CMU 15445 学习笔记—3 Storage Manager
存储介质
一个数据库系统大致由以下几个不同的部分组成:
- query plan(执行计划)
- operator execution(执行器)
- access method(访问方法)
- buffer pool(缓冲池)
- disk manager(磁盘管理)
以及其他的的一些组成部分,例如并发控制、分布式等。
这个课程系列将会自底向上逐一介绍。

首先来看看存储管理,通常来说,不同的存储介质,在存储容量和速度上存在较大的差异,容量越大的介质速度越慢,反之容量越小的介质,速度越快。
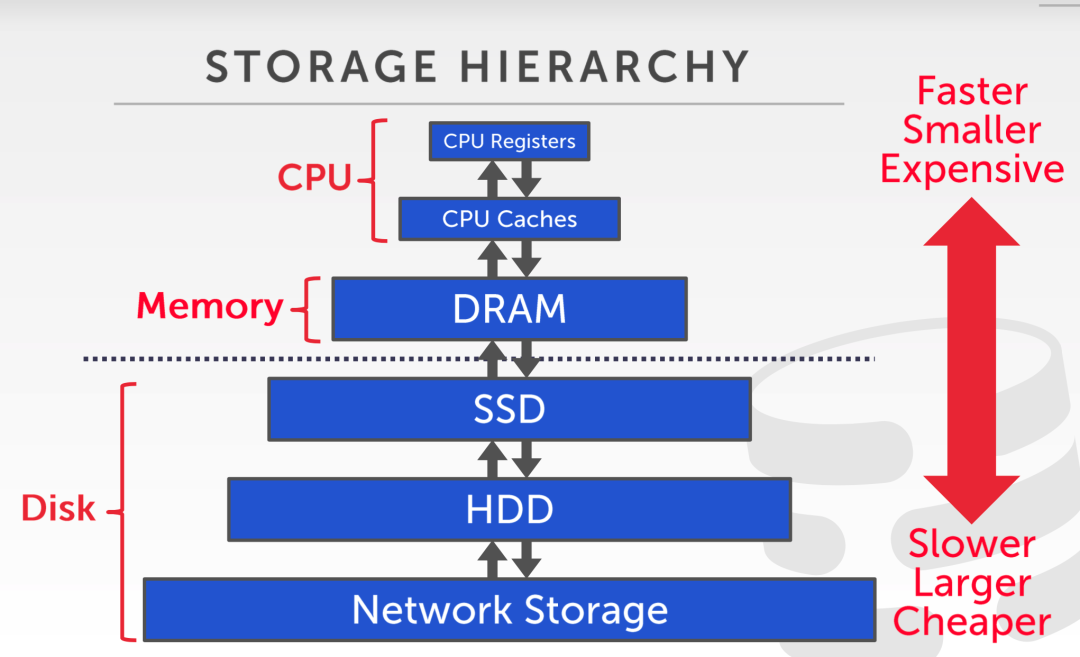
以上图为例,cpu 寄存器和高速缓存(L1、L2、L3),以及内存是常见的易失性存储,容量小速度快,但是掉电之后无法恢复,不能持久化保存数据。
而磁盘例如 SSD 或者 HDD,容量更大,但是访问速度慢,能够持久化保存数据。
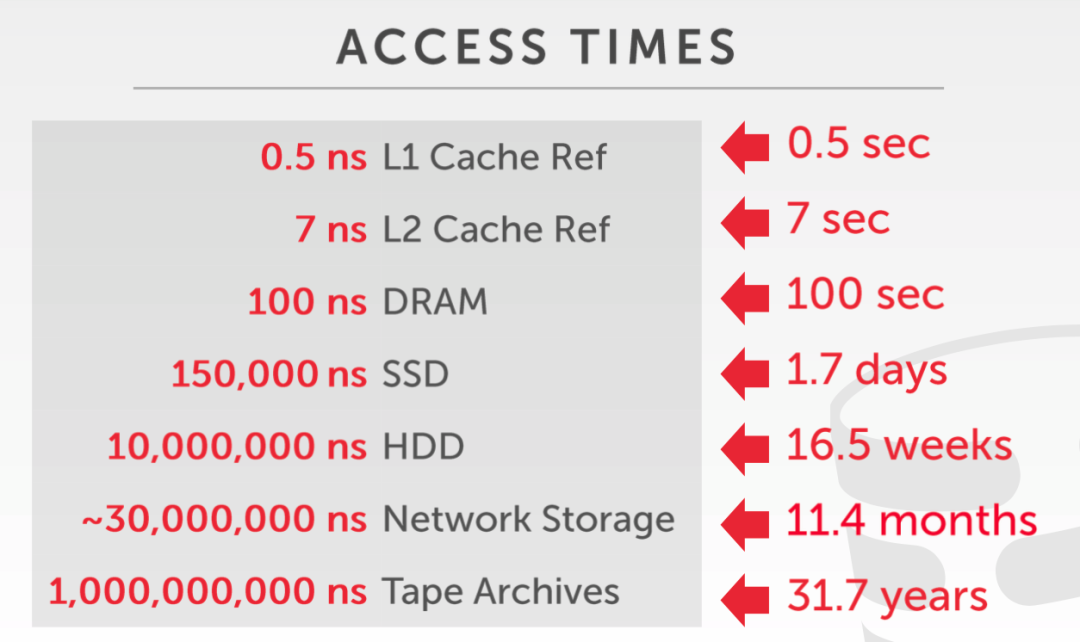
下面对这几种存储介质的访问速度做一个简单的量化(同比放大),可以看到 L1 缓存大概是秒级别的,而机械硬盘甚至长度16 周,容量越大访问速度越慢。
