接口性能优化的 15 个技巧
作为后端研发同学为了几两碎银,没日没夜周旋于各种人、各种事上。
如果你要想成长的更快,就要学会归纳总结,找到规律,并且善用这些规律。
就比如工作,虽然事情很多、也很繁琐,但如果按照性质归下类,我觉得可以分为两大类:
1、业务类,如:产品要做一个红包活动,下周一就要上线,于是研发同学就吭哧吭哧,周末加班不睡觉也要赶出来
2、技术类,如:架构升级、系统优化等,这类事情对技术能力有一定要求,通常要求有一定的项目经验的同学来 owner
关于业务类的内容很大程度依赖于产品同学的节奏,研发更多是被动角色,我们能做的是就是多跟产品聊天,「实时」了解产品的最新动向,培养自己的业务 sense,给自己多预留一定的buffer时间可以去做技术调研、技术储备。
工作过一段时间同学一般都经历过,产品变化节奏很快,经常都是倒排时间,让研发苦不堪言。
至于技术类,相对就比较温和的多了,不过也非常考验研发的技术实力。
今天,我们就来聊下关于接口性能优化有哪些技巧?
1、本地缓存
本地缓存,最大的优点是应用和cache是在同一个进程内部,请求缓存非常快速,没有过多的网络开销等,在单应用不需要集群支持或者集群情况下各节点无需互相通知的场景下使用本地缓存较合适。缺点也是因为缓存跟应用程序耦合,多个应用程序无法直接的共享缓存,各应用或集群的各节点都需要维护自己的单独缓存,对内存是一种浪费。
常用的本地缓存框架有 Guava、Caffeine 等,都是些单独的jar包 ,直接导入到工程里即可使用。
我们可以根据自己的需要灵活选择想要哪个框架

使用门槛比较低, 大家可以自行网上搜索相应的教程,这里就不展开了。
本地缓存适用两种场景:
- 对缓存内容时效性要求不高,能接受一定的延迟,可以设置较短过期时间,被动失效更新保持数据的新鲜度
