Kafka消费者JoinGroupRequest流程解析
-
1. 发起请求
-
1.2 请求参数解析
-
1.3 发起请求
-
2. 协调器接受请求
-
2.1 doUnknownJoinGroup
-
2.2 doJoinGroup
-
3. 客户端处理返回数据
-
4. 总结
-
5. Q&A
-
1. 谁是消费组协调器
-
2. 什么是Leader Member , Leader Member 选举策略
-
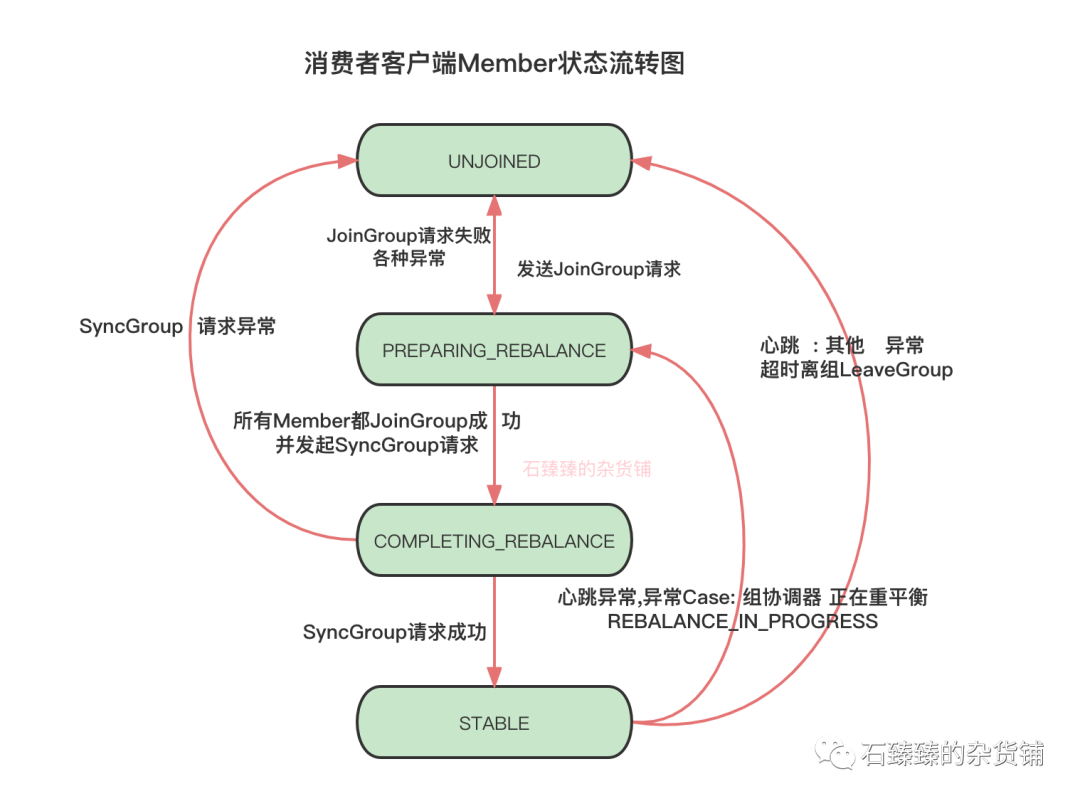
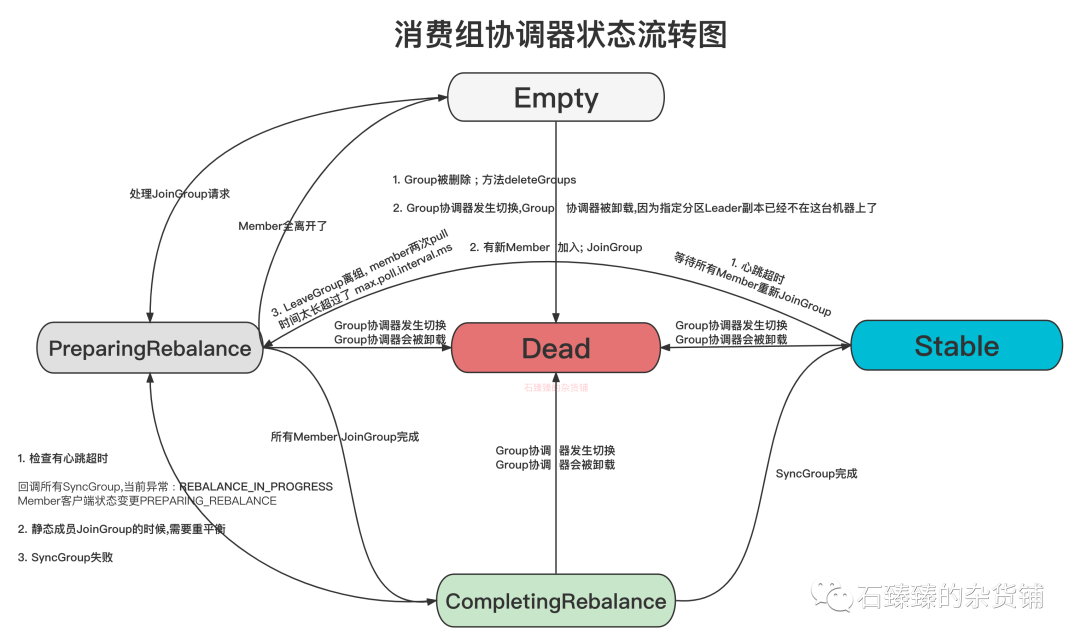
附录: 消费者客户端状态流转图和消费组协调器状态流转图
1 . 发起请求
当我们启动消费者客户端的时候, 会向协调器 coordinator 发起一个 JoinGroup的请求,表示要加入消费组中。
这个发起请求的地方在
AbstractCoordinator#sendJoinGroupRequest
RequestFuture<ByteBuffer> sendJoinGroupRequest() {
// 如果 协调器未获取到或者链接断开了 则返回异常
if (coordinatorUnknown())
return RequestFuture.coordinatorNotAvailable();
// 构建请求参数
JoinGroupRequest.Builder requestBuilder = new JoinGroupRequest.Builder(
new JoinGroupRequestData()
.setGroupId(rebalanceConfig.groupId)
// 客户端与Broker最大会话有效期, 如果超过这个时间没有任何心跳则可能发生重平衡
// 属性 session.timeout.ms;默认10000(10 秒)
.setSessionTimeoutMs(this.rebalanceConfig.sessionTimeoutMs)
//消费者的成员id, 默认就是空字符串
.setMemberId(this.generation.memberId)
//2.3版本引入的新参数. 用户提供的消费者实例的唯一标识符。 如果设置了,消费者则被视为静态成员,
//静态成员配以较大的session超时设置能够避免因成员临时不可用(比如重启)而引发的Rebalance,
// 如果不设置, 消费者将作为动态成员
//配置:group.instance.id
.setGroupInstanceId(this.rebalanceConfig.groupInstanceId.orElse(null))
//协议类型, 这里是consumer, 可选项还有connect
.setProtocolType(protocolType())
// 配置的分区分配策略和对应的 订阅相关信息的
.setProtocols(metadata())
//
.setRebalanceTimeoutMs(this.rebalanceConfig.rebalanceTimeoutMs)
