优雅代码的秘密,都藏在这6个设计原则中
前言
优雅的代码,犹如亭亭玉立的美女,让人赏心悦目。而糟糕的代码,却犹如屎山,让人避而远之。
如何写出优雅的代码呢?那就要理解并熟悉应用这6个设计原则啦:开闭原则、单一职责原则、接口隔离原则 、迪米特法则、里氏替换原则、依赖倒置原则。本文呢,将通过代码demo,让大家轻松理解这6个代码设计原则,加油~
1 . 开闭原则
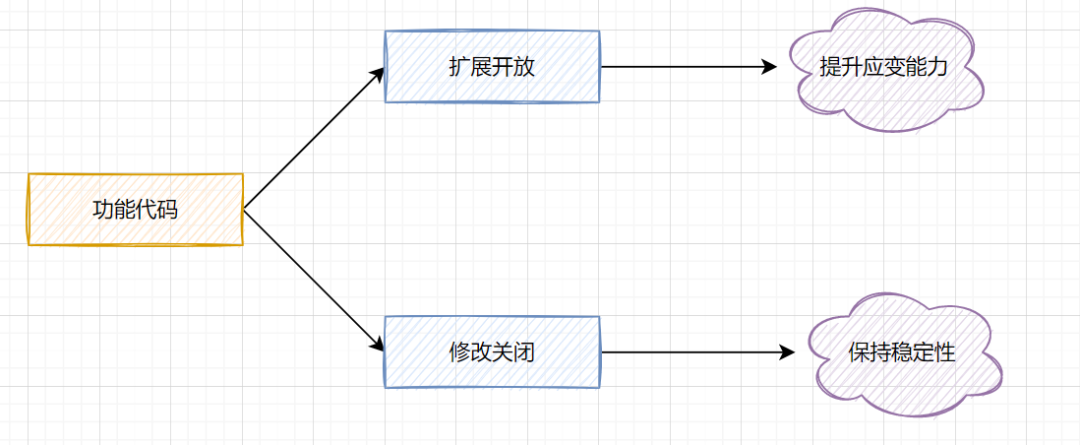
开闭原则,即对扩展开放,对修改关闭。
对于扩展和修改,我们怎么去理解它呢?扩展开放表示,未来业务需求是变化万千,代码应该保持灵活的应变能力。修改关闭表示不允许在原来类修改,保持稳定性。
bug。因此,我们的代码应该遵循开闭原则,也就是对扩展开放,对修改关闭。
为了方便大家理解开闭原则,我们来看个例子:假设有这样的业务场景,大数据系统把文件推送过来,根据不同类型采取不同的解析方式。多数的小伙伴就会写出以下的代码:
if(type=="A"){
//按照A格式解析
}else if(type=="B"){
//按B格式解析
}else{
//按照默认格式解析
}这段代码有什么问题呢?
