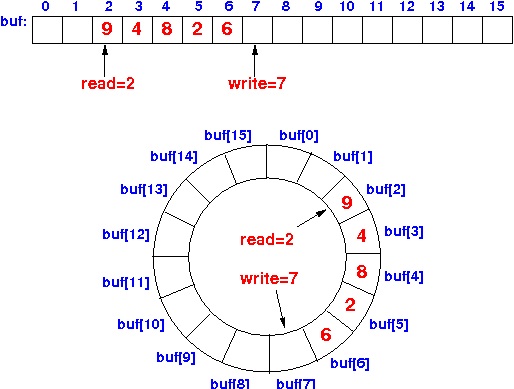
ring buffer的定义很简单,实现细节上有多种不同的方案。比如存储读指针和写指针,标记下一次pop和push的位置。这种实现的麻烦之处是对于队列的满或者空是有歧义的。因为队列满和队列空的时候读写两个指针都是指向相同位置。要区分具体是满还是空,就要额外的操作。比如总保持队列中有一个元素是不可写的,此时如果读写指针指向同一位置,则缓冲区为空。如果读指针位于写指针的相邻后一个位置,则缓冲区为满。
当然还有其他实现,比如不存储写指针,而是存储队列中写入的元素个数。每次写入的时候,通过读指针加上元素个数(需要取模)来计算出写指针的位置。brpc的实现就是这种方案。
brpc中的有界队列
// A thread-unsafe bounded queue(ring buffer). It can push/pop from both
// sides and is more handy than thread-safe queues in single thread. Use
// boost::lockfree::spsc_queue or boost::lockfree::queue in multi-threaded
// scenarios.看注释可以发现,BoundedQueue是一个线程不安全的有界队列。所以BoundedQueue不支持多线程间的并发读写,不过也因此BoundedQueue的代码足够简单。简单到给你10分钟到时间就可以看完,基本上是一个“裸”的ring buffer实现。当然也不是说BoundedQueue不能应用在多线程读写的场景,只是说你需要在外围添加额外的线程同步控制逻辑,比如下文我们也会提到的RemoteTaskQueue。
接下来我们来阅读一下他的源码: 代码路径:butil\containers\bounded_queue.h
模板声明与数据成员
先看一下模板声明及其中的数据成员:
template <typename T>
class BoundedQueue {
public:
...
private:
// Since the space is possibly not owned, we disable copying.
DISALLOW_COPY_AND_ASSIGN(BoundedQueue);
...
uint32_t _count; // 当前元素个数
uint32_t _cap; // 容量
uint32_t _start; // 起始位置
StorageOwnership _ownership; // 枚举类型,所有权。表示有界队列是否持有该数据
void* _items; // 数据指针
};StorageOwnership的定义:
enum StorageOwnership { OWNS_STORAGE, NOT_OWN_STORAGE };
顾名思义,枚举值OWNS_STORAGE表示有界队列持有数据存储的所有权,NOT_OWN_STORAGE则没有。
构造函数
看一下构造函数,它有三个重载。第一个:
// You have to pass the memory for storing items at creation.
// The queue contains at most memsize/sizeof(T) items.
BoundedQueue(void* mem, size_t memsize, StorageOwnership ownership)
: _count(0)
, _cap(memsize / sizeof(T))
, _start(0)
, _ownership(ownership)
, _items(mem) {
DCHECK(_items);
};
支持传入数据所有权ownership,数据地址mem以及大小memsize。
// Construct a queue with the given capacity.
// The malloc() may fail silently, call initialized() to test validity
// of the queue.
explicit BoundedQueue(size_t capacity)
: _count(0)
, _cap(capacity)
, _start(0)
, _ownership(OWNS_STORAGE)
, _items(malloc(capacity * sizeof(T))) {
DCHECK(_items);
};只传入容量capacity,这种表示队列持有数据存储的所有权,在构造时用malloc来分配内存。当然鉴于malloc不一定总能成功,故而使用DCHECK来做一把校验。TODO,失败了如何?
push相关函数
push()
// Push |item| into bottom side of this queue.
