Ftrace function graph原理及性能瓶颈的分析
引言
由于android开发的需要与systrace的普及,现在大家在进行性能与功耗分析时候,经常会用到systrace跟pefetto. 而systrace就是基于内核的event tracing来实现的。以如下的一段pefetto为例。可以看到tid=1845的线程,在被唤醒到CPU5上之后,在runnable状态上维持了503us才开始运行,一共运行了498us.
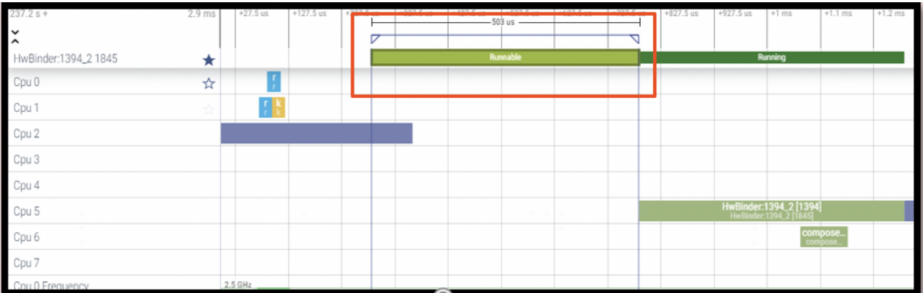
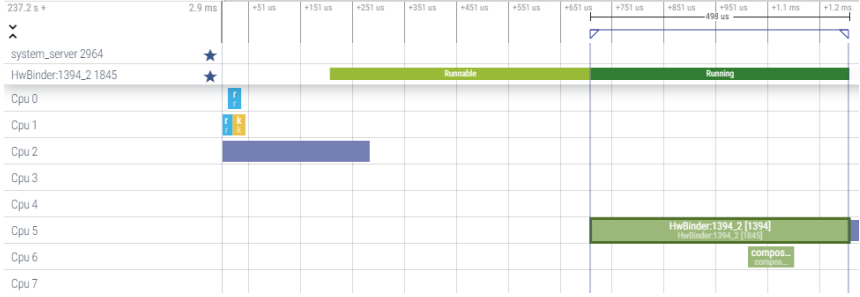
通过查找systrace里面的原始events信息,具体如下


我们可以从systrace找到相应的trace events的信息

可以看到上面systrace显示的runnable状态,其实是通过解析sched_waking及sched_switch事件来获取到的(237.160859 - 237.160356 = 0.000503),而running时间是通过2次sched_switch事件解析出来的(237.161357 - 237.160859 = 0.000498)
一、ftrace function graph是什么
除了上面提到的trace events之外,tracer提供了很多其余的功能(如下的config宏开关),本文主要介绍function graph的实现。
CONFIG_FUNCTION_TRACER=y
CONFIG_FUNCTION_GRAPH_TRACER=y
CONFIG_CONTEXT_SWITCH_TRACER=y
CONFIG_NOP_TRACER=y
#CONFIG_SHADOW_CALL_STACK is not set
通过打开上面的一些宏定义,并且关闭CONFIG_SHADOW_CALL_STACK(具体为什么要关闭这个宏,后面再讲)。我们可以看到如下的一些tracer。
