微信Android增量Proguard方案
背景
随着业务的快速发展,Release构建速度问题不断凸显,从2020年底构建50min到如今接近1h30min的构建时长,其中Proguard阶段耗时占用了接近40%, 时刻影响着工作效率。在整个Release构建耗时链路上,业界优化方案众多,并起到了一定的优化效果。然而我们另辟蹊径,自研一套Inc-Proguard方案,解决了无法增量Proguard问题,实现将耗时降低到分钟级别。
问题出在哪?
目前Android微信采用模块化的Gradle构建方式,也是业界普遍采用的一种方式。大致构建流程如下:
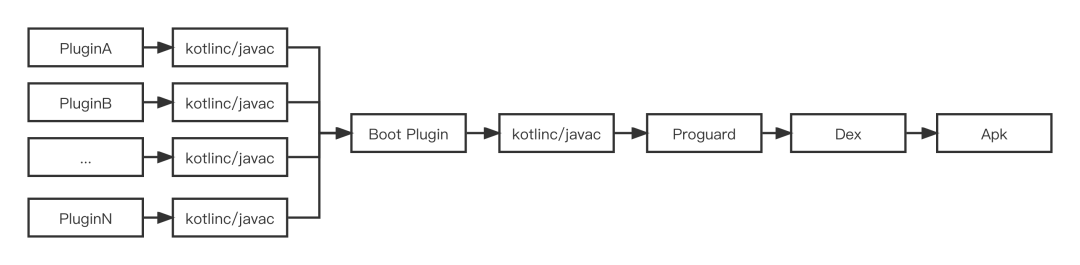
图1
上图可以看出每个Plugin都有可能并发Compile,执行到Boot Plugin时则需要串行Compile,最终经过Proguard、Dex等构建流程输出Apk, 而每个任务都会有相应的Gradle Task负责执行。
通过对Task进行耗时排序, 了解到Full Proguard(3 optimizationpasses) 平均需要40分钟【图2】,在有Apply Mapping情况下也要20分钟左右【图3】
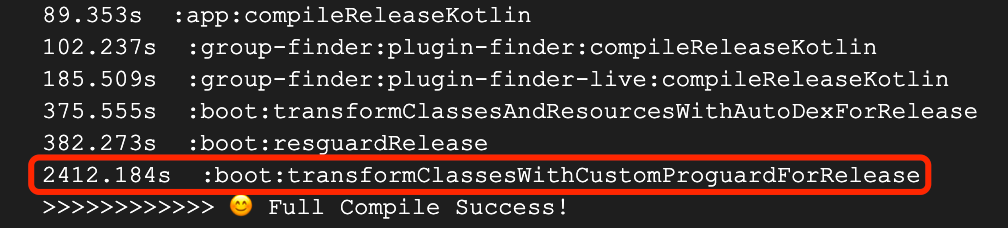
图2 Full Proguard

图4 Proguard部分流程
具体原因主要有几点:
- Proguard过程深度复杂【图4】,每个阶段都存在一定的耗时,比如Initialize、Shrink、Optimize、Obfuscated 阶段很难进行单点优化;
- 并发执行只存在Optimize阶段,对整体优化效果不明显【proguard.classfile.visitor.ParallelAllClassVisitor】;
- 代码膨胀;
- optimizationpasses次数;
- Proguard优化项选取;
考虑的优化方案:
- 一个最简单的优化方案就是通过减少Proguard Optimize 次数来改善耗时,但是会对Apk性能有比较大的影响,比如Dex数,包体积,启动性能等指标;
- 利用Gradle 增量策略将Incremental Input Jars 输入给Proguard进行增量混淆,亲测如果一旦Input Jars的Reference不完备,就很容易出现Warning导致Proguard失效,即便Proguard成功,也未必跟上次构建结果保持一致;
- 采用R8,但R8 的耗时优化也达不到我们预期目标,它不允许您停用或启用离散优化,也不允许您修改优化的行为,比如-optimizations 和 -optimizationpasses,这种黑盒的行为往往一旦出现了问题,高昂的维护成本也不容忽视;第三章节我们将进一步解释采用Proguard的原因;
- 从工程架构考虑,业务Feature层次明确,顺其自然的对Feature部分进行混淆即可,但这种方案也是需要工程架构进一步改造,约束规则,并没有解决根本问题;
综上,我们考虑到在日常开发构建过程中,往往提交的代码并不多,一次提交全量构建,属实恶劣,那能否针对增量修改的代码部分进行增量Proguard呢?答案是可行的!
为什么要采用Proguard?