对于磁盘来说,顺序访问也比随机访问更快,因为磁盘的主要时间消耗在于寻道。
数据库系统对于磁盘管理的设计目标,主要是以下几个方面:
- 能够管理远超过 memory 容量的数据
- 读写磁盘开销巨大,因此需要尽量避免频繁读写磁盘,或者更加高效的读写磁盘,防止 write stall 带来的影响
- 尽量避免随机磁盘 IO
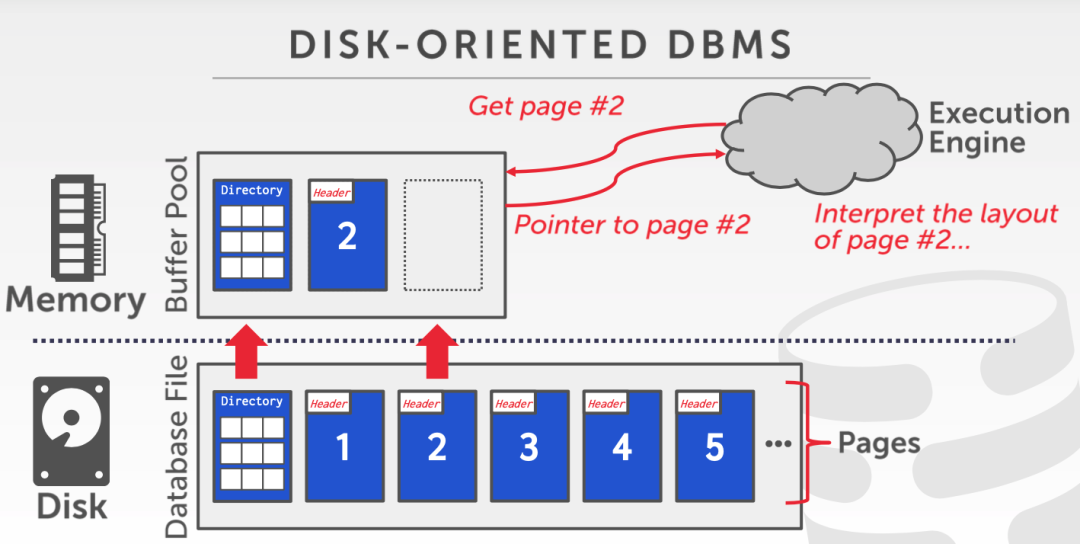
数据库中,内存和磁盘的结构和关系大致如下图,磁盘上的数据通常以 page 为单位进行组织,内存中维护了一个缓冲池 buffer pool,缓存了磁盘中的 page。
当上层的执行引擎需要读写数据时,首先从 buffer pool 中获取数据,如果 buffer pool 中没有,则从磁盘中加载到 buffer pool,然后返回到执行引擎中。
这样的组织方式比较类似操作系统提供的 MMap 机制,即内存映射。
内存映射(MMap)指的是将磁盘文件内容映射到内存地址空间中,进程访问该地址时,触发缺页异常,将磁盘的内容加载到物理内存中进行读写。
”
一个常见的问题是,为什么数据库中不直接使用操作系统提供的 MMap 机制,而是自己去实现内存 buffer 和 disk 的管理呢?