// Returns true on success, false if queue is full.
bool push(const T& item) {
if (_count < _cap) {
new ((T*)_items + _mod(_start + _count, _cap)) T(item);
++_count;
return true;
}
return false;
} // Push a default-constructed item into bottom side of this queue
// Returns address of the item inside this queue
T* push() {
if (_count < _cap) {
return new ((T*)_items + _mod(_start + _count++, _cap)) T();
}
return NULL;
}如果队列没满,则使用placement new进行构造。常规的new是不需要自己指定对象分配的堆地址的,而placement new则可以在指定的内存位置上构造对象。这里内存位置通过起始位置+元素个数来定位到。
// This is faster than % in this queue because most |off| are smaller
// than |cap|. This is probably not true in other place, be careful
// before you use this trick.
static uint32_t _mod(uint32_t off, uint32_t cap) {
while (off >= cap) {
off -= cap;
}
return off;
}这个模运算使用了一个比较Trick的技巧,他的限制是off永远能保证在[0, 2*cap)之间。
push_top()
// Push |item| into top side of this queue
// Returns true on success, false if queue is full.
bool push_top(const T& item) {
if (_count < _cap) {
_start = _start ? (_start - 1) : (_cap - 1);
++_count;
new ((T*)_items + _start) T(item);
return true;
}
return false;
}
// Push a default-constructed item into top side of this queue
// Returns address of the item inside this queue
T* push_top() {
if (_count < _cap) {
_start = _start ? (_start - 1) : (_cap - 1);
++_count;
return new ((T*)_items + _start) T();
}
return NULL;
}elim_push()
// Push |item| into bottom side of this queue. If the queue is full,
// pop topmost item first.
void elim_push(const T& item) {
if (_count < _cap) {
new ((T*)_items + _mod(_start + _count, _cap)) T(item);
++_count;
} else {
((T*)_items)[_start] = item;
_start = _mod(_start + 1, _cap);
}
}pop相关函数
pop是push的逆操作,这里大家可以选择性的阅读。
pop()
// Pop top-most item from this queue
// Returns true on success, false if queue is empty
bool pop() {
if (_count) {
--_count;
((T*)_items + _start)->~T();
_start = _mod(_start + 1, _cap);
return true;
}
return false;
}
// Pop top-most item from this queue and copy into |item|.
// Returns true on success, false if queue is empty
bool pop(T* item) {
if (_count) {
--_count;
T* const p = (T*)_items + _start;
*item = *p;
p->~T();
_start = _mod(_start + 1, _cap);
return true;
}
return false;
}值得一提的是pop() 和 push()是对称的一对操作,但是他们的函数参数却并不相同。在有参版的push()中,其参数是const T&,而pop()的参数是T*。 这其中的差异是我们需要通过pop_bottom()的出参拿到元素。好的C++编码规范(比如谷歌编码规范)都指明,当函数参数做出参的时候用指针,而作为入参的时候使用const &。
pop_bottom()
// Pop bottom-most item from this queue
// Returns true on success, false if queue is empty
bool pop_bottom() {
if (_count) {
--_count;
((T*)_items + _mod(_start + _count, _cap))->~T();
return true;
}
return false;
}
// Pop bottom-most item from this queue and copy into |item|.
// Returns true on success, false if queue is empty
bool pop_bottom(T* item) {
if (_count) {
--_count;
T* const p = (T*)_items + _mod(_start + _count, _cap);
*item = *p;
p->~T();
return true;
}
return false;
}当然push系列函数中的elim_push()在pop中并没有对应的逆操作,这也不难理解。但队列已满的时候,我实在想插入数据可以移除队头元素,但是如果队列为空的时候,我们实在还想从中取出一个元素,那么则是没有什么办法。
清空队列
void clear() {
for (uint32_t i = 0; i < _count; ++i) {
((T*)_items + _mod(_start + i, _cap))->~T();
}
_count = 0;
_start = 0;
}这里主要做的是,遍历所有元素,取显式调用其析构函数:->~T()。这个操作是由于我们的对象是通过placement new构造的,->~T() 就是其必须成对的析构操作。就像new必须有delete一般。但和new与delete不同的是,不管是placement new 还是 ->~T() 都没有对本对象去做堆中内存的分配和释放!(当然如果T中有成员,其实还是会涉及到堆内存分配和释放的,但那是针对其中的成员,并不是T本身)
讲到这,我们来看一下析构函数。
析构函数
~BoundedQueue() {
clear();
if (_ownership == OWNS_STORAGE) {
free(_items);
_items = NULL;
}
}首先调用前面的clear()函数,然后需要对数据存储的所有权做一个判断,只有明确是自己持有的情况下,采取free()释放掉内存,和malloc()成对。而对于非自己持有的,就不必了。
一些视图操作
本节主要是介绍对于有界队列的一些数据与元信息进行观测的函数。
top()
// Get address of top-most item, NULL if queue is empty
T* top() {
return _count ? ((T*)_items + _start) : NULL;
}
const T* top() const {
return _count ? ((const T*)_items + _start) : NULL;
}
// Randomly access item from top side.
// top(0) == top(), top(size()-1) == bottom()
// Returns NULL if |index| is out of range.
