盘点低延时网络架构中使用的那些黑科技!
大家好 !最近我简单研究了一下低延迟网络架构,今天和大家分享分享。
谈到优秀的低延时网络架构,大家首先可能想到的是各家互联网大厂,比如腾讯阿里字节,总会觉得大厂做的肯定最好。但其实在在一般的互联网应用中,用户虽然也讨厌卡顿,但整体上来对延迟其实并不算太敏感,只要按钮点下后一秒之内能响应,用户就基本感觉不出来。甚至是两三秒才响应用户也都还能接受。
所以在今天的互联网公司中,虽然也关注服务访问延迟,但其实优化并没有往特别极致了去做。
而在整个业界中有这么一个细分的领域,对延迟却极其的敏感,那就是高频量化交易场景。因为在这种业务中,同样的价格,先出价的人先成交。
如果一家量化交易公司比竞争对手哪怕多 1 ms(毫秒)的延迟,可能也会意味着会损失很多钱。据某个专业市场机构的评估,在全球的电子交易中,如果交易处理时间比对手慢 5 ms 可能就会损失 1% 的利润。慢 10 ms 损失会扩大到 10 %。
所以高频量化交易场景中的网络架构几乎是全球最顶级的低延时网络架构了,非常值得学习。我请教了朋友圈中几位从事量化交易的专业人士,也看了一些技术资料,初步对这个网络架构有了一点点理解。总结出来,分享给大家!
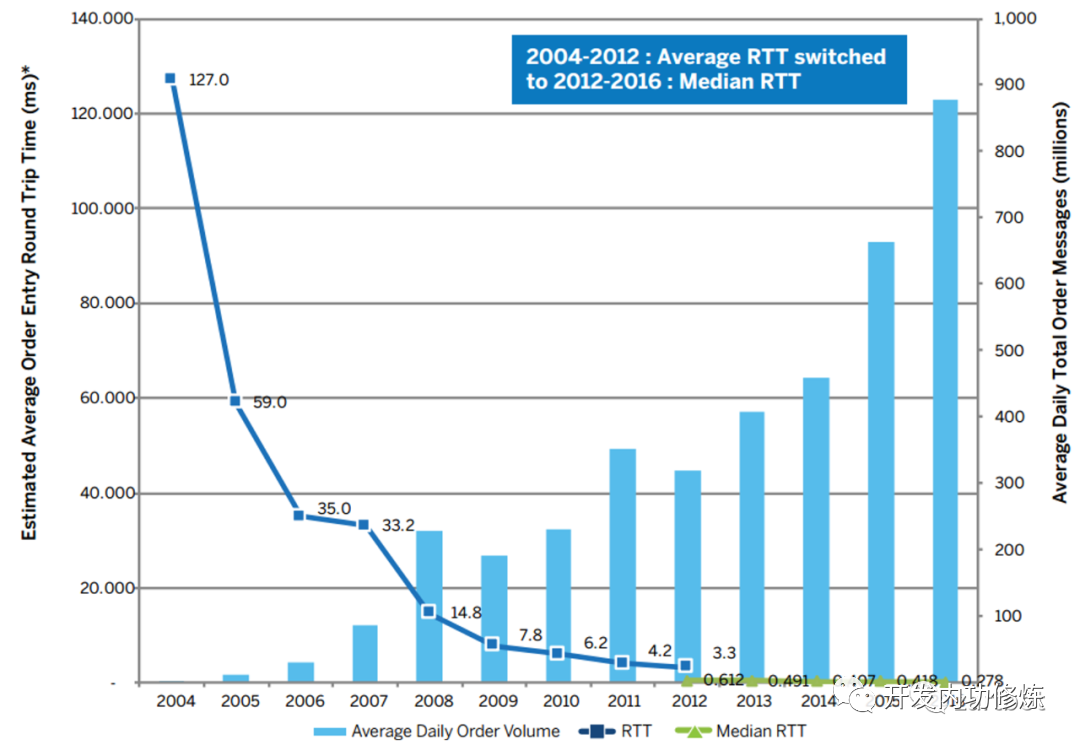
我们先来看一组某交易所的数据,其交易延迟早在 2016 年的时候就优化到了 278 us(微秒)。
