再添神器!Paddle.js 发布 OCR SDK

关键词:OCR、Paddle.js、PaddleOCR
01 前言
OCR(Optical Character Recognition,光学字符识别)是文字识别的统称,不仅支持文档或书本文字识别,还包括识别自然场景下的文字,又可以称为 STR(Scene Text Recognition)。
OCR 文字识别一般包括两个部分,文本检测和文本识别;文本检测首先利用检测算法检测出图像中的文本行;然后检测到的文本行用识别算法去识别出具体文字。
OCR SDK(@paddlejs-models/ocr) 所依赖的技术主要包含两大部分:百度开源的超轻量级文字识别模型套件 PaddleOCR 和基于 JavaScript 的前端深度学习推理引擎 Paddle.js。接下来将对 PaddleOCR 和 @paddlejs-models/ocr 进行详细介绍。

02 PaddleOCR
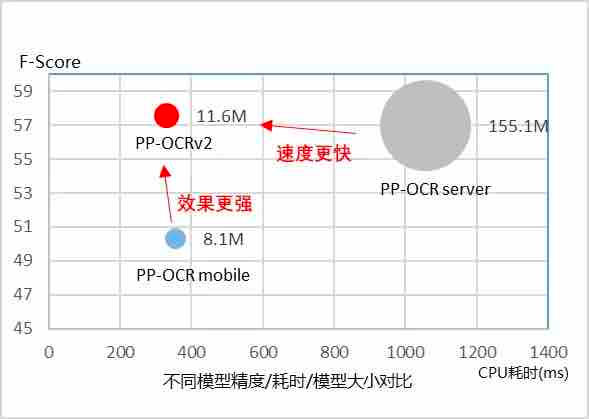
PaddleOCR 是百度开源的超轻量级文字识别模型套件,提供了数十种文本检测、识别模型,旨在打造一套丰富、领先、实用的文字检测、识别模型/工具库,助力使用者训练出更好的模型,并应用落地。目前,不仅开源了超轻量 8.6M 中英文模型,而且用户可以自定义训练,使用自己的数据集 Fine-tune 一下就能达到非常好的效果。并且提供了多种硬件推理(服务器端、移动端、嵌入式端等全支持)的一整套部署工具,是 OCR 文字识别领域工业级应用的绝佳选择。
在 Paddle.js 框架内使用的模型是:ch_PP-OCRv2_det_infer 文本检测推理模型和 ch_PP-OCRv2_rec_infer 文本识别推理模型。对于之前 PP-OCR 版本模型,主要有三个方面提升:
- 在模型效果上,相对于 PP-OCR mobile 版本提升超 7%;
- 在速度上,相对于 PP-OCR server 版本提升超过 220%;
- 在模型大小上,11.6M 的总大小,服务器端和移动端都可以轻松部署。
03 @paddlejs-models/ocr
