合成监控在转转的实践
为什么需要监控
众所周知,性能在提升网站留存率和转化率方面扮演着很重要的角色,尤其对于转转这种电商网站,性能会间接影响到公司的收入。
但是如果让你去描述你们网站应用的性能时,你会怎么回答。你可能会说:比市面上大部分应用要好。但是如果要你说出好在哪里又该如何描述呢?这个时候我们就会想到先对网站进行性能监控,用数据说话。但是监控哪些指标、怎么监控呢?
监控什么
首先需要明确的是我们应该监控什么,或者说我们应该以一个什么指标来度量一个网站的性能好坏呢?
google 最早提出了一个 RAIL 模型来衡量应用性能,即:Response、Animation、Idle、Load,分别代表着 web 应用生命周期的四个不同方面。并指出最好的性能指标是:应该尽可能快速的响应用户的操作,最好在 100ms 内;在展示动画的时候,每一帧应该以 16ms 进行渲染,这样可以保持动画效果的一致性,并且避免卡顿;最大化空闲时间,当使用 js 主线程的时候,应该把任务划分到执行时间小于 50ms 的片段中去,这样可以释放线程以进行用户交互;应该在小于 1s 的时间内加载完成你的网站,最长不超过 5 秒。
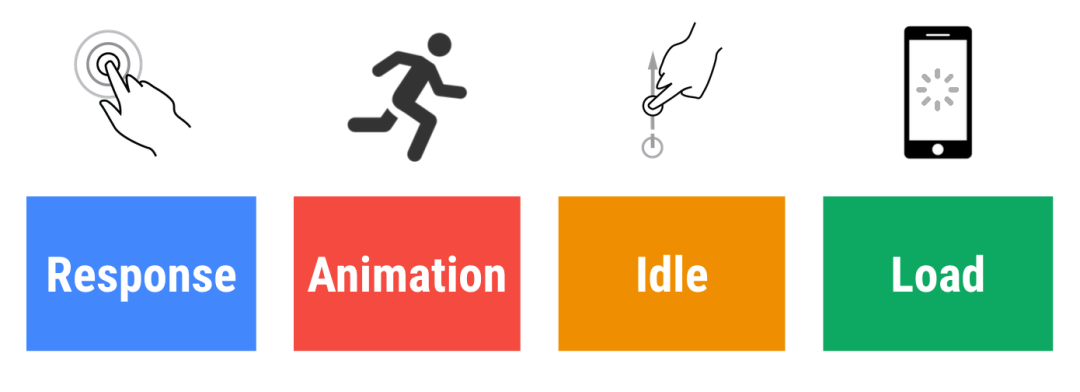
google 也相对应的制定了一些基于用户体验的性能指标
FCP 首次内容绘制时间(First Contentful Paint):首次内容绘制,浏览器首次绘制来自 DOM 的内容的时间,内容必须包括文本,图片,非白色的 canvas 或 svg,也包括带有正在加载中的 web 字体文本。这是用户第一次看到的内容
