美团成都一面面经及详细答案
文章目录:
- 1.了解static吗,static数据存在哪?生命周期什么样的
- 2.了解final吗,讲讲下面这段代码的结果
- 3.讲讲volatile吧
- 4.讲讲两个锁的区别(
reentrantlock和synchronized) - 5.讲讲线程池的创建与销毁,核心线程可以销毁吗?
- 6.高并发怎么减少锁的竞争
- 7.了解类加载机制吗,讲讲下面这段代码运行结果
- 8.hashMap为什么大小是幂次
- 9.euqal和==的区别,equal没有重写的时候默认是什么
- 10.写个sql吧,学号 学生姓名 科目 成绩 班级,选出每个班的每个科目最高分
- 11.linux的tail -f命令里的f是什么意思
- 12.用过grep吗,会正则吗
- 13.mysql 事务的特性
- 14.char和varchar的区别
- 15.如果我一个字段是char(10),我只存三个字节进去,它底层文件占几个字节
- 16.计算机网络:TCP如何保证数据包不丢、不重、不乱、完整性
- 17.自动拆箱装箱了解吗
- 18.有重复元素的升序数组里找到下标最小的目标值
1.了解static吗,static数据存在哪?生命周期什么样的
从Java虚拟机相关知识可知,和运行数据区主要分为五个部分,分别是程序计数器、Java虚拟机栈、本地方法栈、堆、方法区。
其中方法区主要用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译后的代码等数据。
static数据的生命周期就是类的生命周期,Java虚拟机会在加载类的过程中为静态变量分配内存,一个类的完整的生命周期会经历加载、连接、初始化、使用、和卸载五个阶段。
2.了解final吗,讲讲下面这段代码的结果
String s = "hello2";
final String s2 = "hello";
String s3 = s2+2;
System.out.println(s==s3);这个题很有意思,以后可以展开写写篇博客,这里先简单解释下,结论是True,原因也很简单,就是s指向的是常量池中的hello2,经过final修饰的s2在编译器也会被解析为常量放到常量池,s2+2相当于两个常量相加,结果还是常量,所以s3也指向常量池中的hello2,常量池中的值都是唯一的,所以s和s3指向的值是同一个值,所以结果是True。
String s = "hello2"
String s1 = "hello2"
String s2 = new String("hello2") 为了方便理解,可以看下图,不过字符串常量区也是在堆中的,有些资料也说在方法区,我是倾向于在堆中,这里就先不展开解释了
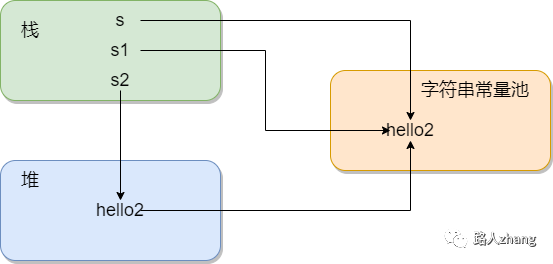
hello2,而s2则是通过new关键字生成的一个新的对象,因为字符串常量池中已经有了hello2,所以会将他们直接联系起来,如果也会在字符串常量池中创建一个hello2
有了上面这些基础,就好办多了,先看这个代码:
String s = "hello2";
String s1 = "hello";
String s2 = "hello" + 2;
System.out.println(s==s2);**分析:**不难猜出这个答案是true,因为s指向字符串常量池中的hello2,而hell0和2两个常量相加也会直接存放到字符串常量池中,所以s2也是直接指向字符串常量池中的hello2,前面也说过了字符串常量池中的值都是唯一的,所以s和s2指向的是同一个值。
下面再来看这个代码,猜猜看运行结果是什么样的
String s = "hello2";
String s1 = "hello";
String s2 = "2"
String s3 = s1 + s2;
System.out.println(s==s3);**分析:**这个答案是false,是不是有些意外。了解这个代码流程就能搞明白了:
- 在栈中存在s,s指向字符串常量池中的
hello2 - 在栈中存在s1,s1指向字符串常量池中的