一个网络请求从用户发出,到最终处理完毕,其延时总体上可以划分为两块,一是网络转发延迟,二是系统处理延迟。

我们分这两块来看看高频量化交易的网络架构中都用了哪些黑科技。
一、网络转发延迟
在网络上,高频量化交易中采用了极致的优化。
1.1 就近部署&专线
就近部署是最简单有效的方法,链路上传输比较耗时那就直接把链路降低的短一些。很多交易中心都在交易所附近租服务器,这种方法还有个专门的名字叫 Co-location。
还有就是跨地区的话,通过独占的物理线连接。这样可以用最短的物理线路,也不用受公网传输数据的干扰,稳定性和安全性也更好。这个在国内用的还是很多的,因为相对下面的微波传输网络成本要低很多。
1.2 微波传输
提到光速,我们都知道它的速度是 3 × 10 的 8 次方 m/s。但其实光在不同介质中的传播速度是不一样的,介质密度越大,光在其中传播速度会越慢。光在空气中的速度比在真空中的速度略慢一点,基本接近。但在光纤中的速度就打折的很厉害了,其速度大致为真空光速的 50% - 66% 左右。
另外还有就是任何两地之间铺设光缆的话,很难做到完全笔直,总是会存在很多的弯弯绕。比如从哈尔滨要想访问上海,需要先经过北京等许多个中转节点。这样实际光纤的传输距离也会增加很多。
量化交易网络应用中为了追求极致的低延迟,在核心网络上采用了微波传输。让信号就在空气中传播,而不是光纤。
在美国加哥商品交易所和新泽西州的纳斯达克数据中心就存在这样一条微波传输网络。将两地的 RTT 从 2012 年的 8.7 ms 削减到了 2016 年的 7.9 ms。
