“分库分表" ?选型和流程要慎重,否则会失控
恭喜你,贵公司终于成长到一定规模,需要考虑高可用,甚至分库分表了。但你是否知道分库分表需要哪些要素?拆分过程是复杂的,提前计划,不要等真正开工,各种意外的工作接踵而至,以至失控。
本文意图打开数据库中间件的广度,而不考虑实现深度,至于库表垂直和水平分的概念和缘由,不做过多解释。所以此文面向的是有一定研发经验,正在寻找选型和拆分流程的专业人士。
切入层次
以下,范围界定在JAVA和MySQL中。我们首先来看一下分库分表切入的层次。
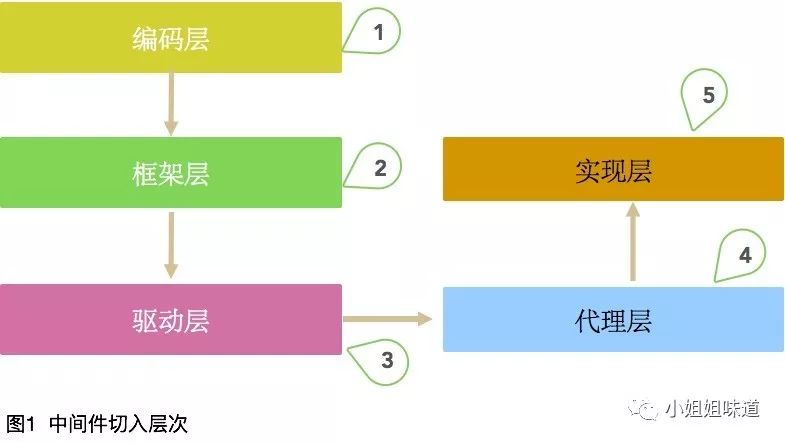
① 编码层
在同一个项目中创建多个数据源,采用if``else的方式,直接根据条件在代码中路由。Spring中有动态切换数据源的抽象类,具体参见
AbstractRoutingDataSource。
如果项目不是很庞大,使用这种方式能够快速的进行分库。但缺点也是显而易见的,需要编写大量的代码,照顾到每个分支。当涉及跨库查询、聚合,需要循环计算结果并合并的场景,工作量巨大。
如果项目裂变,此类代码大多不能共用,大多通过拷贝共享。长此以往,码将不码。
② 框架层
这种情况适合公司ORM框架统一的情况,但在很多情况下不太现实。主要是修改或增强现有ORM框架的功能,在SQL中增加一些自定义原语或者hint来实现。
通过实现一些拦截器(比如Mybatis的Interceptor接口),增加一些自定义解析来控制数据的流向,效果虽然较好,但会改变一些现有的编程经验。
很多情况要修改框架源码,不推荐。
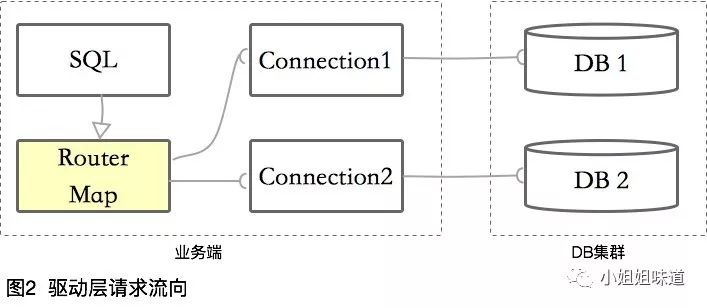
③ 驱动层
基于在编码层和框架层切入的各种缺点,真正的数据库中间件起码要从驱动层开始。什么意思呢?其实就是重新编写了一个JDBC的驱动,在内存中维护一个路由列表,然后将请求转发到真正的数据库连接中。
像TDDL、ShardingJDBC等,都是在此层切入。
包括Mysql Connector/J的Failover协议 (具体指“load balancing”、“replication”、“farbic”等),
也是直接在驱动上进行修改。
请求流向一般是这样的:
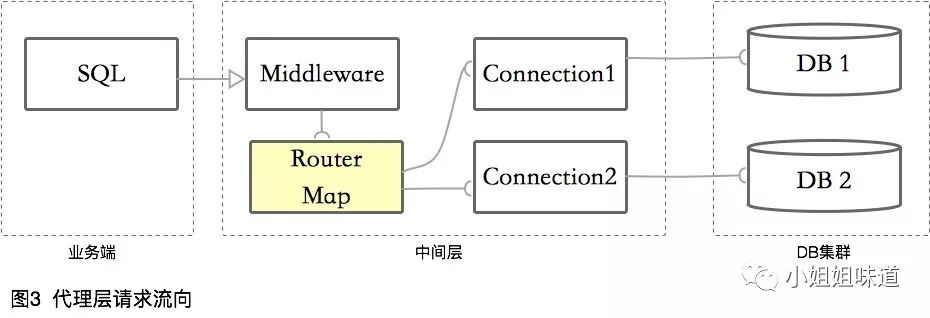
④ 代理层
代理层的数据库中间件,将自己伪装成一个数据库,接受业务端的链接。然后负载业务端的请求,解析或者转发到真正的数据库中。
像MySQL Router、MyCat等,都是在此层切入。
请求流向一般是这样的:
⑤ 实现层
