浅析TypeScript Compiler 原理
前言
众所周知,JavaScript是一款弱类型语言,变量的类型是在运行时动态决定的,2012年微软推出的typescript 给 javascript 扩展了类型的语法和语义,为JavaScript提供了静态检查的能力,这样能够提前发现类型不匹配的错误,还能够在开发时提示可用的属性方法,更利于大型项目的开发和维护。
那么TypeScript它究竟是如何工作的呢,这就要涉及TypeScript 编译器的相关原理了!
关键部分
-
Scanner扫描器:词法分析,生成token流
-
Parser解析器:生成AST
-
Binder绑定器:创建Symbol关联AST,形成语义
-
Checker检查器:类型检查
-
Emitter发射器:输出编译后的文件
处理流程
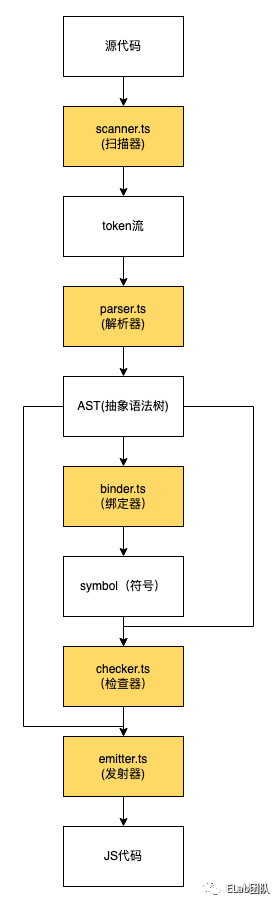
1 . 对于源代码,TS首先对它进行词法分析,通过scanner进行逐词扫描,生成token流
2 . 对于scanner生成的token,parser会对其进行组装并生成一棵AST
3 . binder会生成symbol(符号),并为AST上的每一个节点绑上相应的symbol
4 . checker检查处理后的AST,利用其进行语法检查
5 . emitter根据最终的AST生成JS代码和声明文件(d.ts)
scanner扫描器
什么是token
这里的token和平时前端使用的token并不是一个东西,此处的token实际上是一个标记。scanner会对源代码进行词法分析,根据每个“词”生成不同类别的标记(token),实质上是对“词”的一个分类过程。
例如const a = 1;这行代码,里面有const关键字,有变量a,有数字1,有结束标志;。这些每个都可以生成一个token,只是类别不同罢了。
TS compiler内部是将token的所有类型枚举出来了,在type.ts中可以找到,使用 SyntaxKind 存储标记类型(SyntaxKind 本质是numebr,比较起来性能更高)。
实际上,SyntaxKind不仅存储着token的类型,还存储了AST节点的类型,这个将于parser中用到。
export const enum SyntaxKind {
Unknown,
EndOfFileToken,
SingleLineCommentTrivia,
MultiLineCommentTrivia,
NewLineTrivia,
WhitespaceTrivia,
ShebangTrivia, more pleasant manner.
ConflictMarkerTrivia,
NumericLiteral,
BigIntLiteral,
StringLiteral,
JsxText,
JsxTextAllWhiteSpaces,
//...(more)
}字符处理
在介绍scanner的工作流程之前,我想先跟大家介绍几个scanner中关于字符处理的函数。scanner所做的工作实质上就是词法分析的工作,因此免不了对源代码进行字符的合法性处理、位置判断等等。
CharacterCodes
export const enum CharacterCodes {
_ = 0x5F,
$ = 0x24,
_0 = 0x30,
_1 = 0x31,
_2 = 0x32,
_3 = 0x33,
_4 = 0x34,
_5 = 0x35,
_6 = 0x36,
_7 = 0x37,
_8 = 0x38,
_9 = 0x39,
a = 0x61,
b = 0x62,
c = 0x63,
d = 0x64,
e = 0x65,
f = 0x66,
g = 0x67,
h = 0x68,
//...(more)
}TS compiler的编译也是参照unicode编码表的。在type.ts中,通过枚举的方式将unicode中的所有编码列举出来,为什么要这么做呢?如果我们直接使用0x5F这样一个16进制数字,我们不能直观的理解这是什么字符。通过枚举的方式,我们可以直接通过类如CharacterCodes.a的方式获取相应的unicode值。
字符判断
scanner中大部分的字符判断都是基于CharacterCodes的。
判断是否是空格
export function isWhiteSpaceLike(ch: number): boolean {
return isWhiteSpaceSingleLine(ch) || isLineBreak(ch);
}判断是否是换行符
export function isLineBreak(ch: number): boolean {
// ES5 7.3:
// The ECMAScript line terminator characters are listed in Table 3.