图5 Proguard + D8

图6 R8
在R8出现之前,Proguard基本上配合Dx/D8使用,生成更小更快的Java字节码,然后交给Dx/D8生成Dalvik字节码【图5】,其中D8 比 dx 输出质量指令更少,寄存器分配更好的字节码。而 R8 【图6】是 D8 的衍生产品,旨在集成 ProGuard 和 D8 的功能,目前仍在优化中,逐渐成熟,具体查看QuardSquare官网[1]了解更多。对于微信,我们仍然使用Proguard,主要原因如下:
- Proguard优化项跟R8相似,R8在这方面没有明显的优势;
- Build Time R8 不比 Proguard快多少,在图1基础上采用R8方案则会快10分钟左右,由于两者优化目的不同,R8也包括的Dalvik字节码方面的内容,后续有可能增加耗时,其他原因上述也提到;
- Android微信针对dex的部分有自己的优化工作,主要目的是减少dex数量,对Tinker Patch大小也有一定帮助,有了自己的Dex优化,在将来的一段时间内我们仍然使用Proguard,这是主要原因;
下面重点介绍增量混淆核心工作:
增量混淆
先来看一下Proguard的大致输入输出流程:
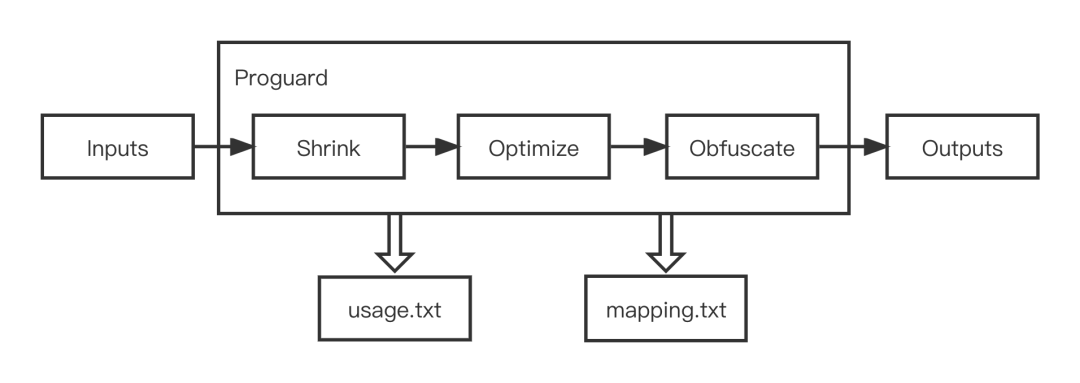
图7
Proguard输出两个产出文件 usage.txt 和 mapping.txt【图7】,usage.txt 是将无用Class、Field和Method进行删除,mapping.txt保留Class、Field和Method的original-obfucate class mapping、inline mapping【图8】,其中inline最为常见,也是Proguard难以增量的主要原因之一。
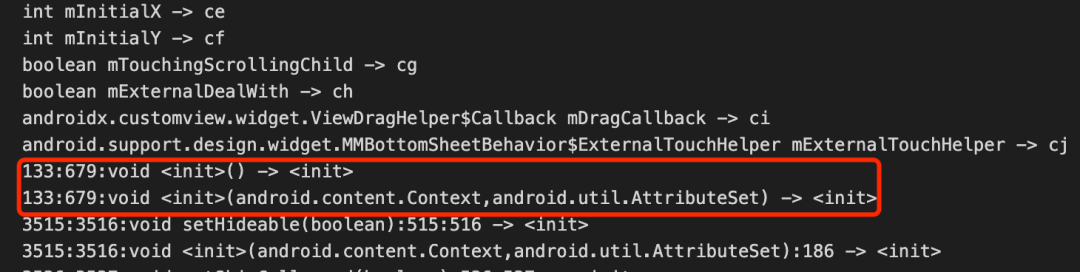
图8 inline
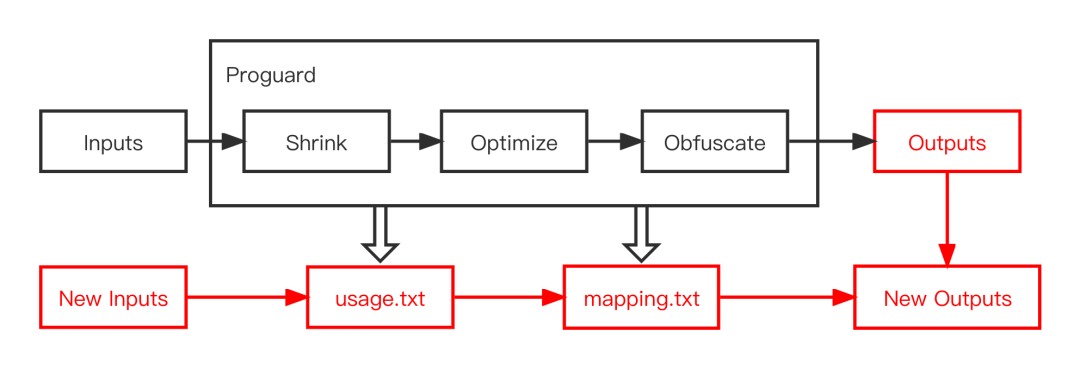
图9
那我们所做的工作就是用当前构建的New Inputs再结合上次构建的产出Outputs【图9】进行增量Proguard,具体实现思路如下:
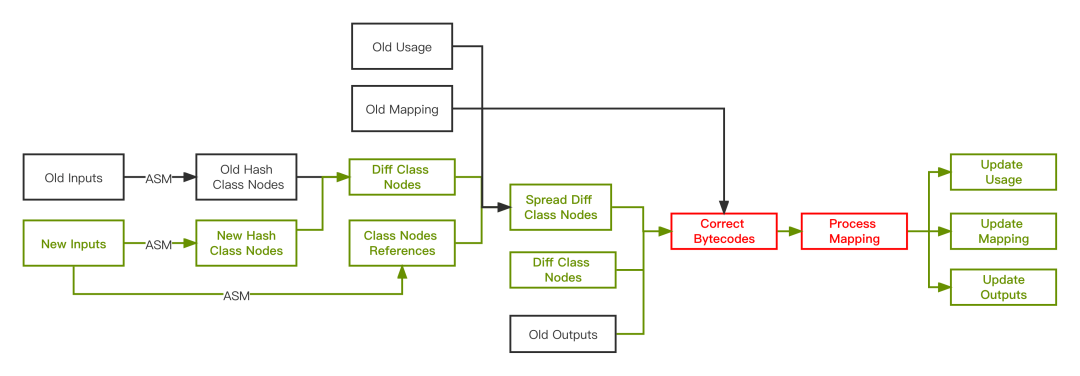
图10 实现思路
根据上述流程图,总结出大致的实现步骤:
- 利用ASM将上次构建的OutInput Jars、构建的NewInputs Jars 构建HashClassNodes Tree,以便序列化Snapshot;
- NewInputs Jars 构建Class Nodes Reference Graph, 目的是获取Class Nodes之间的引用关系;
- HashClassNodes Tree 构建 Diff Class Nodes, 获取当前构建的代码变更;
- Diff Class Nodes 和 Class Nodes Reference Graph 构建 Spread Diff Class Nodes,获取扩散影响的代码变更;
- Spread/ Diff Class Nodes 结合上次构建的产出Old Inputs Jars、usage.txt、mapping.txt 进行字节码矫正(Correct Bytecodes)
- 将校正后的字节码重新ReMapping(Process Mapping)