数据库的上层执行引擎通常是多线程并发执行,如果此时访问 MMap,访问的 page 可能会各不相同,由此可能频繁发生缺页中断,导致系统 stall。
而数据库对于磁盘管理有着更加定制化的需求:
- 以正确的顺序将脏页刷到磁盘
- 特定的预读策略
- buffer 替换策略
- 线程/进程调度
总之,数据库系统希望能够自己控制磁盘和内存管理,而不依赖于操作系统,满足自己特定的需求和场景。
补充知识: 在 PostgreSQL 中,底层的存储管理基于虚拟文件描述符,即 Virtual File Descriptior,简称 VFD,使用 vfd 的主要目的是绕开操作系统对同一个进程最大打开文件数的限制。
进程不直接持有操作系统的 fd,而是由数据库系统分配的 vfd,如果进程打开文件数达到了上限,那么会暂时关闭未被使用的文件。
在 vfd 之上,postgres 封装了操作磁盘文件的基本 API,例如打开、关闭、删除文件等,代码可参考: https://github.com/postgres/postgres/blob/master/src/backend/storage/file/fd.c https://github.com/postgres/postgres/blob/master/src/backend/storage/smgr/smgr.c
Page 概览
绝大多数数据库系统中的磁盘数据都是以 page 为单位进行组织的,所以先来详细看看磁盘 page 的结构。
数据库中的磁盘 Page 指的是一个有固定大小的文件块,Page 中通常可以存储元组、元信息、索引、日志等。每个 page 都有一个唯一的标识,称为 page id。
不同的数据库的 page size 是不同的,常见的几种如下:

在数据库系统中,page 肯定不止一个,那么如此多的 page 之间,需要进行统一管理,例如增加一个 page、删除一个 page、遍历所有的 page 等,该怎么组织这些 page 来实现这些目的呢?
最常见的组织方式叫做 heap file,heap file 指的是一个无序的 page 集合,page 是随机进行排列的。
heap file 有两种常见的组织方式:
- linked list
- page directory
linked list 是按照链表的方式组织 page,链表头有两个指针,一个指向 free page list,表示空闲的 page 列表,一个指向 data page list,指向实际存储数据的 page。
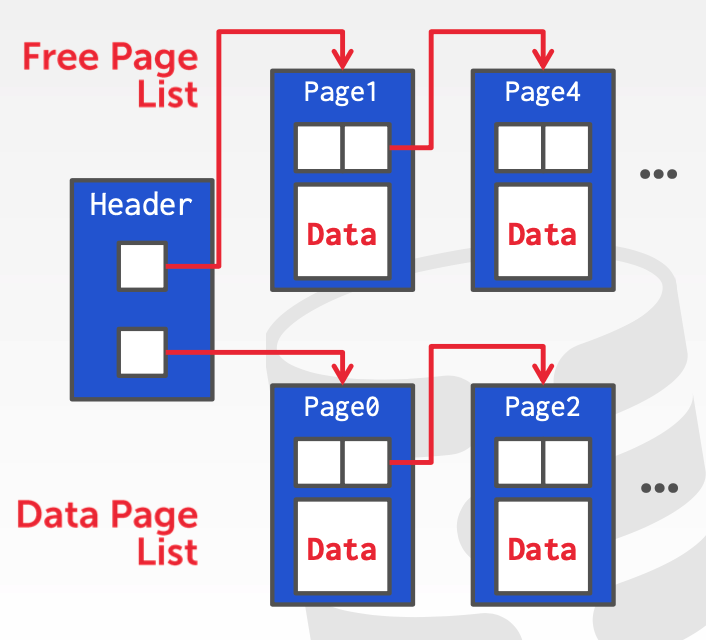
这种方式虽然直观,但是效率低下,因为 page 是通过指针完全无序排列的,查找 page 需要进行遍历,这种组织方式实际使用并不多。
另一种更加常用的方式是 page directory。
page directory 实际上就是维护了一个特殊的 page,这个 page 中存储的是其他 page 的位置,可以看做是 page 的元数据。
这个特殊的 page 还存储了每个 page 的 free space 空间等信息,便于上层应用对需要读写的 page 进行选择。
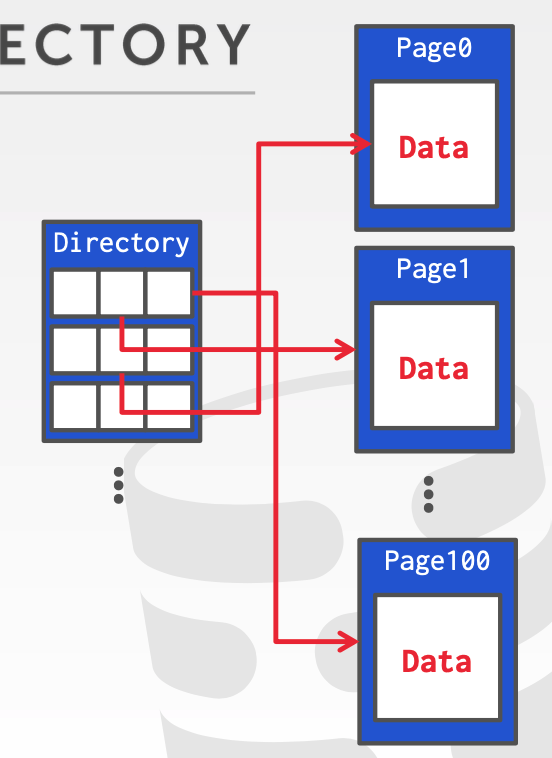
Page 组织方式
log structured
page 中数据可以通过类似日志的方式组织,即对 tuple 的增删操作都以日志追加的方式写到 page 中,这样做的最大好处是可以利用顺序 IO,写性能能够得到提升。
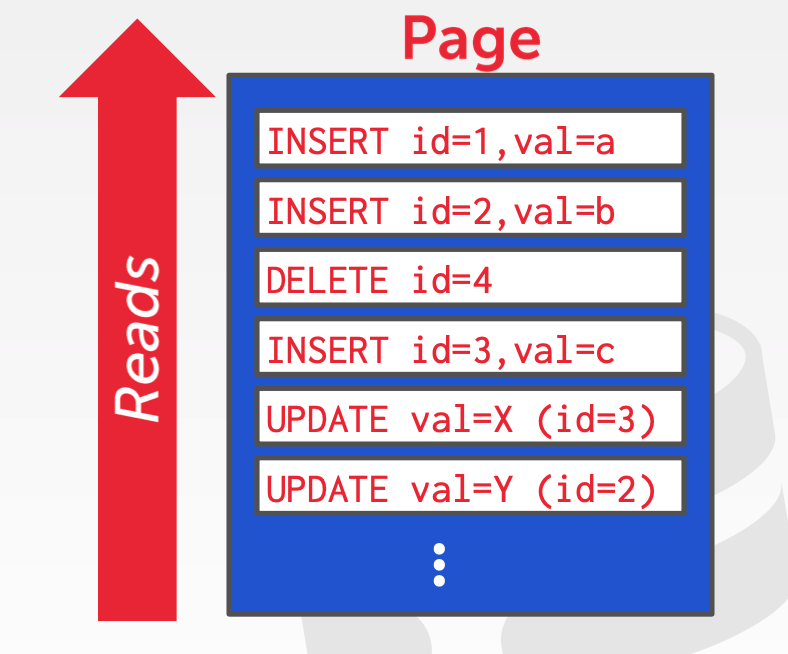
但是这种 log 式的组织方式,需要进行数据的回收处理(compaction),并且在读数据的时候,因为数据存在新旧多个版本,可能会有额外的磁盘 IO 消耗。