@paddlejs-models/ocr 是运行在浏览器端的模型 SDK,提供文本识别 AI 能力。SDK 封装两个API:init(模型初始化)和 recognize(文本识别),核心代码如下:
import * as ocr from '@paddlejs-models/ocr';
// 模型初始化
await ocr.init();
// 获取文本识别结果API,img为用户上传图片,option为可选参数
// option.canvas as HTMLElementCanvas:若用户需要绘制文本框选区域,传入canvas元素
// option.style as object:若用户需要配置canvas 样式,传入style 对象
// option.style.strokeStyle as string:文本框选颜色
// option.style.lineWidth as number:文本框选线段宽度
// option.style.fillStyle as string:文本框选填充颜色
const res = await ocr.recognize(img, option?);
// 识别文字结果
console.log(res.text);
// 文本区域坐标
console.log(res.points);import * as ocr from '@paddlejs-models/ocr';
// 模型初始化
await ocr.init();
// 获取文本识别结果API,img为用户上传图片,option为可选参数
// option.canvas as HTMLElementCanvas:若用户需要绘制文本框选区域,传入canvas元素
// option.style as object:若用户需要配置canvas 样式,传入style 对象
// option.style.strokeStyle as string:文本框选颜色
// option.style.lineWidth as number:文本框选线段宽度
// option.style.fillStyle as string:文本框选填充颜色
const res = await ocr.recognize(img, option?);
// 识别文字结果
