探秘HashMap的实现原理
前言
HashMap主要用于存储键值(key-value)对数据的数据结构,在日常开发中出镜率极高,本篇文章主要对其设计原理进行讲解。
本篇文章主要涉及以下几个内容:
- 问题描述
- HashMap 底层原理
- HashMap hash设计函数
- HashMap key映射数组下标
- HashMap hash冲突
- HashMap put操作
- HashMap 扩容
- HashMap 为什么要引入红黑树
- 问题解答
问题描述
HashMap 在键值对存储与查询的功能中一直都是以高效著称,但在某些使用错误的场景下可能会导致性能严重下降,下面看一个具体的例子:
public static void main(String[] args) {
long start = System.currentTimeMillis();
int n = 10000;
Map<Key, Integer> map = new HashMap<>();
for (int i = 0; i < n; i++) {
map.put(new Key(i), i);
}
for (int i = 0; i < n; i++) {
Integer v = map.get(i);
}
System.out.println(System.currentTimeMillis() - start); // 平均输出 1400ms(仅供参考,输出结果与具体的机器硬件有关)
}
@AllArgsConstructor
public static class Key {
private Integer id; //一级配置id
@Override
public int hashCode() {
return 1;
}
//省略equals方法
}上面的代码中往 HashMap 插入了 10000 条数据并将这 10000 条数据都查询了一遍,平均耗时:1400ms,并且数据规模越大,执行时间增加越明显。
再看下面一个例子:
public static void main(String[] args) {
long start = System.currentTimeMillis();
int n = 10000;
Map<Key, Integer> map = new HashMap<>();
for (int i = 0; i < n; i++) {
map.put(new Key(i), i);
}
for (int i = 0; i < n; i++) {
Integer v = map.get(i);
}
System.out.println(System.currentTimeMillis() - start); // 平均输出 10ms
}
@AllArgsConstructor
public static class Key {
private Integer id; //一级配置id
@Override
public int hashCode() {
return Objects.hash(id);
}
//省略equals方法
}上面的代码中同样往 HashMap 插入了 10000 条数据并将这 10000 条数据都查询了一遍,平均耗时:10ms,并且执行时间不会随着数据规模的增大发生显著的增加。
为什么同样数据规模的代码在执行耗时上相差近了 100 多倍呢?如果你仔细看的话会发生上面两段代码的差别仅仅是 Key 中的 hashCode() 方法逻辑不同而已,那么这个方法在 HashMap 中起到什么作用?看完今天这篇文章,相信你就会有答案。
HashMap的底层原理
HashMap的使用方式很简单,但它底层是如何实现的呢?
HashMap主要使用的是数组+链表的方式实现,先看下在HashMap中如何巧妙的将数组和链表组合在一起使用,如下所示:
public class HashMap<K,V> {
...省略其他代码
Node<K,V>[] table; //声明table数组
...省略其他代码
}
//table数组中存储的数据结构
class Node<K,V> {
final int hash; //键的hash值
final K key; //键
V value; //值
Node<K,V> next; //指向下一个节点,构成单向链表
}可以看到,在HashMap中定义了一个数组table,table中的每个元素是一个Node节点。Node中使用key和value分别存放我们往HashMap中添加的每个键值对,其中还有一个next指针用于指向当前节点的下一个节点,多个节点之间通过next指针串联成了一条单向链表。

为什么要使用数组呢?
数组的一个特性——支持按照下标随机访问数据,可以实现在O(1)的时间复杂度获取到数组中的元素,所以我们只要想办法将存入的键值对按照某种映射规则将数据映射到某个数组的某个下标位置,当要获取数据时就可以使用相同的映射规则映射到数组的某个位置,从而实现数据的快速定位。实际上,这一映射规则便是通过hash函数实现。
HashMap的hash设计函数
前面提到要将键值对数据映射到HashMap底层table数组的某个下标位置要借助hash函数实现,具体要怎么实现呢?
我们知道,数组的下标是整型类型,也就是int类型,但HashMap的键值对是可以为任意的对象类型(基本数据类型要使用对应的包装类型),那么怎么将键值对映射为整型的数组下标呢?