- 缓存的内容不会改变。比如:订单号与uid的映射关系,一旦创建就不会发生改变
注意问题:
- 内存 Cache 数据条目上限控制,避免内存占用过多导致应用瘫痪。
- 内存中的数据移出策略
- 虽然实现简单,但潜在的坑比较多,最好选择一些成熟的开源框架
2、分布式缓存
本地缓存的使用很容易让你的应用服务器带上“状态”,而且容易受内存大小的限制。
分布式缓存借助分布式的概念,集群化部署,独立运维,容量无上限,虽然会有网络传输的损耗,但这1~2ms的延迟相比其更多优势完成可以忽略。
优秀的分布式缓存系统有大家所熟知的 Memcached 、Redis。对比关系型数据库和缓存存储,其在读和写性能上的差距可谓天壤之别,redis单节点已经可以做到 8W+ QPS。设计方案时尽量把读写压力从数据库转移到缓存上,有效保护脆弱的关系型数据库。
注意问题:
- 缓存的命中率,如果太低无法起到抗压的作用,压力还是压到了下游的存储层
- 缓存的空间大小,这个要根据具体业务场景来评估,防止空间不足,导致一些热点数据被置换出去
- 缓存数据的一致性
- 缓存的快速扩容问题
- 缓存的接口平均RT,最大RT,最小RT
- 缓存的QPS
- 网络出口流量
- 客户端连接数
3、并行化
梳理业务流程,画出时序图,分清楚哪些是串行?哪些是并行?充分利用多核 CPU 的并行化处理能力
如下图所示,存在上下文依赖的采用串行处理,否则采用并行处理。
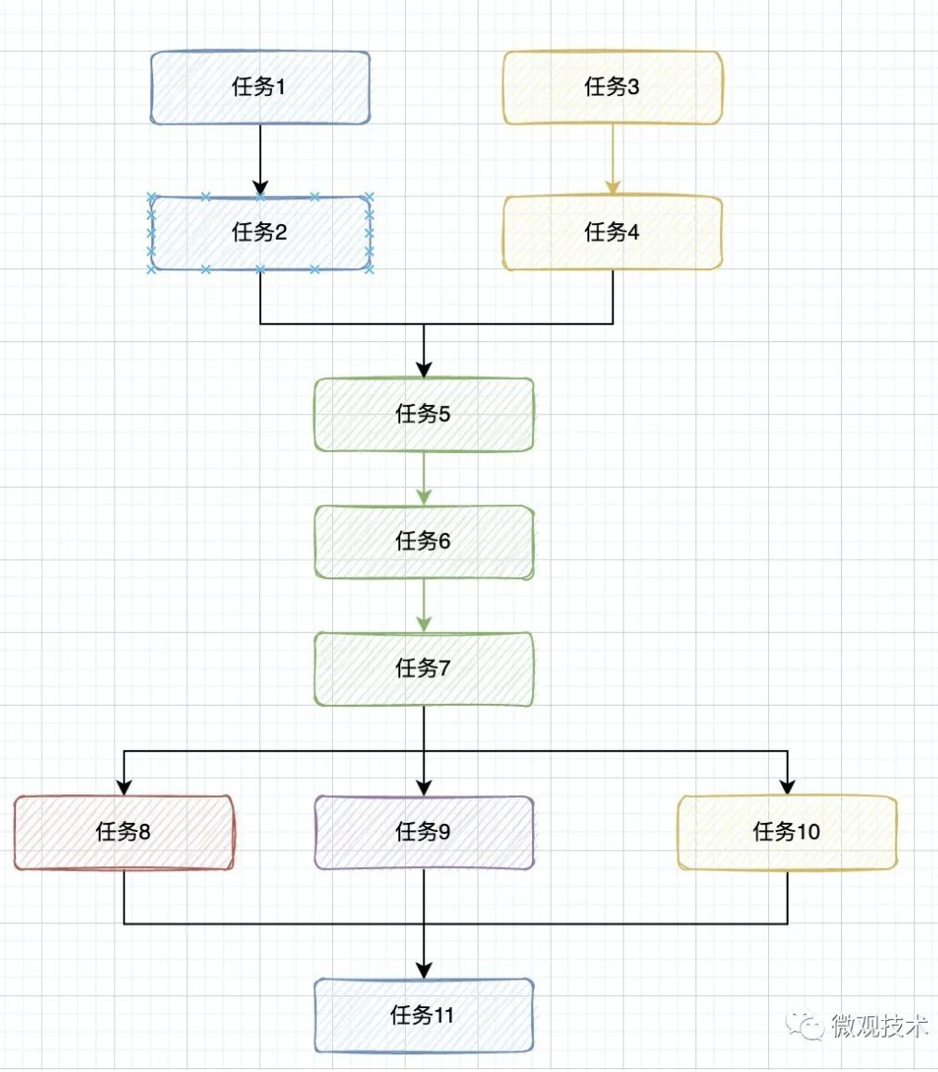
JDK 的 CompletableFuture 提供了非常丰富的API,大约有50种 处理串行、并行、组合以及处理错误的方法,可以满足我们的场景需求。
之前写的文章:[搞定 CompletableFuture,并发异步编程和编写串行程序还有什么区别?]