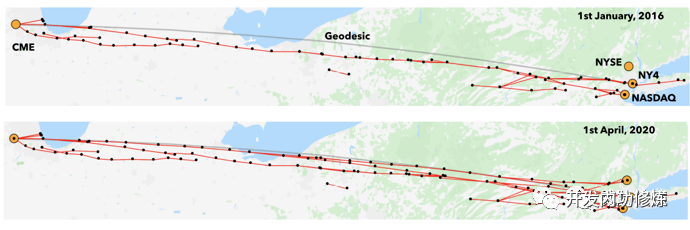
另外就是马斯克的星链网络,也能提供更低延迟的超长距离场景(跨大洋、跨大陆)的网络传输。
1.3 InfiniBand 替换以太网
有少量交易所还使用 InfiniBand 替换了以太网。
在 InfiniBand 网络中包含两部分,一部分是物理链路协议。第二部分是远程直接内存访问 RDMA。
在物理链路协议上,以太网就像一个快递包裹分发网络。网络上的每一个节点都需要先把网络包接收下来,然后看看它的二层或三层地址信息算一下该怎么发,再选择一个出口丢到发送队列等待再发出去。
整个的转发过程其实不是特别高效。还有一种中转转发方式是类似铁路交叉轨道,当有数据到达的时候,提前把轨道变好,数据包到达后直接转发就行了。不用先全部收下来,算一算再转发。
InfiniBand 就是这样一种网络。我找到了一个网卡首发延迟数据对比。基于Ethernet上的TCP UDP应用的收发时延会在10us左右,而InfiniBand的网卡收发时延(write,send)在600ns左右
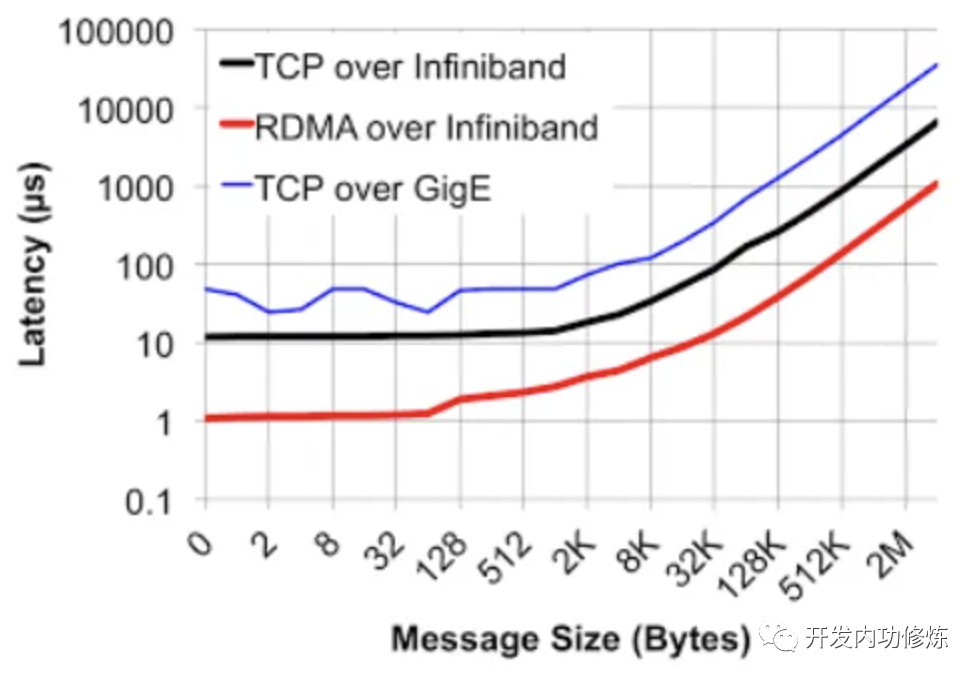
由于转发极其高效,所以在可靠性上,InfiniBand 网络也没有像 Ethernet 网络中存在的抖动问题。
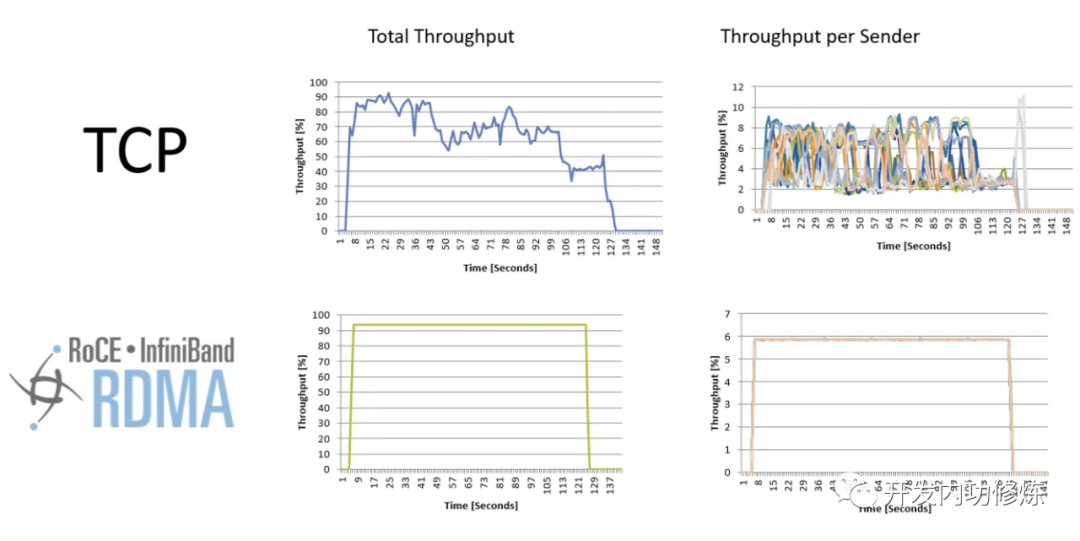