// Table 3: Line Terminator Characters
// Code Unit Value Name Formal Name
// \u000A Line Feed <LF>
// \u000D Carriage Return <CR>
// \u2028 Line separator <LS>
// \u2029 Paragraph separator <PS>
// Only the characters in Table 3 are treated as line terminators. Other new line or line
// breaking characters are treated as white space but not as line terminators.
return ch === CharacterCodes.lineFeed ||
ch === CharacterCodes.carriageReturn ||
ch === CharacterCodes.lineSeparator ||
ch === CharacterCodes.paragraphSeparator;
}判断是否是数字
function isDigit(ch: number): boolean {
return ch >= CharacterCodes._0 && ch <= CharacterCodes._9;
}除了这些,sanner中还有不少对于字符判断的函数,这里就不一一列举,有兴趣的同学可以自行查看源码。
标识符(Identifier)判断
标识符的判断比字符判断稍微复杂一些,TS compiler 分别用 isUnicodeIdentifierStart 和 isUnicodeIdentifierPart 两个函数分别判断字符是否可以可以作为标识符开头、字符是否可以作为标识符。
/* @internal */ export function isUnicodeIdentifierStart(code: number, languageVersion: ScriptTarget | undefined) {
return languageVersion! >= ScriptTarget.ES2015 ?
lookupInUnicodeMap(code, unicodeESNextIdentifierStart) :
languageVersion === ScriptTarget.ES5 ? lookupInUnicodeMap(code, unicodeES5IdentifierStart) :
lookupInUnicodeMap(code, unicodeES3IdentifierStart);
}
function isUnicodeIdentifierPart(code: number, languageVersion: ScriptTarget | undefined) {
return languageVersion! >= ScriptTarget.ES2015 ?
lookupInUnicodeMap(code, unicodeESNextIdentifierPart) :
languageVersion === ScriptTarget.ES5 ? lookupInUnicodeMap(code, unicodeES5IdentifierPart) :
lookupInUnicodeMap(code, unicodeES3IdentifierPart);
}可以作为标识符的字符并没有比较通用的规律,ES规范中也是一个个手动指定的,判断是否字符是否能做标识符的基本实现是:记录允许做标识符的字符,然后查表。
而不难发现,其实除了一些特定的符号,大部分可以作为标识符的字符在unicode编码表中都是连续的,如A-Z,如下图所示
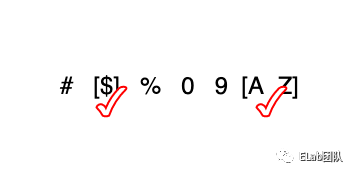
const unicodeESNextIdentifierStart = [65, 90, 97, 122, 170, 170/*...(more)*/ ]
const unicodeESNextIdentifierPart = [48, 57, 65, 90, 95/*...(more)*/ ]scanner中用数组的形式记录下可以作为标识符的合法字符段的位置,如65是A在unicode编码表的位置,90是 Z在unicode编码表的位置,数组的奇数位记录合法字符段的开始位置,偶数位记录合法字符段的结束位置。只记录每段的开头和结尾部分,比记录该段的所有字符更节约内存。
当需要查找一个字符是否符合标识符规范时,采用折半查找法查找即可。
function lookupInUnicodeMap(code: number, map: readonly number[]): boolean {
// Bail out quickly if it couldn't possibly be in the map.
if (code < map[0]) {
return false;
}
// Perform binary search in one of the Unicode range maps
let lo = 0;
let hi: number = map.length;
let mid: number;
while (lo + 1 < hi) {
mid = lo + (hi - lo) / 2;
// mid has to be even to catch a range's beginning
mid -= mid % 2;
if (map[mid] <= code && code <= map[mid + 1]) {
return true;
}
if (code < map[mid]) {
hi = mid;
}
else {
lo = mid + 2;
}
}
return false;
}索引
一般来说,要记录一个字符的位置有两种方式,一是记录一个字符的索引,二是记录一个字符的行列信息。若存储索引信息,只需要一个字段便可,输出时需要计算索引之前有多少个换行符,从而得到行列信息;若存储行列信息,则代表需要用两个字段存储信息,二者各有优劣。
TS compiler采用存储索引信息的方式,并做了一定的优化:记录每一行第一个字符的索引,使索引转换为行列信息时更高效。
计算每一行第一个字符的索引,建立索引表
export function computeLineStarts(text: string): number[] {
const result: number[] = new Array();
let pos = 0;
let lineStart = 0;
while (pos < text.length) {
const ch = text.charCodeAt(pos);
pos++;
switch (ch) {
case CharacterCodes.carriageReturn:
if (text.charCodeAt(pos) === CharacterCodes.lineFeed) {
pos++;
}
// falls through
case CharacterCodes.lineFeed:
result.push(lineStart);
lineStart = pos;
break;
default:
if (ch > CharacterCodes.maxAsciiCharacter && isLineBreak(ch)) {
result.push(lineStart);
lineStart = pos;
}
break;
}
}
result.push(lineStart);
return result;
}通过索引表查询行列号
export function computePositionOfLineAndCharacter(lineStarts: readonly number[], line: number, character: number, debugText?: string, allowEdits?: true): number {
if (line < 0 || line >= lineStarts.length) {
if (allowEdits) {
// Clamp line to nearest allowable value
line = line < 0 ? 0 : line >= lineStarts.length ? lineStarts.length - 1 : line;
}
else {
Debug.fail(`Bad line number. Line: ${line}, lineStarts.length: ${lineStarts.length} , line map is correct? ${debugText !== undefined ? arraysEqual(lineStarts, computeLineStarts(debugText)) : "unknown"}`);
}
}
const res = lineStarts[line] + character;
if (allowEdits) {
// Clamp to nearest allowable values to allow the underlying to be edited without crashing (accuracy is lost, instead)
// TODO: Somehow track edits between file as it was during the creation of sourcemap we have and the current file and
// apply them to the computed position to improve accuracy
return res > lineStarts[line + 1] ? lineStarts[line + 1] : typeof debugText === "string" && res > debugText.length ? debugText.length : res;
}
if (line < lineStarts.length - 1) {
Debug.assert(res < lineStarts[line + 1]);
}
else if (debugText !== undefined) {
Debug.assert(res <= debugText.length); // Allow single character overflow for trailing newline
}
return res;
}主体流程
一份源代码有可能会解析出成千上万的token,如果将全部token都保存的话会占用大量的内存。就像大家看书的方式一样,大家只需要专注于眼前的一行文字就可以,而无需读入整篇文章再理解其中的意思。
TS compiler采用的扫描方式是逐个扫描。scanner设置了一个全局变量来存储token,每调用一次扫描函数(scan()),变量的值便会更新为下一个token的信息,你可以从变量中获取当前token的信息,然后再调用一次scan(),逐个获取token的信息。

function scan(): SyntaxKind {
startPos = pos; // 记录扫描之前的位置
while (true) {
// 这是一个大循环
// 如果发现空格、注释,会重新循环(此时重新设置 tokenPos,即让 tokenPos 忽略了空格)
// 如果发现一个标记,则退出函数
tokenPos = pos;
// 到字符串末尾,返回结束的token
if (pos >= end) {
return token = SyntaxKind.EndOfFileToken;
}
// 获取当前字符的编码
let ch = codePointAt(text, pos);
switch (ch) {
// 接下来就开始判断不同的字符可能并组装token
case CharacterCodes.exclamation:
if (text.charCodeAt(pos + 1) === CharacterCodes.equals) { // 后面是不是“=”
if (text.charCodeAt(pos + 2) === CharacterCodes.equals) { // 后面是不是还是“=”
return pos += 3, token = SyntaxKind.ExclamationEqualsEqualsToken; // 获得“!==”token
}
return pos += 2, token = SyntaxKind.ExclamationEqualsToken; // 获得“!=”token
}
pos++;
return token = SyntaxKind.ExclamationToken; //获得“!”token
case CharacterCodes.doubleQuote:
case CharacterCodes.singleQuote:
// ...(略)
}
}
}scan函数400多行代码,其实做的工作逻辑也比较简单:扫描字符串,判断不同的字符串组装不同的token。
parser解析器
源代码本质上只是一些文本,若想要进行类型检查或者转换成JS代码,将源代码转换成一种有组织性的数据结构是必不可少的,AST是比较好的选择,既能在节点中存储需要的信息,也可以很好的表示各个节点的从属关系。
主体流程
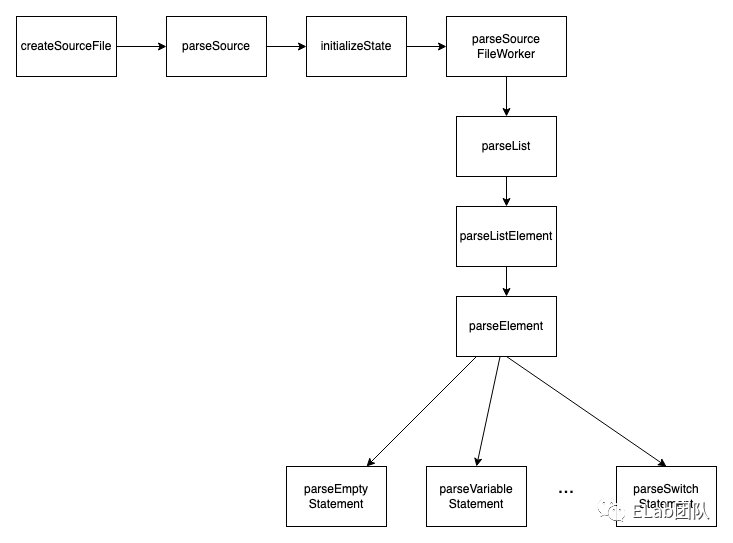
其中的核心函数是parseSourceFileWorker
function parseSourceFileWorker(languageVersion: ScriptTarget, setParentNodes: boolean, scriptKind: ScriptKind): SourceFile {
