什么是Kafka消费组协调器
-
什么是协调器
-
协调器的作用
-
消费组协调器
-
消费者协调器
-
协调器运行流程
-
组协调器选择逻辑
-
消费者加入组流程JoinGroup
-
组协调器同步流程SyncGroup
-
消费者离组流程LeaveGroup
-
心跳检测
-
分区分配策略
-
Q&A
什么是协调器
协调器是用于协调多个消费者之间能够正确的工作的一个角色, 比如计算消费的分区分配策略,又或者消费者的加入组与离开组的处理逻辑, 有一点类似Kafka种的控制器的角色。
协调器的作用
协调器分为 消费组协调器 和 消费者协调器两种
消费组协调器
组协调器(GroupCoordinator)可以理解为各个消费者协调器的一个中央处理器, 每个消费者的所有交互都是和组协调器(GroupCoordinator)进行的。
- 选举Leader消费者客户端
- 处理申请加入组的客户端
- 再平衡后同步新的分配方案
- 维护与客户端的心跳检测
- 管理消费者已消费偏移量,并存储至
__consumer_offset中
消费者协调器
每个客户端都会有一个消费者协调器, 他的主要作用就是向组协调器发起请求做交互, 以及处理回调逻辑
- 向组协调器发起入组请求
- 向组协调器发起同步组请求(如果是Leader客户端,则还会计算分配策略数据放到入参传入)
- 发起离组请求
- 保持跟组协调器的心跳线程
- 向组协调器发送提交已消费偏移量的请求
协调器运行流程
组协调器选择逻辑
消费组协调器的选择
kafka上的组协调器(GroupCoordinator)协调器有很多, 跟Controller不一样的是, Controller只有一个, 而组协调器(GroupCoordinator)是根据内部Topic __consumer_offset数量决定的,有多少个 __consumer_offset分区, 那么就有多少个组协调器(GroupCoordinator)。
但是每个分区可能有多个副本, 那么每个组协调器应该分配在哪里呢?
每个__consumer_offset分区的Leader副本在哪个Broer上, 那么对应协调器就在哪里。