console.log(res.text);
// 文本区域坐标
console.log(res.points);GitHub 项目:
https://github.com/PaddlePaddle/Paddle.js/tree/master/packages/paddlejs-models/ocr
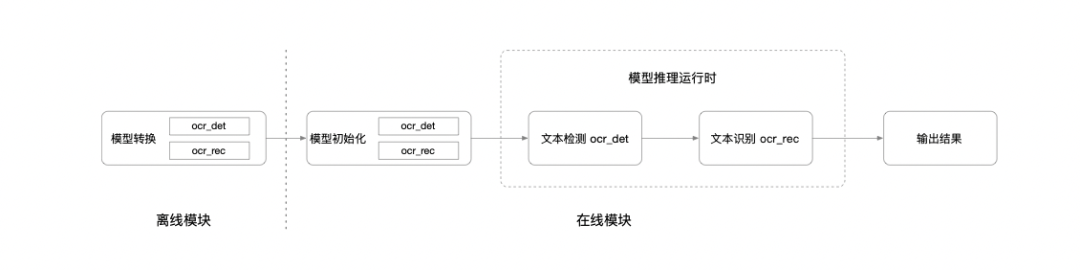
丨 整体流程图
丨 模型转换
paddlejsconverter 是适用于 Paddle.js 的模型转换工具,其作用是将 PaddlePaddle 模型转化为浏览器友好的格式,以供 Paddle.js 在浏览器等环境中加载预测使用。工具安装命令:-
pip3 install paddlejsconverter
工具使用命令:
# paddle_model_file_path 为ocr_det/ocr_rec PaddlePaddle模型本地路径
# paddle_param_file_path 为ocr_det/ocr_rec PaddlePaddle模型参数本地路径
# paddlejs_model_directory 为转换完成的paddlejs模型本地路径(开发者自定义)
paddlejsconverter \
--modelPath=<paddle_model_file_path> \
--paramPath=<paddle_param_file_path> \
--outputDir=<paddlejs_model_directory>丨 模型初始化
模型初始化模块首先会加载 ocr_det 文本检测模型和 ocr_rec 文本识别模型,并行执行模型预热逻辑,减少模型预热时间。模型初始化主要实现如下:
detectRunner = new Runner({
modelPath: 'https://paddlejs.bj.bcebos.com/models/ocr_det_new',
mean: [0.485, 0.456, 0.406],
std: [0.229, 0.224, 0.225],
bgr: true
});
const detectInit = detectRunner.init();