/sys/kernel/tracing # cat available_tracers
blk function_graph preemptirqsoff preemptoff irqsoff function nop
通过echo xxxx > current_tracer可以动态切换tracer
/sys/kernel/tracing # cat current_tracer
nop
/sys/kernel/tracing # echo function_graph > current_tracer
/sys/kernel/tracing # cat current_tracer
function_graph
最终看到的trace信息如下图。我们可看到进程的内核函数的调用关系,并且可以看到每一个函数的执行时间(又一个性能调试神器)。
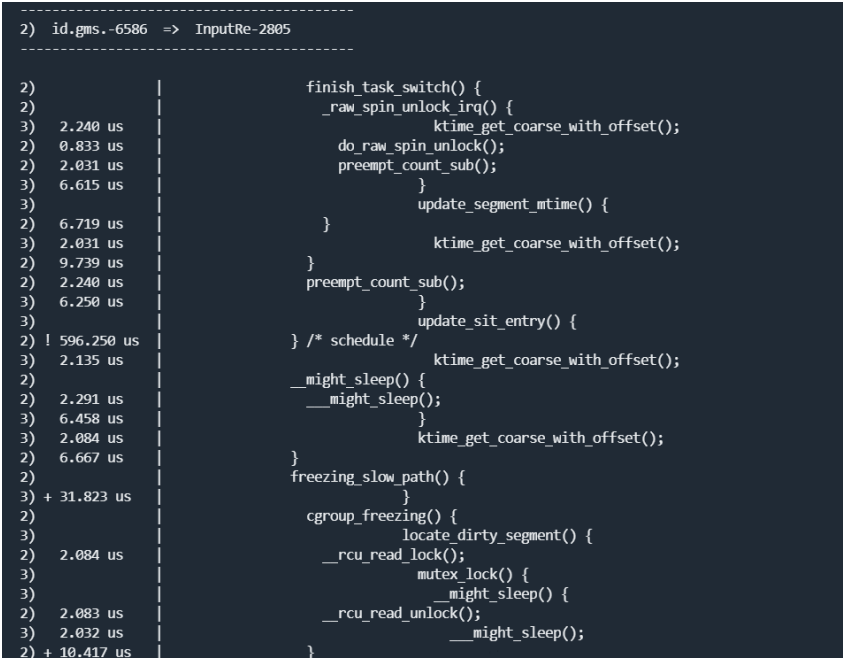
*二、打开function graph时做了什么
那么具体内核是如何实现这个功能的呢?
linux在打开ftrace的相关编译宏之后,在编译的时候加入gcc的-pg编译选项。在函数中加入_mcount函数。以cpu_up函数为例,通过反汇编内核的kernel/cpu.c文件,可以看到如下汇编代码。

可以看到在做完一系列压栈准备之后,直接跳转到了_mcount函数。这个函数定义在arch/arm64/kernel/entry-ftrace.S文件里面。最终函数调用到了ftrace_caller函数。
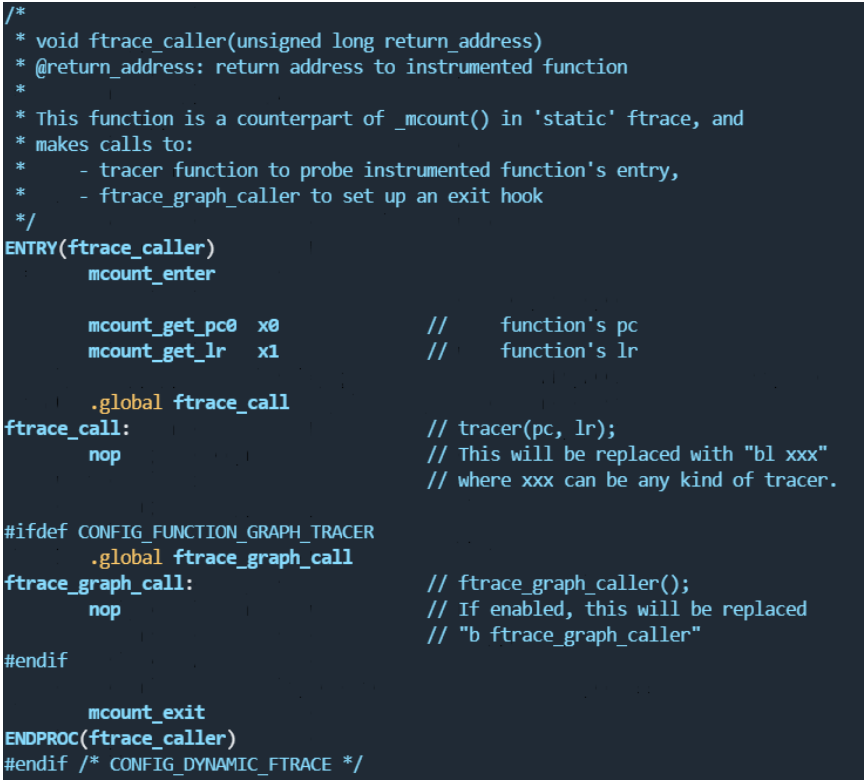
在详细进入这段汇编代码的解释之前,我们先看一下在设置current_tracer的时候具体发生了什么。通过写current_tracer节点来切换tracer的话,调到了内核的tracing_set_trace_write函数,如果是使用function_graph的话,最终调用了函数ftrace_enable_ftrace_graph_caller