- 更新usage.txt 、mapping.txt 和 output jars
Diff
首先来看我们如何将输入Jars进行Hash,首先大家很容易想到利用ASM工具解析Class,分析出Fields/Methods等字节码内容,并利用哈希函数计算hashcode值,例图11:
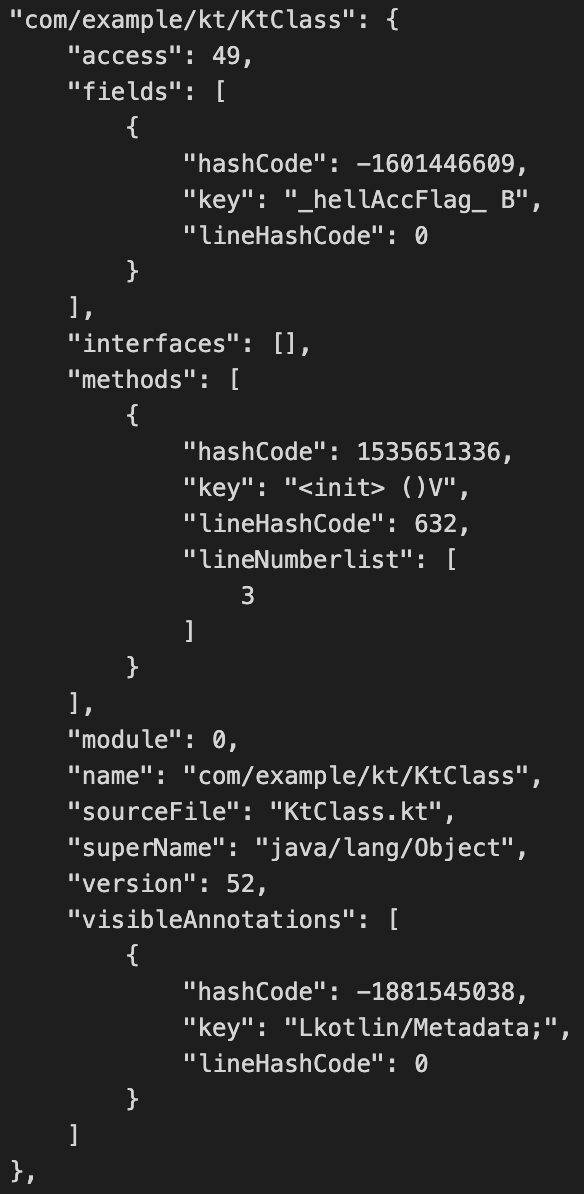
图11 hash snapshot
哈希函数我们采用hash = hash ∗iConstant+value, hash=17, iconstant=37,选取质数因子主要是尽可能避免hash冲突,分布均匀。至此我们很容易计算出相邻构建的代码差异即可【图12】
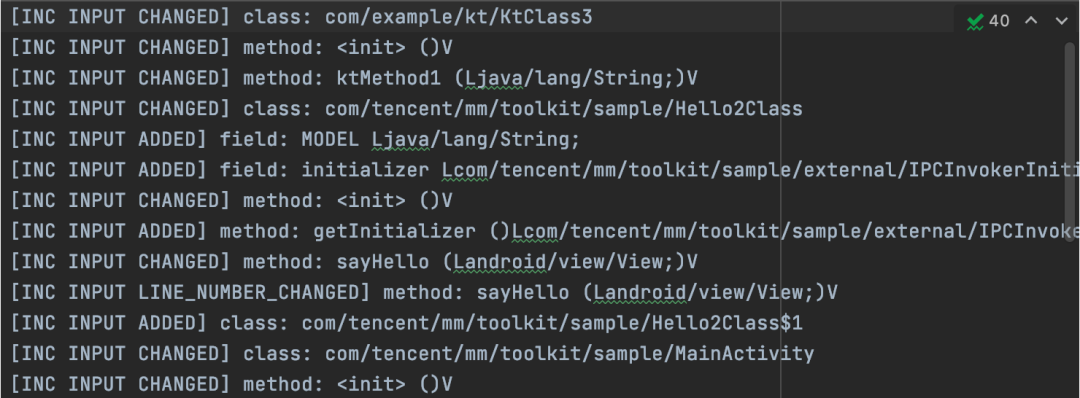
图12 Diff
目前我们支持以下几种类型的变更,基本覆盖所有的代码增量情况的更改:
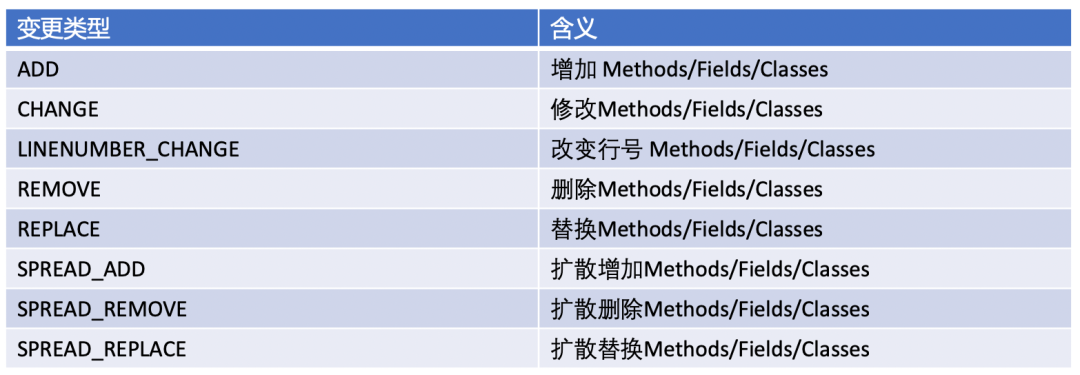
Class Nodes
有了具体的代码变更之后,为了方便后续进行字节码操作,还需要对当前的Class构建Class Node结构化数据,同样我们借鉴ASM-Tree库进行分析和扩展,构建出了功能更为强大的MM-ClassNode-Tree, 结构大致如下【图14】:
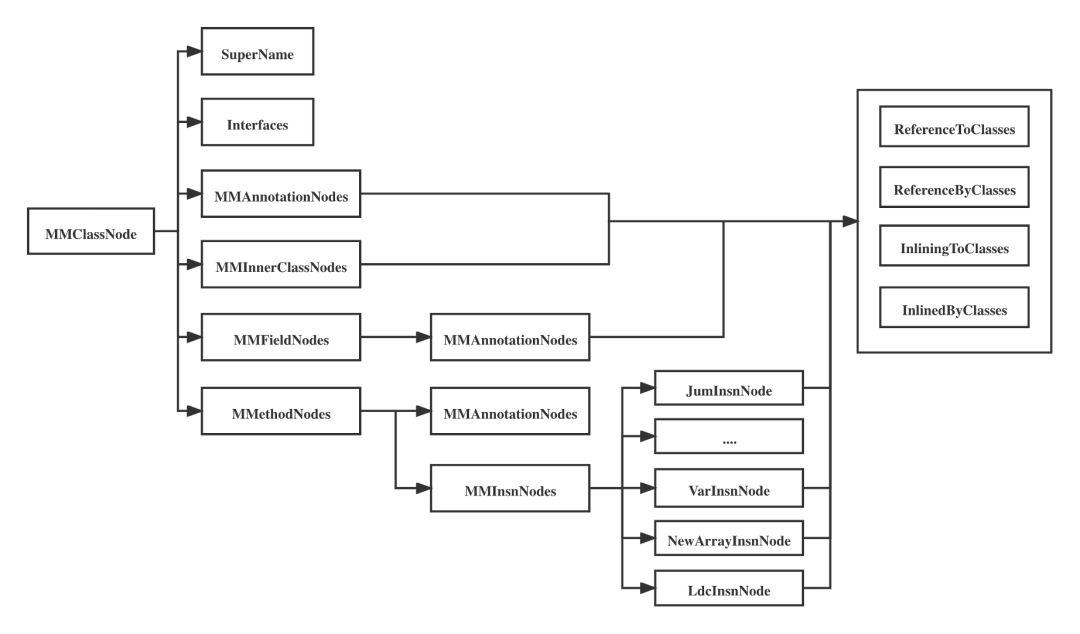
图14 ClassNode Tree
其中每个Node都保存着对Class的直接引用和inline关系,引用关系【15】我们可以通过Constants Pool获得,Inline信息可以从Mapping中获取【图16】,同样我们的Mapping、Usage信息都将会被结构化组织。
private fun findReferencedClasses(referencingClass: Clazz, member: Member?, descriptor: String, owner: String,
name: String, node: String): ArrayList<Clazz?>? {
val enumeration = DescriptorClassEnumeration(descriptor)
val classCount = enumeration.classCount()
var referencedClasses :ArrayList<Clazz?>? = null
if (classCount > 0) {
referencedClasses = ArrayList<Clazz?>()
for (index in 0 until classCount) {
val fluff = enumeration.nextFluff()
val name = enumeration.nextClassName()
val referencedClass: Clazz? = findClass(referencingClass, member, name, node)
if (referencedClass != null) {
referencedClasses.add(referencedClass)
}
}
}