详细请看:寻找协调器FindCoordinatorRequest请求流程
如何确定每个消费组对应哪个协调器
默认情况下, __consumer_offset有50个分区, 每个消费组都会对应其中的一个分区,对应的逻辑为 hash(group.id)%分区数;
消费者加入组流程JoinGroup
客户端启动的时候, 或者重连的时候会发起JoinGroup的请求来申请加入的组中。
JoinGroup时序图
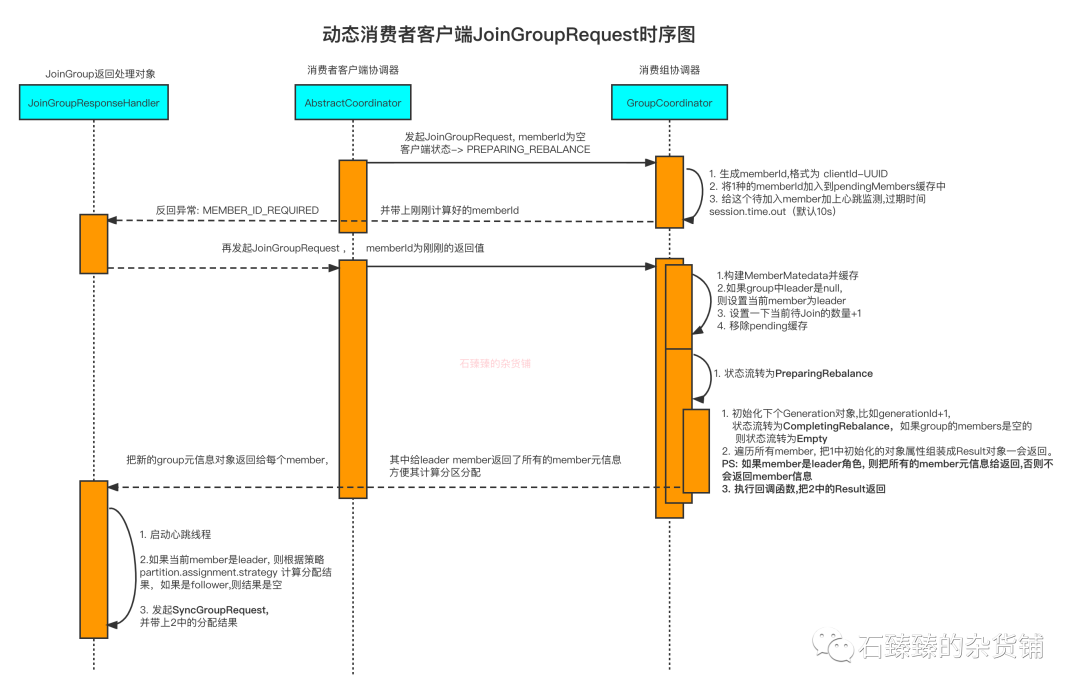
- 消费者客户端发起第一次请求, 协调器给它计算一个MemberId返回
- 消费者客户端发起第二次请求,MemberId是刚刚得到的。
- 消费组协调器处理请求,构建新的MemberMetadata元信息缓存到Group中。
- 消费组协调器将状态流转为 PreparingRebalance
- 初始化Generation数据,比如generationId+1, Group状态流转为 CompletingRebalance,当然如果当前Group的member是空的,则流转为 Empty ;
- 将上面的数据组装一下为JoinGroupResult,返回给所有的Member, 当然如果是Leader Member的话, 还会额外给他所有Member的元信息(因为它要用这些数据去计算新的分区分配的数据。)
- 消费者客户端拿到数据之后, 像消费组协调器发起SyncGroupRequest的请求, 如果是Leader Member的话, 则会根据分区策略去计算一下新的分配策略,并把数据带上发起SyncGroupRequest的请求。关于SyncGroupRequest请看: Kafka消费者 SyncGroupRequest 流程解析
详情请看:Kafka消费者JoinGroupRequest流程解析
组协调器同步流程SyncGroup
当前客户端都已经完成JoinGroup之后, 客户端会收到JoinGroup的回调, 然后客户端会再次向组协调器发起SyncGroup的请求来获取新的分配方案。