recRunner = new Runner({
modelPath: 'https://paddlejs.bj.bcebos.com/models/ocr_rec_new',
mean: [0.5, 0.5, 0.5],
std: [0.5, 0.5, 0.5],
bgr: true
});
const recInit = recRunner.init();
return await Promise.all([detectInit, recInit]);Runner.init API 主要完成模型加载、神经网络生成以及模型预热过程,由于我们使用 WebGL backend 计算,所以在预热过程中需要完成着色器(shader)编译以及权重数据上传至纹理(texture)。
丨 模型推理运行时
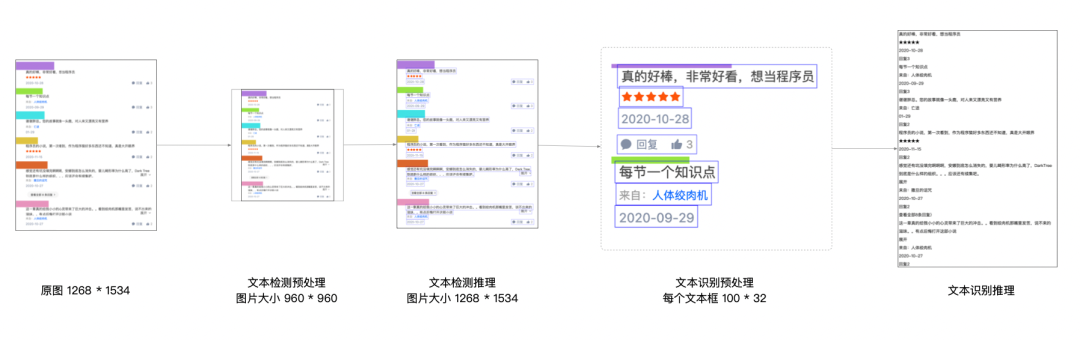
1. 文本检测
ocr_det 文本检测模型用于检测图片内文本所在区域,返回每个文本框选区域的坐标点。
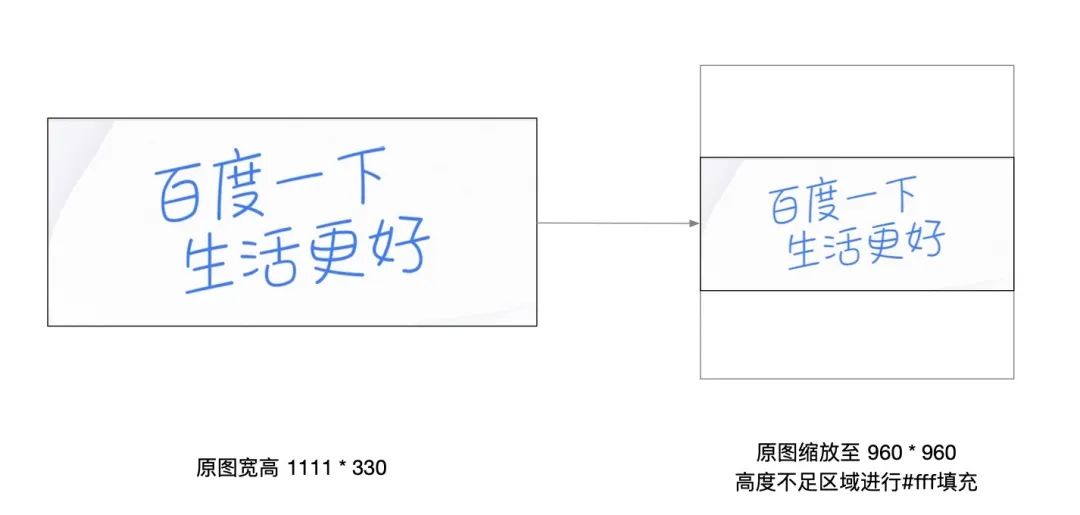
预处理
预处理是将原图大小按照模型输入 shape [1, 3, 960, 960] 缩放至 960 * 960。
- 对长图处理:
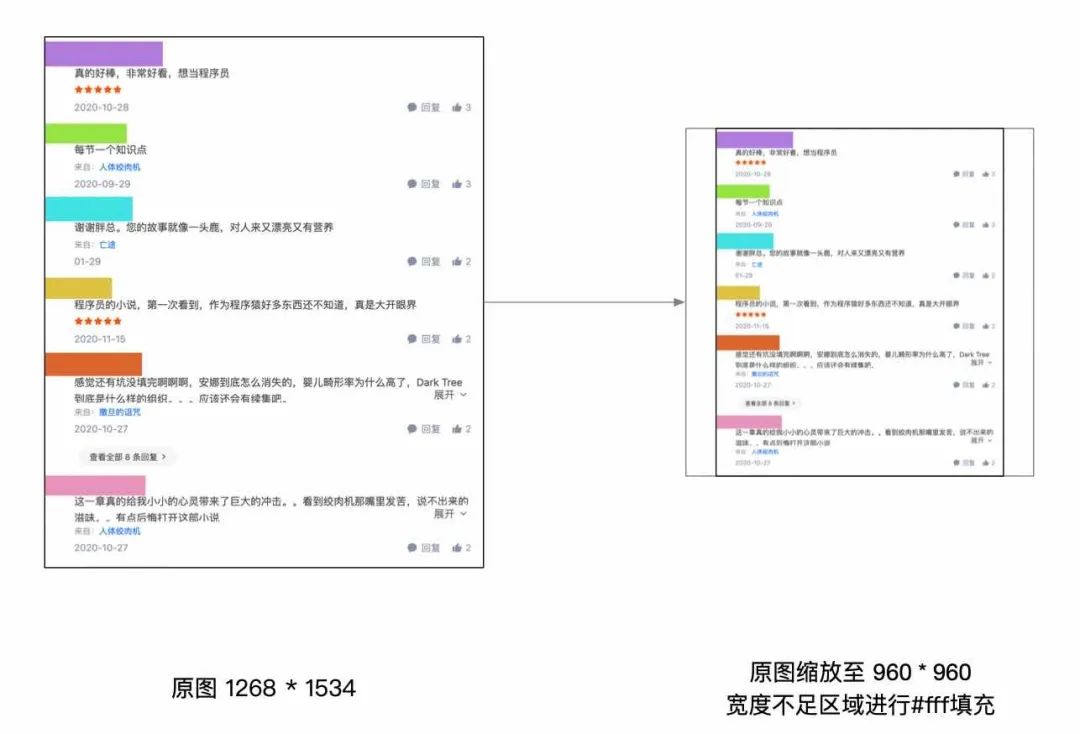
- 对宽图处理:
推理
模型推理过程同 Paddle.js 部分,详见GitHub:https://github.com/PaddlePaddle/Paddle.js
模型后处理采用 DB(可微二值化)算法,具体计算过程如下:
- 根据二值化图像获取所有文本框轮廓
- 根据轮廓信息获取最小外接矩形,返回矩形的顶点坐标和宽高最小值
- 根据二值化图像和矩形框坐标计算矩形框的置信度
- 扩张文本框大小,返回扩张后的轮廓信息
- 根据扩张后的轮廓信息计算最小外接矩形
- 将最终的矩形框映射回原图,获取矩形框的顶点坐标
2. 文本识别
ocr_rec 模型采用 CRNN 算法,该算法的主要思想是认为文本识别是针对序列进行预测,所以采用了预测序列常用的 RNN 网络。算法通过 CNN(卷积层)提取图片特征,然后采用 RNN(循环层)对序列进行预测,最终使用 CTC(转录层)得到文本序列。