val referencedClass: Clazz? = findClass(referencingClass, member, owner, node)
if (referencedClass != null) {
if (referencedClasses == null) {
referencedClasses = ArrayList<Clazz?>()
}
referencedClasses.add(referencedClass)
}
return referencedClasses
}例15 find reference
public static class MethodInfo {
private int obfuscatedFirstLineNumber;
private int obfuscatedLastLineNumber;
private final String originalClassName;
private int originalFirstLineNumber;
private int originalLastLineNumber;
private final String originalType;
private final String originalName;
private final String originalArguments;
private final String obfuscatedName;
private final String obfuscatedArguments;
public MethodInfo inlineToInfo;
public MethodInfo inlineByInfo;
//mapping文件中是否为:xxx:xxx[false], :xxx[true]
private boolean sameLineNumber;
private boolean markRemoved;
}例16 mapping info(部分)
接下来,我们有必要继续计算当前的变更的Spread Change,有了上面的引用和内联关系,就很容易计算出影响的其他Class Diff:
def spreadDiffClassMarker = new SpreadDiffClassVisitor(spreadDiffWriter, logWriter,
configuration.classLoader, programClassPool)
programClassPool.classAccept(
new ClassProcessingInfoFilter(Status.NodeStatusFlag.ADD.value |
Status.NodeStatusFlag.CHANGE.value |
Status.NodeStatusFlag.REPLACE.value, 0, 0,
new MultiClassVisitor(
spreadDiffClassMarker,
new MMAllMemberVisitor(
new MMemberProcessingInfoFilter(Status.NodeStatusFlag.ADD.value |
Status.NodeStatusFlag.CHANGE.value, 0, 0, spreadDiffClassMarker)))))}例17 spread diff