日志组织方式对于写多读少的应用非常合适,一些 NoSQL 引擎例如 leveldb、rocksdb、HBase 都采用了这种方式,但是在关系型数据库中,这种方式并不是主流。
slotted page
page 的内部结构,关系型数据库中常用的组织方式叫做 slotted page,其大致结构如下:
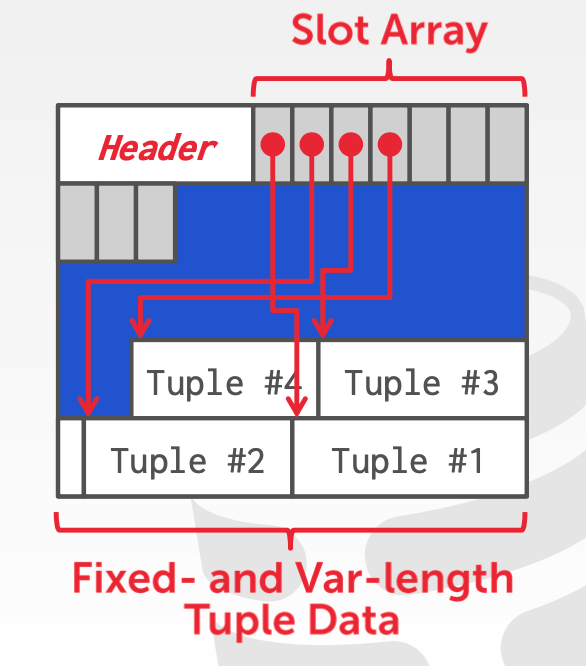
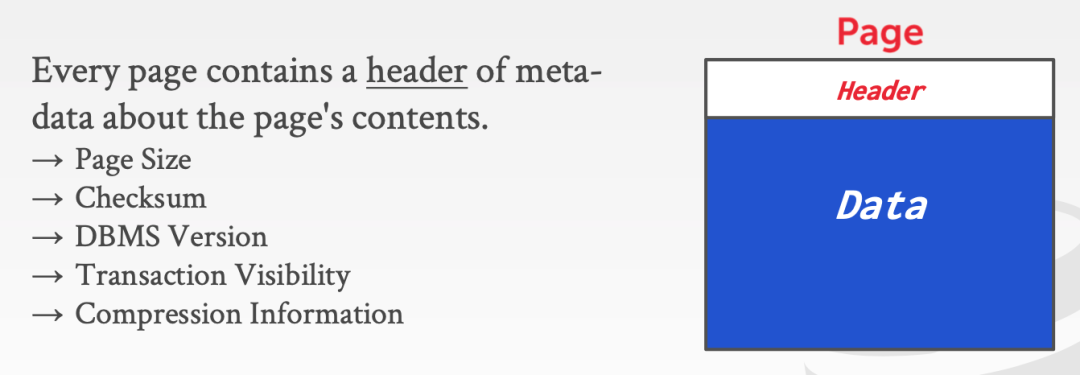
page 最靠前的部分,叫做 page header,这通常是由一个固定 size, header 中通常包含一些关于此 page 的元数据,例如 page 大小、校验和、DB 版本、事务信息、数据压缩信息。
header 之后的部分叫做 slot array,每一个 solt array 都存储了 tuple 的开始位置,这样能够快速定位到每条记录。
例如 postgres 中对于每条记录都有一个隐藏的 CTID,记录的是该 tuple 的物理位置,其内容是 page id + offset,即 tuple 所在页的 id,以及在页内的位置。
select *, ctid from some_table;
每个 tuple 实际上就是一个不定长的字节序列,里面存储了具体的数据信息。
读者有兴趣的话可以再看下 postgres 的磁盘 page 结构,与这里的 slotted page 基本上是一致的,代码: https://github.com/postgres/postgres/blob/master/src/include/storage/bufpage.h
Large Values
前面提到了一个 page 通常都有固定的 size,那么如果存储的数据太大,超过了 page 的大小,应该怎样存储这些数据呢?