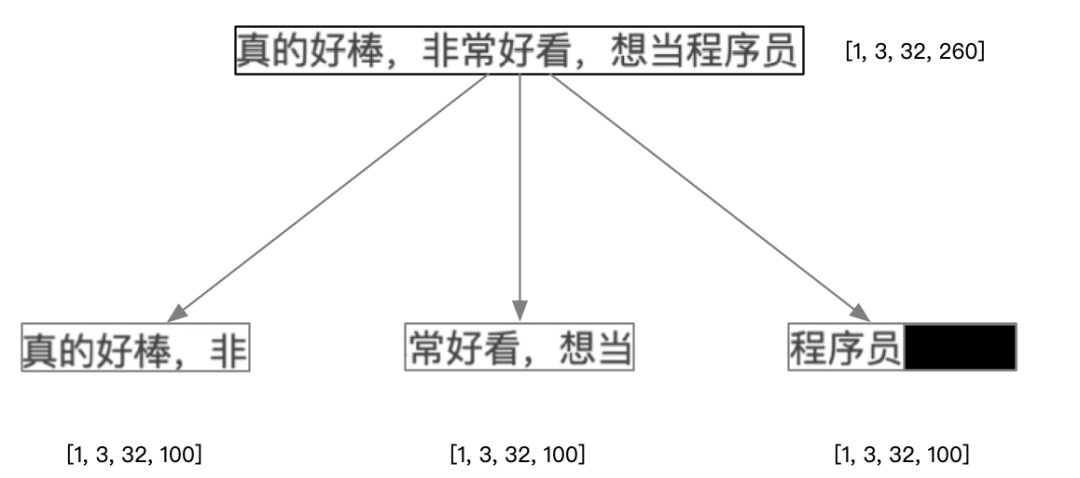
预处理
ocr_rec 模型输入 shape 为 [1, 3, 32, 100],模型推理前会对图片文本框选区域进行处理:图片文本框选区域宽高比 <= 100 / 32,对缺省部分进行 #000 填充;框选区域宽高比
100 / 32,对框选区域按宽度进行裁剪。最终传入识别模型的图片宽高比为 100 : 32。以下图文本框为例:
推理
将预处理过后的图片传入 Paddle.js 框架引擎中,进行模型推理计算,得到文本序列置信度列表,在字典中查找置信度最大值索引对应的字符,完成文字识别。
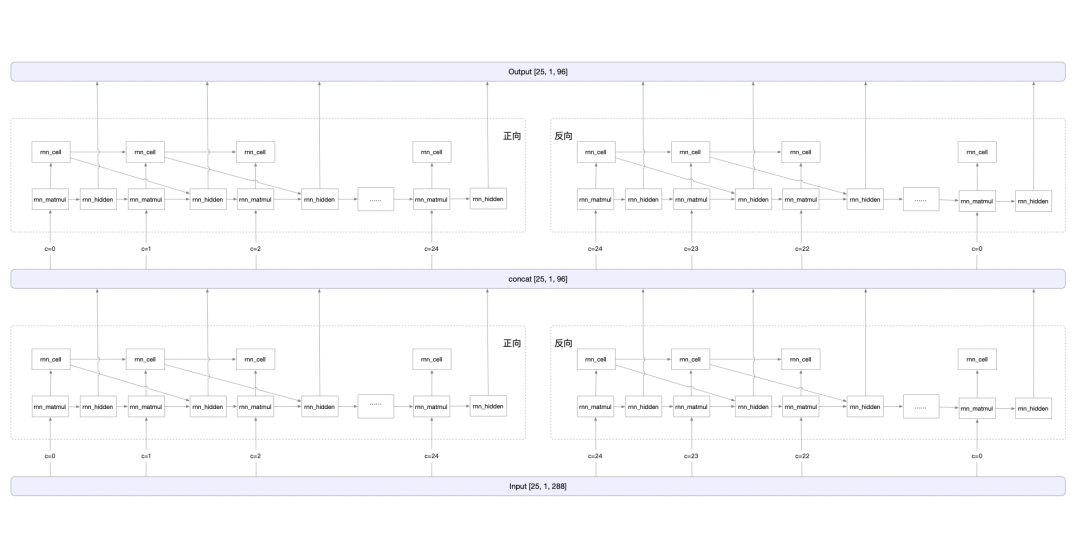
在模型推理过程中,核心算法为 RNN。RNN 是循环神经网络,由输入层、隐藏层和输出层组成,擅长对序列数据进行处理。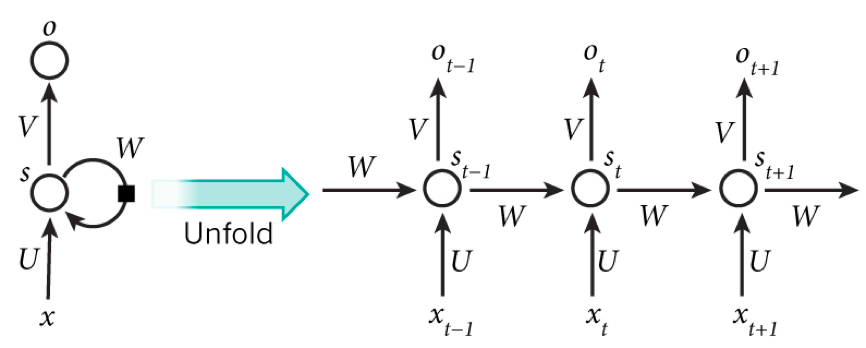
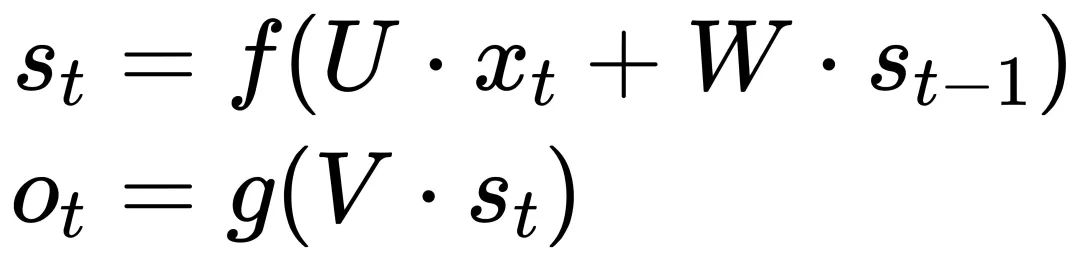
基于图像的序列,两个方向的上下文是相互有用且互补的。由于 LSTM 是单向的,所以将两个 LSTM,一个向前和一个向后组合到一个双向 LSTM 中。此外,可以堆叠多层双向 LSTM。ch_PP-OCRv2_rec_infer 识别模型就是使用的双层双向 LSTM 结构。计算过程如下图所示:
丨 效果展示

05 Benchmark
评估环境:
- MacBook Pro A2141(16英寸/i7/16G/512GSSD)
- 评估耗时阶段为图像预测耗时,不包括图像的预处理和后处理
- 针对OCR实际应用场景,随机收集的50张图像
- 浏览器环境
| 模型名称 | ch_ppocr_mobile | ch_PP-OCRv2 |
|---|---|---|
| 检测耗时(WebGL) | 139ms | 258ms |
| 识别耗时(WebGL) | 254ms | 60ms |
| 整体识别F-score | 0.503 | 0.5224 |
| 检测模型大小 | 2.6M | 3M |
| 识别模型大小 | 4.6M | 8.6M |