基于 eBPF的网络性能问题实例分析

随着 eBPF 技术的广泛应用,在操作系统层面提供了更多的观测能力,站在操作系统层面对应用的行为数据进行 trace 追踪成了一种应用监控的新手段,本文主要介绍基于 eBPF 实现对应用网络数据监控的背后逻辑。
一、一个请求数据包的组成
一个完整的应用请求数据包主要包含请求地址信息及具体的请求数据。其中请求地址信息就是我们常说的五元组信息(IP+端口+协议),这部分都是操作系统协议栈负责去解析;而请求数据则由应用通过各种协议去封装并解析,常见的应用协议有:http、mysql、rediis、dns 等。

二、基于系统调用的请求追踪
2.1 网络请求模型
一个应用进程基于系统调用的网络请求模型如下(这里仅介绍客户端):- 通过 socket 去建立套接字,获得一个 fd 作为 socket 的标识。
- 通过 connect 填写 IP 端口信息发起请求连接。
- 通过read/write请求/接收具体数据,除了read/write系统调用还有send/recvfrom,readv/writev 等可用。
- 通过 close 结束本次请求。
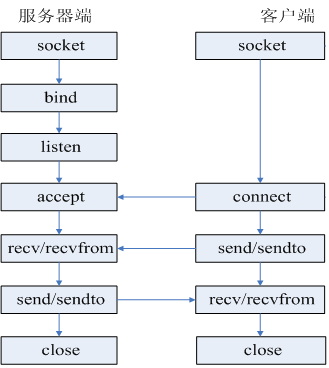
- 对于单个建链完成的请求而言,其发送数据和接收数据往往是串行的,或者说一个 write 必然匹配一个 read,因此我们才能统计到 RT 时间,而 read/write 的返回字节数就可以作为我们的流量统计。
- write/read 如何配对,对于客户端而言,是先 write 再 read,常用的做法是通过进程 pid 和 socket fd 作为配对标识,实现 write/read 这一次完整请求数据的配对。
