图解|Linux 组调度
在介绍 组调度 前,我们先来重温下什么是 进程调度。
本文基于 Linux-2.6.26 版本
什么是进程调度
一般来说,在操作系统中会运行多个进程(几个到几千个不等),但一台计算机的 CPU 资源是有限的,如 8 核的 CPU 只能同时运行 8 个进程。那么当进程数大于 CPU 核心数时,操作系统是如何同时运行这些进程的呢?
这里就涉及
进程调度问题。
操作系统运行进程的时候,是按 时间片 来运行的。时间片 是指一段很短的时间段(如20毫秒),操作系统会为每个进程分配一些时间片。当进程的时间片用完后,操作系统将会把当前运行的进程切换出去,然后从进程队列中选择一个合适的进程运行,这就是所谓的 进程调度。如下图所示:
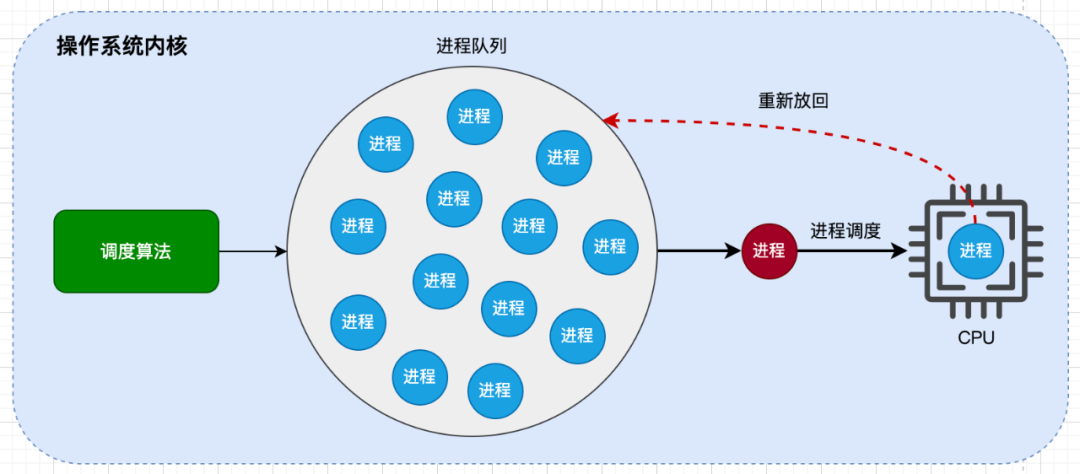
什么是组调度
一般来说,操作系统调度的实体是 进程,也就是说按进程作为单位来调度。但如果按进程作为调度实体,就会出现以下情况:
Linux 是一个支持多用户的操作系统,如果 A 用户运行了 10 个进程,而 B 用户只运行了 2 个进程,那么就会出现 A 用户使用的 CPU 时间是 B 用户的 5 倍。如果 A 用户和 B 用户都是花同样的钱来买的虚拟主机,那么对 B 用户来说是非常不公平的。
为了解决这个问题,Linux 实现了 组调度 这个功能。那么什么是 组调度 呢?