InfiniBand 网络的第二个优势就是从设计之初就考虑了 RDMA,延时很低。这个稍后我们专门介绍 RDMA 时再说。
不过 InfiniBand 的缺点也不少,需要调度中心,成本较高,地址空间也有限制。所以目前只有少数交易所在用。
1.4 更大的带宽
更大的带宽通常可以缓解延迟。这个很好理解,数据包大小一定的情况下,在大带宽网络下肯定发送的更快。

所以在交易场景下采用的都是 10 Gbps 甚至是 25 Gbps 的网络。
1.5 低延迟交换机
传统交换机都是工作在二层上。为了解决信号之间的碰撞,搞出了 CSMA/CD 等协议。但其实只要没有冲突的话,就不必这么麻烦了。
Arista 公司生产的交换机设备可以不用在二层,直接在物理层转发。就好像是一根整的光纤一样。信号从一个端口进去,直接无冲突地转发到另外一个端口(或者多个端口)就发出来了。
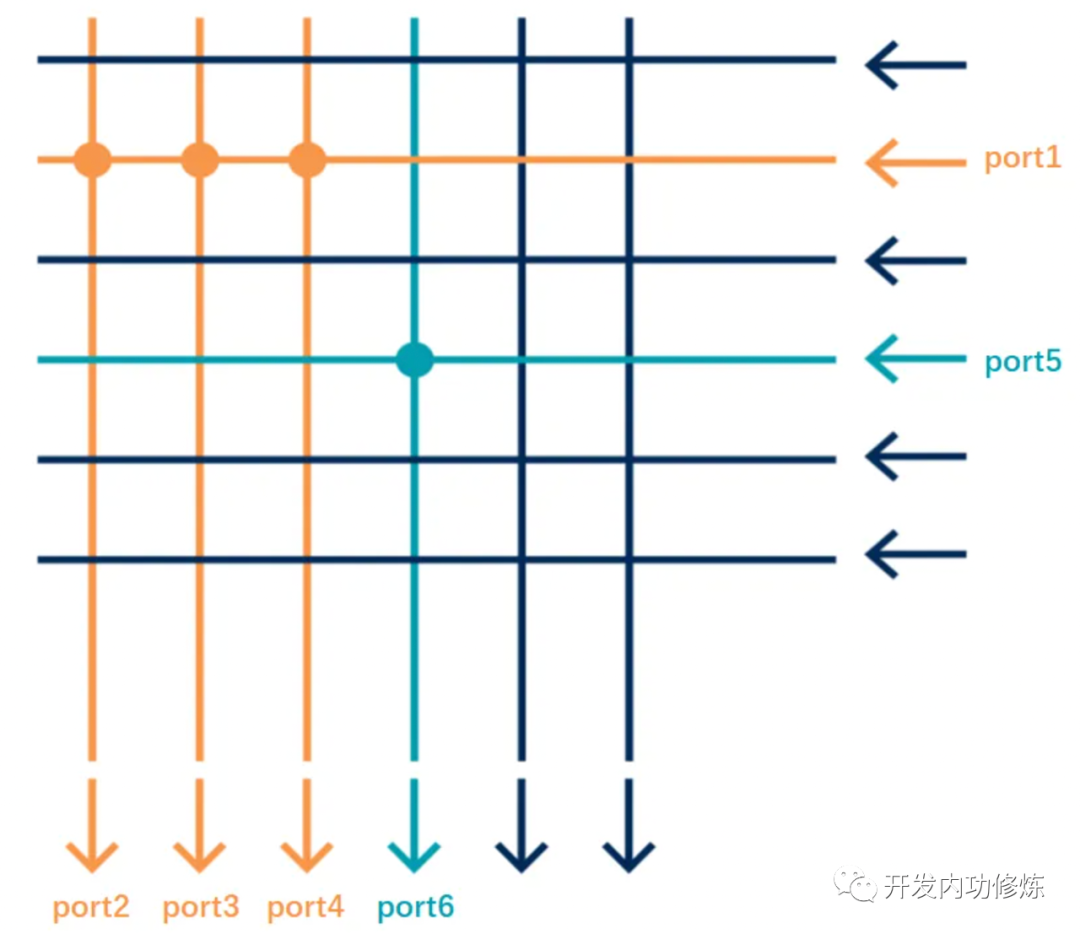
参见 Arista 官网:https://www.arista.com/zh/products/7130-series
二、系统处理延迟
当用户请求到达服务器后,系统就可以开始接收和处理请求了。在这个过程中,高频交易场景同样进行了很多的优化
2.1 Kernel By Pass
大家总以为内核已经久经考验,已经极致优化过了。对于一般应用场景来说确实是这样,但是对于延迟要求极其高的场景来说,还存在过多的性能开销。
网络包接收的时候要经过层层协议栈处理,最后发到接收队列中。再唤醒用户进程,上下文通知用户进程。