在java中,Object是所有对象的父类,在Object中有一个hashCode函数,这个函数返回对象的hashCode,对象的hashCode是一个整型,可以通过这个hashCode与数组table的大小执行取余操作,这样就可以得到一个数组的下标值,也实现了将对象映射到数组的某个下标位置。
下面看看HashMap的hash函数实现:
//返回对象的hash值
int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}可以看到,HashMap的hash函数是依赖于对象的hashCode,将hashCode的高16位与低16位进行异或操作,最终得到一个hash值。
因为hashCode是一个int类型的值,int类型在java中使用4个字节表示,也就是32个二进制位,而HashMap具体的hash值是通过将hashCode的高16位与hashCode的低16位进行异或(^)的方式计算得到,进行异或的原因是为了让hashCode的高位也参与到hash值的计算,后续通过hash值计算数组下标时,使得hashCode的高16位也能参与到实际的运算中,最终多个使得hash值在数组中分布更加均匀,减少了hash冲突的概率。
HashMap中的key映射数组下标
通过hash函数的计算,可以得到键值对中键的hash值,得到hash值后,如何映射到数组table的某个下标呢?
一个简单的方式可以直接通过hash与数组大小进行求余得到,但HashMap中并不是这样简单的设计,而是通过如下的方式进行计算:
//计算key的哈希值
int hash = hash(key);
//获取数组的大小
int n = tab.length;
//通过hash值与数组大小-1进行位与计算得到数组的一个下标值
int i = (n - 1) & hash;
//获取到数组下标对应的链表
Node node = table[i];为什么HashMap要使用这种方式计算数组下标呢?看下面的一个例子:
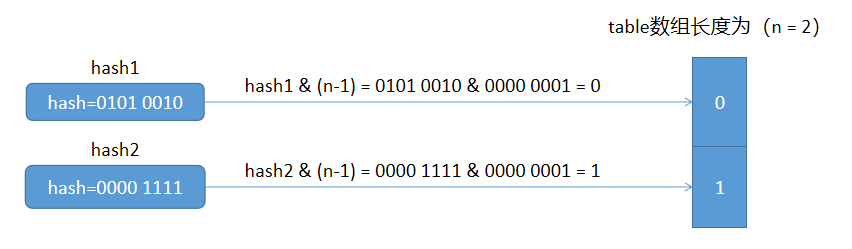
通过上面的例子可以看出,将任意一个 hash 值与 n - 1 进行位与运算,都会得到一个小于n的值,如果n是数组的长度大小,那么得到的值就可以作为数组的下标值。
熟悉HashMap的朋友一定知道,HashMap的数组table的长度大小会保持为2的n次方,也就是1,2,4,8,16...,那么为什么要这么设计呢?
看下面的一个例子:

上面的例子中n=4,而 n - 1 = 3 的二进制位 0000 0011,我们发现该二进制最右边的两位都是1,前面的值都是0。任何值与0进行位与操作得到的结果都是0,也就是在这个例子中只有最右边的两个1参与到具体的下标的运算过程,因此最终hash值计算的下标可能落在是0、1、2、3的范围内。
再看下面一个例子:
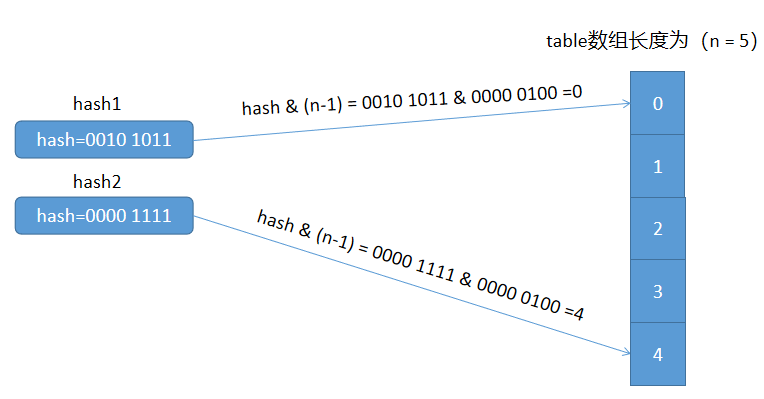
上面的例子中n=5,而 n - 1 = 4 的二进制位 0000 0100,我们发现该二进制只有一个二进制位为1,其它的二进制位都是0。任何值与0进行位与操作得到的结果都是0,也就是实际参与到下标的映射运算只有一个二进制位,因此不同的hash值最终算出的下标结果只能有 0 和 4 这两种情况,显然这个例子中映射出来的结果是不均匀的,对应到数组中,也就是数组下标的为1,2,3的位置永远不会存数据。
通过上面两个例子,相信你已经能知道为什么HashMap的数组大小要保持为2的n次方,其实是为了使不同的hash值通过映射后,能够均匀的分布到table数组的每个位置中。
再回过头来看下hash函数实现中,为什么要将hashCode的高16位与第16位进行异或操作,其实是因为数组的大小n一般不会很大,参与到hash值下标的映射运算中其实只用到低位的二进制位,因此为了让hashCode的高16位也参与到运算中,就将hashCode的高16位与第16位进行异或操作,使得hash值的高16位也能参与到数组下标映射的运算中,最终实现映射结果在数组table中分布的更加均匀。
什么是hash冲突?
