记一次CLOSE_WAIT引发的血案
背景导入
我们线上有一个服务,姑且称之为A服务,它会请求其他部门的B服务获取必要的数据,因此不容有失。但因为跨部门,两个团队的技术栈不同,使用的RPC框架也不同,通信协议的格式也不同,且不是通用协议。因此对方提供了一个SDK,让我们作为调用B服务的client集成到A服务中。该SDK除了协议的序列化和反序列化的功能外,也包含寻址以及负载均衡的逻辑。
这个SDK并不在他们内部使用,而是专门提供给其他部门(比如我们)使用的。因为他们内部使用的client使用了大量内部库,过多的编译依赖只会导致和其他部门的代码难以集成。所以这个SDK几乎没有使用额外的库,几乎就是epoll、send、write等系统调用裸写的。
下面讲一下A服务的网络模型。
A服务所使用到RPC框架(内部框架,非brpc)支持多种网络模型,可以通过配置指定。但由于B服务SDK和该RPC框架的兼容性问题,只能使用半同步半异步(准确说是半同步半反应堆)的网络模型。关于这个网络模型可以阅读我之前写过的文章:[《高山仰之可极,谈半同步/半异步网络并发模型》]
简单理解的话,就是一个请求落到一个工作线程中处理的古早且经典的网络模型。所以A服务的同时并发数就是工作线程的数量,当前是360个。A服务中将请求处理逻辑封装到了名为Worker的类中,在启动时它会初始化360个Worker对象。每次处理请求时,工作线程会调用自己的Worker对象来处理。
Worker类中有一个DataApi类型的成员变量,DataApi是B服务SDK中封装的请求B服务的client类。DataApi中有一个名为connect_map的map类型成员。在需要请求B服务时,通过B服务所用名字服务的API获取到推荐的某个B服务实例的IP:PORT,如果connect_map已经有该IP,则从中获取到具体的连接对象。如果获取不到,则DataApi会与该IP:PORT建立连接,并把连接存储在map中,避免下次重复创建连接。另外在连接对象的后续使用过程中也有一些连接检测和重连的逻辑,不再一一赘述。
所以久而久之,一个Worker对象最终会和B服务的每一台机器都建立一个连接。由于Worker有360个,所以一个A服务的实例最终会和B服务的每一个实例有360个连接。如果B服务有N个实例,那么一台A服务和B服务之间就有360*N个连接。以上都是一些背景,下面开始切入正题。
问题乍现
我从4月份开始负责A服务,当月出现了一次“B服务通信返回值异常上升”的报警。直接表现就是SDK在向B服务发送请求时,出现大量错误。导致线上请求的空结果比例升高。而B服务根本没收到这些异常请求。据之前负责A服务的同事说之前也偶有出现这个问题,通过重启可以解决。因此这次也是通过重启解决的。后面一个月相安无事。
5月20日周五这天晚上(没错,这天不仅是周五,还是五二零!)又出现一次。这次最终也是通过重启解决。紧接着5月29日(是周六,当时正在外购物!)这个问题又出现一次,此后该问题开始变得频繁。平均每周都要出现一到两次。每次都是通过重启解决。有时候发重启单恢复还是太慢,因为重启单也是带间隔的分批次重启,并且非工作时间还不能发单。所以对我来说有一个坏消息和一个好消息:坏消息是大多数时候都需要自己登录机器执行重启命令。好消息是A服务的实例数量并不多,只有十几个。
之所以并没有深入排查这个问题,首先因为A服务此前都比较稳定,近期并没有修改通信相关逻辑。每次事发时,B服务收不到请求,所以是client端的异常,即SDK内部的问题,由于SDK的代码是对方提供的,所以排查修复也应该对方来做。但是对方同学反馈说,在我来之前SDK已经稳定运行近3年了,不应该是SDK的问题。一时之间陷入僵持。由于平时业务需求比较多,并且我是新接手的业务,还有很多需要学习的东西,精力并不充裕。所以就也没有花精力仔细排查这个问题。
排查分析
6月22日,对方同学反馈可能是它们服务开了HPA(自动扩缩容)导致的。然后他们进行了关闭HPA。
但问题并没有得到解决。7月9日 、7月15日、7月18日 又出现异常报警。彼时,因为种种原因,这个问题被提上了优先级,于是我从7月18日开始深入排查这个问题。抛开一些非本质问题的排查过程不谈,下面直入主题。
蛛丝马迹
通过内部监控网站逐个查看监控视图,我突然在单机的网卡监控图上,发现了端倪。下面是A服务某实例的曲线:TCP连接数变化趋势是和流量的变化趋势相符,但socket数却总是持续上涨,从没减少过!
