MySQL如何优化无索引的join
MySQL Join 你用过吗?你知道其中的原理吗?
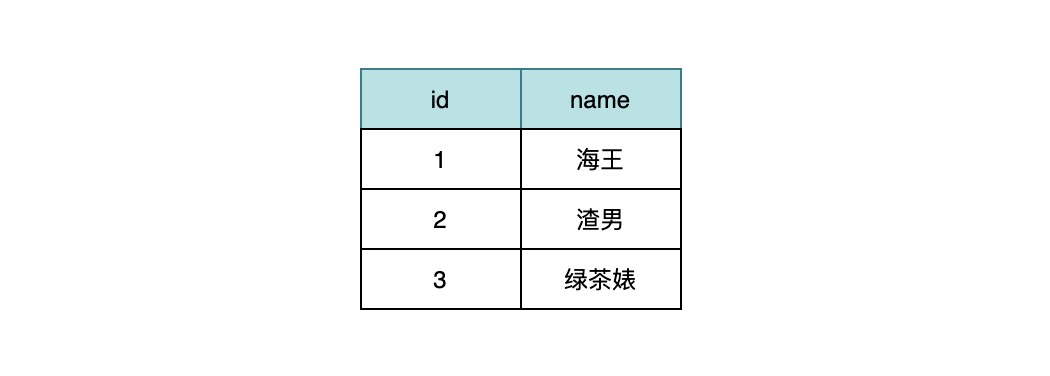
现在有张 user 表,这个 user 表很简单,一个主键 id,也就是我们的用户 id,还有个 name 字段,很明显就是用户的姓名。
遍历循环查询
如果要查出所有用户的姓名和存款,我们可以这样查:
data = select * from user;
for (i=0;i<len(data);i++) {
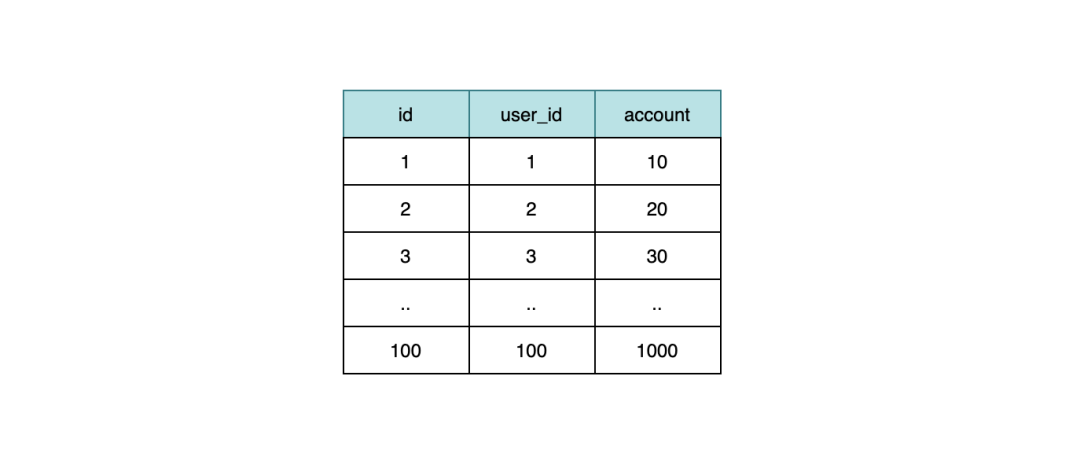
info = select account from user_info where user_id= data[i].user_id
}这种方式最直观,先通过 user 表拿到所有的用户信息,然后根据连接键 user_id 去 user_info 表里查询对应的 account,这样就能得到想要的数据,但是这种方式几个问题:
- 第一次全表扫描 user 表需要一次网络通信,假设 user 表的数据量是n。
- 然后循环查询 user_info 表,这里需要 n 次网络通信
因此一共需要 n+1 次网络通信,如果使用的是长连接,还能省去 3 次握手的时间,如果是短连接,整体的开销会更大。
其次如果 user_id 没有索引,那么整体更伤,假设 user_info 一共有 m 条数据,那么扫描的次数是怎么算的呢?
- 首先 user 表是全表扫,一共需要查询 n 次。
- 由于 user_info 表的 user_id 没有索引,那么每次查询等于都是全表扫,总共需要 n*m 次。
因此这种查询的方式一共需要扫描 n+n*m 次。当然一般不会出现 user_id 没有索引的情况,在 user_id 有索引的时候,可以根据索引快速定位到我们的目标数据,并不需要全表扫描,因此总共需要扫描的行数为 n+m 次。
join 查询
一般对于这种情况的查询,我们会用 join 来做,于是我们的 sql 或许如下:
select a.name,b.account from user a left join user_info b on a.id=b.user_id
首先从网络通信上来说,总体只需要一次通信,至于 MySQL 内部怎么处理数据,怎么把我们想要的数据返回回来是它内部的事。
其次我们来看看这种 join 方式的原理:
- 从 user 表扫描一条数据,然后去 user_info 表中匹配
- 在连接键 user_id 有索引的情况下,可以利用索引快速匹配
- 然后把 user 表中的 name 和 user_info 表中的 account 作为结果集的一部分返回回去
- 重复 1-3 步骤,直至 user 表扫描完毕,数据全部返回。
其中第三步骤,每次组合一条数据的时候,并不是立马返回给客户端,这样效率太低,其实是有缓冲区的,也就是先把数据放在缓冲区中,等缓冲区满了,一次性响应给客户端可以大大提升效率。
从原理来看和上面的遍历查询差不多,主要不同的是,客户端不需要和服务端多次通信。
join buffer (Block Nested Loop)
以上说的还是连接键有索引的,我们来看看连接键没有索引的情况,这时候你通过 explain 来看 MySQL 的执行计划,你会发现其中 user_info 的 extra 字段中会提示这个:
Using where; Using join buffer (Block Nested Loop)
这是什么意思呢?
因为没有索引,所以每次去 user 表得到一条数据的时候,肯定是要再到 user_info 表做全表扫描,这个扫描的成本我们上面也提到了,就是 n+n*m=n(1+m),因此这个时间复杂度是和 n 成正比的,这也是为什么我们一般推荐「小表驱动大表」的方式。
但是如果我们按照这个方式来做 join,未免开销太大了,太耗时了,于是还是沿用老套路,也就是用个临时存储区,也就是 extra 中的 join buffer,有了这个 join buffer 后,首先会把 user 表的数据放进去,然后扫描 user_info 表,每扫描一行数据,就和 join buffer 中的每一行 user 数据匹配,如果匹配上了,也就是我们要的结果,因为 user_info 表有 m 条数据,因此需要判断 n*m 次,咦!这个也没减少呀,还是和上面的一样。其实不一样,这里的 m 条数据其实每次都是和内存中的 n 条数据做匹配的,并非磁盘,内存的速度不用多说。
聪明的读者可能会发现,如果 user 表的数据很多,join buffer 能放得下吗?
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+buffer 默认是 256K,多的话确实放不下,放不下的话,怎么办?其实也很简单,分段放即可,当读 user 表的数据占满 buffer 的时候,就不放了,然后直接和 user_info 做匹配,逻辑还是同上,在 buffer 的数据处理完之后,就清空它,接着上次的位置继续读入数据,再次重复同样的逻辑,直至数据读完。
虽说连接键没有索引的时候,会通过 join buffer 来优化速度,但是现实中,还是建议大家尽量要保证连接键有索引。