const isDeclarationFile = isDeclarationFileName(fileName);
if (isDeclarationFile) {
contextFlags |= NodeFlags.Ambient;
}
sourceFlags = contextFlags;
// 扫描
nextToken();
//解析token,生成node
const statements = parseList(ParsingContext.SourceElements, parseStatement);
Debug.assert(token() === SyntaxKind.EndOfFileToken);
const endOfFileToken = addJSDocComment(parseTokenNode<EndOfFileToken>());
//创建AST
const sourceFile = createSourceFile(fileName, languageVersion, scriptKind, isDeclarationFile, statements, endOfFileToken, sourceFlags);
// ...(more)
return sourceFile;
function reportPragmaDiagnostic(pos: number, end: number, diagnostic: DiagnosticMessage) {
parseDiagnostics.push(createDetachedDiagnostic(fileName, pos, end, diagnostic));
}
}大致流程是这样的:
-
nextToken()函数执行了一次扫描,新的token取代旧的token进行解析。 -
parseList函数进行解析,可以看到parseList的第二个参数传了parseStatement这个函数,这个函数其实是真正的核心执行函数:根据token的类别创建node节点。
node节点创建
让我先来看看一个node节点中都包含着什么信息,一个node节点包含的基础信息可以在TS compiler的types.ts中找到相关的定义。可以看到,包含着pos(在源代码中的开始位置)、end(在源代码中的结束位置)、kind(节点类型,定义于SyntaxKind中)等基础信息
export interface ReadonlyTextRange {
readonly pos: number;
readonly end: number;
}
export interface Node extends ReadonlyTextRange {
readonly kind: SyntaxKind;
readonly flags: NodeFlags;
/* @internal */ modifierFlagsCache: ModifierFlags;
/* @internal */ readonly transformFlags: TransformFlags; // Flags for transforms
readonly decorators?: NodeArray<Decorator>; // Array of decorators (in document order)
readonly modifiers?: ModifiersArray; // Array of modifiers
/* @internal */ id?: NodeId; // Unique id (used to look up NodeLinks)
readonly parent: Node; // Parent node (initialized by binding)
/* @internal */ original?: Node; // The original node if this is an updated node.
/* @internal */ symbol: Symbol; // Symbol declared by node (initialized by binding)
/* @internal */ locals?: SymbolTable; // Locals associated with node (initialized by binding)
/* @internal */ nextContainer?: Node; // Next container in declaration order (initialized by binding)
/* @internal */ localSymbol?: Symbol; // Local symbol declared by node (initialized by binding only for exported nodes)
/* @internal */ flowNode?: FlowNode; // Associated FlowNode (initialized by binding)
/* @internal */ emitNode?: EmitNode; // Associated EmitNode (initialized by transforms)
/* @internal */ contextualType?: Type; // Used to temporarily assign a contextual type during overload resolution
/* @internal */ inferenceContext?: InferenceContext; // Inference context for contextual type
}我们拿parseVariableStatement举例看看node节点的创建
function parseVariableStatement(pos: number, hasJSDoc: boolean, decorators: NodeArray<Decorator> | undefined, modifiers: NodeArray<Modifier> | undefined): VariableStatement {
//生成节点描述信息
const declarationList = parseVariableDeclarationList(/*inForStatementInitializer*/ false);
//解析分号
parseSemicolon();
//创建节点
const node = factory.createVariableStatement(modifiers, declarationList);
// Decorators are not allowed on a variable statement, so we keep track of them to report them in the grammar checker.