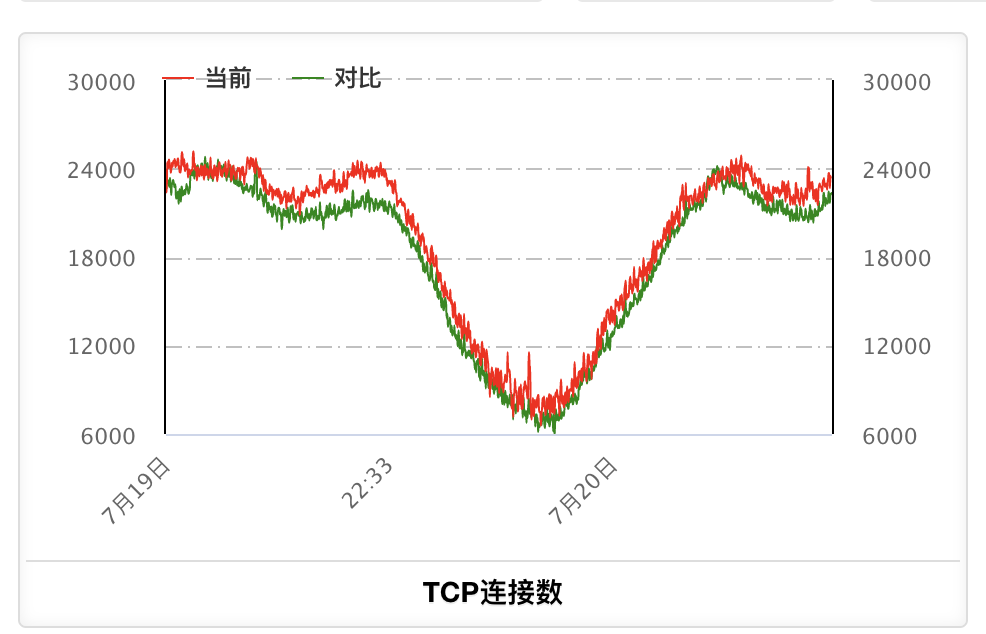
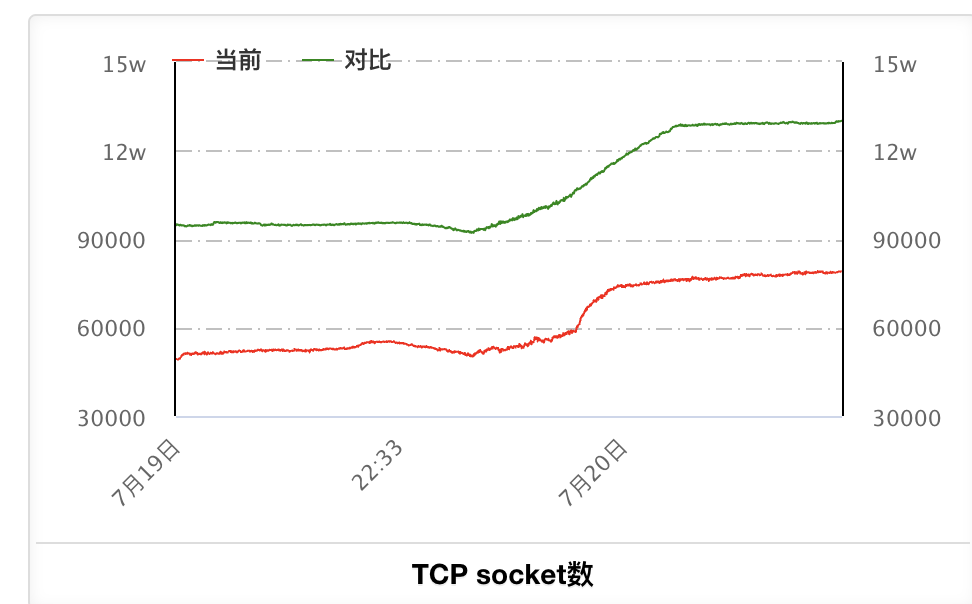
这意味着,可能有大量没有关闭的连接。由于TIME_WAIT的连接经过2MSL的时间(一般是2分钟)就会自动关闭。所以怀疑是有CLOSE_WAIT的连接。
抽丝剥茧
这里先讲解一下CLOSE_WAIT,可能平时大家听说TIME_WAIT比较多,但TIME_WAIT并不是很严重的一个事情,CLOSE_WAIT才是。你可以阅读我之前的文章:[《实践解读CLOSE_WAIT和TIME_WAIT》]
对于TCP连接状态的问题,遇事不决祭此图:
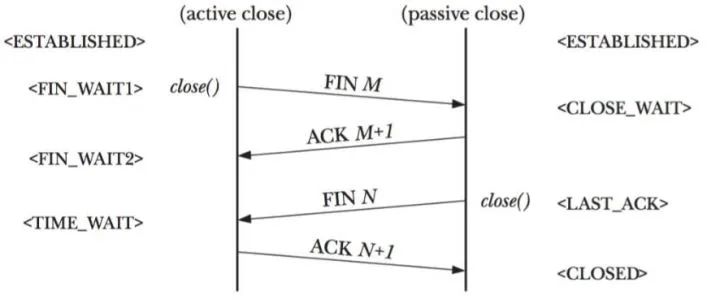
CLOSE_WAIT都是出现在被动关闭的一方,即对端主动关闭了连接,发送了FIN。被动关闭的一方(我们的A服务进程上的TCP连接)在收到FIN之后,连接状态会迁移到CLOSE_WAIT,并发送ACK给对端。接着被动关闭的这方要调用close()去关闭socket,然后连接状态迁移到LAST_ACK,很快变成CLOSED状态。至此连接真正完全消失,socket也释放。
所谓CLOSE_WAIT顾名思义,就是在等待close的函数,而如果被动关闭的一方没有调用close(),那么这个状态则会持续。持续的结果一方面是会占用client端的端口号,也会占用客户端socket(fd)。等到达某一阈值的时候,就会无法建立新的连接。那么CLOSE_WAIT有超时时间吗?可以说有也可以说没有,这个在最后一节会解释。