);
log.debug("Sending JoinGroup ({}) to coordinator {}", requestBuilder, this.coordinator);
// joinGroup请求的超时时间 在 (request.timeout.ms默认30000(30 秒)) 和(max.poll.interval.ms默认30s + 5s ) 中取最大值
int joinGroupTimeoutMs = Math.max(client.defaultRequestTimeoutMs(),
rebalanceConfig.rebalanceTimeoutMs + JOIN_GROUP_TIMEOUT_LAPSE);
// 向指定的coordinator Node节点 发起请求
return client.send(coordinator, requestBuilder, joinGroupTimeoutMs)
.compose(new JoinGroupResponseHandler(generation));
}
1.2 请求参数解析
一般来说, 正常的一个请求都包含如下数据
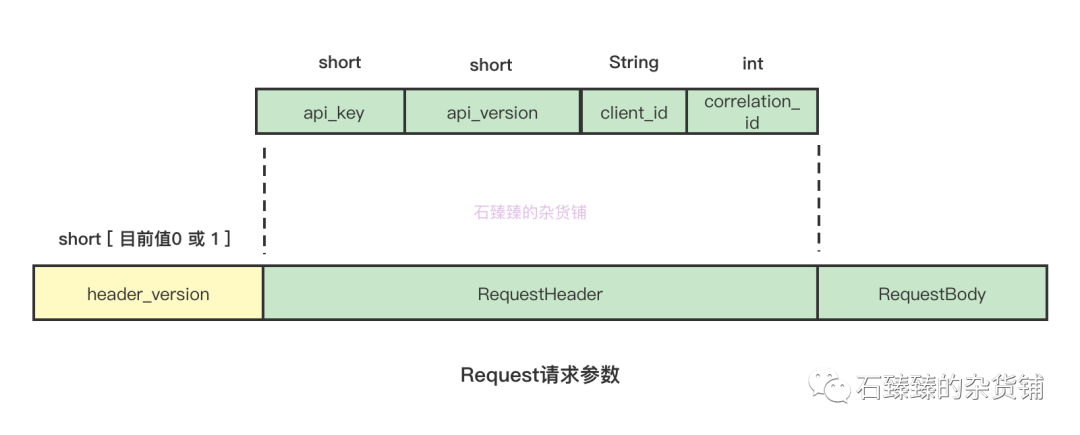
RequestHeader
1 .header_version 请求头版本号
请求头版本号, 请求头的版本目前有 0 和 1; 每个请求对应使用哪个headerVersion的映射关系在ApiMessageType#requestHeaderVersion
2. api_version: 请求的标识ID
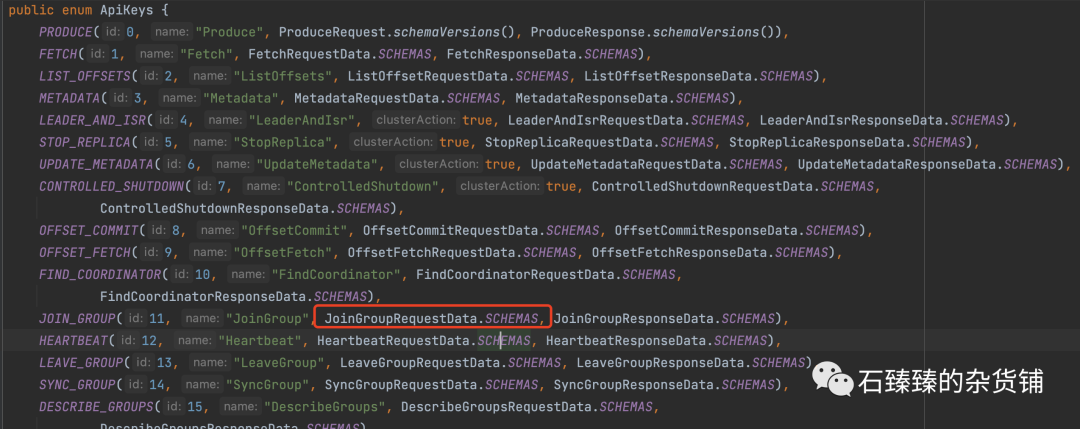
每个类型的请求都有他对应的唯一ID, 比如这里的JoinGroupRequest对应的ID是 11 ; 映射关系在 ApiMessageType
3. api_version: 该请求的版本号
因为我们可能会对某个请求类型做过改动, 并且改动了请求的Schemas, 那么每次改动都是一个版本, 比如JoinGroupRequest这个请求总共就有8个版本, 那么当前发起的请求的版本号是 :Schema.length -1 = 8 - 1 = 7
下面的JoinGroupRequest的Schemas, 不同请求类型的Schemas不一样, 可以通过ApiKeys下面的每个请求查看。
public static final Schema[] SCHEMAS = new Schema[] {
SCHEMA_0,
SCHEMA_1,
SCHEMA_2,
SCHEMA_3,
SCHEMA_4,
SCHEMA_5,
SCHEMA_6,
SCHEMA_7
};4. client_id: 客户端ID
客户端唯一标识
5. correlation_id: 每次发起的请求的唯一标识
发起的每次请求的唯一标识, 该值自增。
RequestBody
上面的RequestHeader基本上都大差不差,不同Request类型的RequestBody是不一样的.