- 如果分支变多,这里的代码就会变得臃肿,难以维护,可读性低。
- 如果你需要接入一种新的解析类型,那只能在原有代码上修改。
显然,增加、删除某个逻辑,都需要修改到原来类的代码,这就违反了开闭原则了。为了解决这个问题,我们可以使用策略模式去优化它。
你可以先声明一个文件解析的接口,如下:
public interface IFileStrategy {
//属于哪种文件解析类型,A或者B
FileTypeResolveEnum gainFileType();
//封装的公用算法(具体的解析方法)
void resolve(Object param);
}然后实现不同策略的解析文件,如类型A解析:
@Component
public class AFileResolve implements IFileStrategy {
@Override
public FileTypeResolveEnum gainFileType() {
return FileTypeResolveEnum.File_A_RESOLVE;
}
@Override
public void resolve(Object objectparam) {
logger.info("A 类型解析文件,参数:{}",objectparam);
//A类型解析具体逻辑
}
}
如果未来需求变更的话,比如增加、删除某个逻辑,不会再修改到原来的类啦,只需要修改对应的文件解析类型的类即可。
对于如何使用设计模式,大家有兴趣的话,可以看我以前的这篇文章哈:[实战!工作中常用到哪些设计模式]
2 . 单一职责原则
单一职责原则:一个类或者一个接口,最好只负责一项职责。比如一个类C违反了单一原则,它负责两个职责P1和P2。当职责P1需要修改时,就会改动到类C,这就可能导致原本正常的P2也受影响。
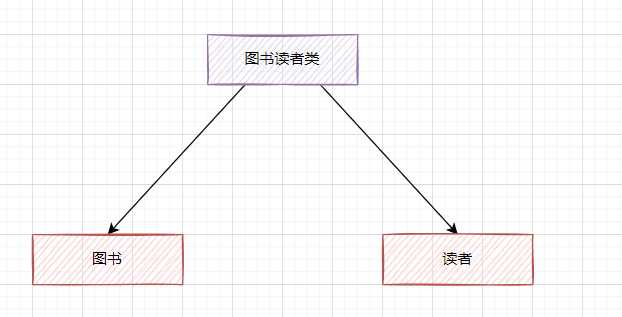
如何更好理解呢?比如你实现一个图书管理系统,一个类既有图书的增删改查,又有读者的增删改查,你就可以认为这个类违反了单一原则。因为这个类涉及了不同的功能职责点,你可以把这个拆分。
- 类中的私有方法过多
- 你很难给类起一个合适的名字
- 类中的代码行数、函数或者属性过多
- 类中大量的方法都是集中操作类中的某几个属性
- 类依赖的其他类过多,或者依赖类的其他类过多
比如,你写了一个方法,这个方法包括了日期处理和借还书的业务操作,你就可以把日期处理抽到私有方法。再然后,如果你发现,很多私有方法,都是类似的日期处理,你就可以把这个日期处理方法抽成一个工具类。
日常开发中,单一原则的思想都有体现的。比如微服务拆分。
3 . 接口隔离原则
接口隔离原则:接口的调用者或者使用者,不应该强迫依赖它不需要的接口。它要求建立单一的接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少,让接口中只包含客户(调用者)感兴趣的方法。即一个类对另一个类的依赖应该建立在最小的接口上。
比如类A通过接口I依赖类B,类C通过接口I依赖类D,如果接口I对于类A和类B来说,都不是最小接口,则类B和类D必须去实现他们不需要的方法。如下图:
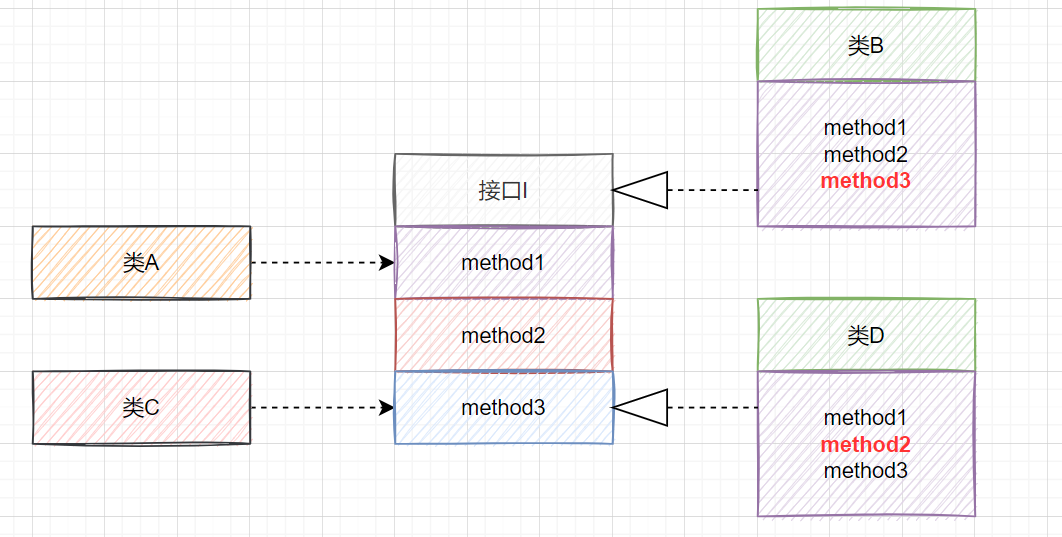
A依赖接口I中的method1、method2,类B是对类A依赖的实现。类C依赖接口I中的method1、method3,类D是对类C依赖的实现。对于实现类B和D,它们都存在用不到的方法,但是因为实现了接口I,所以必须要实现这些用不到的方法。
可以看下以下代码:
public interface I {
void method1();
void method2();
void method3();
}
@Service
public class A {
@Resource(name="B")
private I i;
public void depend1() {
i.method1();
}
public void depend2(){
i.method2();