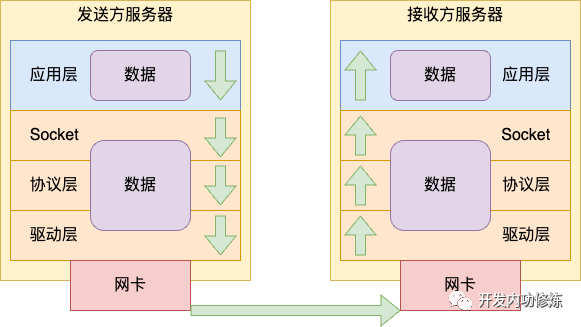
这个过程我在网络篇的文章中都介绍过了。全部文章列表参见:https://github.com/yanfeizhang/coder-kung-fu
另外就是用户进程收到内核通知也不是立即就能运行的,需要在 CPU 的运行队列中排个队。内核中的进程调度也不是抢占式的,等真正开始运行的时候,搞不好 10 个毫秒都过去了。
如果沿用传统的内核方式,在网络链路上耗费巨资节约的几个毫秒可能在这里就全部葬送了。Kernel by pass 类的技术就是在绕过内核协议栈,直接在用户态轮询等待用户请求,一旦有立即开始处理。节约了大量的内核态开销,以及内核态用户态的切换开销。
这类技术包括 Solarflare 的 Onload 和 Exablaze 的 ExaSOCK,在量化交易中大量地被采用!如下是我在 Solarflare 官网上截的一张工作原理图。
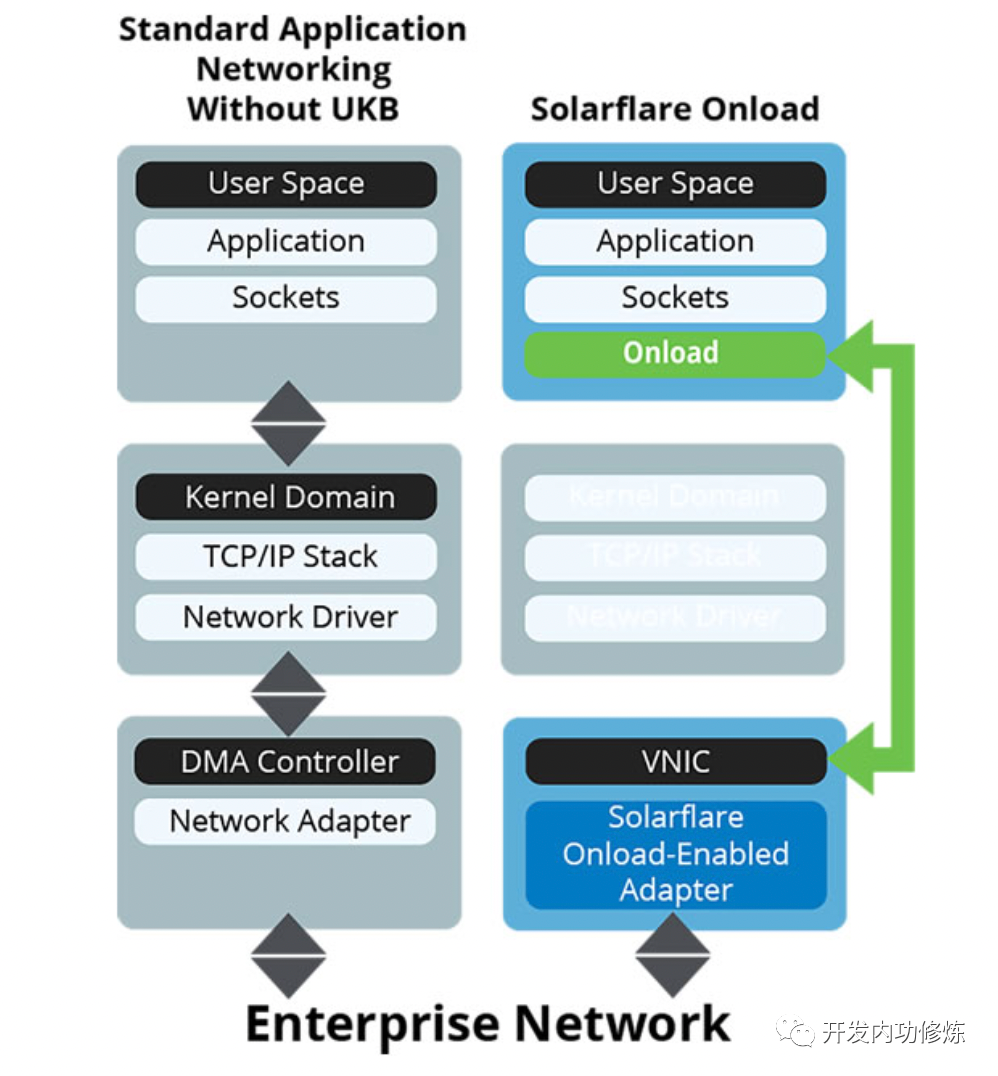
2.2 RDMA
远程直接内存访问 RDMA 是另外一种解决内核开销的方法。在前面我们介绍的 InfiniBand 天生就支持 RDMA。除了 InfiniBand 外,还有 RoCE 和 iWARP 两种 RDMA 方案。它们都实现了直接远程操作接收方内存的能力,从而降低了延迟。