4、异步化
一个接口的 RT 响应时间是由内部业务逻辑的复杂度决定的,执行的流程约简单,那接口的耗费时间就越少。
所以,普遍做法就是将接口内部的非核心逻辑剥离出来,异步化来执行。
下图是一个电商的创建订单接口,创建订单记录并插入数据库是我们的核心诉求,至于后续的用户通知,如:给用户发个短信等,如果失败,并不影响主流程的完成。
我们会将这些操作从主流程中剥离出来。
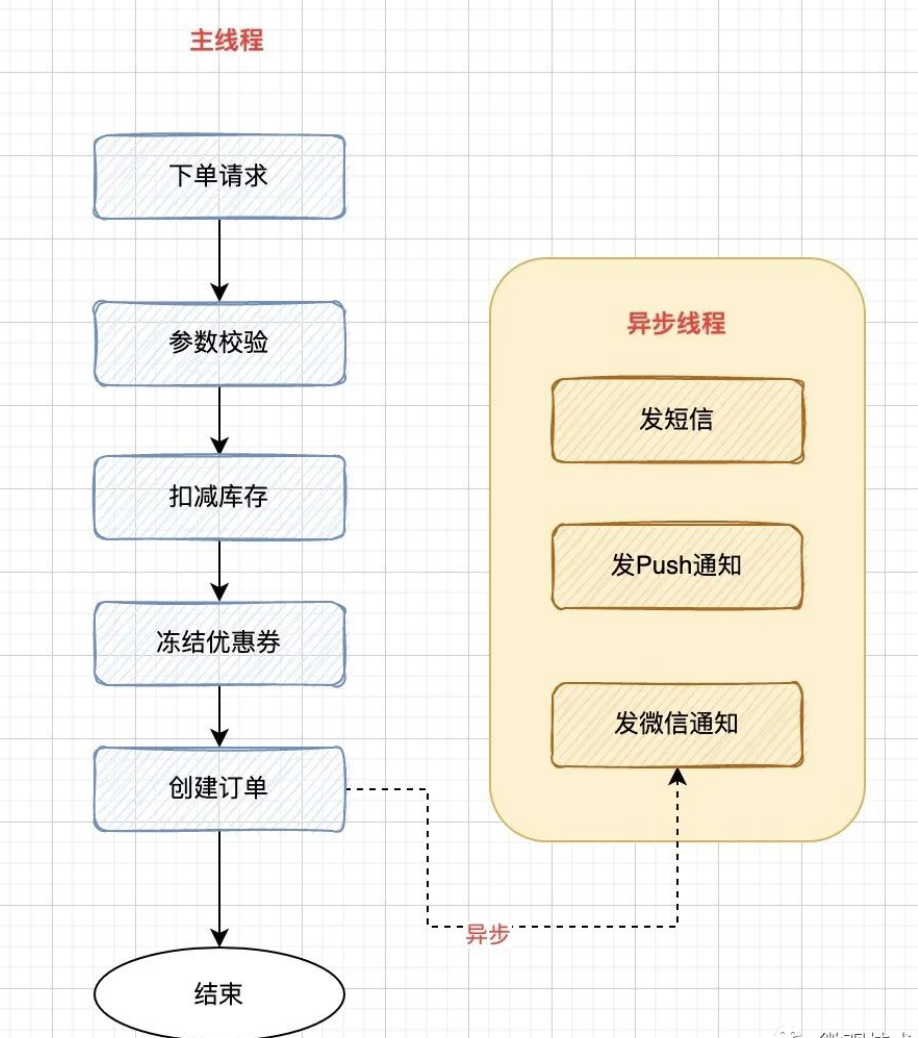
业务的普遍做法就是,下单成功后,发送一条异步消息到MQ 服务器,由消费端监听 topic,异步消费执行,通过发布/订阅 模式也能支持一些新的消费任务的快速接入。
5、池化技术
TCP 三次握手非常耗费性能,所以我们引入了 Keep-Alive 长连接,避免频繁的创建、销毁连接。
池化技术也是类似道理,将很多能重复使用的对象缓存起来,放到一个池子里,用的时候去申请一个实例对象 ,用完后再放回池子里。
池化技术的核心是资源的“预分配”和“循环使用”,常见的池化技术的使用有:线程池、内存池、数据库连接池、HttpClient 连接池等
连接池的几个重要参数:最小连接数、空闲连接数、最大连接数
比如创建一个线程池:
new ThreadPoolExecutor(3, 15, 5, TimeUnit.MINUTES,
new ArrayBlockingQueue<>(10),
new ThreadFactoryBuilder().setNameFormat("data-thread-%d").build(),
(r, executor) -> {
if (r instanceof BaseRunnable) {
((BaseRunnable) r).rejectedExecute();
