对 int 变量赋值的操作是原子的吗?为什么?
前言
这个是在面试的时候遇到的问题,当时没有答出来。回到家以后查了查,整理记录下来。原问题:什么指令集支持原子操作?其原理是什么? 如果考虑到全部的指令集,问题太大了,这里简化下。以X86和ARM为例。原子操作是不可分割的操作,在执行完毕时它不会被任何事件中断。在单处理器系统(UniProcessor,简称 UP)中,能够在单条指令中完成的操作都可以认为是原子操作,因为中断只能发生在指令与指令之间。比如,C语言代码

如果未经优化,有可能生成如下汇编:
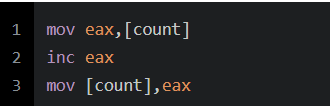
这样在有多个进程执行这段代码时,就有可能产生并发问题:
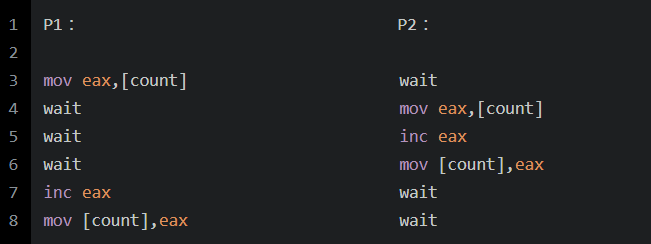
这就会出现问题。
在单处理器中,解决这个问题的方法是,将count++语句翻译成单指令操作

X86指令集支持inc操作,这样count操作可以在一条指内完成。
进程的上下文切换总是在一条指令执行之后完成,所以不会出现上述的并发问题。对于单处理器来说,一条处理器指令就是一个原子操作。
同样,ARM里的SWP和X86里的XCHG都是对于单处理器来说,是原子操作。
但是,在多处理器系统(Symmetric Multi-Processor,简称 SMP)中情况有所不同,由于系统中有多个处理器在独立的运行,即使在能单条指令中完成的操作也可能受到干扰。因为这个时候并发的主题不再是进程,而是处理器。
X86架构
Intel X86指令集提供了指令前缀lock用于锁定前端串行总线FSB,保证了指令执行时不会收到其他处理器的干扰。
比如:

使用lock指令前缀之后,处理期间对count内存的并发访问(Read/Write)被禁止,从而保证了指令的原子性。
如图所示:

X86LOCK其原理在Intel开发手册有如下说明:
Description
Causes the processor’s LOCK# signal to be asserted during execution of the accompanying instruction (turns the instruction into an atomic instruction). In a multiprocessor environment, the LOCK# signal ensures that the processor has exclusive use of any shared memory while the signal is asserted.
The LOCK prefix can be prepended only to the following instructions and only to those forms of the instructions where the destination operand is a memory operand: ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, CMPXCHG16B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG. If the LOCK prefix is used with one of these instructions and the source operand is a memory operand, an undefined opcode exception (#UD) may be generated. An undefined opcode exception will also be generated if the LOCK prefix is used with any instruction not in the above list. The XCHG instruction always asserts the LOCK# signal regardless of the presence or absence of the LOCK prefix.
The LOCK prefix is typically used with the BTS instruction to perform a read-modify-write operation on a memory location in shared memory environment.
The integrity of the LOCK prefix is not affected by the alignment of the memory field. Memory locking is observed for arbitrarily misaligned fields.
在执行伴随的指令期间使处理器的LOCK#信号有效(将指令变为原子指令)。在多处理器环境中,LOCK#信号确保处理器在信号有效时独占使用任何共享存储器。
LOCK前缀只能附加在下面的指令之前,并且只适用于那些目标操作数是内存操作数的指令格式:ADD,ADC,AND,BTC,BTR,BTS,CMPXCHG,CMPXCH8B,CMPXCHG16B,DEC,INC, NEG,NOT,OR,SBB,SUB,XOR,XADD和XCHG。
如果LOCK前缀与这些指令之一一起使用,并且源操作数是内存操作数,则可能会生成未定义的操作码异常(#UD)。如果LOCK前缀与任何不在上述列表中的指令一起使用,也会产生未定义的操作码异常。无论是否存在LOCK前缀,XCHG指令都始终声明LOCK#信号。LOCK前缀通常与BTS指令一起使用,以在共享存储器环境中的存储器位置上执行读取 – 修改 – 写入操作。
LOCK前缀的完整性不受存储器字段对齐的影响。内存锁定是针对任意不对齐的字段。
操作系统中的实现
Linux源码中对于原子自增一是如下定义的:

LOCK_PREFIX的定义如下所示:
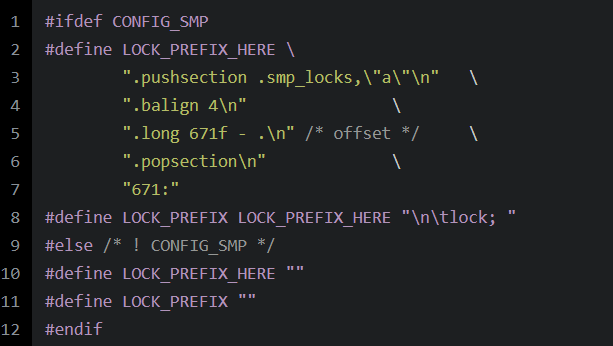
可见:在对称多处理器架构的情况下,LOCK_PREFIX被解释为指令前缀lock。而对于单处理器架构,LOCK_PREFIX不包含任何内容。
另外,对于CAS,有cmpxchg指令进行操作。代码如下:
static __always_inline int atomic_cmpxchg(atomic_t *v, int old, int new)
{
return cmpxchg(&v->counter, old, new);
}
#define cmpxchg(ptr, old, new) \
__cmpxchg(ptr, old, new, sizeof(*(ptr)))
#define __cmpxchg(ptr, old, new, size) \
__raw_cmpxchg((ptr), (old), (new), (size), LOCK_PREFIX)
#define __raw_cmpxchg(ptr, old, new, size, lock) \
({ \
__typeof__(*(ptr)) __ret; \
__typeof__(*(ptr)) __old = (old); \
__typeof__(*(ptr)) __new = (new); \
switch (size) { \
case __X86_CASE_B: \
{ \
volatile u8 *__ptr = (volatile u8 *)(ptr); \
asm volatile(lock "cmpxchgb %2,%1" \
: "=a" (__ret), "+m" (*__ptr) \
: "q" (__new), "0" (__old) \
: "memory"); \
break; \
} \
case __X86_CASE_W: \
{ \
volatile u16 *__ptr = (volatile u16 *)(ptr); \
asm volatile(lock "cmpxchgw %2,%1" \
: "=a" (__ret), "+m" (*__ptr) \
: "r" (__new), "0" (__old) \
: "memory"); \
break; \
} \
case __X86_CASE_L: \
{ \
volatile u32 *__ptr = (volatile u32 *)(ptr); \
asm volatile(lock "cmpxchgl %2,%1" \
: "=a" (__ret), "+m" (*__ptr) \
: "r" (__new), "0" (__old) \
: "memory"); \
break; \
} \
case __X86_CASE_Q: \
{ \
volatile u64 *__ptr = (volatile u64 *)(ptr); \
asm volatile(lock "cmpxchgq %2,%1" \
: "=a" (__ret), "+m" (*__ptr) \
: "r" (__new), "0" (__old) \
: "memory"); \
break; \
} \
default: \
__cmpxchg_wrong_size(); \
} \