本次JoinGroupRequest的属性如下
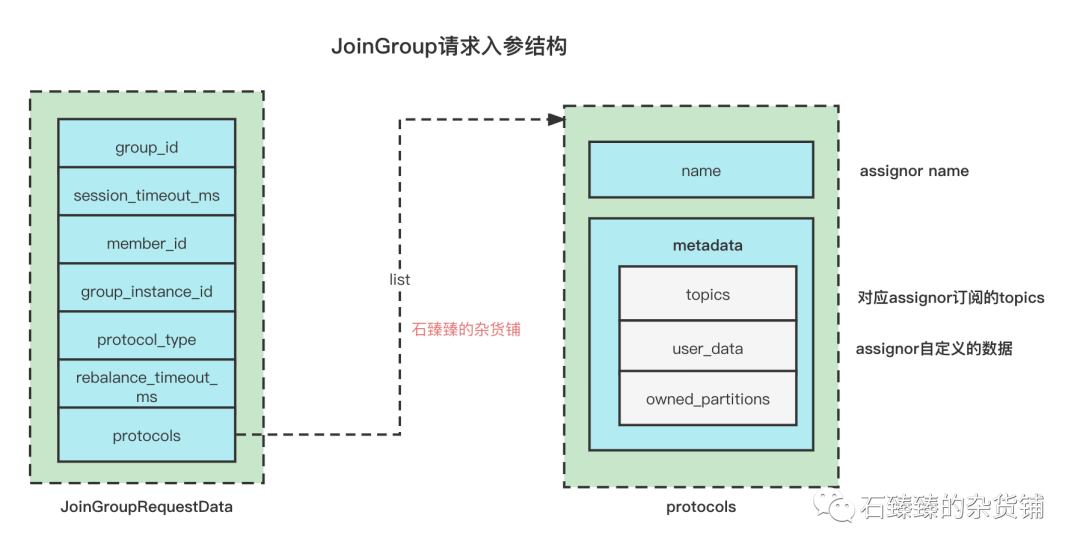
1. group_id 消费组id
属性group.id 配置
2. session_timeout_ms
客户端属性:session.timeout.ms 默认值 10000(10 秒)
消费者 定期发送心跳证明自己的存活,如果在这个时间之内broker没收到,那broker就将此消费者从group中移除,进行一次reblance。
需要注意的是, 这个值必须在Broker属性 group.min.session.timeout.ms 和 group.max.session.timeout.ms 的值范围中间。
3. member_id 消费者成员ID
消费者的成员id, 默认就是空字符串, 客户端不可设置。该值会在后续的请求中返回并被赋值。
4. group_instance_id
客户端属性:group.instance.id 默认值 空)
Kafka2.3版本引入的新参数. 用户提供的消费者实例的唯一标识符。如果设置了,消费者则被视为静态成员, 静态成员配以较大的session超时设置能够避免因成员临时不可用(比如重启)而引发的Rebalance, 如果不设置, 消费者将作为动态成员
5. protocol_type 协议类型
Consumer发起的协议是 comsumer , 另一个可选项为connect
6. rebalance_timeout_ms 重平衡的超时时间
客户端属性:max.poll.interval.ms,默认值300000(5 分钟)
如果消费者两次poll的时间超过了此值,那就认为此消费者能力不足,将此消费者的commit标记为失败,并将此消费者从group移除,触发一次reblance,将该消费者消费的分区分配给其他人
7. protocols 协议映射
这个值保存着 分区分配策略和对应的订阅元信息
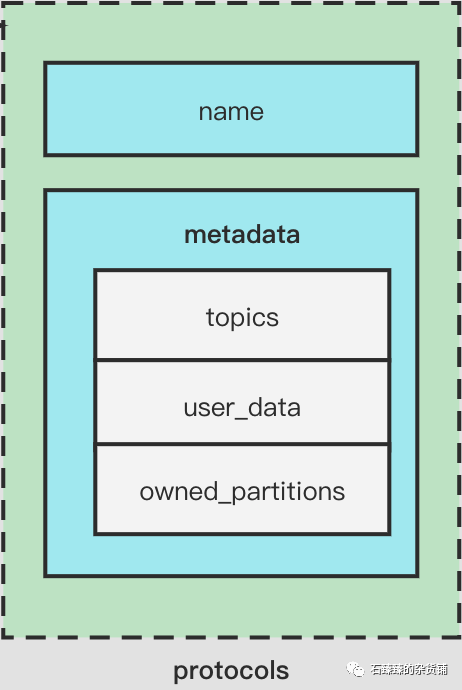
- name : 分配策略的name, 可选值有{ range、roundrobin、sticky、cooperative-sticky、stream}
- metadata:里面保存着对应的元信息,比如 topics为订阅的topic、user_data 为用户自定义数据等等。
protocols 的计算在下面
AbstractCoordinator#metadata()
@Override
protected JoinGroupRequestData.JoinGroupRequestProtocolCollection metadata() {
log.debug("Joining group with current subscription: {}", subscriptions.subscription());
this.joinedSubscription = subscriptions.subscription();
JoinGroupRequestData.JoinGroupRequestProtocolCollection protocolSet = new JoinGroupRequestData.JoinGroupRequestProtocolCollection();
List<String> topics = new ArrayList<>(joinedSubscription);
// assignors 是配置 partition.assignment.strategy 的分区分配策略
for (ConsumerPartitionAssignor assignor : assignors) {
Subscription subscription = new Subscription(topics,
// 分配策略的用户自定义数据,需要实现subscriptionUserData方法,默认range策略是null
assignor.subscriptionUserData(joinedSubscription),
// 订阅的所有分区列表
subscriptions.assignedPartitionsList());
//这个数据包含了 订阅的Topic、UserData 和经过分组整理的订阅的(Topic-分区列表 ) 并且序列化成ByteBuffer
ByteBuffer metadata = ConsumerProtocol.serializeSubscription(subscription);
// 组装成 每种策略对应的 订阅信息数据
protocolSet.add(new JoinGroupRequestData.JoinGroupRequestProtocol()
.setName(assignor.name())
.setMetadata(Utils.toArray(metadata)));
}
return protocolSet;
}
需要注意的是: userData是用户自定义数据, 默认的range策略 返回的是null, 如果你想设置自己的数据, 需要实现方法subscriptionUserData
1.3 发起请求
向协调器节点发起请求
既然要发起请求,那么究竟是哪个节点呢?之前客户端向集群发起请求的计算方式一般都是获取最小负载的节点发起请求。
那么这里可不一样, 这里发起请求的Node是有具体要求的, 那就是向协调器 coordinator 发起。
那么问题来了, 谁是协调器, 协调器的节点是哪个?
先说结论:
该客户端的group.id 的hash值跟__consumer_offsets 分区数取模得到的分区号, 这个分区号的Leader在哪个Broker,那么这个Node就在哪个Broker上。
一个Broker可能有多个Node, 使用哪个Node取决于客户端发起请求时候使用的是哪个listener。客户端发起请求对应的listener就对应着相应的Node。
PS: 如果leader不存在或者不在线, 会提示异常:The coordinator is not available
下面是分析:
我们看上面的代码
client.send(coordinator, requestBuilder, joinGroupTimeoutMs)
.compose(new JoinGroupResponseHandler(generation));这个coordinator的值是客户端发起FindCoordinatorRequest请求后获取到的, 如下代码所示
private class FindCoordinatorResponseHandler extends RequestFutureAdapter<ClientResponse, Void> {
@Override
public void onSuccess(ClientResponse resp, RequestFuture<Void> future) {
log.debug("Received FindCoordinator response {}", resp);