}
}
@Service("B")
public class B implements I {
@Override
public void method1() {
System.out.println("类B实现接口I的方法1");
}
@Override
public void method2() {
System.out.println("类B实现接口I的方法2");
}
//没用到这个方法,但是也要默认实现,因为I有这个接口方法
@Override
public void method3() {
}
}
@Service
public class C {
@Resource(name="D")
private I i;
public void depend1(I i){
i.method1();
}
public void depend3(I i){
i.method3();
}
}
@Service("D")
public class D implements I {
@Override
public void method1() {
System.out.println("类D实现接口I的方法1");
}
//没用到这个方法,但是也要默认实现,因为I有这个接口方法
@Override
public void method2() {
}
@Override
public void method3() {
System.out.println("类D实现接口I的方法3");
}
}大家可以发现,如果接口过于臃肿,只要接口中出现的方法,不管对依赖于它的类有没有用到,实现类都必须去实现这些方法。实现类B没用到method3,它也要有个默认实现。实现类D没用到method2,它也要有个默认实现。
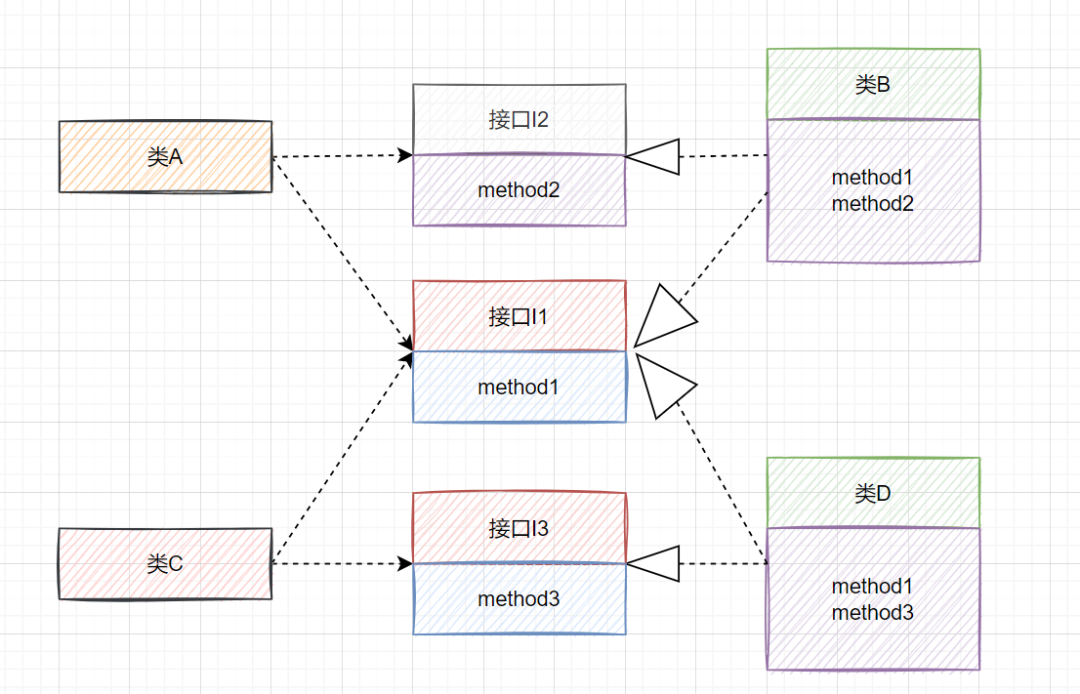
显然,这不是一个好的设计,违反了接口隔离原则。我们可以对接口I进行拆分。拆分后的设计如图2所示:
- 接口尽量小,但是要有限度。对接口进行细化可以提高程序设计灵活性是不挣的事实,但是如果过小,则会造成接口数量过多,使设计复杂化。所以一定要适度。
- 为依赖接口的类定制服务,只暴露给调用的类它需要的方法,它不需要的方法则隐藏起来。只有专注地为一个模块提供定制服务,才能建立最小的依赖关系。
- 提高内聚,减少对外交互。使接口用最少的方法去完成最多的事情。运用接口隔离原则,一定要适度,接口设计的过大或过小都不好。设计接口的时候,只有多花些时间去思考和筹划,才能准确地实践这一原则。
4 . 迪米特法则
定义:又叫最少知道原则。一个类对于其他类知道的越少越好,就是说一个对象应当对其他对象有尽可能少的了解,只和朋友谈心,不和陌生人说话。它的核心思想就是,尽量降低类与类之间的耦合,尽最大能力减小代码修改带来的对原有的系统的影响。
比如一个生活例子:你对你的对象肯定了解的很多,但是如果你对别人的对象也了解很多,你的对象要是知道,那就要出大事了。
我们来看下一个违反迪米特法则的例子,业务场景是这样的:一个学校,要求打印出所有师生的ID。
//学生
class Student{
private String id;
public void setId(String id){
this.id = id;
}
public String getId(){
return id;
}
}
//老师
class Teacher{
private String id;
public void setId(String id){
this.id = id;
}
public String getId(){
return id;
}
}
//管理者(班长)
public class Monitor {
//所有学生
public List<Student> getAllStudent(){
List<Student> list = new ArrayList<Student>();
for(int i=0; i<100; i++){