}
});6、分库分表
MySQL的底层 innodb 存储引擎采用 B+ 树结构,三层结构支持千万级的数据存储。
当然,现在互联网的用户基数非常大,这么大的用户量,单表通常很难支撑业务需求,将一个大表水平拆分成多张结构一样的物理表,可以极大缓解存储、访问压力。
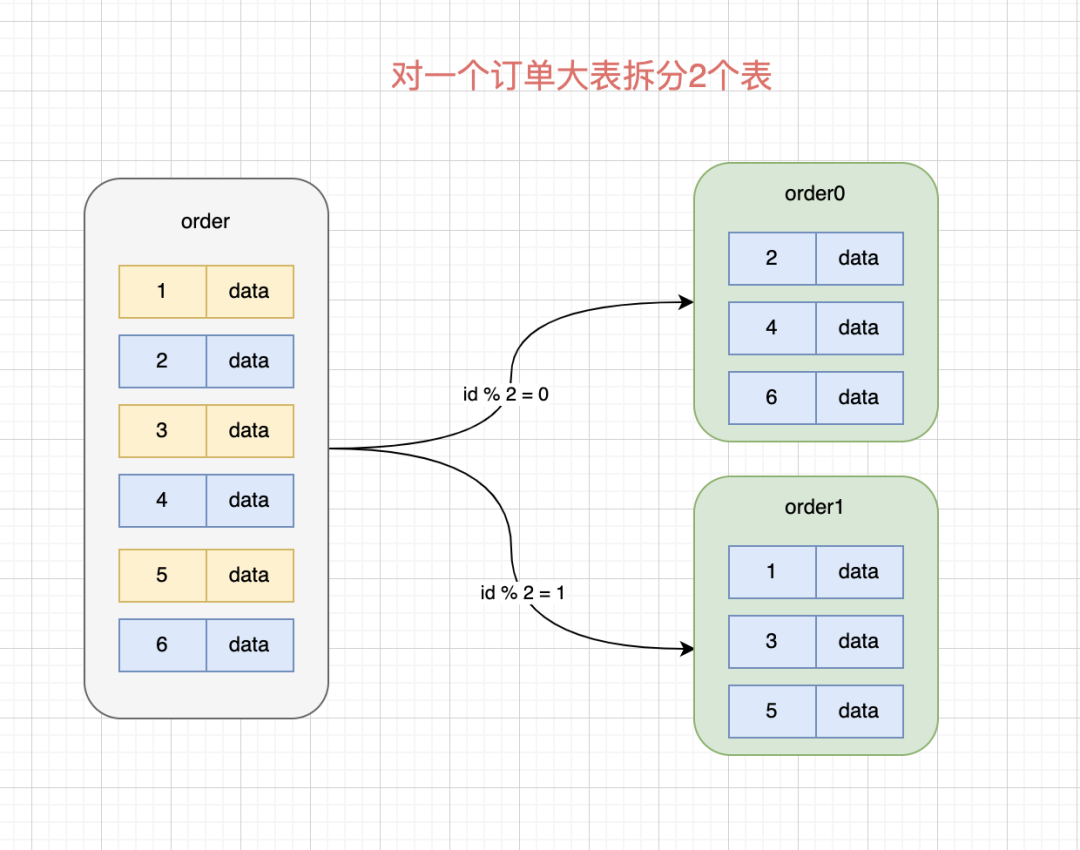
分库分表也可能会带入很多问题:
- 分库分表后,数据在分表内产生数据倾斜
- 如何创建全局性的唯一主键id
- 数据如何路由到哪一个分片
每一个问题展开都要花费很长篇幅来讲解,这里主要讲接口性能优化的方案汇总,就不展开细讲了。
关于分库分表,市场受欢迎的开源框架是 sharding-jdbc,目前已经捐赠给Apache并启动孵化
之前写的文章:[为什么要分库分表?]
7、SQL 优化
虽然有了分库分表,从存储维度可以减少很大压力,但「富不过三代」,我们还是要学会精打细算,就比如所有的数据库操作都是通过 SQL 来执行。
一个不好的SQL会对接口性能产生很大影响。
比如:
- 搞了个深度翻页,每次数据库引擎都要预查非常多的数据
- 索引缺失,走了全表扫描
- 一条 SQL 一次查询 几万条数据
SQL 优化的经验非常多,比如:
- SQL 查询时,尽量不要使用 select * ,而是 select 具体字段
- 如果只有一条查询结果(或者最大值、最小值),建议使用 limit 1
- 索引不宜太多,一般控制在 5个以内
- where 语句中尽量避免使用 or来连接条件。or 可能会导致索引失效,从而全表扫描
- 索引尽量避免建在有大量重复数据的字段上,如:性别
- where 、 order by 涉及的列上建索引,避免全表扫描
- 更多.....