node.decorators = decorators;
//添加节点边界信息
return withJSDoc(finishNode(node, pos), hasJSDoc);
}parseVariableDeclarationList生成节点的一些描述信息,如kind、parent等等,将描述信息作为参数传入createVariableStatement中,生成node节点,最后再调用finishNode函数,为node添加range信息(pos、end)
function createVariableStatement(modifiers: readonly Modifier[] | undefined, declarationList: VariableDeclarationList | readonly VariableDeclaration[]) {
const node = createBaseDeclaration<VariableStatement>(SyntaxKind.VariableStatement, /*decorators*/ undefined, modifiers);
node.declarationList = isArray(declarationList) ? createVariableDeclarationList(declarationList) : declarationList;
node.transformFlags |=
propagateChildFlags(node.declarationList);
if (modifiersToFlags(node.modifiers) & ModifierFlags.Ambient) {
node.transformFlags = TransformFlags.ContainsTypeScript;
}
return node;
}binder绑定器
binder的主要工作是创建符号(symbol变量,与ES6的symbol没有关系),并且把符号与AST上的节点关联起来。
符号(symbol)
当我们初次定义一个变量、函数或类时,binder会为其创建一个符号(其实符号就是一个标识符的唯一标识),binder会先将所有的符号收集起来,建立符号表。当在其他地方使用一个名称(例如变量)时,就查表找出这个名称所代表的符号。
binder调用了如下的Symbol函数,初始化了一个符号的信息,其中SymbolFlags符号标志是个标志枚举,用于识别符号类别(例如:变量作用域标志 FunctionScopedVariable 或 BlockScopedVariable 等)。
function Symbol(this: Symbol, flags: SymbolFlags, name: __String) {
this.flags = flags;
this.escapedName = name;
this.declarations = undefined;
this.valueDeclaration = undefined;
this.id = undefined;
this.mergeId = undefined;
this.parent = undefined;
}主体流程
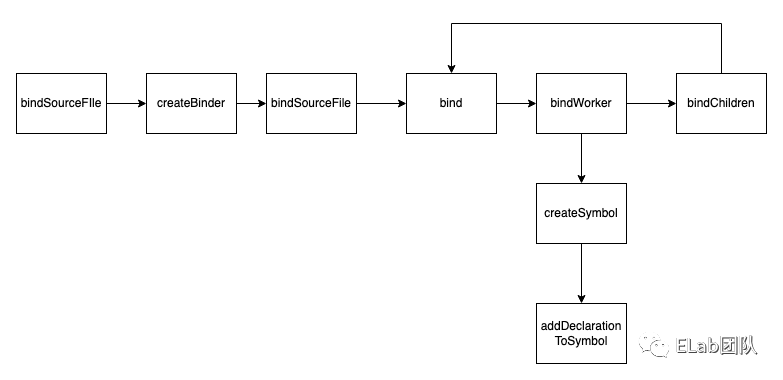
-
bindWorker:根据节点的kind分发不同的bindXXX函数 -
createSymbol:创建符号 -
addDeclarationToSymbol:为node节点添加声明
function bind(node: Node | undefined): void {
if (!node) {
return;
}
//设置父节点
setParent(node, parent);
const saveInStrictMode = inStrictMode;
bindWorker(node);
if (node.kind > SyntaxKind.LastToken) {
const saveParent = parent;
parent = node;
const containerFlags = getContainerFlags(node);
if (containerFlags === ContainerFlags.None) {
//对子节点进行绑定
bindChildren(node);
}
// ...(more)
}bind函数先设置当前节点的父节点信息,紧接着执行bindWorker,根据不同的节点调用与之对应的绑定函数 最后调用bindChildren, 对当前节点的每个子节点进行一一绑定, bindChildren内部也是通过递归调用bind 对每一个节点进行绑定。
在不同的bindXXX函数中,其中的核心函数是declareSymbol(declareModuleMember函数内部其实也是调用了declareSymbol方法)
function declareSymbol(symbolTable: SymbolTable, parent: Symbol | undefined, node: Declaration, includes: SymbolFlags, excludes: SymbolFlags, isReplaceableByMethod?: boolean, isComputedName?: boolean): Symbol {
Debug.assert(isComputedName || !hasDynamicName(node));