图18
Corrector
上述章节主要讲述如何获取Diff Class Nodes, 整个流程最为关键的部分则是字节码校正,下面通过举例说明针对不同的变更类型,其处理方式也不尽相同:

图19
在上次构建中,class A被映射为class a,B.funb() 被shrink掉保存在usage.txt中,A$2为匿名内部类remapping为A$1, 方法funB中将class C的func方法inline,并保存在mapping.txt中,考虑针对当前修改情况进行分别校正处理:
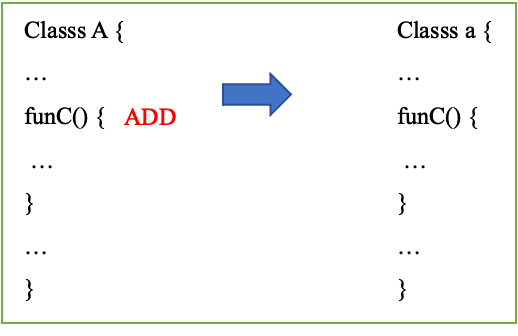
图20 ADD

图21 CHANGE

图22 REPLACE
- ADD: func()为新添加方法,由于mapping文件并不存在func的映射关系,所以直接添加到class a中即可,code部分也相应copy输出【图20】,如果新增的方法中存在shrink/inline的code部分,同样也一并ADD处理;
usageMarker.isAdded(programMethod) || usageMarker.isSpreadAdded(programMethod) -> {
val exceptionsArray: Array<String>? =
if (programMethod.exceptions == null) null else programMethod.exceptions.toTypedArray<String>()
val correctMethodVisitor = outputClass.visitMethod(
programMethod.access,
programMethod.name,
programMethod.desc,
programMethod.signature,
exceptionsArray
) as MMethodNode
processingFlagMarker.markCorrectAdd(correctMethodVisitor)
programMethod.accept(InnerProcessingMethodVisitor(
programClass = inputProgramClass,
inputMethodNode = programMethod,
methodVisitor = correctMethodVisitor
))
}- CHANGE: 如果在方法funB中新增一个D.fund方法,则class A的funB处于CHANGE状态,此时inline的C.func和新添加的D.fund方法copy到class a中,inline的Class D部分则需要设置ADD状态,补齐func code部分【图21】;
usageMarker.isChanged(inputMethodNode) || usageMarker.isSpreadChanged(inputMethodNode) -> {
val index = outputProgramClass.methods.indexOf(outputProgramMethod)
val exceptionsArray: Array<String>? =