hello - 在栈中存在s2,s2指向字符串常量池中的
2 - 在栈中存放s3,而
s1+s2则会通过StringBuilder中的toString()方法在堆中创建一个hello2
结合上面的图,这时就可以看出来s指向字符串常量池中的hello2,而s3则指向堆中的hello2,输出为false
同理,再看看这段代码就不能猜到结果了:
String s = "hello2";
String s1 = "hello";
String s2 = s1 + 2;
System.out.println(s==s2);**分析:**没错,答案是false,原因同上,从jvm的角度来理解就是,字符串常量之间的+操作是在编译期就已经确定的了,而引用的值是在编译期无法确定的,所以是在运行期进行的,新创建的对象也会放在堆中。
最后回到原问题,看问题中的代码,用final关键字修饰了s2
String s = "hello2";
final String s2 = "hello";
String s3 = s2+2;
System.out.println(s==s3);s2被final关键字修饰后则会在编译期就解析为一个常量值放到常量池中,所以这个题目的最终结果是True
3.讲讲volatile吧
话不多说直接上链接:[面试官:请说下volatile的实现原理]
4.讲讲两个锁的区别(reentrantlock和synchronized)
这也是一个高频面试题
从几个方面简单说下两者的区别:
-
底层实现
synchronized是JVM层面的锁,也是Java的关键字,通过monitor对象进行完成的。ReentrantLock是JDK提供的API层面的锁 -
是否需要手动释放
synchronized不需要用户去手动释放锁,ReentrantLock则需要用户去手动释放锁。 -
是否可中断
synchronized是不可中断类型的锁,ReentrantLock是可以中断的 -
是否可以绑定条件
synchronized不能绑定,ReentrantLock可以通过绑定Condition并结合await()/singal()方法对线程进行精准唤醒
关于synchronized的更多细节可以看这篇文章:[面试官:请详细说下synchronized的实现原理]
5.讲讲线程池的创建与销毁,核心线程可以销毁吗?
线程池的创建:
线程池的常用创建方式主要有两种,通过Executors工厂方法创建和**通过new ThreadPoolExecutor**方法创建。
- Executors工厂方法创建,在工具类 Executors 提供了一些静态的工厂方法
newSingleThreadExecutor:创建一个单线程的线程池。newFixedThreadPool:创建固定大小的线程池。newCachedThreadPool:创建一个可缓存的线程池。newScheduledThreadPool:创建一个大小无限的线程池。
new ThreadPoolExecutor 方法创建: 通过new``ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)自定义创建
线程池的关闭:
线程池的关闭可以调用线程池中的shutdown或shutdownNow方法进行关闭,它们会遍历线程池中的工作线程,然后调用每个线程的interrupt方法来中断线程。
核心线程可以销毁吗?这个问题需要看下源码,这里就不展开了,当线程池未调用 shutdown 方法时,是通过队列的take方法阻塞核心线程的run方法从而保证核心线程不会被销毁的。如果想销毁核心线程可以通过调用线程池对象的allowCoreThreadTimeOut(true)方法。
6.高并发怎么减少锁的竞争
- 降低锁的粒度
- 缩小锁的范围
- 避免使用独占锁
7.了解类加载机制吗,讲讲下面这段代码运行结果
class Father{
private String a = "father";
public Father(){
say();
}
public void say(){