LCP 最大内容绘制时间 (Largest Contentful Paint):最大内容绘制,可视区域中最大的内容元素呈现到屏幕上的时间,用以估算页面的主要内容对用户的可见时间。img 图片,video 元素的封面,通过 url 加载到的背景,文本节点等,为了提供更好的用户体验,网站应该在 2.5s 以内或者更短的时间最大内容绘制。
FID 首次输入延迟时间(First Input Delay):首次输入延迟,从用户第一次与页面进行交互到浏览器实际能够响应该交互的时间,输入延迟是因为浏览器的主线程正忙于做其他事情,所以不能响应用户,发生这种情况的一个常见原因是浏览器正忙于解析和执行应用程序加载的大量计算的 JavaScript。
TTI 页面可交互时间(Time to Interactive):网页第一次完全达到可交互状态的时间点,浏览器已经可以持续的响应用户的输入,完全达到可交互的状态的时间是在最后一个长任务完成的时间,并且在随后的 5 秒内网络和主线程是空闲的。从定义上来看,中文名称叫持续可交互时间或可流畅交互时间更合适。
TBT 主线程累计阻塞时间(Total Block Time):总阻塞时间,度量了 FCP 和 TTI 之间的总时间,在该时间范围内,主线程被阻塞足够长的时间以防止输入响应。只要存在长任务,该主线程就会被视为阻塞,该任务在主线程上运行超过 50 毫秒
CLS 累计布局偏移 (Cumulative Layout Shift):累计布局偏移,CLS 会测量在页面整个生命周期中发生的每个意外的布局移位的所有单独布局移位分数的总和,他是一种保证页面的视觉稳定性从而提升用户体验的指标方案。
google 后来觉得指标有些太多了,就缩减成三个了,也就是 2020 年提出的 Web Vitals。认为网站只要做好加载性能 LCP,交互性 FID,视觉稳定性 CLS,基本性能就可以了