FindCoordinatorResponse findCoordinatorResponse = (FindCoordinatorResponse) resp.responseBody();
Errors error = findCoordinatorResponse.error();
if (error == Errors.NONE) {
synchronized (AbstractCoordinator.this) {
// use MAX_VALUE - node.id as the coordinator id to allow separate connections
// for the coordinator in the underlying network client layer
int coordinatorConnectionId = Integer.MAX_VALUE - findCoordinatorResponse.data().nodeId();
// 获取到了节点
AbstractCoordinator.this.coordinator = new Node(
coordinatorConnectionId,
findCoordinatorResponse.data().host(),
findCoordinatorResponse.data().port());
log.info("Discovered group coordinator {}", coordinator);
client.tryConnect(coordinator);
heartbeat.resetSessionTimeout();
}
future.complete(null);
} else if (error == Errors.GROUP_AUTHORIZATION_FAILED) {
future.raise(GroupAuthorizationException.forGroupId(rebalanceConfig.groupId));
} else {
log.debug("Group coordinator lookup failed: {}", findCoordinatorResponse.data().errorMessage());
future.raise(error);
}
}
这个获取逻辑是:
- 选择集群中的负载最小的一个Node发起FindCoordinatorRequest请求,请求带上了参数
group.id - Broker接收到请求后, 计算
group.id所对应的分区号partition, 计算方式是Utils.abs(groupId.hashCode) % __consumer_offsets分区总数 - 获取该TopicPartition的元信息(也就是
[__consumer_offsets,分区号]), 如果发现不存在该信息,说明该Topi还没有创建, 则开始执行创建__consumer_offsets的流程,需要注意的是,创建这个内部Topic相关的配置如下:
| 属性 | 值 | 描述 |
|---|---|---|
| cleanup.policy | compact | 日志清理策略为 :紧缩 |
| segment.bytes | 10010241024 | 一个日志段的大小 |
| compression.type | producer | 压缩类型 为跟生产者保持一致 |
4 . 拿到元信息之后,那么我们就可以知道该TopicPartition的Leader在哪个Broker上, 那我们就能够获取到对应的EndPoint一个Broker可能同时有多个EndPoint(配置了多个监听器),那么我们应该使用哪个EndPoint呢?客户端发起请求时候的监听器是哪个,那么这里就应该用哪个监听器的EndPoint。如果不理解,可以看下这篇文章:[多网络情况下,Kafka客户端如何选择合适的网络发起请求]
5 . 如果这个分区Leader不存在,那么说明这个协调器他就不存在,提示The coordinator is not available
具体流程请看
寻找协调器FindCoordinatorRequest请求流程
2 . 协调器接受请求
协调器接受到客户端发来的JoinGroup请求进行处理
处理入口:KafkaApi#handleJoinGroupRequest
//省略
- 如果入参配置了
group_instance_id并且当前版本小于 2.3,则返回异常 UNSUPPORTED_VERSION - check
group.min.session.timeout.ms<session.timeout.ms<group.max.session.timeout.ms, 否则返回异常 INVALID_SESSION_TIMEOUT
The session timeout is not within the range allowed by the broker as configured by
group.min.session.timeout.ms and group.max.session.timeout.ms)
3 . 判断是否能够接受该member, 判断的逻辑是:①. 如果当前Group的状态是 (Empty | Dead), 则判定为true;②. 如果Group状态是PreparingRebalance,则判定该Group正在 等待加入的member数量(numMembersAwaitingJoin)<group.max.size 或者 如果现有member已经在等待加入也返回true ③. 如果Group状态是(CompletingRebalance | Stable) ,则判定 ( group.has(member) || group.size < group.max.size)
4 . 如果发现不能接受该member, 则返回异常GROUP_MAX_SIZE_REACHED
The consumer group has reached its max size
- 如果当前Join的member是未知的(memberId = "") ,则执行doUnknownJoinGroup流程,否则执行doJoinGroup流程 这两个流程是具体的Join流程, 具体的细节请看下面
2.1 doUnknownJoinGroup
当请求参数 memberId是空的时候, 则调用这个Join方法
它的作用就是, 计算一个新的memberId,格式为:
- 如果是动态Member :
cliend.id-UUID.toString - 如果是静态Member:
group.instance.id-UUID.toString
计算好了这个MemberId之后,就会返回异常:MEMBER_ID_REQUIRED (必须要传入惨member_id),并且还会返回刚刚计算的newMemberId。
然后消费者客户端接收到这个异常之后会再次发起一次JoinGroupRequest请求,并带上刚获取到的心得member_id.