System.out.println("i'm father"+a);
}
}
class Sub extends Father{
private String a = "child";
@Override public void say(){
System.out.println("i'm child"+a);
}
}
public class Test {
public static void main(String[] args) {
Father father = new Father();
Sub sub = new Sub();
}
}类的加载机制:虚拟机把描述类的数据从class文件加载到内存,并对数据进行校验,转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制。
这段代码的运行结果还是有些古怪的
i'm fatherfather
i'm childnull大家可以先记住代码执行顺序:
静态代码块(父) > 静态代码块(子) > 实例成员变量(父) > 构造代码块(父) > 构造方法(父) > 实例成员变量(子) > 构造代码块(子) > 构造方法(子)
在本题中的执行顺序如下:
Father father = new Father();—>private String a = "father";—>public Father( { say() ;}—>执行say()方法,结果为i'm fatherfather
Sub sub = new Sub();—>private String a = "father";—>public Father( { say() ;}—>调用子类的say()方法,因为子类的实例成员变量并未初始化,所以结果为i'm childnull
8.hashMap为什么大小是幂次
因为HashMap是通过key的hash值来确定存储的位置,但Hash值的范围是-2147483648到2147483647,不可能建立一个这么大的数组来覆盖所有hash值。所以在计算完hash值后会对数组的长度进行取余操作,如果数组的长度是2的幂次方,(length - 1)&hash等同于hash%length,可以用(length - 1)&hash这种位运算来代替%取余的操作进而提高性能。
更多HashMap相关面试题见[面试手册]
9.euqal和==的区别,equal没有重写的时候默认是什么
区别:
-
==
对于基本数据类型,
==比较的是值;对于引用数据类型,==比较的是内存地址。 -
eauals
对于没有重写
equals方法的类,equals方法和==作用类似;对于重写过equals方法的类,equals比较的是值。
如果没有重写equal(),那么equals和==的作用相同,比较的是对象的地址值。
更详细的相关面试题:[Java八股文]
10.写个sql吧,学号 学生姓名 科目 成绩 班级,选出每个班的每个科目最高分
SELECT MAX(成绩) FROM 学生 GROUP BY 班级,科目
11.linux的tail -f命令里的f是什么意思
tail 命令可用于查看文件的内容,其中-f是循环读取的意思
12.用过grep吗,会正则吗
grep 命令主要用于查找文件里符合条件的字符串,简单背它的常用参数就行了
13.mysql 事务的特性
- 原子性:原子性是指包含事务的操作要么全部执行成功,要么全部失败回滚。
- 一致性:一致性指事务在执行前后状态是一致的。
- 隔离性:一个事务所进行的修改在最终提交之前,对其他事务是不可见的。
- 持久性:数据一旦提交,其所作的修改将永久地保存到数据库中。
14.char和varchar的区别
字符串常用的主要有CHAR和VARCHAR,VARCHAR主要用于存储可变长字符串,相比于定长的CHAR更节省空间。CHAR是定长的,根据定义的字符串长度分配空间。
15.如果我一个字段是char(10),我只存三个字节进去,它底层文件占几个字节
10个,剩余七个会用空格填充。
16.计算机网络:TCP如何保证数据包不丢、不重、不乱、完整性