const isDefaultExport = hasSyntacticModifier(node, ModifierFlags.Default) || isExportSpecifier(node) && node.name.escapedText === "default";
const name = isComputedName ? InternalSymbolName.Computed
: isDefaultExport && parent ? InternalSymbolName.Default
: getDeclarationName(node);
let symbol: Symbol | undefined;
if (name === undefined) {
symbol = createSymbol(SymbolFlags.None, InternalSymbolName.Missing);
}
else {
symbol = symbolTable.get(name);
if (includes & SymbolFlags.Classifiable) {
classifiableNames.add(name);
}
if (!symbol) {
symbolTable.set(name, symbol = createSymbol(SymbolFlags.None, name));
if (isReplaceableByMethod) symbol.isReplaceableByMethod = true;
}
//...(more)
}
addDeclarationToSymbol(symbol, node, includes);
//...(more)
return symbol;
}需要说明的是binder中会维护符号表,在declareSymbol函数中,会判断符号表中是否有同名的符号,若没有的话,创建新的符号并加入符号表中;有的话就会直接从符号表中取出符号信息。接下来是调用addDeclarationToSymbol函数,这个函数主要进行两个工作:1.创建 AST 节点到 symbol 的连接 ( node.symbol = symbol;) 2. 为符号添加一个关于节点的声明(symbol.declarations = appendIfUnique(symbol.declarations, ``node``))
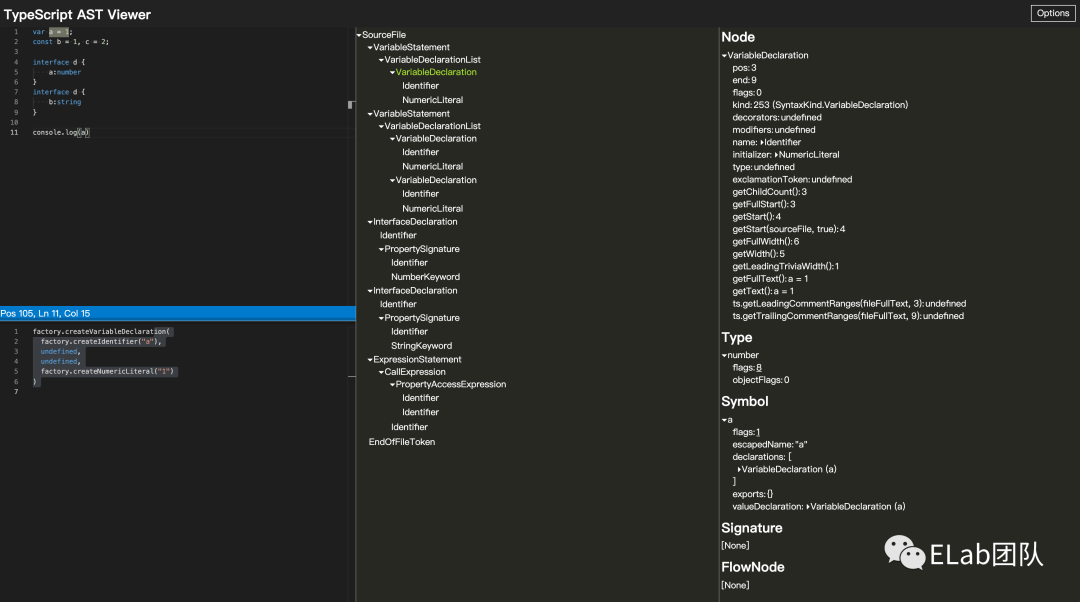
夹带私货:TypeScript AST Viewer
这里夹带一下私货,给大家推荐一个非常好用的网站:TypeScript ASTViewer (ts-ast-viewer.com)[1]
checker检查器
Checker部分的代码超过了4w行,是整个compiler中最重的部分,我也无法细细的读每一个细节,在此就对其流程做一个分析。
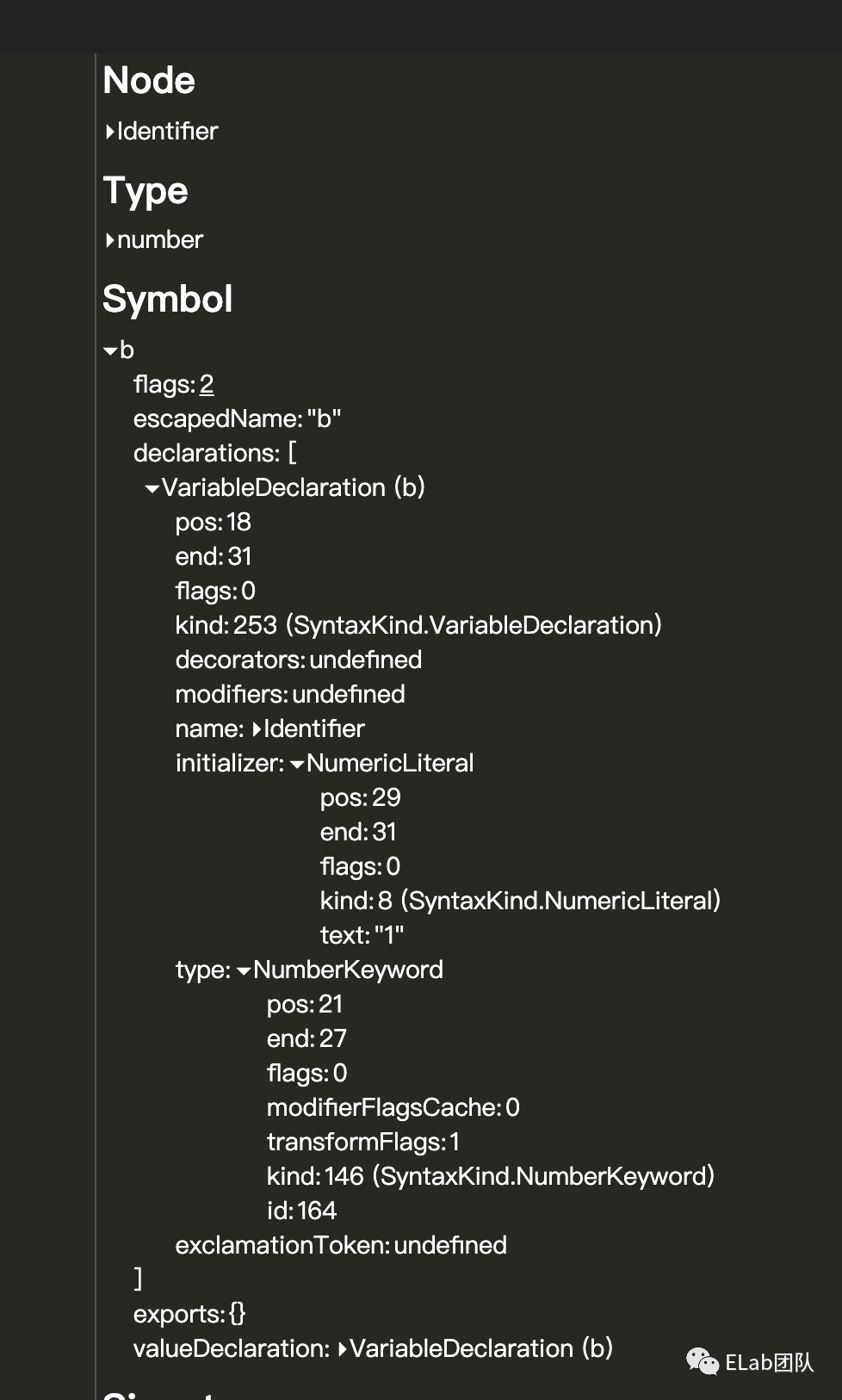
如何检查
例如const b:number = 1;这一行代码,在AST中的结构如下:

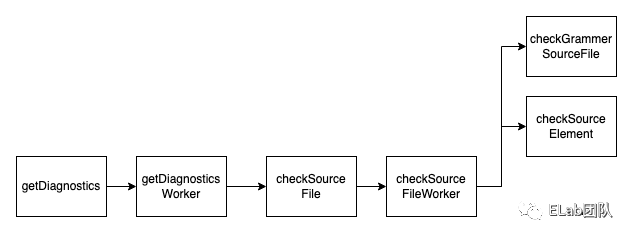
主体流程
function checkSourceFileWorker(node: SourceFile) {
const links = getNodeLinks(node);
if (!(links.flags & NodeCheckFlags.TypeChecked)) {
if (skipTypeChecking(node, compilerOptions, host)) {
return;
}
// 语法检查
checkGrammarSourceFile(node);
clear(potentialThisCollisions);
clear(potentialNewTargetCollisions);
clear(potentialWeakMapSetCollisions);
clear(potentialReflectCollisions);
//类型检查
forEach(node.statements, checkSourceElement);
checkSourceElement(node.endOfFileToken);
checkDeferredNodes(node);
if (isExternalOrCommonJsModule(node)) {
registerForUnusedIdentifiersCheck(node);
}
if (!node.isDeclarationFile && (compilerOptions.noUnusedLocals || compilerOptions.noUnusedParameters)) {
checkUnusedIdentifiers(getPotentiallyUnusedIdentifiers(node), (containingNode, kind, diag) => {
if (!containsParseError(containingNode) && unusedIsError(kind, !!(containingNode.flags & NodeFlags.Ambient))) {
diagnostics.add(diag);
}
});
}
// ...(more)
}我们发现在checkSourceFileWorker函数内有各种各样的check操作,先执行了checkGrammarSourceFile进行语法检查,后面执行checkSourceElement、checkDeferredNodes等才对具体的节点进行具体的语义检查。其中其实也是做了一个分发,根据node.kind来判断节点的类别,执行不同类型节点的检查函数。