这个方法我们可以简单的看一下它的代码;
GroupCoordinator#doUnknownJoinGroup
private def doUnknownJoinGroup(group: GroupMetadata,
groupInstanceId: Option[String],
requireKnownMemberId: Boolean,
clientId: String,
clientHost: String,
rebalanceTimeoutMs: Int,
sessionTimeoutMs: Int,
protocolType: String,
protocols: List[(String, Array[Byte])],
responseCallback: JoinCallback): Unit = {
group.inLock {
if (group.is(Dead)) {
// 如果该组被标记为死亡,则意味着其他某个线程刚刚从协调器元数据中删除了该组;
// 该组很可能已迁移到其他一些协调器,或者该组处于瞬态不稳定阶段。让成员重试找到正确的协调者并重新加入。
responseCallback(JoinGroupResult(JoinGroupRequest.UNKNOWN_MEMBER_ID, Errors.COORDINATOR_NOT_AVAILABLE))
// 检查group支持的协议
} else if (!group.supportsProtocols(protocolType, MemberMetadata.plainProtocolSet(protocols))) {
responseCallback(JoinGroupResult(JoinGroupRequest.UNKNOWN_MEMBER_ID, Errors.INCONSISTENT_GROUP_PROTOCOL))
} else {
//newMemberId计算逻辑 无groupInstanceId情况 格式:clientId-UUID ;
//有groupInstanceId情况 格式:groupInstanceId-UUID
val newMemberId = group.generateMemberId(clientId, groupInstanceId)
if (group.hasStaticMember(groupInstanceId)) {
// 静态member的处理情况
updateStaticMemberAndRebalance(group, newMemberId, groupInstanceId, protocols, responseCallback)
} else if (requireKnownMemberId) {
// 返回MEMBER_ID_REQUIRED异常,让客户端再发一次请求
debug(s"Dynamic member with unknown member id joins group ${group.groupId} in " +
s"${group.currentState} state. Created a new member id $newMemberId and request the member to rejoin with this id.")
group.addPendingMember(newMemberId)
addPendingMemberExpiration(group, newMemberId, sessionTimeoutMs)
responseCallback(JoinGroupResult(newMemberId, Errors.MEMBER_ID_REQUIRED))
} else {
info(s"${if (groupInstanceId.isDefined) "Static" else "Dynamic"} Member with unknown member id joins group ${group.groupId} in " +
s"${group.currentState} state. Created a new member id $newMemberId for this member and add to the group.")
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, newMemberId, groupInstanceId,
clientId, clientHost, protocolType, protocols, group, responseCallback)
}
}
}
}里面的代码逻辑
- 如果group状态是Dead了,则返回异常:COORDINATOR_NOT_AVAILABLE ;一般出现这种情况可能是协调器转移了, 需要让Member重试并找到正确的协调者并重新加入(JoinGroup)
- 计算newMemberId,格式在上面说过了。
- 如果是静态成员(配置了
group.instance.id) ,那么会去更新一些静态成员的缓存,然后Rebalance,这里不细说,Rebalance和下面一会要说的流程差不多 - 将刚刚计算得到的newMemberId放入到PendingMember缓存中,这个缓存存放的都是待加入的Member。
- 给这个待加入的Member一个
session.time.out(默认10s)的心跳监测有效期时间,如果超出这个时间消费者客户端还没有启动心跳线程去交互, 那么就会从PendingMember缓存中移除。移除之后就算你带了刚刚的newMemberId再发JoinGroupReques,那么也会识别不到,抛出UNKNOWN_MEMBER_ID异常 - 返回异常UNKNOWN_MEMBER_ID,表示JoinGroup请求需要传入MemberId,并把刚刚的newMemberId也一并返回, 期待他下一次请求给带上。
2.2 doJoinGroup
当消费者客户端经过了刚刚的doUnknownJoinGroup拿到了新的memberId之后,会再次发起JoinGropRequest, 这个时候入参memberId会带上刚刚的值。
那么就会走入真正的JoinGroup流程了, 那么这个流程做了哪些事情呢?我们一起来看看
GroupCoordinator#doJoinGroup
private def doJoinGroup(group: GroupMetadata,
memberId: String,
groupInstanceId: Option[String],
clientId: String,
clientHost: String,
rebalanceTimeoutMs: Int,
sessionTimeoutMs: Int,
protocolType: String,
protocols: List[(String, Array[Byte])],
responseCallback: JoinCallback): Unit = {
group.inLock {
if (group.is(Dead)) {
// 如果该组被标记为死亡,则意味着其他某个线程刚刚从协调器元数据中删除了该组;
// 这可能是该组已迁移到其他一些协调器,或者该组处于瞬态不稳定阶段。让成员重试找到正确的协调者并重新加入
responseCallback(JoinGroupResult(memberId, Errors.COORDINATOR_NOT_AVAILABLE))
} else if (!group.supportsProtocols(protocolType, MemberMetadata.plainProtocolSet(protocols))) {
responseCallback(JoinGroupResult(memberId, Errors.INCONSISTENT_GROUP_PROTOCOL))
} else if (group.isPendingMember(memberId)) {
// 重新加入的待定成员将被接受。请注意,待定成员永远不会是静态成员。
if (groupInstanceId.isDefined) {
throw new IllegalStateException(s"the static member $groupInstanceId was not expected to be assigned " +
s"into pending member bucket with member id $memberId")
} else {
debug(s"Dynamic Member with specific member id $memberId joins group ${group.groupId} in " +
s"${group.currentState} state. Adding to the group now.")