T* top(size_t index) {
if (index < _count) {
return (T*)_items + _mod(_start + index, _cap);
}
return NULL; // including _count == 0
}
const T* top(size_t index) const {
if (index < _count) {
return (const T*)_items + _mod(_start + index, _cap);
}
return NULL; // including _count == 0
}bottom()
// Get address of bottom-most item, NULL if queue is empty
T* bottom() {
return _count ? ((T*)_items + _mod(_start + _count - 1, _cap)) : NULL;
}
const T* bottom() const {
return _count ? ((const T*)_items + _mod(_start + _count - 1, _cap)) : NULL;
}
// Randomly access item from bottom side.
// bottom(0) == bottom(), bottom(size()-1) == top()
// Returns NULL if |index| is out of range.
T* bottom(size_t index) {
if (index < _count) {
return (T*)_items + _mod(_start + _count - index - 1, _cap);
}
return NULL; // including _count == 0
}
const T* bottom(size_t index) const {
if (index < _count) {
return (const T*)_items + _mod(_start + _count - index - 1, _cap);
}
return NULL; // including _count == 0
}initialized()
检查队列是否已经初始化
// True if the queue was constructed successfully.
bool initialized() const { return _items != NULL; }empty()和full()
bool empty() const { return !_count; }
bool full() const { return _cap == _count; }size()和capacity()
// Number of items
size_t size() const { return _count; }
// Maximum number of items that can be in this queue
size_t capacity() const { return _cap; }max_capacity()
// Maximum value of capacity()
size_t max_capacity() const { return (1UL << (sizeof(_cap) * 8)) - 1; }这个函数的内容其实是编译期间就能确定的。也就是说返回的是固定值。sizeof(_cap)返回的是_cap的字节数,乘以8则是因为一个字节(byte)等于8个位(bit)。所以sizeof(_cap) * 8)表示的就是uint32_t类型所占的bit数,1UL << (sizeof(_cap) * 8)) - 1的结果就是uint32_t的每一位都是1,也就是uint32_t所能表示的最大值。
这个函数应该是实现的类似vector的max_size()接口。只不过这里命名成了max_capacity()。vector中的max_size()表示的是vector能存储的最大元素个数,有这个函数的原因是因为vector是能够动态扩容的。而有界队列,其实是不存在动态扩容的。所以这个max_capacity()其实也没太大用。
在brpc中的应用
BoundedQueue 在brpc中有大量使用。比如实现bthread时,每个做worker用的pthread都有一个TaskGroup,而这个TaskGroup中有两个队列:
class TaskGroup {
...
WorkStealingQueue<bthread_t> _rq;
RemoteTaskQueue _remote_rq;
...
};
其中的_remote_rq的类RemoteTaskQueue就是通过BoundedQueue存储的。
class RemoteTaskQueue {
public:
RemoteTaskQueue() {}
int init(size_t cap) {
const size_t memsize = sizeof(bthread_t) * cap;
void* q_mem = malloc(memsize);
if (q_mem == NULL) {
return -1;
}
butil::BoundedQueue<bthread_t> q(q_mem, memsize, butil::OWNS_STORAGE);
_tasks.swap(q);
return 0;
}由于BoundedQueue构造函数并不能很好的处理malloc失败的情况。所以这里是在外部用malloc一段内存,然后再传给BoundedQueue来管理(所有权是:OWNS_STORAGE)
class RemoteTaskQueue {
// ...
bool pop(bthread_t* task) {
if (_tasks.empty()) {
return false;
}
_mutex.lock();
const bool result = _tasks.pop(task);
_mutex.unlock();
return result;
}
bool push(bthread_t task) {
_mutex.lock();
const bool res = push_locked(task);
_mutex.unlock();
return res;
}
bool push_locked(bthread_t task) {
return _tasks.push(task);
}可以看到在往RemoteTaskQueue中push和pop数据的时候,要自己添加加锁和解锁的代码,因为我们开头就已经讲过了:
BoundedQueue 不是线程安全的!
push_locked()函数,由于没有在内部加锁,所以需要调用RemoteTaskQueue的使用方在更外围加锁。看下这个函数被唯一调用过的地方:
void TaskGroup::ready_to_run_remote(bthread_t tid, bool nosignal) {
_remote_rq._mutex.lock();
while (!_remote_rq.push_locked(tid)) {
flush_nosignal_tasks_remote_locked(_remote_rq._mutex);
LOG_EVERY_SECOND(ERROR) << "_remote_rq is full, capacity="
<< _remote_rq.capacity();
::usleep(1000);
_remote_rq._mutex.lock();
}
...
...
}