数组的空间大小固定会用完,因此随着我们往HashMap中添加的元素越来越多,不可避免的就会将整个数组填充满。
有个著名的鸽巢理论,说的是假如有10个鸽巢,但是有11只鸽子,11只鸽子必须全部进入到鸽巢中,因为鸽子的数量大于鸽巢的数量,因此不管怎么样都会出现某个鸽巢中的鸽子数量大于1的情况。
HashMap也是类似,当多个数据存储到数组table中时,因为table大小固定,随着存储的数据增多,不可避免的会出现多个hash值映射到table数组中的同一个位置,这种情况就叫做hash冲突。
而使用链表的作用就是解决hash冲突,如果多个元素映射到table数组的同一个位置时,则将这些数据追加到链表中,与鸽巢理论类比就是多只鸽子进入到同一个鸽巢。
HashMap的put操作
HashMap的put操作主要用于将键值对数据添加到HashMap中,在添加的过程中,如果键的hash值发生了冲突,就会将当前的键值对添加到产生冲突对应的链表中;另外如果当前添加的键在HashMap中已经存在,则会使用新添加值覆盖已存在的值。
主要执行流程如下:
- 通过hash(key)函数计算得到key的hash值;
- 将key的hash值与数组table的大小(n - 1)进行位与操作,得到key在table数组中映射的下标位置index;
- 判断table数组的下标index位置的值是否为null,如果为null,则说明当前的key是第一个映射到该位置的元素,则直接将key-value封装为Node节点添加到该位置即可;
- 如果table数组的下标index位置的值不为null,则说明已经发生了hash冲突,也就是多个hash值都映射到了同一个数组位置,此时要将多个冲突的键值对数据追加到table数组对应位置的链表上,追加逻辑是遍历链表找到链表的尾结点,然后将新的键值对添加到链表的尾部;
- 在添加键值对的过程中,如果当前的键在hashMap中已经存在,则会用当前添加的键值对的值覆盖已存在的键值对的值。具体判断键是否存在的逻辑是:比较两个键的hash值是否相等,再通过==比较两个key是否指向内存中的同一个位置,如果两个key不是指向同一个位置,则再通过key的equals方法比较两个key是否相等,如下所示:
//如果hash值相等,再通过 == 或者 equals 比较
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))HashMap的扩容
当调用put方法添加数据到HashMap后,会判断当前HahMap中存储的数据量是否已经达到扩容的阈值,如果已经达到扩容的阈值,就会对HashMap底层的数组table进行扩容,以此来减少hash冲突。
为什么需要扩容?
通过前面的讲解我们知道,数组的大小有限,随着添加元素的增多,出现hash冲突,在数组中发生冲突的位置,会通过链表的方式将多个hash冲突的键值对添加到链表的尾部。
如果我们不对底层的数组进行扩容操作,随着数据量的增大,发生冲突的概率会增大,极端情况下,数组的所有位置都已经存放了数据,那之后每次添加数据时都会发生hash冲突,而且发生冲突后链表长度会变长,最终会导致每次从HashMap中获取或者添加数据的操作变得低效。
当我们对底层的数组进行扩容后,底层的数组长度就变长了,数组长度变长后,会导致已存在的hash值映射到数组中的下标位置发生变化,数组下标的计算公式如下所示:
int i = hash % (n - 1);
因为hash值没有改变,数组长度n改变了,导致最终计算出来的数组下标 i 也发生了变化,因此我们需要对原来的所有键进行重新下标位置,使其能够映射到扩容后的数组上面,然后再将旧数组中的数据移动到扩容后的数组中。
扩容后,在HashMap整体数据量不变的情况下,底层的table数组变长了,对应的发生冲突的链表长度就会变短,从链表中查询数据的速度就会提高;另外由于table数组长度变长,之后再添加数据到HashMap中也会降低hash冲突的概率,从而提升了整体的执行效率。
何时进行扩容?