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, memberId, groupInstanceId,
clientId, clientHost, protocolType, protocols, group, responseCallback)
}
} else {
// 这里的逻辑 省略...
}
}
private def addMemberAndRebalance(rebalanceTimeoutMs: Int,
sessionTimeoutMs: Int,
memberId: String,
groupInstanceId: Option[String],
clientId: String,
clientHost: String,
protocolType: String,
protocols: List[(String, Array[Byte])],
group: GroupMetadata,
callback: JoinCallback): Unit = {
// 构建member对象
val member = new MemberMetadata(memberId, group.groupId, groupInstanceId,
clientId, clientHost, rebalanceTimeoutMs,
sessionTimeoutMs, protocolType, protocols)
member.isNew = true
// update the newMemberAdded flag to indicate that the join group can be further delayed
if (group.is(PreparingRebalance) && group.generationId == 0)
group.newMemberAdded = true
// 添加member,如果有callback!=null的话,则numMembersAwaitingJoin+1.
//意思是又有一个member正在等待加入。
group.add(member, callback)
// 重新设置一下心跳检测,并把设置设置为了5分钟, 一开始的时候是10s,意味着10s内要发起第二次的JoinGroup才行
// 但是走到了这里,把过期时间设置更大了一点, 这个时候客户端是还没有启动心跳线程的。
completeAndScheduleNextExpiration(group, member, NewMemberJoinTimeoutMs)
if (member.isStaticMember) {
info(s"Adding new static member $groupInstanceId to group ${group.groupId} with member id $memberId.")
group.addStaticMember(groupInstanceId, memberId)
} else {
// 把memberId从Pending缓存中移除, 因为已经在Group总添加了Member了
group.removePendingMember(memberId)
}
//尝试将group状态流转为 PreparingRebalance,并且发起再平衡
maybePrepareRebalance(group, s"Adding new member $memberId with group instance id $groupInstanceId")
}
简单的捋一捋代码逻辑, 分支条件太多,我们主要讲第二次JoinGroup的主流程。
- 做一些检验,group是否Dead。
- 构建member对象,并添加到Group中,如果有callback!=null的话,则numMembersAwaitingJoin+1. 意思是标记一下又有一个member正在等待加入
- 重新设置一下心跳检测,并把设置设置为了5分钟, 一开始的时候是10s,意味着10s内要发起第二次的JoinGroup才行 但是走到了这里,把过期时间设置更大了一点, 这个时候客户端是还没有启动心跳线程的。
- 把memberId从Pending缓存中移除, 因为已经在Group总添加了Member了
- 尝试将group状态流转为 PreparingRebalance,并且尝试完成Join ;执行onCompleteJoin
onCompleteJoin
上面的Group状态流转为了 PreparingRebalance, 就开始去完成Join的整个流程了。
上面都还只是把Member加入到了Group中, 这不能算是Join成功了, Join成功与否需要把状态返回给消费者客户端。
我们来看看下面的代码逻辑
GroupCoordinator#onCompleteJoin
def onCompleteJoin(group: GroupMetadata): Unit = {
group.inLock {
val notYetRejoinedDynamicMembers = group.notYetRejoinedMembers.filterNot(_._2.isStaticMember)
if (notYetRejoinedDynamicMembers.nonEmpty) {
info(s"Group ${group.groupId} remove dynamic members " +
s"who haven't joined: ${notYetRejoinedDynamicMembers.keySet}")
// 还有一些Member没有重新Join的 直接在Group中把他们给移除掉,心跳监测也移除掉
// 是否重新Rejoin的判断逻辑是, 请求的callback一只没有执行和设置为null。
notYetRejoinedDynamicMembers.values foreach { failedMember =>
//移除那些被移除的member的心跳监测 并在group中移除member
removeHeartbeatForLeavingMember(group, failedMember)
group.remove(failedMember.memberId)
// TODO: cut the socket connection to the client
}
}
if (group.is(Dead)) {
info(s"Group ${group.groupId} is dead, skipping rebalance stage")
} else if (!group.maybeElectNewJoinedLeader() && group.allMembers.nonEmpty) {
//如果所有成员都没有重新加入,我们将推迟重新平衡准备阶段的完成,并发出另一个延迟操作,直到会话超时删除所有未响应的成员。
error(s"Group ${group.groupId} could not complete rebalance because no members rejoined")
joinPurgatory.tryCompleteElseWatch(
new DelayedJoin(this, group, group.rebalanceTimeoutMs),
Seq(GroupKey(group.groupId)))
} else {
// 初始化下个Generation对象,Generation自增,如果member是空的,则group状态为Empty,协议也为None,
// 否则状态为CompletingRebalance