其实就是问TCP如何保证可靠传输
主要有校验和、序列号、超时重传、流量控制及拥塞避免等几种方法。
-
校验和:在发送端和接收端分别计算数据的校验和,如果两者不一致,则说明数据在传输过程中出现了差错,TCP将丢弃和不确认此报文段。
-
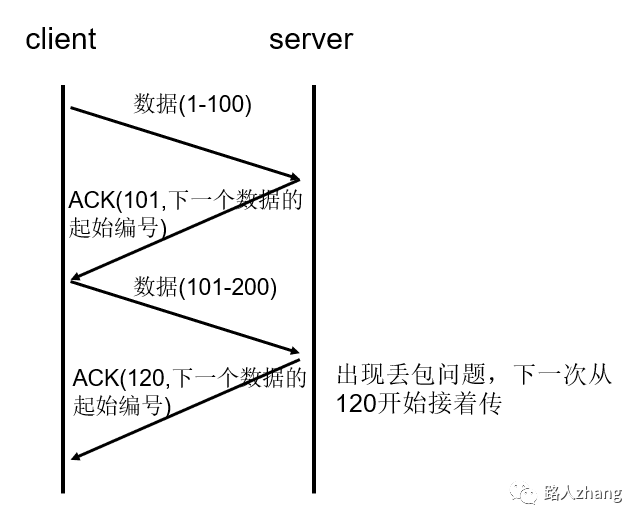
序列号:TCP会对每一个发送的字节进行编号,接收方接到数据后,会对发送方发送确认应答(ACK报文),并且这个ACK报文中带有相应的确认编号,告诉发送方,下一次发送的数据从编号多少开始发。如果发送方发送相同的数据,接收端也可以通过序列号判断出,直接将数据丢弃。
-
超时重传:在上面说了序列号的作用,但如果发送方在发送数据后一段时间内(可以设置重传计时器规定这段时间)没有收到确认序号ACK,那么发送方就会重新发送数据。
这里发送方没有收到ACK可以分两种情况,如果是发送方发送的数据包丢失了,接收方收到发送方重新发送的数据包后会马上给发送方发送ACK;如果是接收方之前接收到了发送方发送的数据包,而返回给发送方的ACK丢失了,这种情况,发送方重传后,接收方会直接丢弃发送方冲重传的数据包,然后再次发送ACK响应报文。
如果数据被重发之后还是没有收到接收方的确认应答,则进行再次发送。此时,等待确认应答的时间将会以2倍、4倍的指数函数延长,直到最后关闭连接。
-
流量控制:如果发送端发送的数据太快,接收端来不及接收就会出现丢包问题。为了解决这个问题,TCP协议利用了滑动窗口进行了流量控制。在TCP首部有一个16位字段大小的窗口,窗口的大小就是接收端接收数据缓冲区的剩余大小。接收端会在收到数据包后发送ACK报文时,将自己的窗口大小填入ACK中,发送方会根据ACK报文中的窗口大小进而控制发送速度。如果窗口大小为零,发送方会停止发送数据。
-
拥塞控制:如果网络出现拥塞,则会产生丢包等问题,这时发送方会将丢失的数据包继续重传,网络拥塞会更加严重,所以在网络出现拥塞时应注意控制发送方的发送数据,降低整个网络的拥塞程度。拥塞控制主要有四部分组成:慢开始、拥塞避免、快重传、快恢复,如下图(图片来源于网络)。
这里的发送方会维护一个拥塞窗口的状态变量,它和流量控制的滑动窗口是不一样的,滑动窗口是根据接收方数据缓冲区大小确定的,而拥塞窗口是根据网络的拥塞情况动态确定的,一般来说发送方真实的发送窗口为滑动窗口和拥塞窗口中的最小值。
- 慢开始:为了避免一开始发送大量的数据而产生网络阻塞,会先初始化cwnd为1,当收到ACK后到下一个传输轮次,cwnd为2,以此类推成指数形式增长。
- 拥塞避免:因为cwnd的数量在慢开始是指数增长的,为了防止cwnd数量过大而导致网络阻塞,会设置一个慢开始的门限值ssthresh,当cwnd>=ssthresh时,进入到拥塞避免阶段,cwnd每个传输轮次加1。但网络出现超时,会将门限值ssthresh变为出现超时cwnd数值的一半,cwnd重新设置为1,如上图,在第12轮出现超时后,cwnd变为1,ssthresh变为12。
- 快重传:在网络中如果出现超时或者阻塞,则按慢开始和拥塞避免算法进行调整。但如果只是丢失某一个报文段,如下图(图片来源于网络),则使用快重传算法。
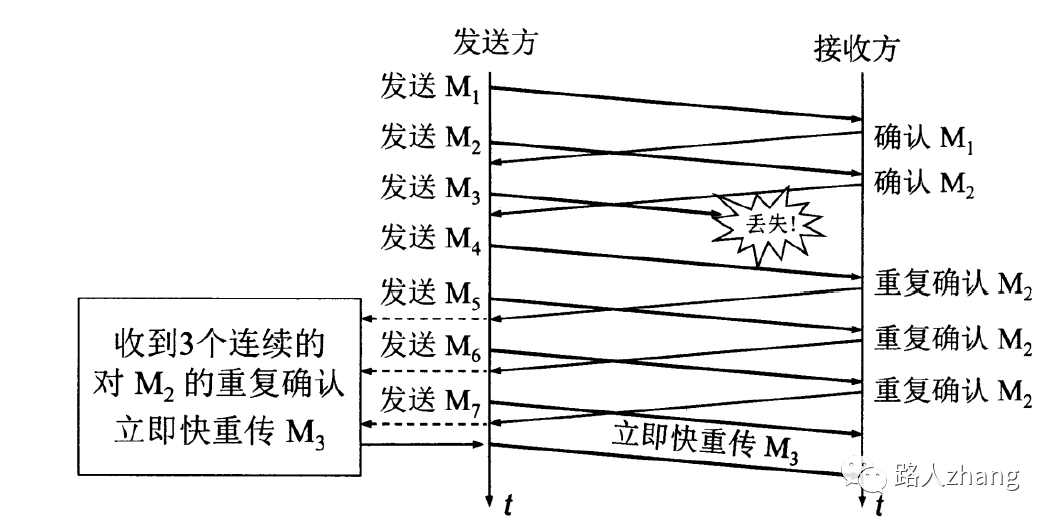
但是根据快重传算法,要求在这种情况下,需要快速向发送端发送M2的确认报文,在发送方收到三个M2的确认报文后,无需等待重传计时器所设置的时间,可直接进行M3的重传,这就是快重传。(面试时说这一句就够了,前面是帮助理解) 4. 快恢复:从上上图圈4可以看到,当发送收到三个重复的ACK,会进行快重传和快恢复。快恢复是指将ssthresh设置为发生快重传时的cwnd数量的一半,而cwnd不是设置为1而是设置为为门限值ssthresh,并开始拥塞避免阶段。
17.自动拆箱装箱了解吗
- 装箱:将基本类型用包装器类型包装起来
- 拆箱:将包装器类型转换为基本类型
详细内容可见面试手册中的答案
18.有重复元素的升序数组里找到下标最小的目标值
这题目不难,有序数组基本就是二分,不要对其直接进行遍历就好了。