__ret; \
})ARM架构
在ARM架构下,没有LOCK#指令,其具体实现如下:## ARMv6之前 早期的ARM架构是不支持SMP的,这些单核架构的CPU实现原子操作的方式就是通过关闭CPU中断来完成的。
在Linux对于ARM架构的代码下
有如下:
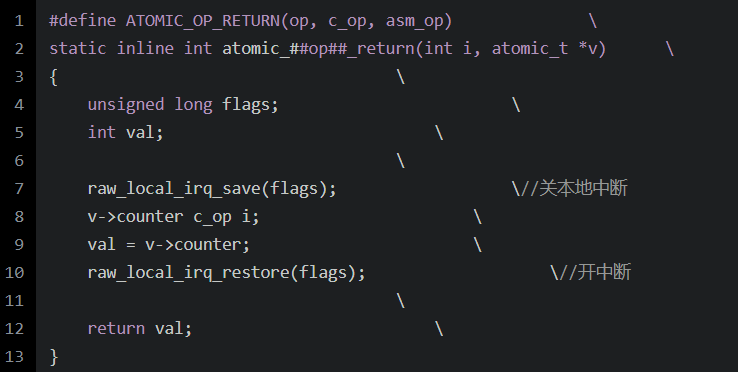
这个是好多操作共用的一套代码。
对于cmpxchg:
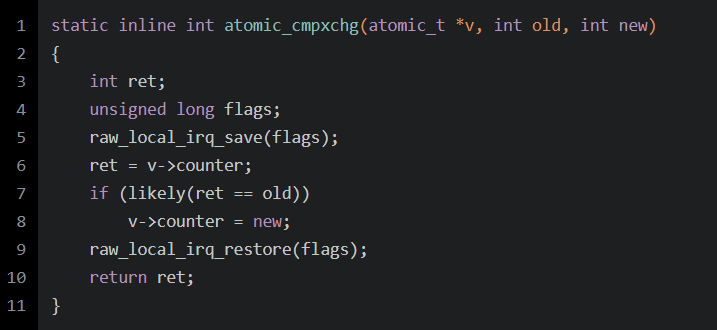
可以看到,对v->counter的操作是一个临界区,指令的执行不能被打断,内存的访问也需要保持没有干扰。
ARMv6以前的版本通过关本地中断来保护这块临界区,看起来相当简单,其奥秘就在于ARMv6以前的版本不支持SMP。
比如经典的read-modify-write问题,其本质是保持一个对内存read和write访问的原子性问题,也就是说内存的读和写的访问不能被打断。对该问题的解决可以通过硬件、软件或者软硬件结合的方法来进行。
早期的ARM CPU给出的方案就是依赖硬件:SWP这个汇编指令执行了一次读内存操作、一次写内存操作,但是从程序员的角度看,SWP这条指令就是原子的,读写之间不会被任何的异步事件打断。具体底层的硬件是如何做的呢?这时候,硬件会提供一个lock signal,在进行memory操作的时候设定lock信号,告诉总线这是一个不可被中断的内存访问,直到完成了SWP需要进行的两次内存访问之后再clear lock信号。
多说一点关于SWP和SWPB的内容
这两个指令是用来同步的,不是用来执行原子操作的。在将独占访问引入ARM架构之前,SWP和SWPB指令常用于同步。
其局限性是:如果中断在触发交换操作时触发,则处理器必须在执行中断之前完成指令的加载和存储部分,从而增加中断延迟。由于独立加载和独占存储是单独的指令,因此在使用新的同步基元时会降低此效果。
但是在多核系统中,交换指令期间阻止所有处理器访问主存会降低系统性能。在处理器工作在不同频率但是共享相同主存的多核系统中,情况尤其如此。
所以在ARMv6及以后的版本中,弃用了SWP, ARMv6架构引入了独占访问内存为止的概念,提供了更灵活的原子内存更新。
ARMv6体系结构以Load-Exclusive和Store-Exclusive同步原语LDREX和STREX的形式引入了Load Link和Store Conditional指令。从ARMv6T2开始,这些指令在ARM和Thumb指令集中可用。独立加载和专有存储提供了灵活和可扩展的同步,取代了弃用的SWP和SWPB指令。
后来使用的是LDREX和STREX指令,在armv7之后就用了ldrex和strex:
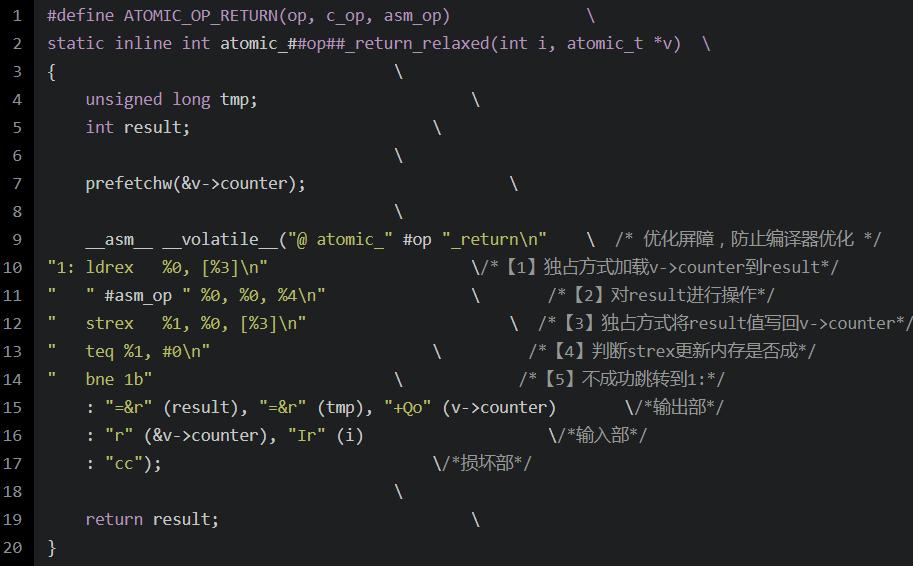
访存指令LDREX/STREX和普通的LDR/STR访存指令不一样,它是“独占”访存指令。这对指令访存过程由一个称作“exclusive monitor”的部件来监视是否可以进行独占访问。
独占访存指令:
(1)LDREX R1 ,[R0] 指令是以独占的方式从R0所指的地址中取一个字存放到R0中;
(2)STREX R2,R1,[R0] 指令是以独占的方式用R1来更新内存,如果独占访问条件允许,则更新成功并返回0到R2,否则失败返回1到R2。