function checkSourceElementWorker(node: Node): void {
if (isInJSFile(node)) {
forEach((node as JSDocContainer).jsDoc, ({ tags }) => forEach(tags, checkSourceElement));
}
const kind = node.kind;
// ...(more)
if (kind >= SyntaxKind.FirstStatement && kind <= SyntaxKind.LastStatement && node.flowNode && !isReachableFlowNode(node.flowNode)) {
errorOrSuggestion(compilerOptions.allowUnreachableCode === false, node, Diagnostics.Unreachable_code_detected);
}
//根据node类型执行不同的检查函数
switch (kind) {
case SyntaxKind.TypeParameter:
return checkTypeParameter(node as TypeParameterDeclaration);
case SyntaxKind.Parameter:
return checkParameter(node as ParameterDeclaration);
case SyntaxKind.PropertyDeclaration:
return checkPropertyDeclaration(node as PropertyDeclaration);
case SyntaxKind.PropertySignature:
return checkPropertySignature(node as PropertySignature);
//...(more)
}
}检查之后,通过error函数报告错误
function error(location: Node | undefined, message: DiagnosticMessage, arg0?: string | number, arg1?: string | number, arg2?: string | number, arg3?: string | number): Diagnostic {
//生成单条错误
const diagnostic = createError(location, message, arg0, arg1, arg2, arg3);
//加入错误报告中
diagnostics.add(diagnostic);
return diagnostic;
}export function createFileDiagnostic(file: SourceFile, start: number, length: number, message: DiagnosticMessage): DiagnosticWithLocation {
assertDiagnosticLocation(file, start, length);
let text = getLocaleSpecificMessage(message);
if (arguments.length > 4) {
text = formatStringFromArgs(text, arguments, 4);
}
return {
file,
start,
length,
messageText: text,
category: message.category,
code: message.code,
reportsUnnecessary: message.reportsUnnecessary,
reportsDeprecated: message.reportsDeprecated
};
}emitter发射器
发射器所做的事情主要是通过AST输出对应的JS代码以及声明文件(d.ts)
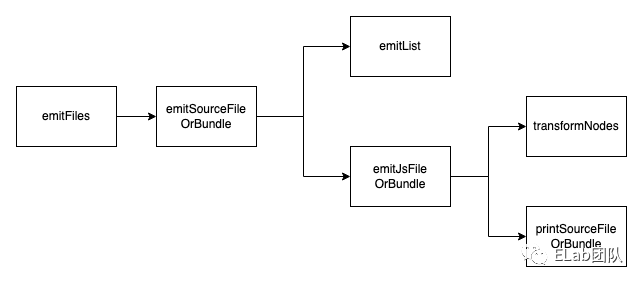
主体流程
Emitter的主要流程核心函数为emitFiles
export function emitFiles(resolver: EmitResolver, host: EmitHost, targetSourceFile: SourceFile | undefined, { scriptTransformers, declarationTransformers }: EmitTransformers, emitOnlyDtsFiles?: boolean, onlyBuildInfo?: boolean, forceDtsEmit?: boolean): EmitResult {
const compilerOptions = host.getCompilerOptions();
const sourceMapDataList: SourceMapEmitResult[] | undefined = (compilerOptions.sourceMap || compilerOptions.inlineSourceMap || getAreDeclarationMapsEnabled(compilerOptions)) ? [] : undefined;
const emittedFilesList: string[] | undefined = compilerOptions.listEmittedFiles ? [] : undefined;