SQL 优化的内容非常多,这里就不展开了
之前写的一篇文章:[SQL 优化有哪些技巧?]
8、预先计算
有很多业务的计算逻辑比较复杂,比如页面要展示一个网站的 PV、微信的拼手气红包等
如果在用户访问接口的瞬间触发计算逻辑,而这些逻辑计算的耗时通常比较长,很难满足用户的实时性要求。
一般我们都是提前计算,然后将算好的数据预热到缓存中,接口访问时,只需要读缓存即可
是不是一下子就快了很多。

9、事务相关
很多业务逻辑有事务要求,针对多个表的写操作要保证事务特性。
但事务本身又特别耗费性能,为了能尽快结束,不长时间占用数据库连接资源,我们一般要减少事务的范围。
将很多查询逻辑放到事务外部处理。
另外在事务内部,一般不要进行远程的 RPC 接口访问,一般占用的时间比较长。
10、海量数据处理
如果数据量过大,除了采用关系型数据库的分库分表外,我们还可以采用 NoSQL
如:MongoDB、Hbase、Elasticsearch、TiDB
NoSQL 采用分区架构,对数据海量存储能较好的支持,但是事务方面可能没那么友好。
每一个 NoSQL 框架都有自己的特色,有支持 搜索的、有列式存储、有文档存储,大家可以根据自己的业务场景选择合适的框架。
11、批量读写
当下的计算机CPU处理速度还是很多的,而 IO 一般是个瓶颈,如:磁盘IO、网络IO。
有这么一个场景,查询 100 个人的账户余额?
有两个设计方案:
方案一:开单次查询接口,调用方内部循环调用 100 次
方案二:服务提供方开一个批量查询接口,调用方只需查询 1 次
你觉得那种方案更好?
答案不言而喻,肯定是方案二
数据库的写操作也是一样道理,为了提高性能,我们一般都是采用批量更新。
12、锁的粒度
并发业务,为了防止数据的并发更新对数据的正确性产生干扰,我们通常是采用 加锁 ,涉及独享资源每次只能是一个线程来处理。
问题点在于,锁是成对出现的,有加锁就是释放锁
对于非竞争资源,我们没有必要圈在锁内部,会严重影响系统的并发能力。
控制锁的范围是我们要考虑的重点。
之前写过一篇常用的锁有哪些,[聊聊 13 种锁的实现方式]
13、上下文传递
带团队对小伙伴有要求,代码必须要有 code review 环节,review 同学代码经常发现一个问题。
当需要一个数据时,如果没有调 RPC 接口去查,比如想用户信息这种通用型接口
因为前面要用,肯定已经查过。但是我们知道方法的调用都是以栈帧的形式来传递,随着一个方法执行完毕而出栈,方法内部的局部变量也就被回收了。
后面如果又要用到这个信息,只能重新去查。
如果能定义一个Context 上下文对象,将一些中间信息存储并传递下来,会大大减轻后面流程的再次查询压力。
14、空间大小
如何创建一个集合,这还不简单,很快我们就写出下面代码
List<String> lists = Lists.newArrayList();
如果说,要往里面插入 1000000 个元素,有没有更好的方式?
我们做个试验:
场景一:

结果:1000000 次插入 List,花费时间:154
场景二:

结果:1000000 次插入 List,花费时间:134
如果我们预先知道集合要存储多少元素,初始化集合时尽量指定大小,尤其是容量较大的集合。
ArrayList 初始大小是 10,超过阈值会按 1.5 倍大小扩容,涉及老集合到新集合的数据拷贝,浪费性能。
15、查询优化
避免一次从 DB 中查询大量的数据到内存中,可能会导致内存不足,建议采用分批、分页查询