HashMap中的负载因子loadFactory主要用于控制何时进行扩容,先看下loadFactory的计算方式:
loadFactory = 已添加的数据个数 / table数组的长度
从上述公式中,可以看到如果table数组的长度固定,那么往HashMap中添加的数据越多,loadFactory也就越大,当loadFactory大于等于1时,意味table数组已经没有空闲位置,之后往HashMap中添加元素将发生大量的冲突,发生冲突后的链表也会越来越长,最终就会导致整个HashMap的操作效率下降。
如果保证HashMap的负载因子loadFactory不变,那么随着我们往HashMap添加元素的过程中,table数组的长度也要在适当的时候进行扩容,从而减低后续hash冲突的概率,保证HashMap性能不至于下降的太多。
如果设置loadFactory小于1,则说明已添加的数据量小于table数组长度;如果loadFactory越小,说明table数组中空闲的位置越多,hash冲突的概率越低,性能也就越高,但是缺点也很明显,会造成一定的空间浪费。
如果设置loadFactory大于等于1,则说明已添加的数据量大于等于table数组的长度;如果loadFactory越大,说明发生hash冲突的概率越高,发生冲突后拉出的链表长度越长,进而导致了HashMap的操作性能下降。
因此loadFactory的设置要在空间消耗与操作性能之间的均衡考虑,不要让HashMap的操作性能下降得太多,也不要额外消耗太多的空间。
HashMap默认的loadFactory为0.75,这个值保证了table数组中始终有一定的空闲位置,不至于产生太多的hash冲突,也不会有太多的空间浪费,在空间消耗和操作性能之间得到了一定的均衡。
举个例子,HashMap默认的table数组长度为16,loadFactory为0.75,此时的扩容阈值为160.75=12,也就是当HashMap中添加的数据数量等于12时就会触发扩容逻辑;因为HashMap的table数组长度要设置为2的n次方,因此table数组的长度会被扩容为32,此时扩容阈值就会增加为320.75=24,也就是当数据量到达24时会再次触发扩容阈值。
HashMap扩容优化
前面提到,HashMap扩容时需要将数据从旧的table数组中搬移到扩容后的table数组中,我们知道,要将键映射到数组下标是通过以下公式计算得到:
int i = hash(key) & (n - 1); //n是数组的长度
在扩容过程也需要重新计算每个key的hash值吗?
其实是不需要的,因为HashMap中的Node节点除了存储具体的键和值之外,还会将键的hash值一起保存起来,所以我们可以通过Node节点直接取出key的hash值。
在扩容过程获取扩容后的数组下标值需要通过 hash & (n - 1) 计算得到吗?