//关于分配协议的选择逻辑:找到所有Member都支持的分配协议, 然后让每个Member 根据自己的partition.assignment.strategy配置顺序
// 找到第一个所有人都支持的的协议投出一票
// 然后最后比较这些协议, 哪个投票数最多就当选为最终使用的分配协议。
//中心思想就是:1. 找到所有人都支持的协议 2. 1中的协议在partition.assignment.strategy中更靠前
group.initNextGeneration()
if (group.is(Empty)) {
info(s"Group ${group.groupId} with generation ${group.generationId} is now empty " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
// 如果Group是空的话,我们则在 __consumer_offset 里面写入一条Group的元数据,状态是Empty
groupManager.storeGroup(group, Map.empty, error => {
if (error != Errors.NONE) {
warn(s"Failed to write empty metadata for group ${group.groupId}: ${error.message}")
warn(s"onCompleteJoin 因为当前Group中的member位空了,所以要给Group中写入的空元信息,但是写入失败了, 不过问题也不大,只是警告一下 group ${group.groupId}: ${error.message}")
}
})
} else {
info(s"Stabilized group ${group.groupId} generation ${group.generationId} " +
s"(${Topic.GROUP_METADATA_TOPIC_NAME}-${partitionFor(group.groupId)})")
// trigger the awaiting join group response callback for all the members after rebalancing
// 当重平衡后触发所有等待Join group的members的的回调接口
for (member <- group.allMemberMetadata) {
val joinResult = JoinGroupResult(
// 如果这个member是leader的话,则传入所有members
members = if (group.isLeader(member.memberId)) {
group.currentMemberMetadata
} else {
List.empty
},
memberId = member.memberId,
generationId = group.generationId,
protocolType = group.protocolType,
protocolName = group.protocolName,
leaderId = group.leaderOrNull,
error = Errors.NONE)
group.maybeInvokeJoinCallback(member, joinResult)
completeAndScheduleNextHeartbeatExpiration(group, member)
member.isNew = false
}
}
}
}
}
简单的捋一捋代码逻辑
- 找到那些没有重新ReJoin的Member, 直接在Group中把他们给移除掉,心跳监测也移除掉 是否重新Rejoin的判断逻辑是, 请求的callback一只没有执行和设置为null。比如说:第一次Join了没有带参数memberId,那是不是得再次Join一下
- 如果发现Leader Member 还没有Join, 那么就会选举新的Leader,当然是选择当前Group的第一个Member为Leader咯。
- 初始化initNextGeneration,比如generationId += 1,状态流转为 CompletingRebalance,当然如果当前Group的member是空的,则流转为 Empty ; 有个非常重要的是:选择所有Member都支持的并且排序最高的分配策略作为当前的分配策略详细的看下面 分配策略的选择说明
- 如果Group的状态是Empty的, 则需要将当前Group的元信息存储内部Topic
__consumer_offset中。Group元信息的存储结构请看:消费组偏移量_consumer_offset的数据结构 - 如果不是Empty状态的话,那我们得给所有的Member返回JoinGroupResult数据了。这个数据包含了刚刚3步骤初始化的Generation数据,特别需要注意的是:如果Member是Leader角色, 还会把所有Member的元信息全部给他打包放到JoinGroupResult中, 非Leader不会。
- 回调Member的回调函数,把数据给返回
分配策略的选择
这里重点说下分配策略的选择, 因为分配策略是每个客户端的属性partition.assignment.strategy来控制的,并且分配策略可以设置多个 比如
partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor,org.apache.kafka.clients.consumer.RangeAssignor
那么整个消费组应该使用哪种方式来分配呢 ?
这个选择的原则如下
- 选择所有Member都支持的分配策略
- 在1的基础上,优先选择每个
partition.assignment.strategy配置靠前的策略。
请看下面的2个例子
| consumer-0 | consumer-1 | 选中策略 |
|---|---|---|
| roundrobin,rang | rang | rang |
| roundrobin,rang,strick | rang,strick | rang |
那么就会抛出异常:INCONSISTENT_GROUP_PROTOCOL
[2022-09-08 14:34:12,508] INFO [Consumer clientId=client2, groupId=consumer0] Rebalance failed. (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
org.apache.kafka.common.errors.InconsistentGroupProtocolException: The group member's supported protocols are incompatible with those of existing members or first group member tried to join with empty protocol type or empty protocol list.
[2022-09-08 14:34:12,511] ERROR Error processing message, terminating consumer process: (kafka.tools.ConsoleConsumer$)
更详细的请看 Kafka消费组分区分配策略
3 . 客户端处理返回数据
上面我们说到了 Join之后会给Member发起回调,那么拿到回调之和客户端是如何处理的呢?