if (outputProgramMethod.exceptions == null) null else outputProgramMethod.exceptions.toTypedArray<String>()
val newProgramMethod = MMProgramMethodNode(outputProgramMethod.access,
outputProgramMethod.name,
outputProgramMethod.desc,
outputProgramMethod.signature,
exceptionsArray)
inputMethodNode.accept(
InnerProcessingMethodVisitor(
programClass = inputProgramClass,
inputMethodNode = inputMethodNode,
methodVisitor = newProgramMethod
)
)
outputProgramClass.methods[index] = newProgramMethod
processingFlagMarker.markCorrectChange(newProgramMethod)
}- REMOVE: 此过程比较简单,删除class A中某个方法,可以简单将class a中对应的方法进行删除即可;
- LINE NUMBER CHANGE: 如果修改class A中的任何代码,都会引起下面的code 行号信息发生变更,同样也会影响解栈操作,这里我们在hash过程中也要保留一份line code信息,针对当前的行号变更并结合offset偏移从而计算当前的line number,最后更新到outputs即可;
indexLineNumberOffsets = inputMethodNode.getLineNumberOffset(inputProgramClass)
val filterInputLineNumberNodes = inputMethodNode.filterLineNumberNodes()
val filterOutputLineNumberNodes = outputProgramMethod.filterLineNumberNodes()
if (filterInputLineNumberNodes.size == indexLineNumberOffsets?.size && filterOutputLineNumberNodes.size == indexLineNumberOffsets?.size ) {
oldLineNumberArray = inputMethodNode.filterLineNumberNodes().mapIndexed { _index ,lineNumberNode -> lineNumberNode.line - indexLineNumberOffsets!![_index] }
outputProgramMethod.insnsAccept(outputProgramClass, this, null)
} else {
logPrinter?.println("$TAG >>>>>>>>>>>>>> ERROR, lineNumberNodes is not same size!")