组调度 的实质是:调度时候不再以进程作为调度实体,而是以 进程组 作为调度实体。比如上面的例子,可以把 A 用户运行的进程划分为 进程组A,而 B 用户运行的进程划分为 进程组B。
调度的时候,进程组A 和 进程组B 分配到相同的可运行 时间片,如 进程组A 和 进程组B 各分配到 100 毫秒的可运行时间片。由于 进程组A 有 10 个进程,所以每个进程分配到的可运行时间片为 10 毫秒。而 进程组B 只有 2 个进程,所以每个进程分配到的可运行时间片为 50 毫秒。
下图是 组调度 的原理:
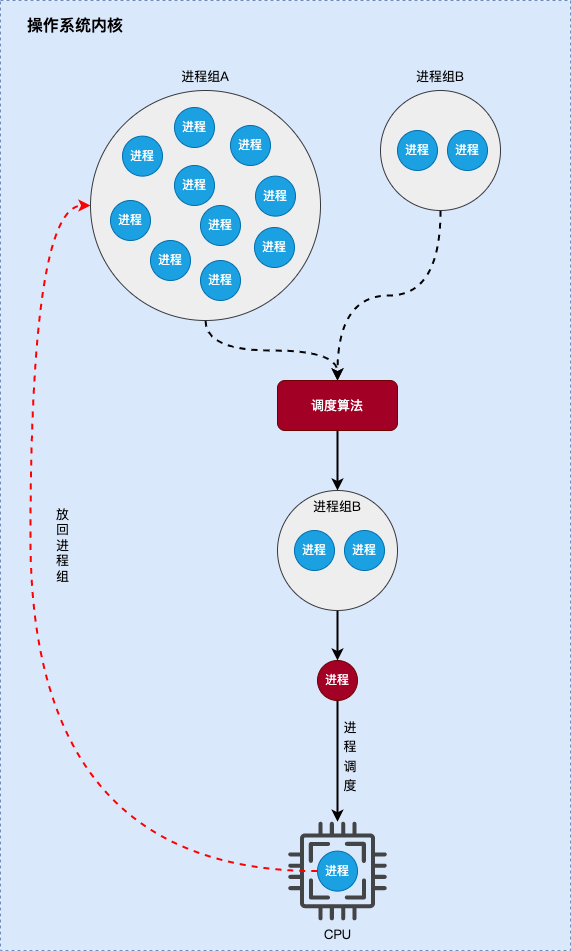
如上图所示,当内核进行调度时,首先以 进程组 作为调度实体。当选择出最优的 进程组 后,再从 进程组 中选择出最优的进程进行运行,而被切换出来的进程将会放置回原来的 进程组。
由于 组调度 是建立在 cgroup 机制之上的,而 cgroup 又是基于 虚拟文件系统,所以 进程组 是以树结构存在的。也就是说,进程组 除了可以包含进程,还可以包含进程组。如下图所示:
cgroup 相关的知识点可以参考文章:《[cgroup介绍] 》 和 《[cgroup实现原理] 》
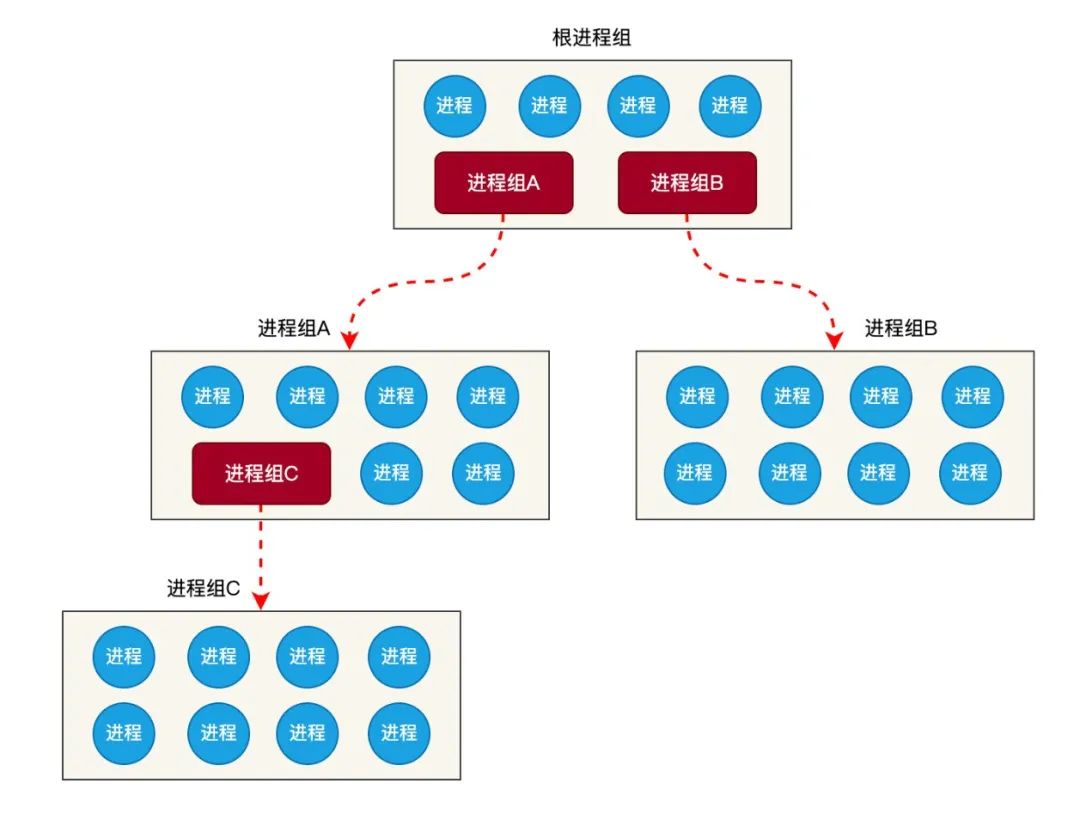
在 Linux 系统启动时,会创建一个根进程组 init_task_group。然后,我们可以通过使用 cgroup 的 CPU 子系统创建新的进程组,如下命令:
$ mkdir /sys/cgroup/cpu/A # 在根进程组中创建进程组A
$ mkdir /sys/cgroup/cpu/B # 在根进程组中创建进程组B
$ mkdir /sys/cgroup/cpu/A/C # 在进程组A中创建进程组C
$ echo 1923 > /sys/cgroup/cpu/A/cgroup.procs # 向进程组A中添加进程ID为1923的进程Linux 在调度的时候,首先会根据 完全公平调度算法 从根进程组中筛选出一个最优的进程或者进程组进行调度。
- 如果筛选出来的是进程,那么可以直接把当前运行的进程切换到筛选出来的进程运行即可。
- 如果筛选出来的是进程组,那么就继续根据
完全公平调度算法从进程组中筛选出一个最优的进程或者进程组进行调度(重复进行第一步操作),如此类推。
组调度实现
接下来,我们将介绍 组调度 是如何实现的。在分析之前,为了对 完全公平调度算法 有个大体了解,建议先看看这篇文章:《[Linux完全公平调度算法] 》。
1. 进程组
在 Linux 内核中,使用 task_group 结构表示一个进程组。其定义如下:
struct task_group {
struct cgroup_subsys_state css; // cgroup相关结构