Student student = new Student();
//为每个学生分配个ID
student.setId("学生Id:"+i);
list.add(student);
}
return list;
}
}
//校长
public class Principal {
//所有教师
public List<Teacher> getAllTeacher(){
List<Teacher> list = new ArrayList<Teacher>();
for(int i=0; i<20; i++){
Teacher emp = new Teacher();
//为全校老师按顺序分配一个ID
emp.setId("老师编号"+i);
list.add(emp);
}
return list;
}
//所有师生
public void printAllTeacherAndStudent(ClassMonitor classMonitor) {
List<Student> list1 = classMonitor.getAllStudent();
for (Student s : list1) {
System.out.println(s.getId());
}
List<Teacher> list2 = this.getAllTeacher();
for (Teacher teacher : list2) {
System.out.println(teacher.getId());
}
}
}
这块代码。问题出在类Principal中,根据迪米特法则,只能与直接的朋友发生通信,而Student类并不是Principal类的直接朋友(以局部变量出现的耦合不属于直接朋友),从逻辑上讲校长Principal只与管理者Monitor耦合就行了,可以让Principal继承类Monitor,重写一个printMember的方法。优化后的代码如下:
public class Monitor {
public List<Student> getAllStudent(){
List<Student> list = new ArrayList<Student>();
for(int i=0; i<100; i++){
Student student = new Student();
//为每个学生分配个ID
student.setId("学生Id:"+i);
list.add(student);
}
return list;
}
public void printMember() {
List<Student> list = this.getAllStudent();
for (Student student : list) {
System.out.println(student.getId());
}
}
}
public class Principal extends Monitor {
public List<Teacher> getAllTeacher(){
List<Teacher> list = new ArrayList<Teacher>();
for(int i=0; i<30; i++){
Teacher emp = new Teacher();
//为全校老师按顺序分配一个ID
emp.setId("老师编号"+i);
list.add(emp);
}
return list;
}
public void printMember() {
super.printMember();
for (Teacher teacher : this.getAllTeacher()) {
System.out.println(teacher.getId());
}
}
}5 . 里氏替换原则
里氏替换原则:
如果对每一个类型为
S的对象o1,都有类型为T的对象o2,使得以T定义的所有程序P在所有的对象o1都代换成o2时,程序P的行为没有发生变化,那么类型S是类型T的子类型。