}- SPREAD CHANGE/REMOVE/ADD... 处理逻辑同上
考虑以下几种特殊情况:
-
匿名内部类mapping:
Proguard针对匿名内部类,可能会做remapping处理,比如图23中SearchView$10会被重新mapping为SearchView$2,因此,因此无法利用上次构建的mapping信息来还原当前的class,这里我们采取REPLACE的方式进行处理,见图22,当class A中的funA方法体有修改,则标记为CHANGE状态,此时A$2将必须copy到class a中,同时A$2需要remapping为A$2, 而不是A$1;
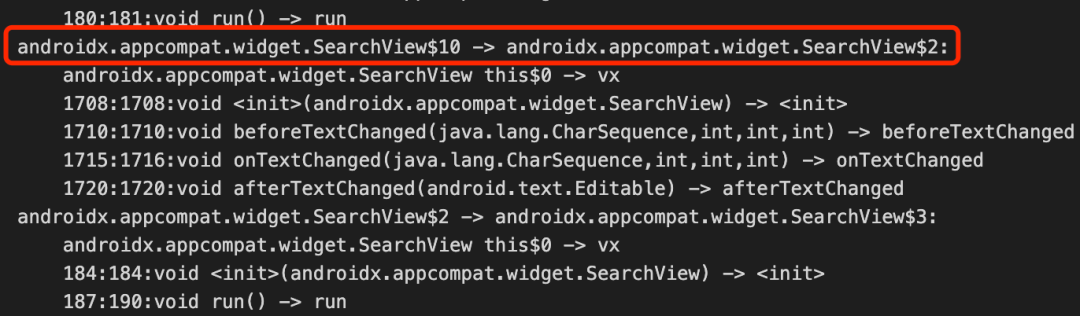
图23 匿名类
其他情况:
-
arguments 优化
method的方法参数也有可能被Shrink优化【proguard.optimize.MethodDescriptorShrinker#visitProgramMethod】,导致无法通过mapping进行找回,这里我们修改Proguard源码,保留Shrink前后的mapping信息即可。
-
return value 优化
同样method的 return value也会存在优化的情况,考虑到在微信此优化数量并不明显,这里通过配置!method/propagation/returnvalue简单处理
Update
corrector环节处理之后,最后则需要对outputs进行remapping,并更新产出文件,大致原理如下:
-
Remapping outputs
校正后的字节码还必须进行重新混淆才能输出生产环境Apk,阅读retrace解析流程,我们顺利地将上次构建的mapping.txt进行结构化解析,再对已经标记待处理的output classes/fields/methods/annotation/code insn部分进行混淆remapping【图24,25,26】;
// Process mapping
def mappingProcessor = new ProcessingMappingVisitor(mappingRemapper, logPrinter, outputProgramPool)
outputProgramPool.classAccept(new MultiClassVisitor(
// Update class mapping
new ClassProcessingFlagFilter(ProcessingFlag.CORRECTED_CHANGE.value |
ProcessingFlag.CORRECTED_ADD.value |
ProcessingFlag.CORRECTED_REPLACED.value,
0,0, mappingProcessor),
new MMAllMemberVisitor(
// Update methods/fields mapping
new MMemberProcessingFlagFilter(ProcessingFlag.CORRECTED_CHANGE.value |
ProcessingFlag.CORRECTED_ADD.value|
ProcessingFlag.CORRECTED_REPLACED.value,
0, 0, mappingProcessor)),
))图24 remapping
if (typeInsnNode.opcode == Opcodes.NEW ||
typeInsnNode.opcode == Opcodes.ANEWARRAY ||
typeInsnNode.opcode == Opcodes.CHECKCAST ||
typeInsnNode.opcode == Opcodes.INSTANCEOF) {
typeInsnNode.desc = obfuscatedDescriptor(typeInsnNode.desc, mapper, logPrinter)
logPrinter?.println("$TAG, >>>>>>>> process typeInsn desc: ${typeInsnNode.desc}" +
" -> obfuscate desc: ${typeInsnNode.desc}")
}图25 obfuscate insn(部分)
fun obfuscatedDescriptor(originalInternalDescriptor: String, mappingRemapper: FrameRemapper?,
logPrinter: PrintWriter?, fixClassInfo: ProgramClassFixInfo? = null): String {
val startIndex = originalInternalDescriptor.indexOf(TypeConstants.CLASS_START)
val endIndex = originalInternalDescriptor.lastIndexOf(TypeConstants.CLASS_END)
if (startIndex < 0 || endIndex <= 0) {
return obfuscatedInternalClass(ClassUtil.externalClassName(originalInternalDescriptor), mappingRemapper, fixClassInfo)
}
try {
val newDescriptorBuffer = StringBuffer(originalInternalDescriptor.length)
val enumeration = DescriptorClassEnumeration(originalInternalDescriptor)
if (enumeration.classCount() < 2) {
return obfuscatedInnerDescriptor(originalInternalDescriptor, startIndex, endIndex, mappingRemapper, logPrinter, fixClassInfo)
}
newDescriptorBuffer.append(enumeration.nextFluff())
while (enumeration.hasMoreClassNames()) {
val internalClassName = enumeration.nextClassName()
val obfuscatedClassName = obfuscatedInternalClass(ClassUtil.externalClassName(internalClassName), mappingRemapper, fixClassInfo)
newDescriptorBuffer.append(obfuscatedClassName)
newDescriptorBuffer.append(enumeration.nextFluff())
}
return newDescriptorBuffer.toString()
} catch (ex: Exception) {
logPrinter?.println("process obfuscatedDescriptor error, originalDescriptor: $originalInternalDescriptor")
ex.printStackTrace()
}
return obfuscatedInnerDescriptor(originalInternalDescriptor, startIndex, endIndex, mappingRemapper, logPrinter, fixClassInfo)
}图26 obfuscate description
-
Update usage/mapping.txt
进一步的,通过corrector后的字节码状态信息,也需要同步更新usase/mapping的结构化数据,并Print到当前的usage和mapping产出文件中【图27】;
...
if (!methodInfo.isInlineInfo()) {
if (methodInfo.originalFirstLineNumber > 0) {
// Print out the line number range of the method,
// ignoring line numbers of any inlined methods.