2.2 系统调用追踪eBPF 技术可以在不改变内核源码或加载内核模块情况下在内核插入指定 hook 代码,能在内核或应用程序执行到一个特定的 hook 点时执行。预定义的 hooks 包含系统调用、 函数出/入口、内核追踪点、网络事件等等。
上文中提到 pid+fd 作为 traceid 作为请求的唯一标志,有如下两种方法可以实现:
方法1:当有 connect 的时候先在 BPF map 中记录下这个 traceid,表示有一个新的请求建立,后续的 read/write 请求数据都是以此为配对。不过在 http 长连接场景下,connect 发起可能在我们 trace 之前,所以只能通过 netlink 等其他方式来获取链接信息。
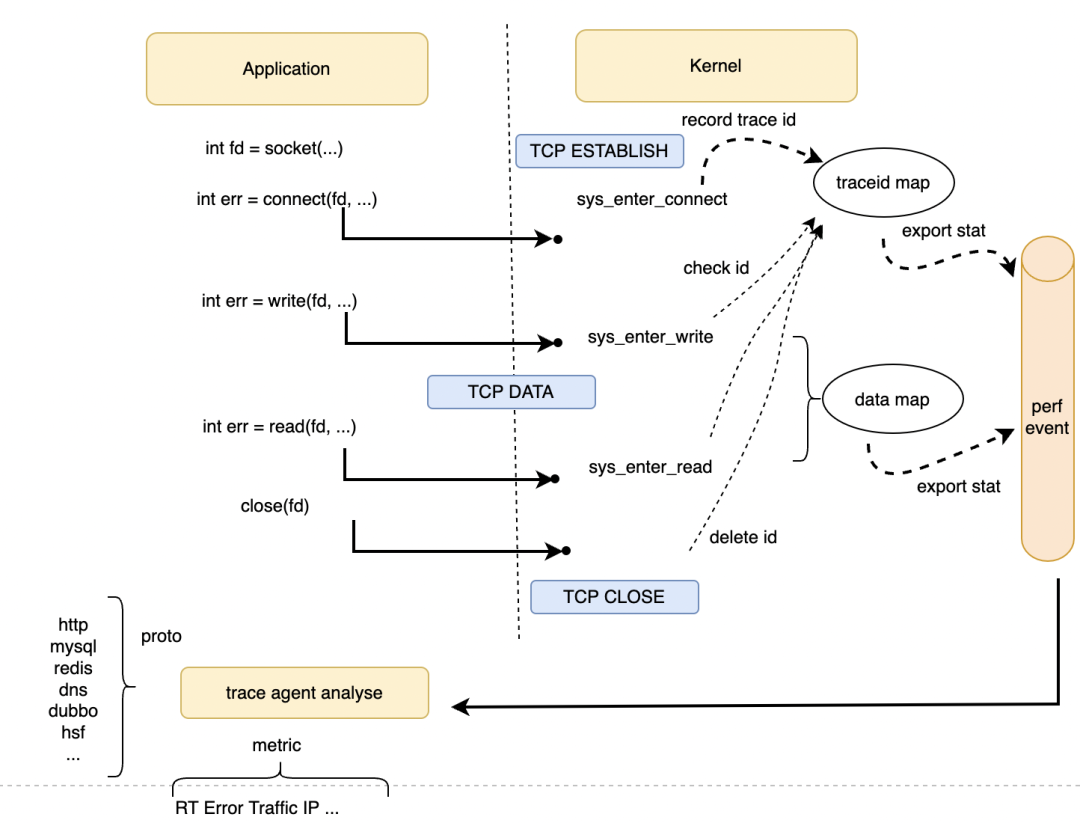
方法2:实际上我们关心的只是 read/write 的请求数据及如何配对,是否可以仅根据 fd 获取连接信息?BPF 程序可以拿到当前进程的 task_struct,根据 fd 可以拿到对应的 sock 结构体,sock 结构体中记录了请求地址信息。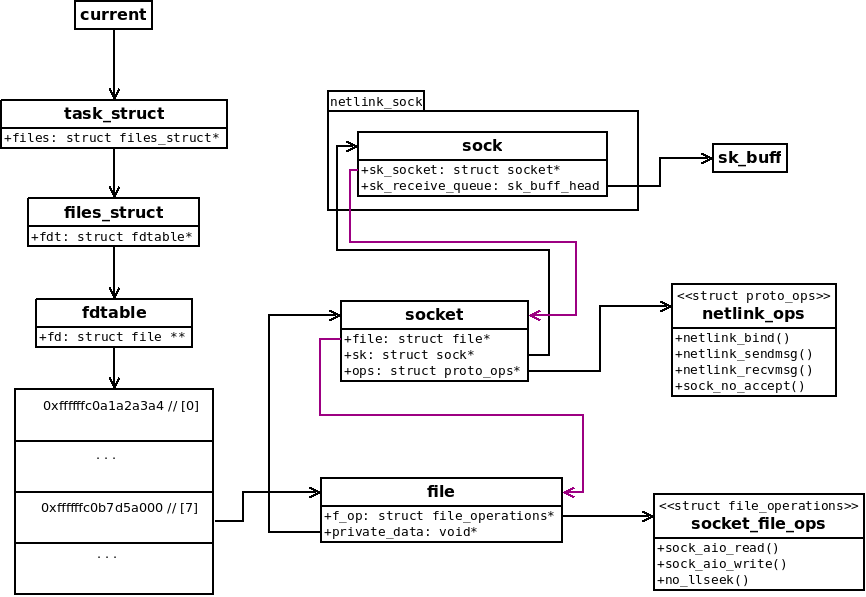
三、应用协议识别
在系统调用层面只能识别到 4 层网络协议,对于应用的 7 层协议无法识别,实际上是在 hook 系统调用拿到 buf 参数后,对 buf 的头部几个字节做协议头解析,目前支持的协议有:http、mysql、kafak、dns、mongo、pgsql、dubbo。对于 https 等加密报文可以通过 uprobe 的方式对 ssl 加密库做 hook,后续会支持这部分功能。
四、部署
我们在日常值班问题中也有碰到各种网络抖动时延问题,因此我们将此部分功能放在了 SysOM 智能诊断平台的 agent 中,可以通过容器一键部署,并在 grafana 中查看对应的时延分布及具体的时延请求信息。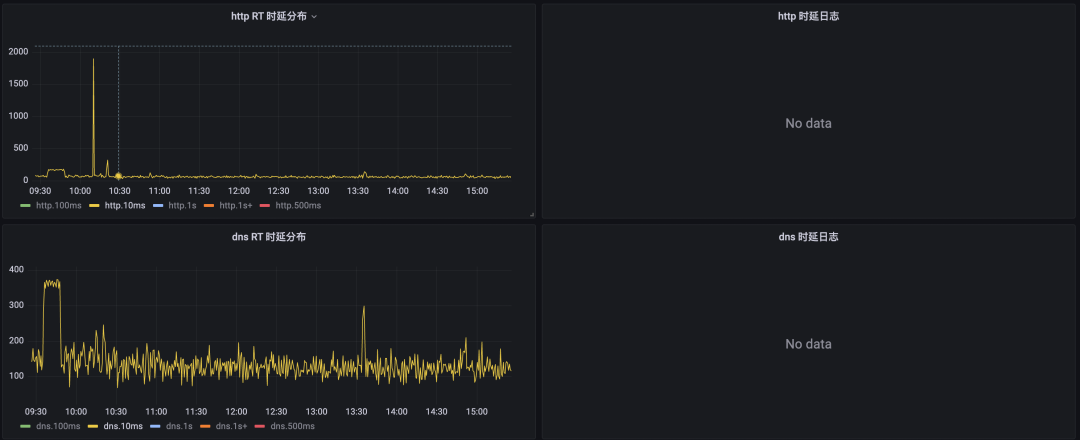