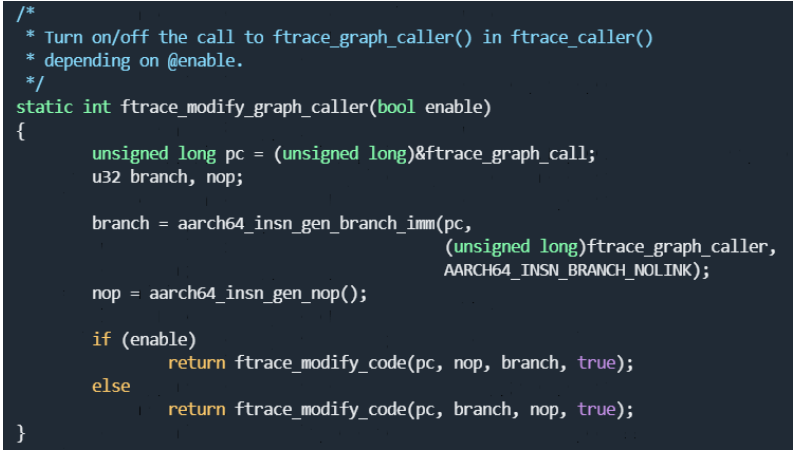
这个函数比较重要:
1 . 获取ftrace_graph_call这个函数的地址,放到pc这个变量里面
2 .通过aarch64_insn_gen_branch_imm 函数,产生一条到ftrace_graph_caller的跳转指令。
3 . 最终通过ftrace_modify_code来修改ftrace_graph_call原来所在位置的代码(步骤2中产生的跳转指令,这样可以直接跳转到ftrace_graph_caller这个函数)
所以我们可以看到,在使能ftrace function graph的时候,通过动态修改一条指令来跳转到我们想执行的函数上。在关闭的时候,通过将这条跳转指令恢复为nop指令。
三、function graph的功能实现
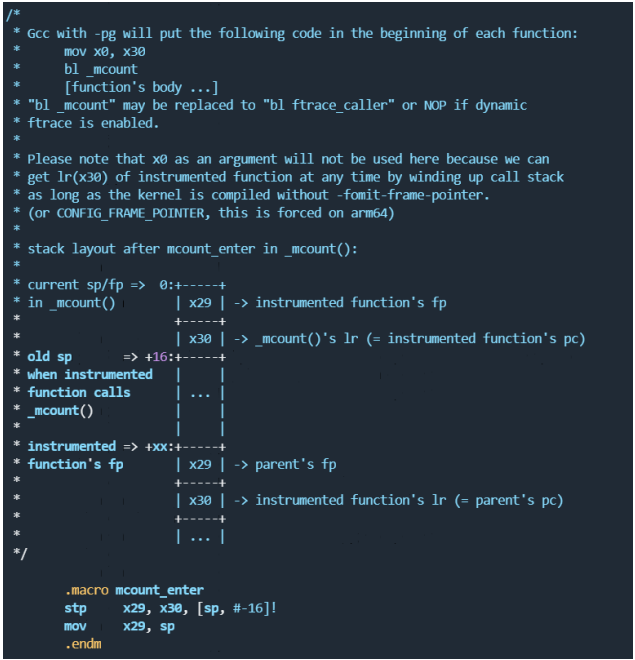
下面我们看一下_mcount函数, 第一个是mcount_enter宏。
这里面要不得不提到ARM64平台的ABI(Application Binary Interface)
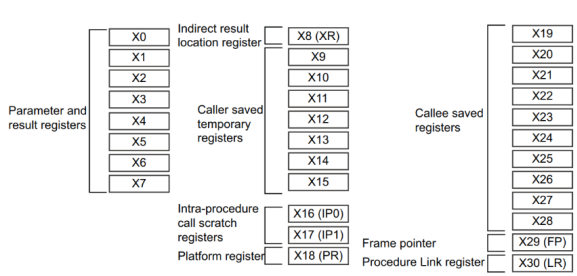
简而言之,X0~X7寄存器用来进行函数的传参,X29作为FP(frame pointer,帧指针,用来指向一段函数的栈顶,注意不是整个程序的栈顶),X30作为LR(link register)。
所以其实mcount_enter函数就是将FP及LR寄存器的值保持在栈里面。同时将当前的栈指针SP作为新函数的FP(frame pointer)。
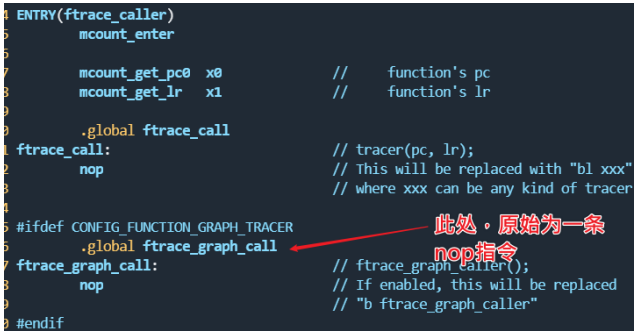
ENTRY(ftrace_caller)
mcount_enter
mcount_get_pc0 x0 // function's pc
mcount_get_lr x1 // function's lr
.global ftrace_call