SQL特殊版本支持,如Mysql cluster本身就支持各种特性,mariadb galera cluster支持对等双主,Greenplum支持分片等。
需要换存储,一般是解决方案,就不在讨论之列了。
技术最终都会趋于一致,选择任何一种、都是可行的。但最终选型,受开发人员熟悉度、社区活跃度、公司切合度、官方维护度、扩展性,以及公司现有的数据库产品等多方位因素影响。选择或开发一款合适的,小伙伴们会幸福很多。
驱动层和代理层对比
通过以上层次描述,很明显,我们选择或开发中间件,就集中在驱动层和代理层。在这两层,能够对数据库连接和路由进行更强的控制和更细致的管理。但它们的区别也是明显的。
驱动层特点
仅支持JAVA,支持丰富的DB
驱动层中间件仅支持Java一种开发语言,但支持所有后端关系型数据库。如果你的开发语言固定,后端数据源类型丰富,推荐使用此方案。

占用较多的数据库连接
驱动层中间件要维护很多数据库连接。比如一个分了10个 库 的表,每个java中的Connection要维护10个数据库连接。如果项目过多,则会出现连接爆炸(我们算一下,如果每个项目6个实例,连接池中minIdle等于5,3个项目的连接总数是 10*6*5*3 = 900 个)。像Postgres这种每个连接对应一个进程的数据库,压力会很大。
数据聚合在业务实例执行
数据聚合,比如count``sum等,是通过多次查询,然后在业务实例的内存中进行聚合。
路由表存在于业务方实例内存中,通过轮询或者被动通知的途径更新路由表即可。
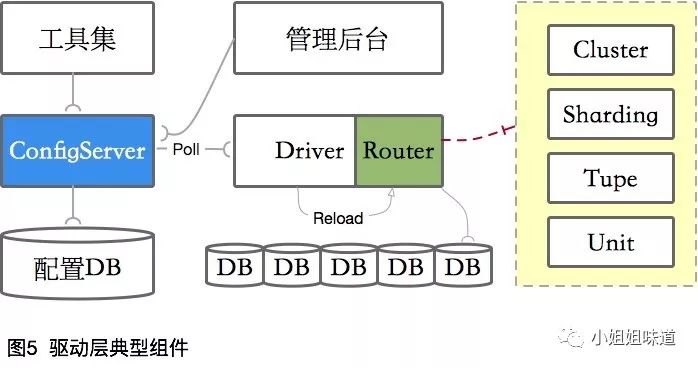
集中式管理
所有集群的配置管理都集中在一个地方,运维负担小,DBA即可完成相关操作。
典型实现
代理层特点
异构支持,DB支持有限
代理层中间件正好相反。仅支持一种后端关系型数据库,但支持多种开发语言。如果你的系统是异构的,并且都有同样的SLA要求,则推荐使用此方案。
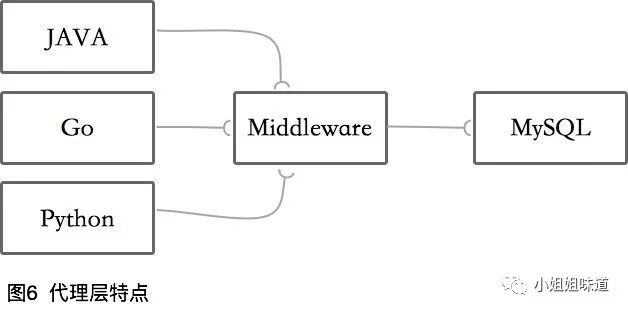
运维负担大
代理层需要维护数据库连接数量有限(MySQL Router那种粘性连接除外)。但作为一个独立的服务,既要考虑单独部署,又要考虑高可用,会增加很多额外节点,更别提用了影子节点的公司了。
另外,代理层是请求唯一的入口,稳定性要求极高,一旦有高耗内存的聚合查询把节点搞崩溃了,都是灾难性的事故。
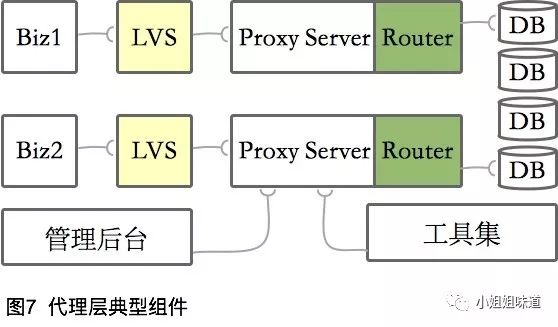
典型实现
共同点
篇幅有限,不做过多讨论。访问各中间件宣传页面,能够看到长长的Feature列表,也就是白名单;也能看到长长的限制列表,也就是黑名单。限定了你怎么玩,在增强了分布式能力后,分库分表本身就是一个阉割的数据库。