最常见的方式是使用一个额外的 page 来存储,原来的 page 中保存一个指向它的指针,如果数据仍然很大,额外的 page 还是放不下,那么可以在新开一个 page,并且由上一个 page 指向它。
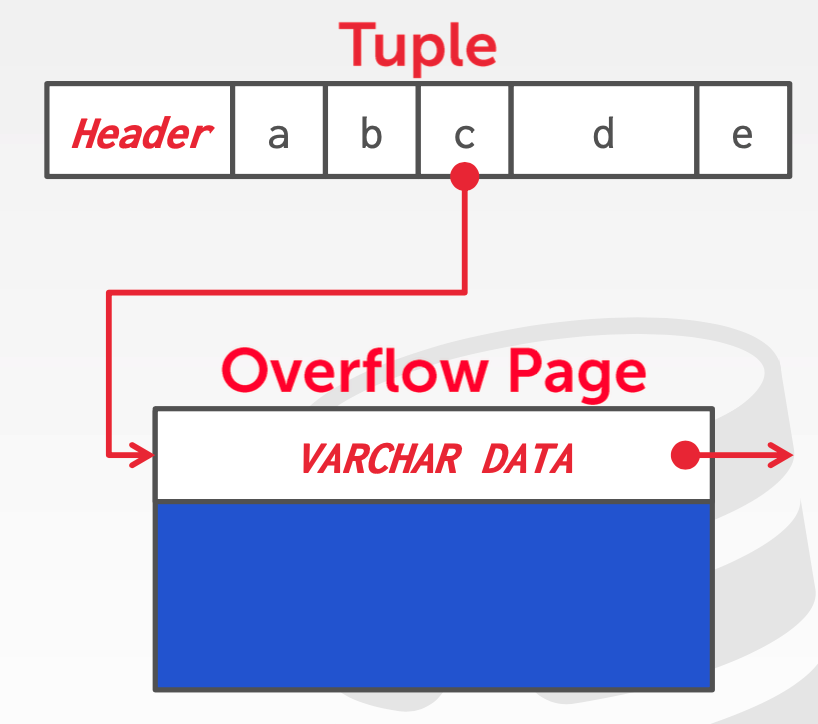
这个额外的 page 通常叫做 overflow page,不同的数据库有不同的称呼或做法,例如 PostgreSQL 中把这种存储叫做 TOAST。
Tuple 的结构
再来看一下 tuple 的内部结构,tuple 大致由两部分组成,header 和数据部分。

header 中主要存储了一些元数据信息,例如 tuple 的可见性(用于并发控制),用于判断 null 列的 bit map 等等。
postgres 中 tuple 的内部结构可以参考:https://github.com/postgres/postgres/blob/master/src/include/access/htup_details.h
Storage Model
最后再来看一下,在宏观的角度,对于不同 workload 的数据库的存储方式有什么区别。
目前根据不同的应用场景和数据读写特征,大致将数据库划分为了两种:OLTP 和 OLAP,他们的存储方式也存在很大的差异。
OLTP,即 On-Line Transaction Processing,在线事务处理,其特征是读写简单,通常是读/写一小部分数据,并且事务可保证数据的一致性。