struct sched_entity **se; // 调度实体(每个CPU分配一个)
struct cfs_rq **cfs_rq; // 完全公平调度运行队列(每个CPU分配一个)
unsigned long shares; // 当前进程组权重(用于获取时间片)
...
// 由于进程组支持嵌套, 也就是说进程组可以包含进程组
// 所以, 进程组可以通过下面3个成员组成一个树结构
struct task_group *parent; // 父进程组
struct list_head siblings; // 兄弟进程组
struct list_head children; // 子进程组
};下面介绍一下 task_group 结构各个字段的作用:
se:完全公平调度算法是以sched_entity结构作为调度实体(也就是说运行队列中的元素都是sched_entity结构),而sched_entity结构既能代表一个进程,也能代表一个进程组。这个字段主要作用是,将进程组放置到运行队列中进行调度。由于进程组中的进程可能会在不同的 CPU 上运行,所以这里为每个 CPU 分配一个sched_entity结构。cfs_rq:完全公平调度算法的运行队列。完全公平调度算法在调度时是通过cfs_rq结构完成的,cfs_rq结构使用一棵红黑树将需要调度的进程或者进程组组织起来,然后选择最左端的节点作为要运行的进程或进程组,详情可以参考文章:《[Linux完全公平调度算法] 》。由于进程组可能在不同的 CPU 上调度,所以进程组也为每个 CPU 分配一个运行队列。shares:进程组的权重,用于计算当前进程组的可运行时间片。parent、siblings、children:用于将系统中所有的进程组组成一棵亲属关系树。
task_group、sched_entity 和 cfs_rq 这三个结构的关系如下图所示:
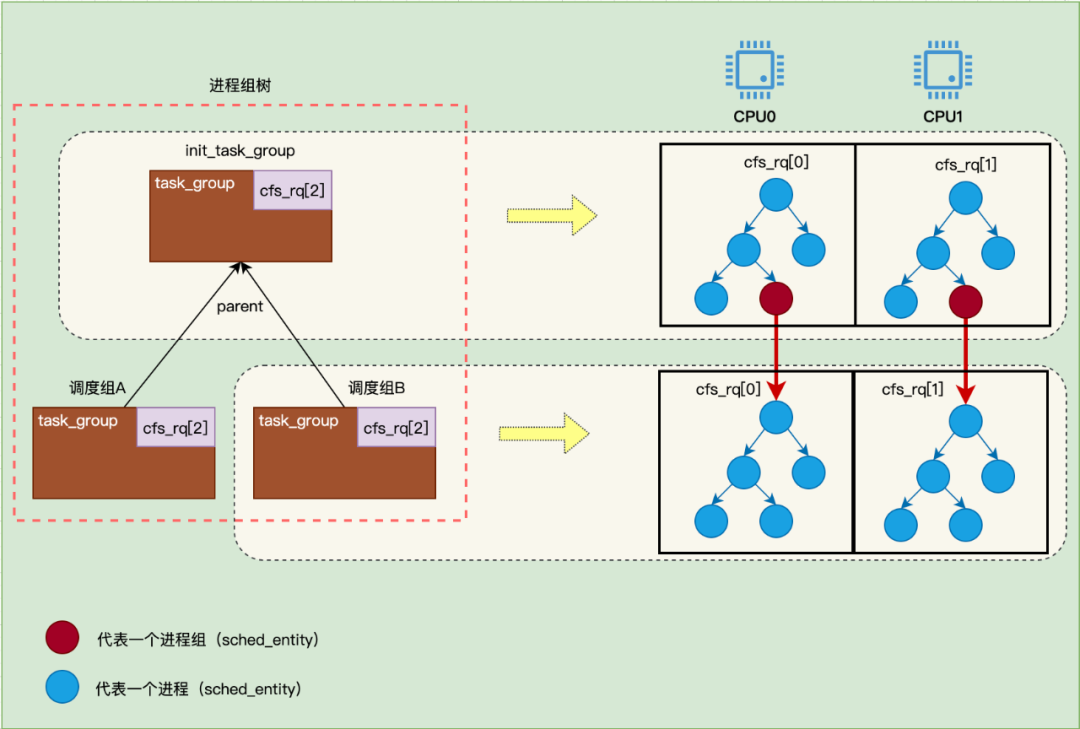
从上图可以看出,每个进程组都为每个 CPU 分配一个可运行队列,可运行队列中保存着可运行的进程和进程组。Linux 调度的时候,就是从上而下(从根进程组开始)地筛选出最优的进程进行运行。
2. 调度过程
当 Linux 需要进行进程调度时,会调用 schedule() 函数来完成,其实现如下(经精简后):
void __sched schedule(void)
{
struct task_struct *prev, *next;
struct rq *rq;
int cpu;
...
rq = cpu_rq(cpu); // 获取当前CPU的可运行队列
...
prev->sched_class->put_prev_task(rq, prev); // 把当前运行的进程放回到运行队列