ftrace_call: // tracer(pc, lr);
nop // This will be replaced with "bl xxx"
// where xxx can be any kind of tracer.
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
.global ftrace_graph_call
ftrace_graph_call: // ftrace_graph_caller();
nop // If enabled, this will be replaced
// "b ftrace_graph_caller"
#endif
mcount_exit
ENDPROC(ftrace_caller)
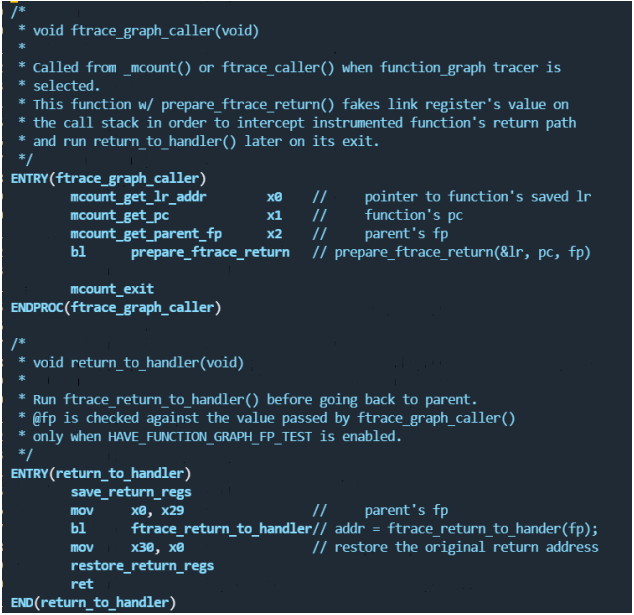
由于我们在使能function graph的时候在ftrace_enable_ftrace_graph_caller里面把ftrace_graph_call地址所在的nop指令改成了b ftrace_graph_caller(注意这里面是无返回的跳转,没有保存lr)
ENTRY(ftrace_graph_caller)
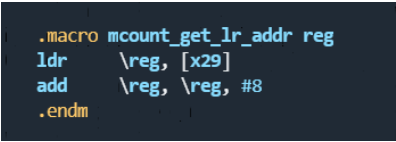
mcount_get_lr_addr x0 // pointer to function's saved lr
mcount_get_pc x1 // function's pc
mcount_get_parent_fp x2 // parent's fp
bl prepare_ftrace_return // prepare_ftrace_return(&lr, pc, fp)
mcount_exit
ENDPROC(ftrace_graph_caller)