使用限制
确保数据均衡 拆分数据库的数据尽量均匀,比如按省份分user库不均匀,按userid取模会比较均匀 不用深分页 不带切分键的深分页,会取出所有库所取页数之前的所有数据在内存排序计算。容易造成内存溢出。 减少子查询 子查询会造成SQL解析紊乱,解析错误的情况,尽量减少SQL的子查询。 事务最小原则 尽量缩小单机事务涉及的库范围,即尽可能减少夸库操作,将同类操作的库/表分在一起 数据均衡原则 拆分数据库的数据尽量均匀,比如按省份分user库不均匀,按userid取模会比较均匀 特殊函数 distinct、having、union、in、or等,一般不被支持。或者被支持,使用之后会增加风险,需要改造。
产品
建议聚焦在MyCat和ShardingJDBC上。另外,还有大量其他的中间件,不熟悉建议不要妄动。
数据库中间件不好维护,你会发现大量半死不活的项目。
以下列表,排名不分先后,有几个是只有HA功能,没有拆分功能的:
Atlas、Kingshard、DBProxy、mysql router、MaxScale、58 Oceanus、ArkProxy、Ctrip DAL、Tsharding、Youtube vitess、网易DDB、Heisenberg、proxysql、Mango、DDAL、Datahekr、MTAtlas、MTDDL、Zebra、Cobar、Cobar
汗、几乎每个大厂都有自己的数据库中间件(还发现了几个喜欢拿开源组件加公司前缀作为产品的),只不过不给咱用罢了。
流程解决方案
无论是采用哪个层面切入进行分库分表,都面临以下工作过程。
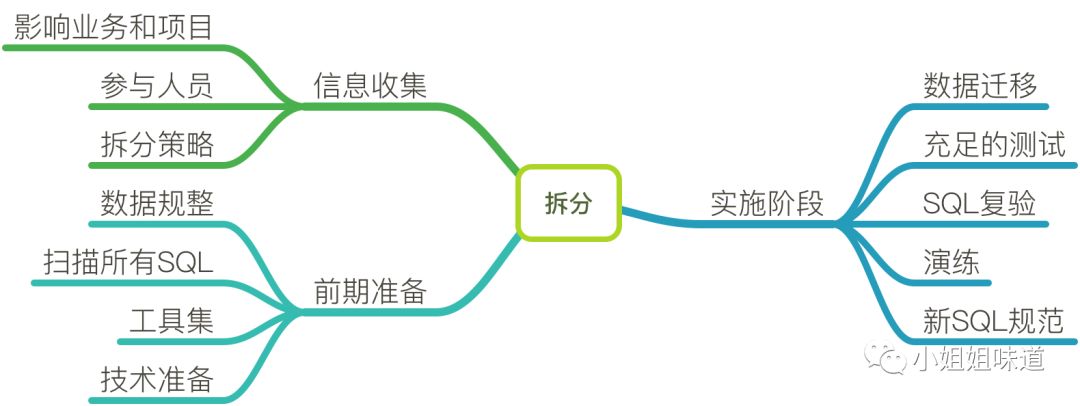
信息收集
统计影响的业务和项目
项目范围越大,分库难度越高。有时候,一句复杂的SQL能够涉及四五个业务方,这种SQL都是需要重点关注的。
确定分库分表的规模,是只分其中的几张表,还是全部涉及。分的越多,工作量越大,几乎是线性的。
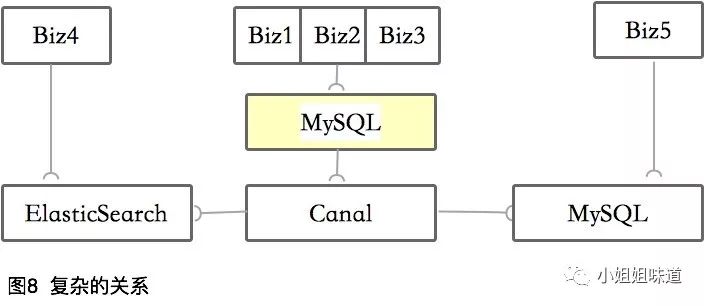
还有一些项目是牵一发动全身的。举个例子,下面这个过程,影响的链路就不仅是分库这么简单了。
确定参与人员
除了分库分表组件的技术支持人员,最应该参与的是对系统、对现有代码最熟悉的几个人。只有他们能够确定哪些SQL该废弃掉、SQL的影响面等。
确定分库分表策略
确定分库分表的维度和切分键。切分键(就是路由数据的column)一旦确定,是不允许修改的,所以在前期架构设计上,应该首先将其确立下来,才能进行后续的工作;数据维度多意味着有不同的切分键,达到不同条件查询的效果。这涉及到数据的冗余(多写、数据同步),会更加复杂。
