线上订单号重复了?一招搞定它!
问题的背景
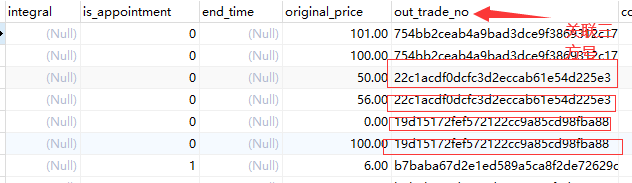
公司老的系统原先采用的时间戳生成订单号,导致了如下情形

SELECT * FROM XX表 WHERE 重复项 in( SELECT 重复项 FROM XX表 GROUP BY 重复项 HAVING count(1) >= 2)
解决方法
不得了,这样重复岂不是一单成功三方回调导致另一单也成功了。
多个服务怎么保证生成的订单号唯一呢?
先上code
package com.zhongjian.util;
public class IdWorkerUtil{
private long workerId;
private long datacenterId;
private long sequence;
public IdWorkerUtil(long workerId, long datacenterId, long sequence){
// sanity check for workerId
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0",maxDatacenterId));
}
System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
private long twepoch = 1288834974657L;
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
private long sequenceBits = 12L;
private long workerIdShift = sequenceBits;
private long datacenterIdShift = sequenceBits + workerIdBits;
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private long sequenceMask = -1L ^ (-1L << sequenceBits);
private long lastTimestamp = -1L;
public long getWorkerId(){
return workerId;
}
public long getDatacenterId(){
return datacenterId;
}
public long getTimestamp(){
return System.currentTimeMillis();
}
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",
lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
lastTimestamp = timestamp;
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
private long timeGen(){
return System.currentTimeMillis();
}
public static void main(String[] args) {
IdWorkerUtil idWorkerUtil = new IdWorkerUtil(1,1,0L);
System.out.println(idWorkerUtil.nextId());
}
}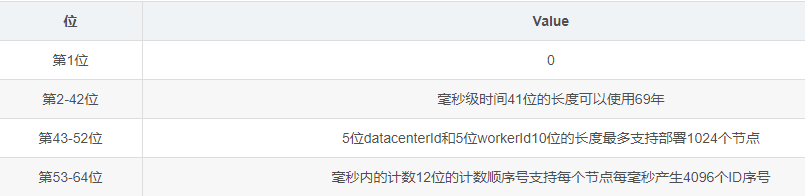
41-bit的时间可以表示(1L<<41)/(1000L360024*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。
这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
这种方式的优缺点是:
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
一般来说,采用这种方案就解决了。
还有诸如,mysql的 auto_increment策略,redis的INCR,zookeeper的单一节点修改版本号递增,以及zookeeper的持久顺序节点。
看完点个赞呗~
参考
- https://tech.meituan.com/2017/04/21/mt-leaf.html
- https://www.cnblogs.com/qianzhengkai/p/11151613.html