目前大多数在线业务均使用 OLTP 类型的数据库,例如电商,通常选择、购买商品,针对一个用户,大多数情况下,都只会读取和更新一部分只关于这个用户的数据。
OLAP,即 On-Line Analytic Processing,在线分析处理,其特征是查询复杂,需要读取大批量数据进行统计分析。
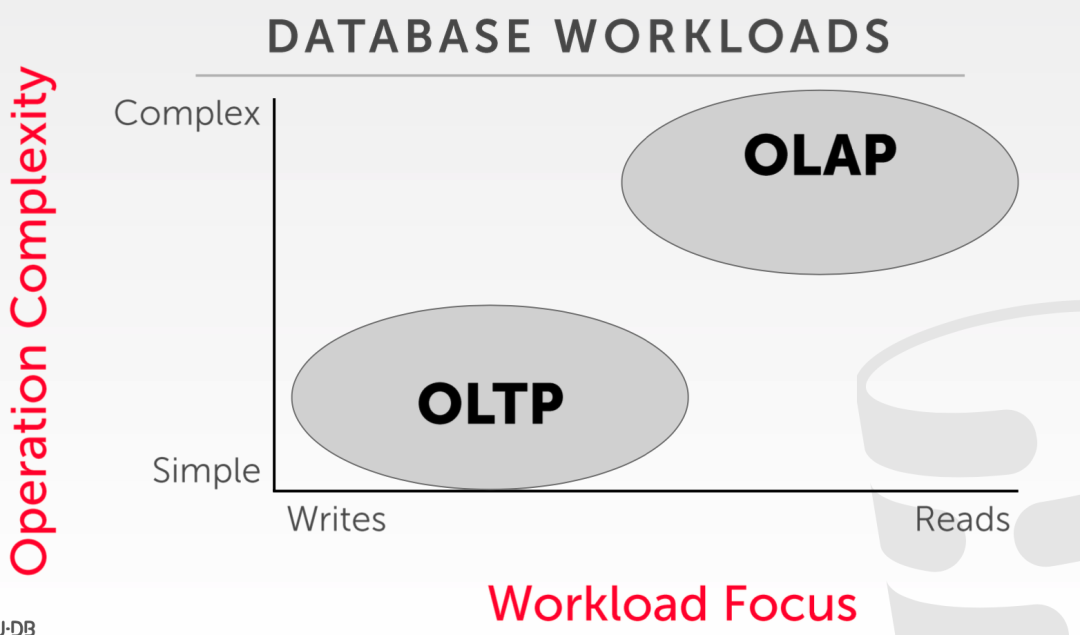
针对这两种不同的 workload,数据库中的数据组织上也有一些区别,分别是以行存和列存为主流。
行存是最常见、符合直观思维的存储模式,将不同属性的数据一行行的组织起来,并且存储到 page 当中。
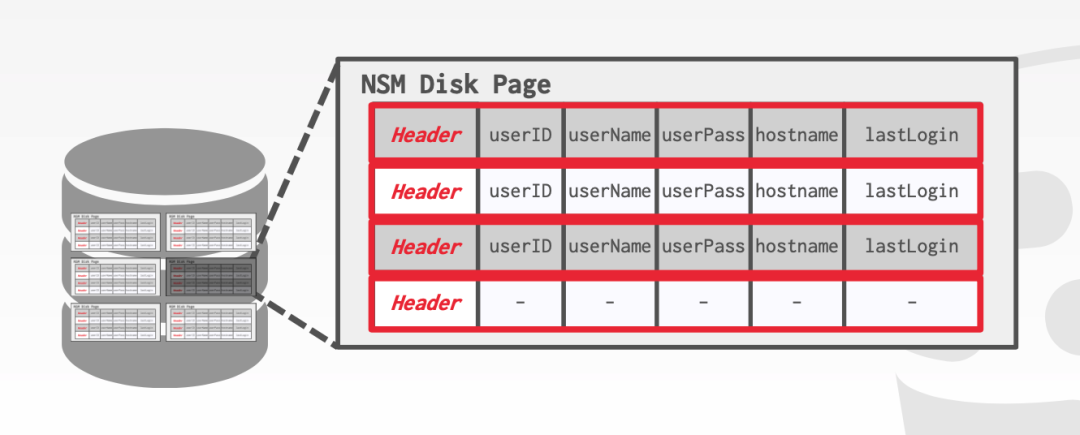
这样更适合 OLTP,因为能够非常方便的更新或者获取到某一条(或几条)具体的数据(点查)。
但如果我们的查询只需要取出一部分的列,而不是一个 table 中的全部列,那么这样会造成一定的浪费,因为我们可能会把毫不相关的列取出来然后丢弃掉。
列存的组织方式则完全不同,它会将有相同属性的数据一起组织起来,这样更方便大批量扫描数据。

具体的存储方式,是将表中一个列的数据存到 page 中。由于具有相同属性的数据,会更可能有类似的特征,所以这样的数据组织方式更适合压缩,节省存储空间。
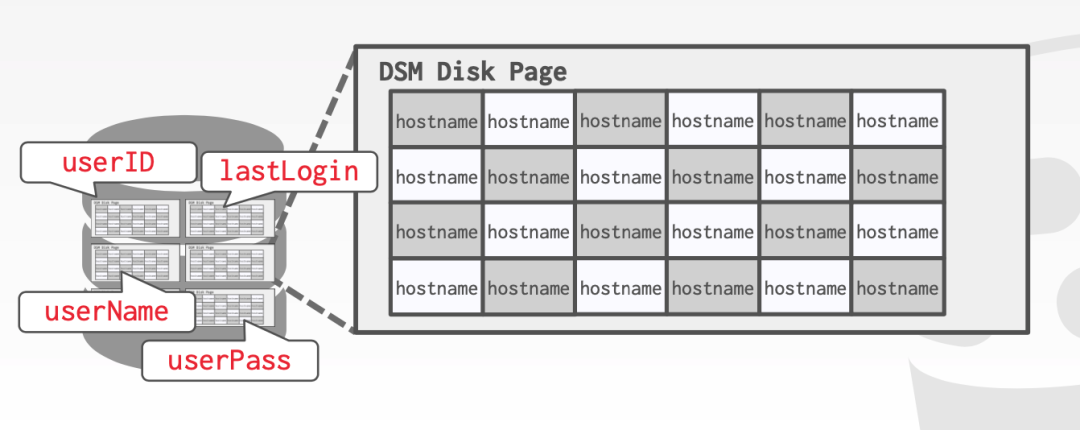
列存更适合 OLAP 类型的数据库。
这一节主要讲述了数据库的存储管理,并且掺杂了一些 PostgreSQL 的 demo,大家可以自行参考。下一节会向上一层,来看看对于内存 buffer pool 的管理。