但是在这一个过程中,新的分配方案是由Leader 客户端计算出来的,并且会同步给组协调器。
然后组协调器再把这些结果回调给众多客户端。
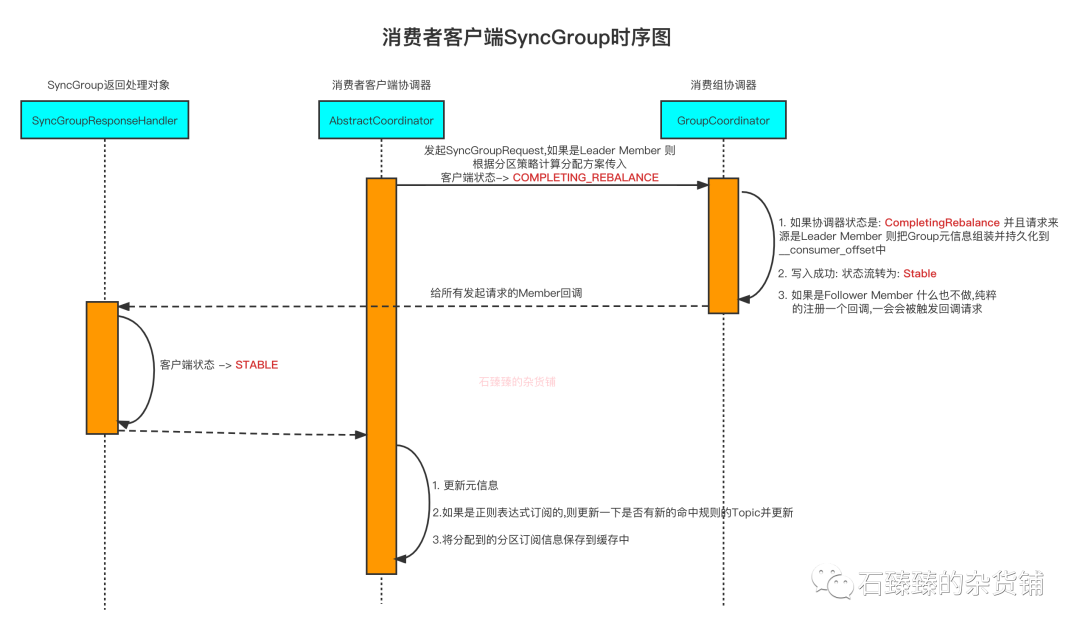
详情请看 :图解KafkaConsumer SyncGroupRequest请求流程
消费者离组流程LeaveGroup
当消费者客户端关机/异常 时, 会触发离组LeaveGroup请求。
组协调器一直会有针对每个客户端的心跳检测, 如果监测失败,则就会将这个客户端踢出Group、
这个提出的流程也很简单
就是触发一下 再平衡。
心跳检测
客户端加入组内后, 会一直保持一个心跳线程,来保持跟组协调器的一个感知。
并且组协调器会针对每个加入组的客户端做一个心跳监测,如果监测到过期, 则会将其踢出组内并再平衡。
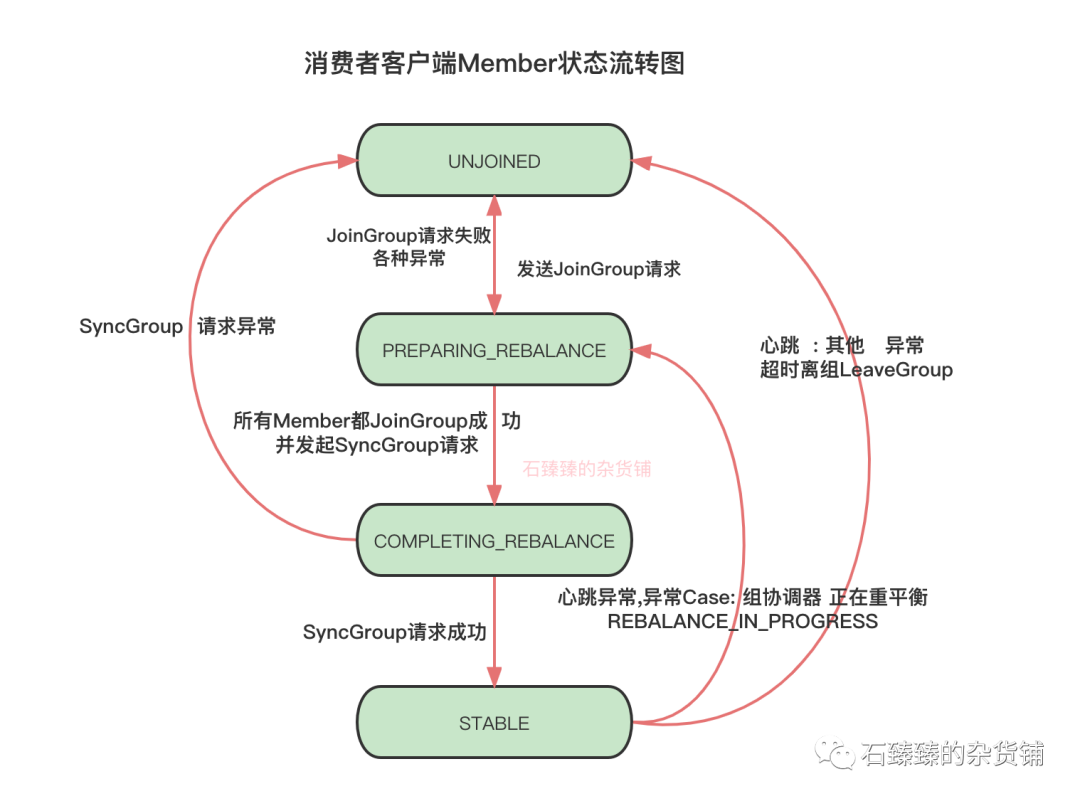
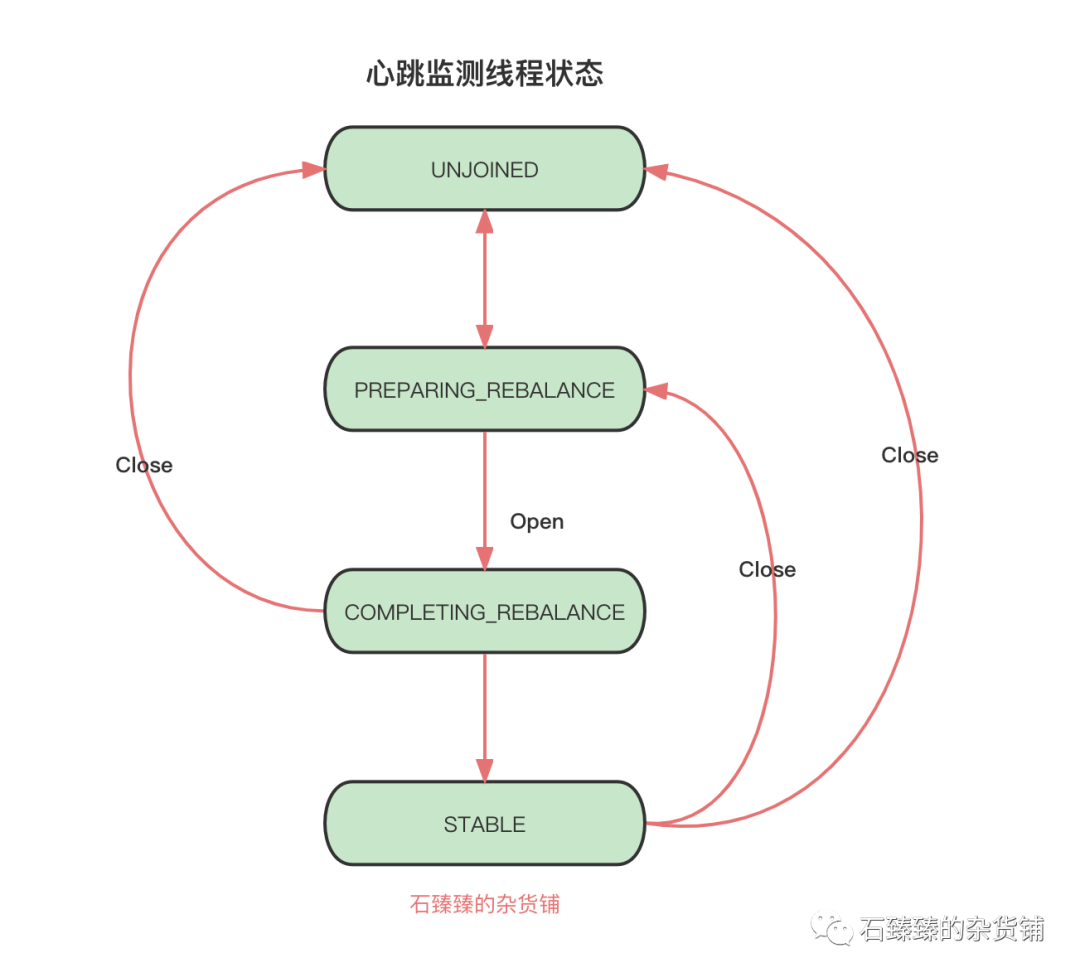
Kafka消费者客户端心跳请求
分区分配策略
Q&A
1. 如果有多个客户端配置了不同的分配策略, 那么会以哪个配置生效呢?
肯定是需要消费组下面的所有成员都使用同一种分配策略来进行分配。所以GroupCoordinator就面临着选择哪个分配策略。
选择的逻辑如下
- 选择所有Member都支持的分配策略
- 在1的基础上,优先选择每个
partition.assignment.strategy配置靠前的策略。
请看下面的2个例子
| case | consumer-0 | consumer-1 | consumer-2 | 选中策略 |
|---|---|---|---|---|
| case-1 | roundrobin,rang | rang,roundrobin,strick | roundrobin,rang | roundrobin |
| case-2 | strick,roundrobin,rang | rang,roundrobin | strick ,rang | rang |
Case-1
- 所有支持的分配策略为:roundrobin,rang
- 每个consumer都在1的基础上,给自己排最前面的投票, consumer-0投roundrobin, consumer-1投rang, consumer-3投roundrobin;这样算下来 roundrobin是有2票的, 那么久选择roundrobin为分配策略;
Case-2
- 所有支持的分配策略为:rang
- 都不用投票, 直接选择rang当选
如果新Member加入Group的时候, 带上的分配策略跟现有Group中所有Member(Group有Member的情况下)都支持的协议都不交叉
那么就会抛出异常:INCONSISTENT_GROUP_PROTOCOL
[2022-09-08 14:34:12,508] INFO [Consumer clientId=client2, groupId=consumer0] Rebalance failed. (org.apache.kafka.clients.consumer.internals.AbstractCoordinator)
org.apache.kafka.common.errors.InconsistentGroupProtocolException: The group member's supported protocols are incompatible with those of existing members or first group member tried to join with empty protocol type or empty protocol list.
[2022-09-08 14:34:12,511] ERROR Error processing message, terminating consumer process: (kafka.tools.ConsoleConsumer$)
2. 消费者消费并提交了之后, 其他消费者是如果知道我已经消费了,从而不会重新消费的呢?