pw.println(" " +
methodInfo.originalFirstLineNumber + ":" +
methodInfo.originalLastLineNumber + ":" +
methodInfo.originalType + " " +
methodInfo.originalName + JavaTypeConstants.METHOD_ARGUMENTS_OPEN +
methodInfo.originalArguments + JavaTypeConstants.METHOD_ARGUMENTS_CLOSE +
" -> " +
obfuscatedMethodName);
} else {
// Print out the method mapping without line numbers.
pw.println(" " +
methodInfo.originalType + " " +
methodInfo.originalName + JavaTypeConstants.METHOD_ARGUMENTS_OPEN +
methodInfo.originalArguments + JavaTypeConstants.METHOD_ARGUMENTS_CLOSE +
" -> " +
obfuscatedMethodName);
}
} else {
...
}图27 print mapping
-
Update outputs:
最后,基于corrector后的字节码状态信息,利用ASM更新上次构建的Output Jars产物【图28】,从而实现增量混淆效果;
...
ExtensionUtil.isDir(outputFile.absolutePath) -> {
classNameSets?.forEach { name ->
val programClass = outputProgramPool.getClass(name) as MMClassNode
IncrementalDirProcessor(
logPrinter,
classLoader,
ignoreCheckClass,
outputProgramPool, programClass,
processFlagsMarker,
outputFile.toPath(),
outputFile.toPath()
).proceed()
}
}
...图28 update outputs
效果
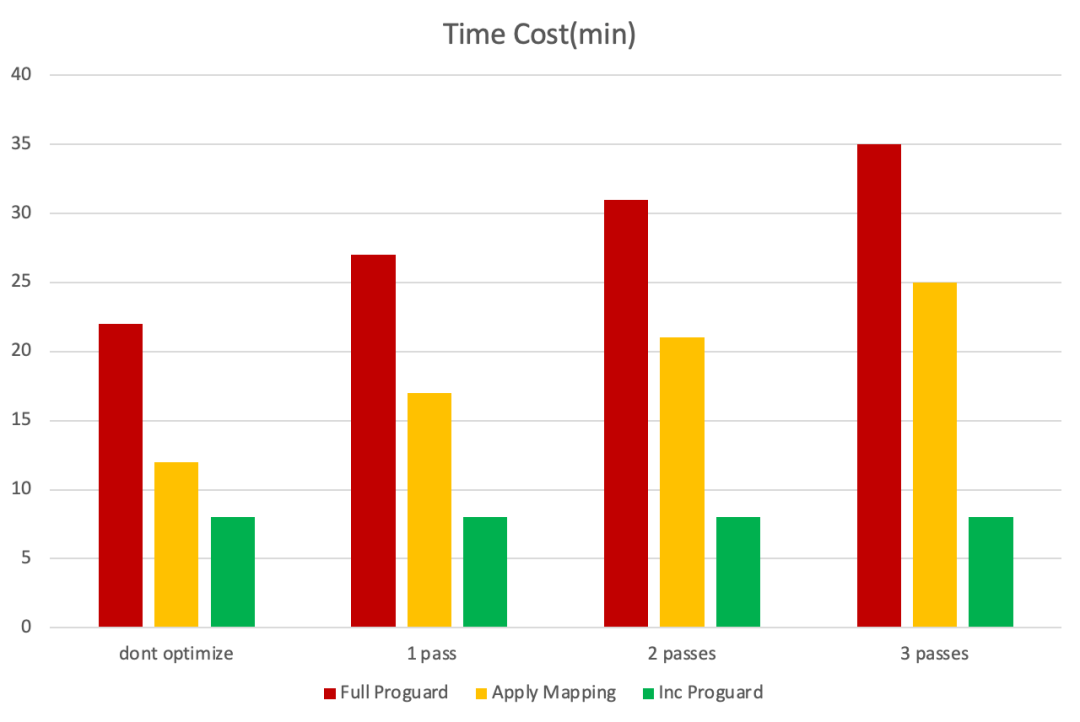
从图29,30可以看出,优化效果十分明显,整个inc-proguard过程平均控制在8分钟左右即可增量混淆完成,pass越多优化越明显,达到了预期效果。除此之外,为了保证增量准确率,还做了很多细节上的处理,比如call super/interface class的method 其mapping如何处理、特定的字节码指令如何mapping、ClassReader出现ClassNotFoundException如何解决等等。
最后
最后,编译优化并不是一件容易的事情,有些策略的选择都是结合整个团队的实际情况来综合考虑,总体上增量混淆方案基本上保持了耗时相对稳定、代码侵入小、优化程度完全可控等优势,编译问题我们仍在优化,欢迎大家留言交流。
参考资料
[1]https://www.guardsquare.com/blog/proguard-and-r8