前期准备
数据规整
库表结构不满足需求,需要提前规整。比如,切分键的字段名称不同或者类型各异。在实施分库分表策略时,这些个性会造成策略过大不好维护。
扫描所有SQL
将项目中所有的SQL扫描出来,逐个判断是否能够按照切分键正常运行。 在判断过程中肯定会有大量不合规的SQL,则都需要给出改造方案,这是主要的工作量之一。
验证工具支持
直接在原有项目上进行改动和验证是可行的,但会遇到诸多问题,主要是效率太低。我倾向于首先设计一些验证工具,输入要验证的SQL或者列表,然后打印路由信息和结果进行判断。
技术准备
建议以下提到的各个点,都找一个例子体验一下,然后根据自己的团队预估难度。
以下: 中间件所有不支持的SQL类型 整理容易造成崩溃的注意事项 不支持的SQL给出处理方式 考虑一个通用的主键生成器 考虑没有切分键的SQL如何处理 考虑定时任务等扫全库的如何进行遍历 考虑跨库跨表查询如何改造 准备一些工具集
实施阶段
数据迁移
分库分表会重新影响数据的分布,无论是全量还是增量,都会涉及到数据迁移,所以Databus是必要的。
一种理想的状态是所有的增删改都是消息,可以通过订阅MQ进行双写。
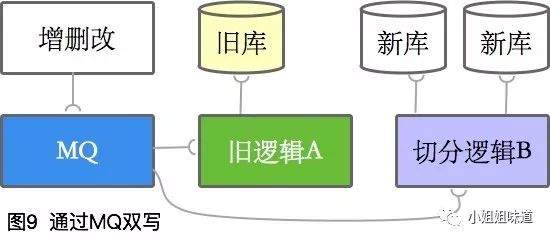
但一般情况下,仍然需要去模拟这个状态,比如使用Canal组件。
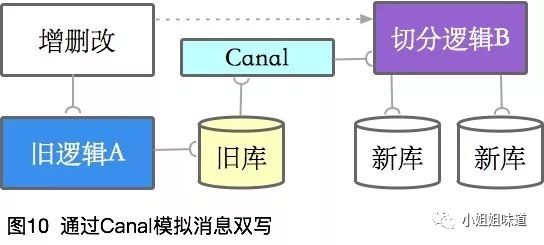
怎么保证数据安全的切换,我们分其他章节进行讨论。
充足的测试
分库分表必须经过充足的测试,每一句SQL都要经过严格的验证。如果有单元测试或者自动化测试工具,完全的覆盖是必要的。一旦有数据进行了错误的路由,尤其是增删改,将会创造大量的麻烦。
在测试阶段,将验证过程输出到单独的日志文件,充足测试后review日志文件是否有错误的数据流向。
SQL复验
强烈建议统一进行一次SQL复验。主要是根据功能描述,确定SQL的正确性,也就是通常说的review。
演练
在非线上环境多次对方案进行演练,确保万无一失。
制定新的SQL规范
分库分表以后,项目中的SQL就加了枷锁,不能够随意书写了。很多平常支持的操作,在拆分环境下就可能运行不了了。所以在上线前,涉及的SQL都应该有一个确认过程,即使已经经过了充足的测试。
题外话
没有支持的活别接,干不成。
分库分表是战略性的技术方案,很多情况无法回退或者回退方案复杂。如果要拆分的库表涉及多个业务方,公司技术人员复杂,CTO要亲自挂帅进行协调,并有专业仔细的架构师进行监督。没有授权的协调人员会陷入尴尬的境地,导致流程失控项目难产。
真正经历过的人,会知道它的痛!