一个分区只会被同一个消费组内的消费者就行消费, 当消费者消费了之后会把消费的偏移量offset提交给组协调器进行存储。
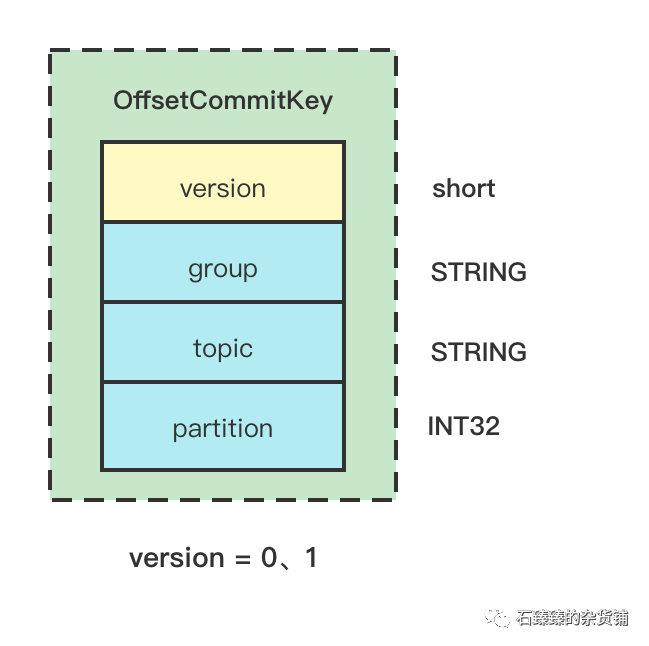
存储地方是 kafka的内部Topic __consumer_offset, 存储的数据结构是如下:
Key:
Value:
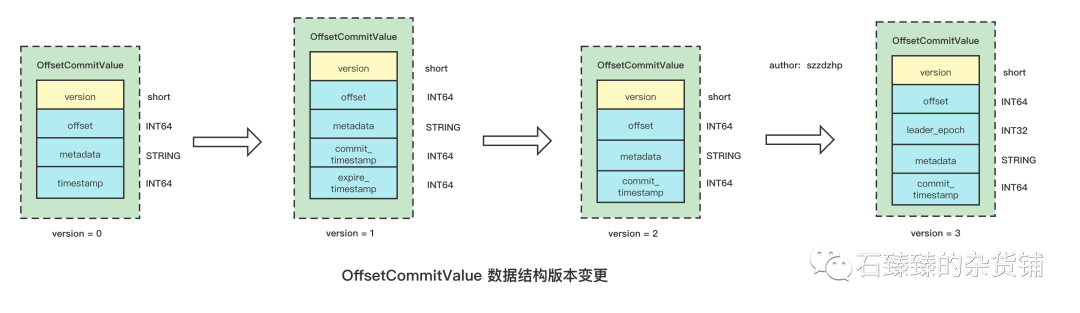
可以看到Key的结构是 group+topic+partition,当发生再平衡的时候,就算该分区分配给了别的消费者的话,它也是通过这个key来寻找当前已经消费到的offset了。
简单来说就是:
- 同一个消费组下,一个分区只会被一个消费者消费
- 消息被消费之后 会存储到内部Topic
__consumer_offset中, 并且过期策略是 compact(紧缩) - 存储offset的时候,key的结构是 group+topic+partition,所以就算重平衡后, 相同组内不同的消费者它去读取到的offset是上一个消费者提交之后的。
3. 消费者消费的offset存储结构是什么样子的呢?
存储结构请看:图解Kafka消费组偏移量_consumer_offset的数据结构
4. 了解到offset存储结构,如果让你去重置offset,你觉得应该如果操作呢?
既然消费者消费过的偏移量offset是存储在内部Topic __consumer_offset中, 消费者消费的时候先去读取这个Topic的最新值,key的结构是 group+topic+partition;
如果我们想要修改offset,只需要改变这个值的数据大小就行了。
又因为它的过期策略是 compact(紧缩), 那么我们只需要这个Topic __consumer_offset 的指定key( group+topic+partition)发送一个新的offset值就行了。
如果想要重置offset, 给这个topic发送一个墓碑消息让它消息就行。
5. 如果 __consumer_offset扩容的话,offset记录会丢失吗?