一句话来描述就是:只要有父类出现的地方,都可以用子类来替代,而且不会出现任何错误和异常。 更通俗点讲,就是子类可以扩展父类的功能,但是不能改变父类原有的功能。
其实,对里氏替换原则的定义可以总结如下:
- 子类可以实现父类的抽象方法,但不能覆盖父类的非抽象方法
- 子类中可以增加自己特有的方法
- 当子类的方法重载父类的方法时,方法的前置条件(即方法的输入参数)要比父类的方法更宽松
- 当子类的方法实现父类的方法时(重写/重载或实现抽象方法),方法的后置条件(即方法的的输出/返回值)要比父类的方法更严格或相等
我们来看个例子:
public class Cache {
public void set(String key, String value) {
}
}
public class RedisCache extends Cache {
public void set(String key, String value) {
}
}这里例子是没有违反里氏替换原则的,任何父类、父接口出现的地方子类都可以出现。如果给RedisCache加上参数校验,如下:
public class Cache {
public void set(String key, String value) {
}
}
public class RedisCache extends Cache {
public void set(String key, String value) {
if (key == null || key.length() < 10 || key.length() > 100) {
System.out.println("key的长度不符合要求");
throw new IllegalArgumentException();
}
}
}这就违反了里氏替换原则了,因为子类方法增加了加了参数校验,抛出了异常,虽然子类仍然可以来替换父类。
6.依赖倒置原则
依赖倒置原则定义:
高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象。它的核心思想是:要面向接口编程,而不要面向实现编程。
依赖倒置原则可以降低类间的耦合性、提高系统的稳定性、减少并行开发引起的风险、提高代码的可读性和可维护性。要满足依赖倒置原则,我们需要在项目中满足这个规则:
- 每个类尽量提供接口或抽象类,或者两者都具备。
- 变量的声明类型尽量是接口或者是抽象类。
- 任何类都不应该从具体类派生。
- 使用继承时尽量遵循里氏替换原则。
我们来看一段违反依赖倒置原则的代码,业务需求是:顾客从淘宝购物。代码如下:
class Customer{
public void shopping(TaoBaoShop shop){
//购物
System.out.println(shop.buy());
}
}以上代码是存在问题的,如果未来产品变更需求,改为顾客从京东上购物,就需要把代码修改为:
class Customer{
public void shopping(JingDongShop shop){
//购物
System.out.println(shop.buy());
}
}如果产品又变更为从天猫购物呢?那有得修改代码了,显然这违反了开闭原则。顾客类设计时,同具体的购物平台类绑定了,这违背了依赖倒置原则。可以设计一个shop接口,不同购物平台(如淘宝、京东)实现于这个接口,即修改顾客类面向该接口编程,就可以解决这个问题了。代码如下:
class Customer{
public void shopping(Shop shop){
//购物
System.out.println(shop.buy());
}
}
interface Shop{
String buy();
}
Class TaoBaoShop implements Shop{
public String buy(){
return "从淘宝购物";
}
}
Class JingDongShop implements Shop{
public String buy(){
return "从京东购物";
}
}