next = pick_next_task(rq, prev); // 从可运行队列筛选一个最优的可运行的进程
if (likely(prev != next)) {
...
// 将旧进程切换到新进程
context_switch(rq, prev, next); /* unlocks the rq */
...
}
...
}schedule() 函数会调用 pick_next_task() 函数来筛选最优的可运行进程,我们来看看 pick_next_task() 函数的实现过程:
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev)
{
const struct sched_class *class;
struct task_struct *p;
// 如果所有进程都是使用完全公平调度
if (likely(rq->nr_running == rq->cfs.nr_running)) {
p = fair_sched_class.pick_next_task(rq);
if (likely(p))
return p;
}
...
}从 pick_next_task() 函数的实现来看,其最终会调用 完全公平调度算法 的 pick_next_task() 方法来完成筛选工作,我们来看看这个方法的实现:
static struct task_struct *pick_next_task_fair(struct rq *rq)
{
struct task_struct *p;
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
...
do {
se = pick_next_entity(cfs_rq); // 从可运行队列中获取最优的可运行实体
// 如果最优可运行实体是一个进程组,
// 那么将继续从进程组中获取到当前CPU对应的可运行队列
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se); // 最后一定会获取一个进程
...
return p; // 返回最优可运行进程
}我们来分析下 pick_next_task_fair() 函数到流程:
- 从根进程组中筛选出最优的可运行实体(进程或进程组)。
- 如果筛选出来的实体是进程,那么直接返回这个进程。
- 如果筛选出来的实体是进程组,那么将会继续对这个进程组中的可运行队列进行筛选,直至筛选出一个可运行的进程。
怎么区分
sched_entity实体是进程或者进程组?sched_entity结构中有个my_q的字段,当这个字段设置为 NULL 时,说明这个实体是一个进程。如果这个字段指向一个可运行队列时,说明这个实体是一个进程组。