JoinGroupResponseHandler#handle
private class JoinGroupResponseHandler extends CoordinatorResponseHandler<JoinGroupResponse, ByteBuffer> {
private JoinGroupResponseHandler(final Generation generation) {
super(generation);
}
@Override
public void handle(JoinGroupResponse joinResponse, RequestFuture<ByteBuffer> future) {
Errors error = joinResponse.error();
if (error == Errors.NONE) {
if (isProtocolTypeInconsistent(joinResponse.data().protocolType())) {
log.error("JoinGroup failed: Inconsistent Protocol Type, received {} but expected {}",
joinResponse.data().protocolType(), protocolType());
future.raise(Errors.INCONSISTENT_GROUP_PROTOCOL);
} else {
log.debug("Received successful JoinGroup response: {}", joinResponse);
sensors.joinSensor.record(response.requestLatencyMs());
synchronized (AbstractCoordinator.this) {
if (state != MemberState.PREPARING_REBALANCE) {
} else {
state = MemberState.COMPLETING_REBALANCE;
// 启动心跳线程
if (heartbeatThread != null)
heartbeatThread.enable();
AbstractCoordinator.this.generation = new Generation(
joinResponse.data().generationId(),
joinResponse.data().memberId(), joinResponse.data().protocolName());
log.info("Successfully joined group with generation {}", AbstractCoordinator.this.generation);
if (joinResponse.isLeader()) {
//如果是Leader Member的话,则需要计算一下新的分配方式,再发起SyncGroup请求
//并且会把新的分配数据给带上
onJoinLeader(joinResponse).chain(future);
} else {
//如果是Follower Member的话,直接发起SyncGroup请求
onJoinFollower().chain(future);
}
}
}
}
} else {
// 省略....
}
}
}
- 启动心跳线程,关于心跳线程请看:Kafka消费者客户端心跳请求
- 如果当前Member是Leader,则计算新的分区分配方式,把数据作为参数发起SyncGroupRequest
- 如果当前Member是Follow,直接发起SyncGroupRequest
关于SyncGroupRequest请看: Kafka消费者 SyncGroupRequest 流程解析
这里最非常重要的地方就是, 如果是Leader Member 则计算新的消费者分区分配方式。如何计算这个分配呢?
关于 消费组分区分配策略请看: Kafka消费组分区分配策略
4 . 总结
JoinGroup时序图
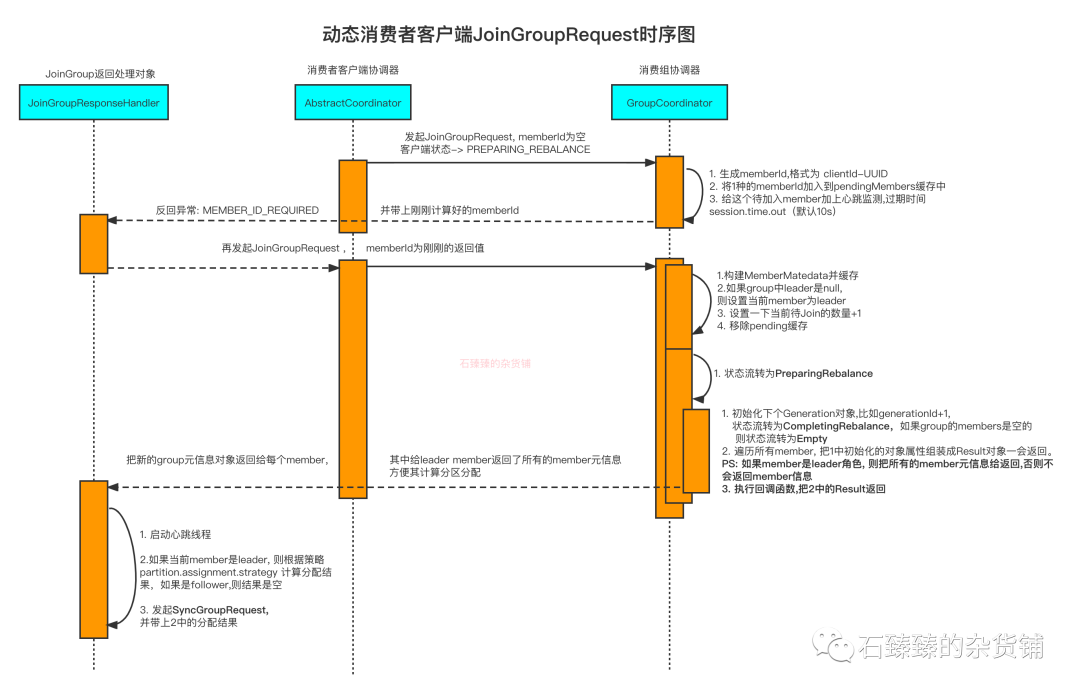
- 消费者客户端发起第一次请求, 协调器给它计算一个MemberId返回
- 消费者客户端发起第二次请求,MemberId是刚刚得到的。
- 消费组协调器处理请求,构建新的MemberMetadata元信息缓存到Group中。
- 消费组协调器将状态流转为 PreparingRebalance
- 初始化Generation数据,比如generationId+1, Group状态流转为 CompletingRebalance,当然如果当前Group的member是空的,则流转为 Empty ;
- 将上面的数据组装一下为JoinGroupResult,返回给所有的Member, 当然如果是Leader Member的话, 还会额外给他所有Member的元信息(因为它要用这些数据去计算新的分区分配的数据。)
- 消费者客户端拿到数据之后, 像消费组协调器发起SyncGroupRequest的请求, 如果是Leader Member的话, 则会根据分区策略去计算一下新的分配策略,并把数据带上发起SyncGroupRequest的请求。关于SyncGroupRequest请看: Kafka消费者 SyncGroupRequest 流程解析
5 . Q&A
1. 谁是消费组协调器
每个消费组对应一个消费组协调器,每个消费组对应着一个
__consumer_offset的分区。计算分区号的方式为:( hash(groupId)%__consumer_offset的分区数 ) 确定了消费组的分区之后, 再找到这个分区的Leader,那么这个Leader分区所在的Broker节点就是消费组协调器。
2. 什么是Leader Member , Leader Member 选举策略
每个消费组中都有很多消费者成员,Kafka内称为Member, 消费组协调器会持有所有的Member的元信息, 但是这么多Member里面会选择一个Member成为Leader Member,其他的为Follow Member, Leader Member的主要作用就是可以计算分区分配方案返回给协调器。
附录: 消费者客户端状态流转图和消费组协调器状态流转图