我们前面说到了X0~X7是默认用来进行参数传递的。在跳转到prepare_ftrace_return之前,先准备一下传入参数。这里面的prepare_ftrace_return函数是C语言的,我们看一下这个函数的3个输入参数。
void prepare_ftrace_return(unsigned long *parent, unsigned long self_addr,unsigned long frame_pointer)
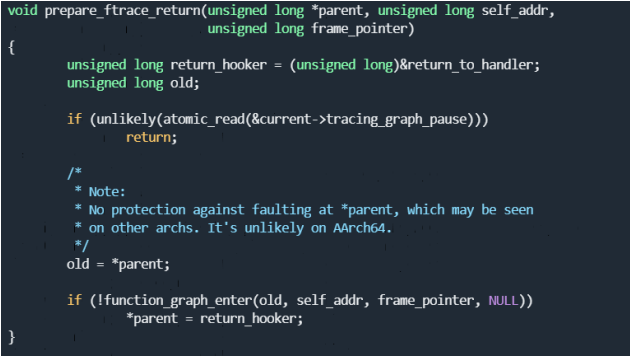
prepare_ftrace_return函数里面,除了function_graph_enter
之外,最重要的就是*parent = return_hooker.
这个代码非常重要!parent指针具体指向哪里?
我们再次回到ftrace_graph_caller函数里面准备parent参数的地方。
mcount_get_lr_addr x0 // pointer to function's saved lr
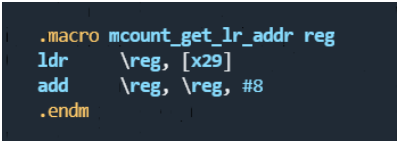
看起来有点难懂,我们再次回到mcount_enter函数。
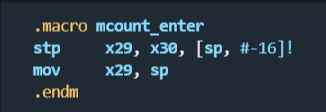
将X29(FP)与X30(LR)寄存器的内容压栈,然后当前的栈地址设置为当前函数的FP。
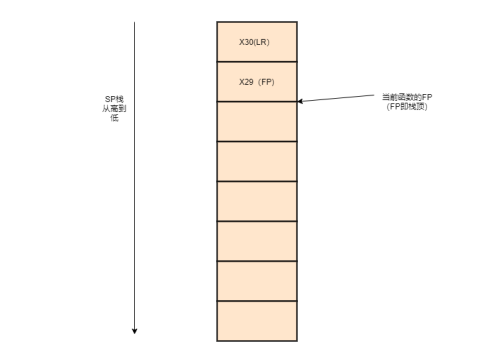
由于栈是递减的,所以这张图的上面是栈的高地址,下面是低地址部分。随着函数调用,栈从下往上递减。再回到代码
X29即FP,为当前函数的栈顶。由于栈地址是递减的,所以[X29]里面保持的内容,就是下图中的箭头指向的FP,即函数的栈顶。
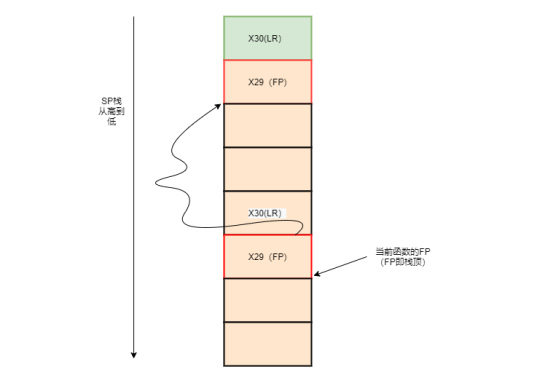
而[X29] + 8 ,就是绿框所在的地址(注意是地址,是一个指针)。
*parent = return_hooker就是将函数在栈里面保存的LR值给改成了return_hooker。
会产生什么结果呢?