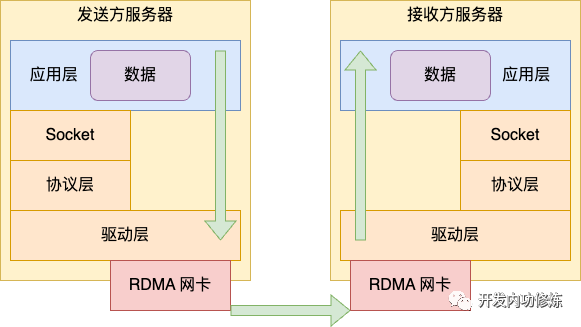
相比 InfiniBand ,RoCE 和 iWARP 两种 RDMA 方案兼容现在的 Ethernet 链路层的,不用使用专门的交换机,但是也必须得使用专用的网卡硬件。
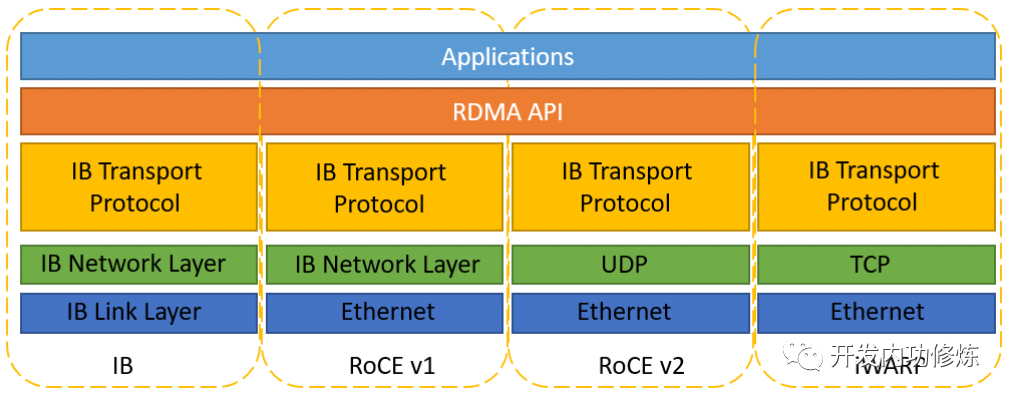
RoCE 协议存在 RoCEv1 和 RoCEv2 两个版本。RoCE v1 是基于以太网链路层实现的 RDMA 协议(交换机需要支持 PFC 等流控技术,在物理层保证可靠传输),允许在同一个VLAN中的两台主机进行通信。RoCE v2克服了 RoCE v1绑定到单个VLAN的限制。通过改变数据包封装,包括IP和UDP标头,RoCE v2 现在可以跨 L2 和 L3 网络使用。
2.3 TOE 硬件卸载
传统的计算都是由 CPU 进行的。但是 CPU 的性能已经发展到了极限,无法进一步提升了。下一步的提升思路就是如何将一些计算工作从 CPU 中卸载出来,由其他的硬件来完成,例如 DPU 和 FPGA。
TOE 的全称是 TCP offload Engine,指的是将 TCP 协议卸载到 FPGA 硬件中。在高频量化交易中,大量地采用了 FPGA 编程计算。
FPGA 相比 GPU 的核心优势在于低延迟。所有数据均不需要跨越 PCIE 总线,另外在 FPGA 的数据传输不需要进行多次数据拷贝。其加速效果甚至可以达到 CPU 的 10 - 100 倍。