其实是不需要的,因为HashMap底层的数组table的长度要求是2的n次方,每次扩容时都是将数组长度的二进制位的高位向左移动一位,因此最终数据映射到扩容后数组的哪个下标位置,是由hash值的高位决定。如果hash值的高位为0,那么数据映射到扩容后数组中的下标与其在旧数组中的下标一致;如果hash值的高位为1,那么数据映射到扩容后数组的下标为(原下标值 + 旧数组的长度)。
举个例子看一下:
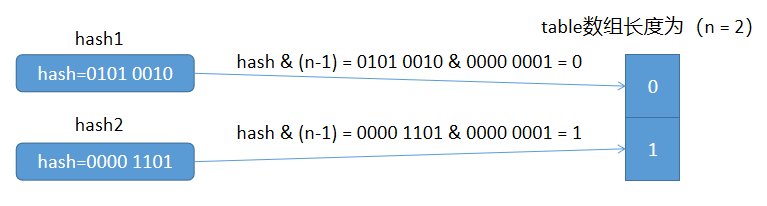
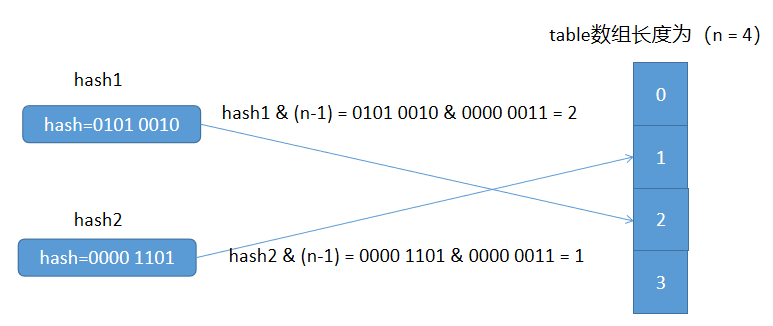
下面分析一下上面的例子:
先看hash1的变化,当数组长度n为2时,n - 1的二进制为0000 0001,hash1的二进制为0101 0010,进行位与后得到下标为0;
当数组长度n为4时,n - 1的二进制为0000 0011,hash1的二进制为0101 0010,进行位与后得到下标为2;
可以发现,当n从2扩容为4时,n - 1的二进制位产生的变化是高位进1,也就是最右边的二进制位由01变为了11,而hash2的二进制位的最后两位为10,因此,扩容后hash2在新数组中的下标为2,也就是通过(原下标值 + 旧数组的长度 = 0 + 2 = 2)计算得到。
再来看hash2的变化,当数组长度n为2时,n - 1的二进制为0000 0001,hash2的二进制为0000 1101,进行位与后得到下标为1;
当数组长度n为4时,n - 1的二进制为0000 0011,hash2的二进制为0000 1101,进行位与后得到下标为1;
可以发现,当n从2扩容为4时,n - 1的二进制位产生的变化是高位进1,也就是最右边的二进制位由01变为了11,而hash1的二进制位的最后两位为01,因此,扩容后hash1在新数组中的位置与其在旧数组中的位置一致,还是1。
HashMap为什么要引入红黑树
当发生hash冲突时,HashMap解决冲突的办法是使用链表将hash冲突的节点都添加到链表中,如果hash冲突比较严重的话,就会导致链表的长度过长,链表操作的时间复杂度为O(n),最终导致HashMap的操作性能下降。
为了避免HashMap由于链表过长而导致了性能问题,HashMap引入了红黑树,红黑树是一颗平衡二叉查找树,其操作的时间复杂度为O(log n),因此引入红黑树可以避免由于链表过长而导致HashMap性能退化的问题。
什么时候将链表修改为红黑树呢
当HashMap中的table数组某个位置的链表长度超过7,且table数组长度大于等于64时,会将对应的链表替换为红黑树实现。
但如果HashMap中的table数组长度小于64时,此时不会将链表替换为红黑树实现,而是通过扩容的方式来解决链表过长的问题。因为节点数不多,底层的table数组长度不会太长,通过对table数组进行扩容不会导致过多的空间浪费;而如果节点数量比较多,此时再对table数组进行扩容,会导致table数组中的空闲位置较多,进而导致过多的额外空间浪费,此时替换为红黑树实现,就可以避免这个问题。
当红黑树中存储的节点比较少时,会将红黑树重新调整为链表实现,因为红黑树为了保持整棵树的平衡性,需要多做一些维护操作,当节点数量比较少时,链表的性能相对于红黑树来说比较高,因此当节点数量比较少时,使用链表可以得到更好的性能。
问题解答
回到开篇的问题,开篇示例代码 Key 中的 hashCode() 方法返回的 hash 值的作用主要是用来计算数据在 HashMap 中的映射位置,如果 hashCode() 方法返回的 hash 值是固定的就会导致所有的数据都路由到 HashMap 中同样的位置,这就会导致 HashMap 的操作性能急剧下降,因此我们需要保证 HashMap 中 Key 的 hashCode() 方法返回的 hash 值尽量是随机的,以保证数据在 HashMap 中分布均匀,这样才能充分发挥 HashMap 的性能优势。
小结
本篇文章中主要总结了小编对HashMap底层实现与原理的一些思考,其中不涉及到具体的源码分析,感兴趣的小伙伴可以自行参考对应的源码实现。