依然以上面的cpu_up的汇编代码为例,首先通过压栈将LR、FP寄存器的内容保存在栈里。在函数结束时,通过ldr x29, x30, [SP], #32将栈里面的LR及FP的内容恢复到寄存器里面。然后最终直接ret指令。这样在函数调用中就实现了“从哪儿来,回哪儿去”。
但是执行了*parent = return_hooker这条代码之后,栈内的LR的内容就被改变了。
函数会返回执行return_to_handler函数。
这一段依然是汇编代码。

其中save_return_regs将X0~X7的值保持在栈里面,restore_return_regs
用于将内容重新restore到寄存器里面。
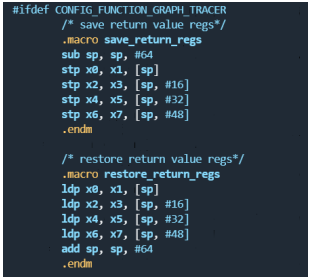
为什么要这么做呢?因为这时候函数主体已经执行完了,应该返回父函数继续往下跑。但是因为开启了function graph,这时候并没有直接返回父函数继续执行,而是在执行return_to_handler函数。这时候X0~X7里面保持了一些返回值(函数主体的执行结果,需要返回给调用的地方进行返回值的判断),而且X0~X7(见Aarch64 ABI)本身又是用来进行参数传递的,会用来给return_to_handler的一些子函数ftrace_return_to_handler进行传参。所以为了防止这些返回值被破坏,就临时保持在栈里面。
在prepare_ftrace_return里面,除了替换了函数的LR之外,还将原来的LR的值进行了保存。调用ftrace_push_return_trace函数将old的LR值(即原始的LR返回地址)保存在current->ret_stack[index].ret = ret; 里面(可以看到function graph之后,task_struct结构体里面增加了不少字段)。最终通过调用ftrace_pop_return_trace将LR的值恢复。这样回到了正常的父函数里面继续往下执行了。
四、小结
本文介绍了ftrace的function graph tracer,通过在函数的调用开始及调用结束分别调用了prepare_ftrace_return及ftrace_return_to_handler来进行LR的修改与恢复。这样可以统计到每一个函数的调用关系与具体执行时间(在开始与结束时分别记录了时间)。该功能可以帮助读者在性能调试的时候识别到性能瓶颈,以便于后期的进一步性能优化调优。
由于在执行过程中要动态的修改栈内容,所以需要关闭CONFIG_SHADOW_CALL_STACK;在比较旧的内核版本上是需要关闭CONFIG_STRICT_MEMORY_RWX和KERNEL_TEXT_RDONLY, 因为代码段是只读的,不允许动态修改。在linux内核的热补丁中也用到类似的技术。
当然有些函数用notrace进行修饰,如u64notracetrace_clock(void)。具体原因留给读者思考。通过ftrace function graph的整个代码的学习,我们可以再次梳理一下在arm64架构上函数之间的调用是如何实现的、aarch64上一些ABI的规范要求的参数传递方式与结果返回方式。
本文基于kernel-4.19的代码进行解读分析。
参考
1. https://www.kernel.org/ kernel-4.19内核代码
2. https://blog.csdn.net/u010681589/article/details/122400638 ARM V8A体系结构-第九章 ARM64平台的ABI