五、what's more
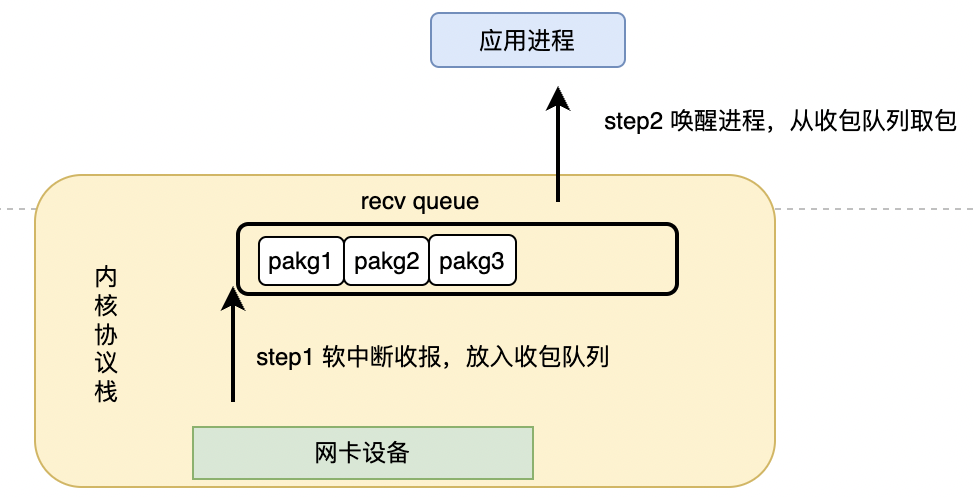
除了上文提到的基于系统调用的应用观测,对于应用由于自身原因收包缓慢造成网络“假抖动”的情况,我们基于 Coolbpf 也做了相关观测实践。一个完整的收包流程主要分为两个阶段:
阶段1:OS 通过软中断将数据包上送到应用的收包队列并通知进程后就算完成了协议栈的收包工作。
阶段2:应用得到通知后去收报队列取包。
案例1 某业务应用基于 dubbo 框架容器收到 tcp 包后延迟了将近 1s 业务层才收到
部署 SysOM agent 对“收包延迟时间”进行观测,发现"收包延迟时间"将近 1 秒,右侧红框部分为时间,单位为纳秒,结合左侧红框每次发生延迟时间都在某某时间 42 秒,怀疑跟业务某定时任务相关造成应用自身时延,最终排查到业务有某个任务会定时收集 jvm 的参数,对应用有 stop 动作,停掉该任务后消除了抖动问题。

案例2 业务高峰期,客户端 rpc 耗时比服务端多 20-30ms
业务监控如下:
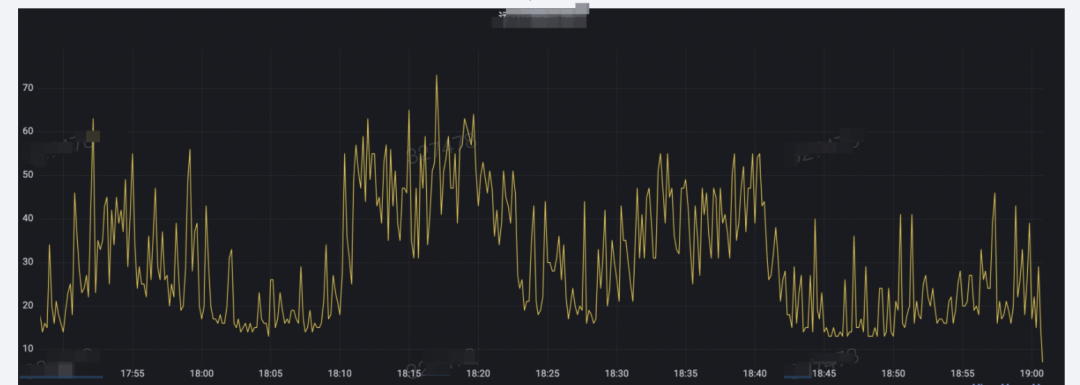
部署 SysOM agent 对“收包延迟时间”进行观测,发现对应时间段存在应用“收包延迟时间”较大,因此首先排除了网络链路问题。红框部分为时间,单位为纳秒,图中时间需要加上 8 小时。

六、总结
以上是基于 Coolbpf 在可观测性的相关实践,相关功能都集成在了 SysOM 的 agent 中,后续会引入更多对应用观测的功能。当应用日志无法解决问题或者没有日志的情况下,利用 eBPF 技术在 OS 层面对应用行为逻辑的观测,在定位某些应用的疑难问题时有着极大帮助。