缓存一致性最佳实践
背景
概述
最近团队里我们在密集的讨论Redis缓存一致性相关的问题,电商核心的域如商品、营销、库存、订单等实际上在缓存的选择上各有特色,那么在这些差异的业务背后,我们有没有一些最佳实践可供参考呢?
本文尝试着来讨论这个问题,并给出一些建议。
在讨论之前,有两个重点我们需要达成一致:
-
分布式场景下无法做到强一致:
不同于CPU硬件缓存体系采用的MESI协议以及硬件的强时钟控制,分布式场景下我们无法做到缓存与底层数据库的强一致,即把缓存和数据库的数据变更做成一个原子操作。
硬件工程师设计了内存屏障(Memory Barrier)的概念,提供给软件开发者不同的一致性选项在性能与一致性上进行权衡。
-
就算是达到最终一致性也很难:
分布式场景下,要做到最终一致性,就要求缓存中存储的是最新版本的数据(或者缓存为空),而且是在数据库更新后很迅速的就要达到这个一致性的状态,要做到是极其困难的。
我们会面临硬件、软件、通信等等组件非常多的异常情况。
缓存的一致性问题
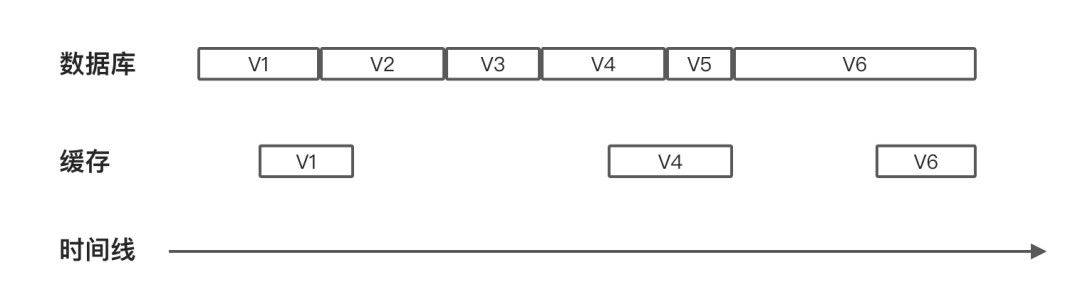
一般化来说,我们面临的是这样的一个问题,如下图所示,数据库的数据会有5次更新,产生6个版本,V1~V6,图中每个方框的长度代表这个版本持续的时间。
我们期望,在数据库中的数据变化后,缓存层需要尽快的感知到并作出反应,如下图所示,缓存层方框中的间隔代表这个时间段缓存数据不存在,V2、V3以及V5版本在缓存中不存在并不会破坏我们的最终一致性要求,只要数据库的最终版本和缓存的最终版本是相同的就可以了。
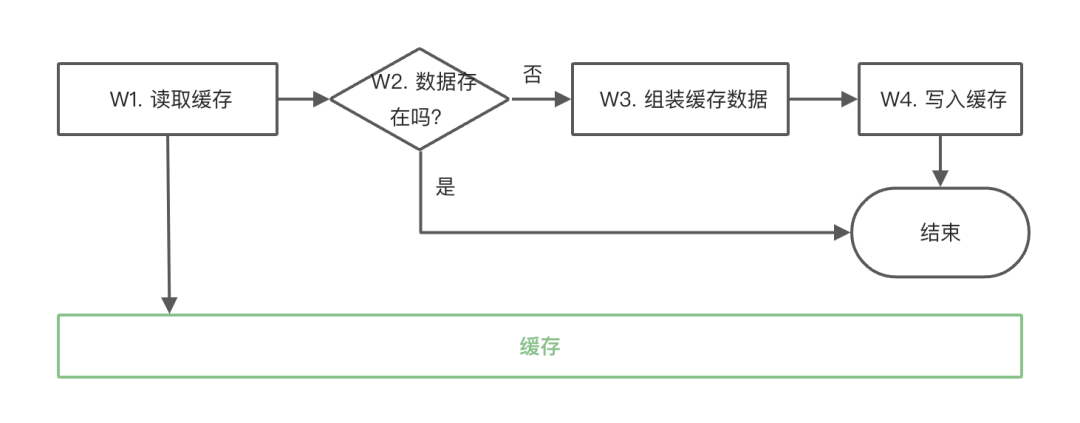
缓存写入的代码通常情况下都是和缓存使用的代码放在一起的,包含4个步骤,如下图所示:W1读取缓存,W2判断缓存是否存在,W3组装缓存数据(这通常需要向数据库进行查询),W4写入缓存。
每一个步骤间可能会停顿多久是没有办法控制的,尤其是W3、W4之间的停顿最为要命,它很可能让我们将旧版本的数据写入到缓存中。
我们可能会想,W4步的写入,带上W2的假设,即使用WriteIfNotExists语义,会不会有所改善?