转转内部也有自己沉淀的一套性能衡量指标,包含自研的根据 dom 权重计算的 FMP 指标,再配合白屏时间、秒开率、DOM 加载时间等综合来评定一个网站的性能优劣。
怎么监控
有了指标,接下来我们就需要监控。通过监控来知道 web 应用性能的现状和趋势,找到 web 应用的瓶颈,提高业务的稳定性。同时还能清楚的了解到某次发布后对性能的影响,感知到业务出错的概率。
目前市面上的主流监控分为两种,一种是合成监控,一种是真实用户监控。
合成监控是指在一个模拟场景里去运行你的页面,然后提取一些性能指标,得出一个审计报告。另外一种是真实用户监控:真实用户监控是一种应用服务,被监控的 web 应用通过 sdk 等方式接入该服务,将真实的用户访问、交互等性能指标数据收集上报到我们的日志服务器上、通过数据清洗加工后形成性能分析报表,最后在我们的监控平台上进行展示
两种监控的对比

用于真实用户监控的性能平台之前公众号已有相关文章阐述,接下来主要介绍下如何进行合成监控
合成监控-Lighthouse
合成监控中最流行的是 Google 的 Lighthouse。Lighthouse 是一个开源的自动化工具,用于分析和改善 Web 应用的质量。启动 Lighthouse 共有 4 种姿势,分别是 Chrome 开发者工具,Chrome 扩展程序,Node CLI 和 Node module。
以最常用也最为方便的的开发者工具的方式运行 Lighthouse 会生成一个如下的报告。
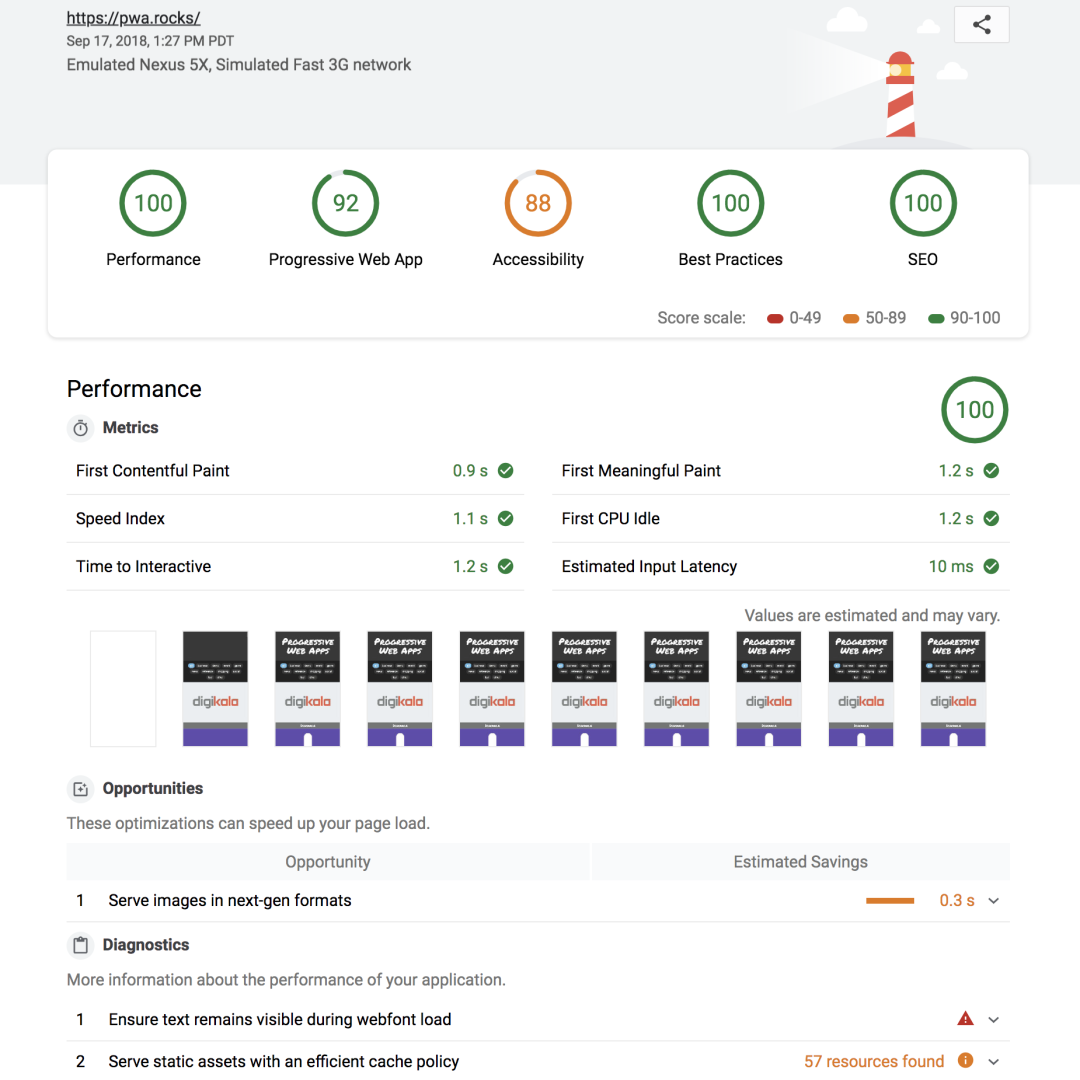
- 无法检测需要登录的页面
- 指标太多、太杂,无法定制化、差异化
- 没有接入平台,无法了解整体概况