const emitterDiagnostics = createDiagnosticCollection();
const newLine = getNewLineCharacter(compilerOptions, () => host.getNewLine());
const writer = createTextWriter(newLine);
const { enter, exit } = performance.createTimer("printTime", "beforePrint", "afterPrint");
let bundleBuildInfo: BundleBuildInfo | undefined;
let emitSkipped = false;
let exportedModulesFromDeclarationEmit: ExportedModulesFromDeclarationEmit | undefined;
// Emit each output file
enter();
forEachEmittedFile(
host,
emitSourceFileOrBundle,
getSourceFilesToEmit(host, targetSourceFile, forceDtsEmit),
forceDtsEmit,
onlyBuildInfo,
!targetSourceFile
);
exit();
return {
emitSkipped,
diagnostics: emitterDiagnostics.getDiagnostics(),
emittedFiles: emittedFilesList,
sourceMaps: sourceMapDataList,
exportedModulesFromDeclarationEmit
};可以看到这里创建了三个变量sourceMapDataList、emittedFilesList、emitterDiagnostics,这三个分别对应了需要输出的三种文件数据:sourceMap、JS代码和声明文件、类型检查的错误报告
function emitJsFileOrBundle(
sourceFileOrBundle: SourceFile | Bundle | undefined,
jsFilePath: string | undefined,
sourceMapFilePath: string | undefined,
relativeToBuildInfo: (path: string) => string) {
// ...(more)
// 将TS语法转换成js语法
const transform = transformNodes(resolver, host, factory, compilerOptions, [sourceFileOrBundle], scriptTransformers, /*allowDtsFiles*/ false);
// ...(more)
// 创建一个printer
const printer = createPrinter(printerOptions, {
// resolver hooks
hasGlobalName: resolver.hasGlobalName,
// transform hooks
onEmitNode: transform.emitNodeWithNotification,
isEmitNotificationEnabled: transform.isEmitNotificationEnabled,
substituteNode: transform.substituteNode,
});
Debug.assert(transform.transformed.length === 1, "Should only see one output from the transform");
// 输出JS文件
printSourceFileOrBundle(jsFilePath, sourceMapFilePath, transform.transformed[0], printer, compilerOptions);
// ...(more)
}再往深处找,发现了emitJsFileOrBundle与emitDeclarationFileOrBundle两个函数,一个用于输出JS代码,一个用于输出声明文件(d.ts)。我们看看emitJsFileOrBundle中的逻辑,可以看到做了两件事情:1.对每一个节点做了一次transform的操作,将TS语法转化为JS语法 。2.创建一个printer,调用printSourceFileOrBundle输出js文件。
总结
TypeScript Compiler的代码量其实非常大,内部的细节逻辑也挺复杂的,我分享的仅仅是其中的冰山一角,这都是因为TypeScript设计了一套比较完善的类型系统。这里给大家推荐篇论文,是一篇关于类型系统的入门介绍,如果对类型系统相关设计有兴趣的同学可以看一下: 类型系统[2]
最后是一点建议吧,建议初读TypeScript Compiler这部分源码的同学可以注重于摸清整个编译的流程,之后再慢慢研究其中的设计细节,否则巨大的代码量随时让人想弃坑
参考资料
[1]TypeScript-AST-Viewer (ts-ast-viewer.com): https://ts-ast-viewer.com
[2]类型系统: http://lucacardelli.name/papers/typesystems.pdf
❤️ 谢谢支持
以上便是本次分享的全部内容,希望对你有所帮助^_^