使用WriteIfNotExists语义,其中必然有2个执行会失败,哪一个会成功根本无法保证。
我们无法简单的做决策,需要再次将缓存读取出来,然后判断是否我们即将写入的一样,如果一样那就很简单;如果不一样的话,我们有两种选择:
- 将缓存删除,让后续别的请求来处理写入。
- 使用缓存提供的原子操作,仅在我们的数据是较新版本时写入。

数据库的数据发生变化后,我们如何感知到并进行有效的缓存管理呢?
通常情况下有如下的3种做法:
-
使用代码执行流
通常我们会在数据库操作完成后,执行一些缓存操作的代码。
这种方式最大的问题是可靠性不高,应用重启、机器意外当机等情况都会导致后续的代码无法执行。
-
使用事务消息
作为使用代码执行流的改进,在数据库操作完成后发出事务消息,然后在消息的消费逻辑里执行缓存的管理操作。
可靠性的问题就解决了,只是业务侧要为此增加事务消息的逻辑,以及运行成本。
-
使用数据变更日志
数据库产品通常都支持在数据变更后产生变更日志,比如MySQL的binlog。
可以让中间件团队写一款产品,在接收到变更后执行缓存的管理操作,比如阿里的精卫。
可靠性有保证,同时还可以进行某个时间段变更日志的回放,功能就比较强大了。
最佳实践一:数据库变更后失效缓存
这是最常用和简单的方式,应该被作为首选的方案,整体的执行逻辑如下图所示:
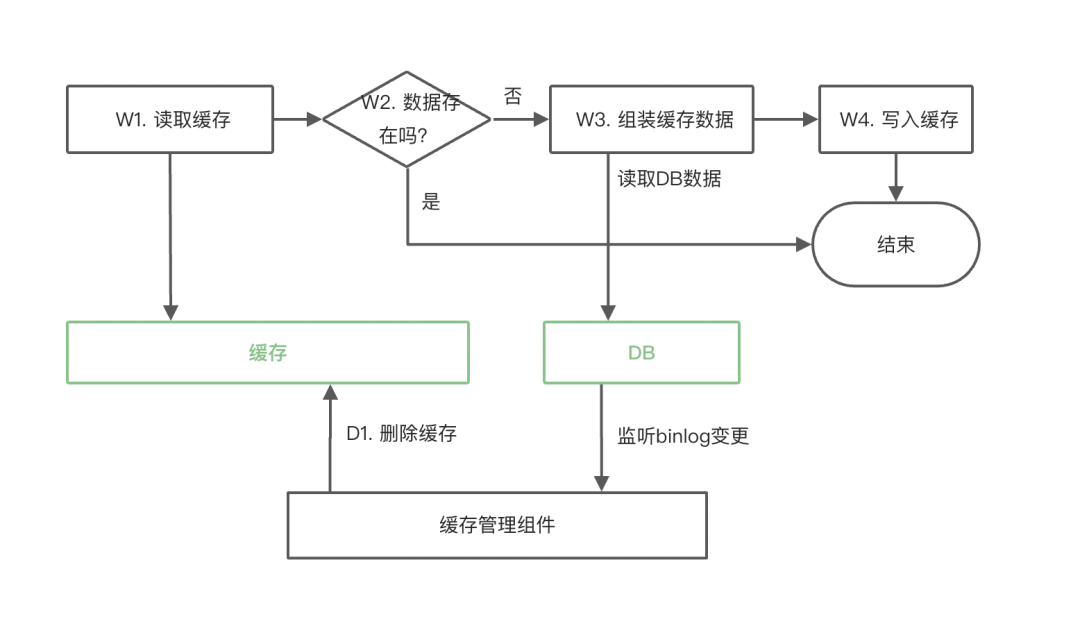
D1步使用监听DB binlog的方式来删除缓存,即前述使用数据变更日志中介绍的方法。
这个方案的缺点是:在数据库数据存在高并发更新且缓存读取流量较大的情况下,会有小概率存在缓存中存储的是旧版本数据的情况。
通常的解法有四种:
- 限制缓存有效时间:
设定缓存的过期时间,比如15分钟。即表示我们最多接受缓存在15分钟的时间范围内是旧的。
- 小概率缓存重加载:
根据流量比设定一定比例的缓存重加载,以保证大流量情况下的缓存数据的一致性。
比如1%的比例,这同时还可以帮助数据库得到充分的预热。
- 结合业务特点:
根据业务的特点做一些设计,比如:
a . 针对营销的场景:
在商品详情页/确认订单页的优惠计算时使用缓存,而在下单时不使用缓存。
这可以让极端情况发生时,不产生过大的业务损失。
b . 针对库存的场景:
读取到旧版本的数据只是会在商品已售罄的情况下让多余的流量进入到下单而已,下单时的库存扣减是操作数据库的,所以不会有业务上的损失。
- 两次删除:
D1步删除缓存的操作执行两次,且中间有一定的间隔,比如30秒。
这两次动作的触发都是由“缓存管理组件”发起的,所以可以由它支持。
最佳实践二:带版本写入
针对象商品信息缓存这种更新频率低、数据一致性要求较高且缓存读取流量很高的场景,通常会采用带版本更新的方式,整体的执行逻辑如下图如示:
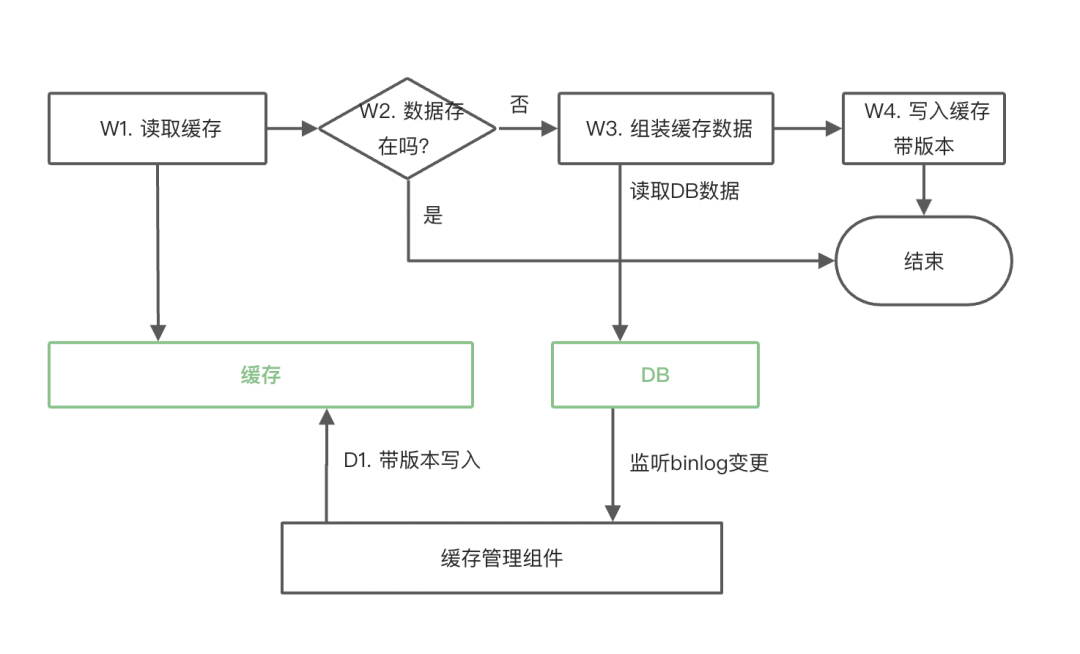
这同时也要求我们在数据库增加数据版本的信息。
这个方案的最终一致性效果比较好,仅在极端情况下(新版本写入后数据丢失了,后续旧版本的写入就会成功)存在缓存中存储的是旧版本数据的可能。
在D1步使用写入而不是使用删除可以极大程度的避免这个极端情况的出现,同时由于该方案适用于缓存读取流量很高的场景,还可以避免缓存被删除后W3步短时间大量请求穿透到DB。
总结与展望
对于缓存与数据库分离的场景,在结合了业界多家公司的实践经验以及ROI权衡之后,前述的两个最佳实践是被应用的最为广泛的,尤其是最佳实践一,应该作为我们日常应用的首选。
同时,为了最大限度的避免每个最佳实践背后可能发生的不一致性问题,我们还需要切合业务的特点,在关键的场景上做一些保障一致性的设计(比如前述的营销在下单时使用数据库读而不是缓存读),这也显得尤为重要(毕竟如“背景”中所述,并不存在完美的技术方案)。
除了缓存与数据库分离的方案,还有两个业界已经应用的方案也值得我们借鉴:
阿里XKV
简单来讲就是在数据库上部署一个Memcache的Server,它直接绕过数据库层直接访问存储引擎层(如:InnoDB),同时使用KV client来进行数据的访问。
它的特点是数据实际上与数据库是强一致的,性能可以比使用SQL访问数据库提升5~10倍。
缺点也很明显,只能通过主键或者唯一键来访问数据(这只是相对SQL来说的,大多数缓存本来也就是KV访问协议)。
腾讯DCache
不用自行维护缓存与数据库两套存储,给开发人员统一的一套数据视图,由DCache在缓存更新后自行持久化数据。
缺点是支持的数据结构有限( key-value,k-k-row,list,set,zset ),未来也很难支持形如数据库表一样复杂的数据结构。