目前业界大部分公司都会选择搭建一个合成监控平台,通过 Node module 以编程的方式来解决上述问题
Lighthouse 运行流程
以编程的方式运行 Lighthouse,就需要先对 Lighthouse 的运行流程做一个全面的了解
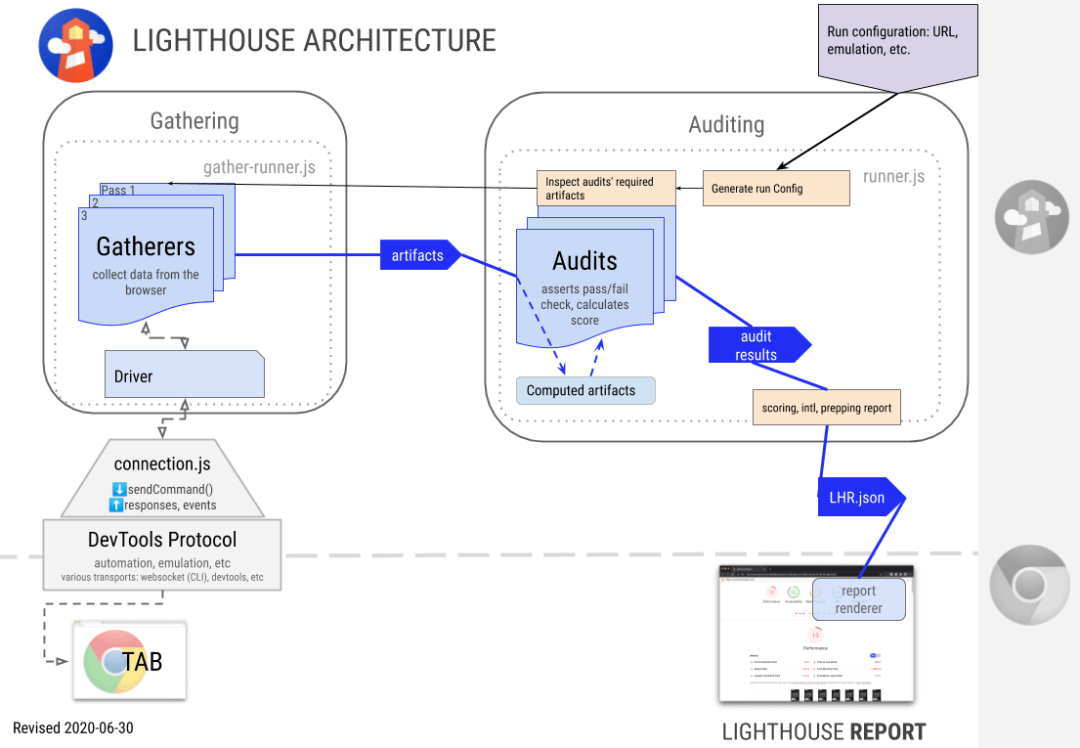
Lighthouse 会驱动 Driver 通过 Chrome DevTool Protocol 协议 与浏览器进行交互,执行一系列命令,然后通过 Gatherers 模块采集页面加载过程中的信息,并生成中间产物 artifacts,这些 artifacts 信息的聚合会在 Auditing 阶段作为 Audit case 逻辑的输入凭证,通过定义的一系列自定义的审计标准输出分数/优化/详情/描述/原因/展示形式/错误等信息,最终得到一系列的 LHR 统计结果并输出 UI 报表。
解决问题
流程介绍完了,那么如何基于 Lighthouse 的运行流程去解决上述的几点问题呢?
登录问题
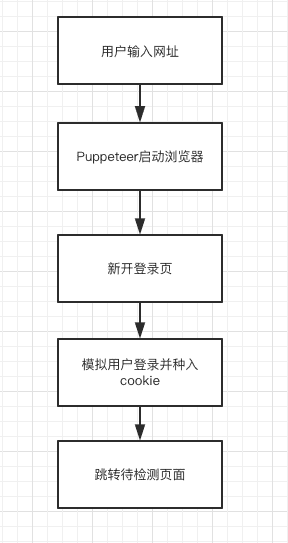
我们知道,直接使用 Lighthouse 去检测需要登录态的页面最终输出的其实是登录页的检测结果,这显然不是我们想要的。
好在官方也给我们指明了出路,最方便最灵活的就是使用 Puppeteer 模拟用户登录,正好 Puppeteer 也是使用 Chrome DevTool Protocol 协议,可以无缝切换。
在 Lighthouse 中使用 Puppeteer 有两种方式,一种是使用 Puppeteer 启动浏览器,然后将控制权交还到 Lighthouse,另外一种是使用 Lighthouse/chrome-launcher 启动浏览器,然后将控制权交还到 Puppeteer。这里我们采用的是第一种方式