有的公司还用 FPGA 不仅把 TCP、IP、epoll 等机制实现了,甚至还包括业务逻辑处理,这样可以把系统延时做到百纳秒级别,甚至几十纳秒。
2.4 其他优化方法
除了以上几个方法以外,高频量化交易场景在系统的各个位置都会注重耗时的优化。
在内存上,堆大量的内存换取时间,使用的内存通常都是 1 TB 起步。
在 CPU 硬件上,会采购主频较高的 CPU。一般普通的服务器 CPU 主频在 3 GHz 多点,而量化交易甚至都会采购 5 GHz 主频的硬件。也会通过 BIOS 调整进制 CPU 进入省电降频模式。
在进程运行上,会把线程单独绑定在一个核上运行,独占该 CPU 核心,充分利用 CPU 的缓存,也会非常主动 CacheLine 对齐。也会尽可能少地调用系统调用,避免用户态内核态切换开销。通过各种方式极致地降低延迟。
三、总结
一个网络请求从用户发出,到最终处理完毕,其延时总体上可以划分为两块,一是网络转发延迟,二是系统处理延迟。
高频量化交易公司在网络转发延迟上采取的优化手段有微波传输、InfiniBand、低延迟交换机,就近部署、拉网络专线等。
在系统处理延迟上,大量地采用 Kernel By Pass 来降低内核处理延迟,部分公司还采用了 RDMA 类的技术。在计算上将大量的计算密集型的工作从 CPU 上卸载到 FPGA 中完成。
当然传统的优化手段量化公司也在用,例如大内存换时间,高频 CPU、绑核等等。
总之,量化交易公司采用了各种业界先进的技术来降低处理延迟。