个性化
默认的检测指标只是一个通用的检测模型,实际情况中我们需要根据不同的业务形态去制定不同的检测模型。比如在 pc 端由于逻辑复杂,我们可能会写很多的嵌套组件,那么构建 dom 数的深度就是一个需要关注的指标了;而在移动端,我们可能更加的聚焦于性能和体验,那么页面是否有横向滚动条就是一个需要关注的指标了。
如何去收集这些指标信息呢?答案就在 Lighthouse 的 Gatherers 模块。
每一个 gatherer 都继承自相同的父类 Gatherer,其中定义了三个模板方法,子类只需实现关心的模板方法即可

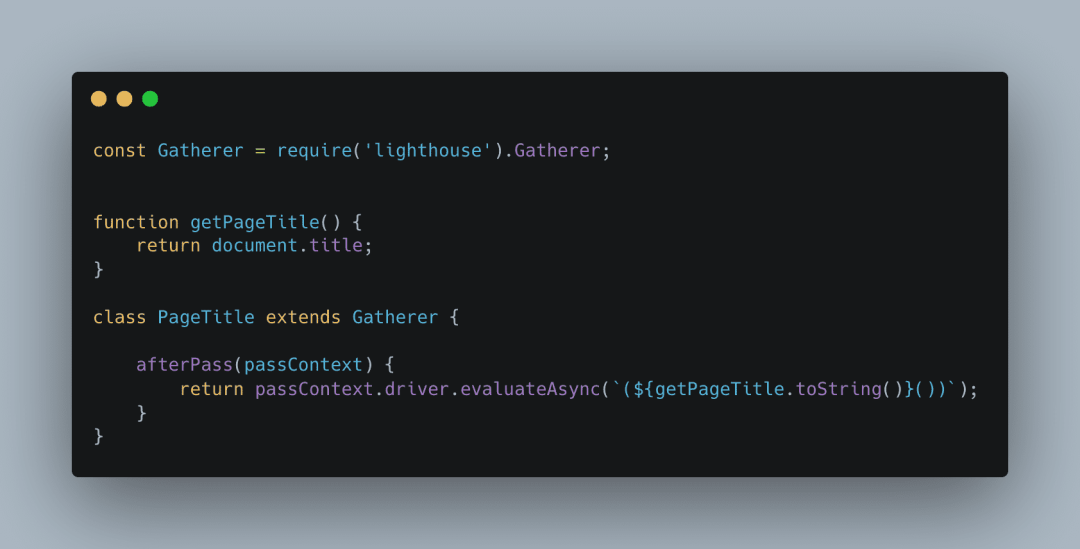
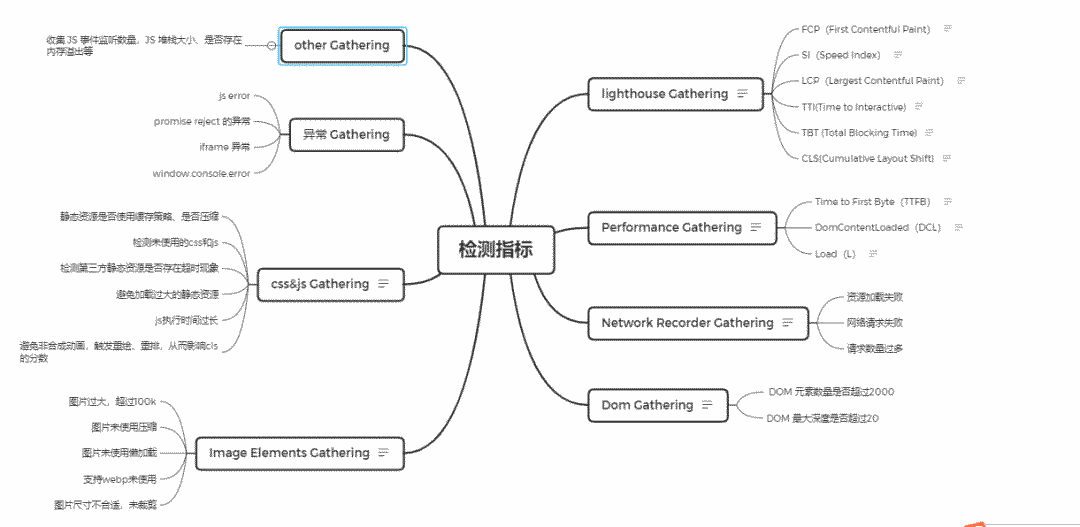
转转初版检测模型如下
平台化
这个可以根据各自公司的 CI/CD 工具进行集成,在部署服务的时候调用一下检测接口,最后将报告输出的 json 数据进行入库操作即可
赋能业务
开发完这个检测平台,想的第一件事就是如何同业务相结合。当时正值公司 618 大促,运营人员使用公司内部的魔方系统搭建活动页的需求较多,所以专门针对魔方业务制定了一套检测模型。
魔方系统主要以图文展示为主,所以重点就放在图片的布局偏移、大小、数量以及错别字检测等维度

总结
检测平台作为一个辅助性的检测系统,当制定好相关的检测模型后,能方便大家快速定位到性能问题。目前我们也是在探索实验阶段,有感兴趣的同学可以互相交流学习。
参考:
lighthouse 官网
为什么性能如此重要
蚂蚁金服如何把前端性能监控做到极致?
如何从 0 到 1 搭建性能检测系统