登录到A服务某实例寻找点蛛丝马迹,虽然排查的时候,服务都已经重启过,没有了事故现场。但由于监控显示socket数是不停上涨的,所以应该也能辅助分析问题。
使用ss命令来查看一下有没有CLOSE_WAIT的连接。B服务的端口号固定,不同实例仅IP不同,所以可以通过grep B的端口号来找到本机与B服务各实例的所有连接。下面命令中的 $PORT 表示的是B服务的端口号。
ss -tna|grep $PORT|grep CLOSE

ss -tna|grep $PORT|grep CLOSE|awk '{print $5}'|sort|uniq -c

回顾A服务的网络模型,理论上A服务的每个实例都会与B服务的每个实例建立360个连接。如果一台A服务的机器上,出现360个CLOSE_WAIT那么可以猜测就是本机与的B服务的某个实例的所有连接都挂了。进一步猜测是B副队实例下线(比如缩容或换机)时才会出现。
B服务所用名字服务有运营网站,可以查询B服务实例的变化记录。果然可以发现发现每天凌晨B服务都会有自动变更,Delete掉实例,然后再Add新实例。新旧实例IP不同。这个操作并不是HPA,类似一种扩缩容健康度的检测。刚才用ss命令发现的异常连接数达到360的IP,通过在该网站中进行查询,发现确实都是当天凌晨Delete掉的。
每天凌晨TCP Socket数监控会大涨,和凌晨B服务的机器变更吻合。
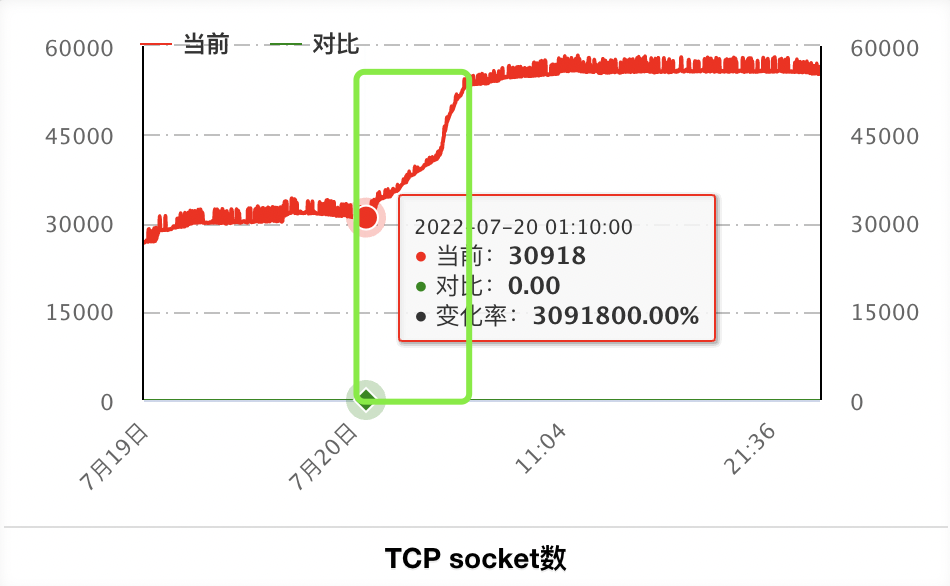
再来看一下之前几次异常的时候的机器监控,以A服务某实例所在机器为例:
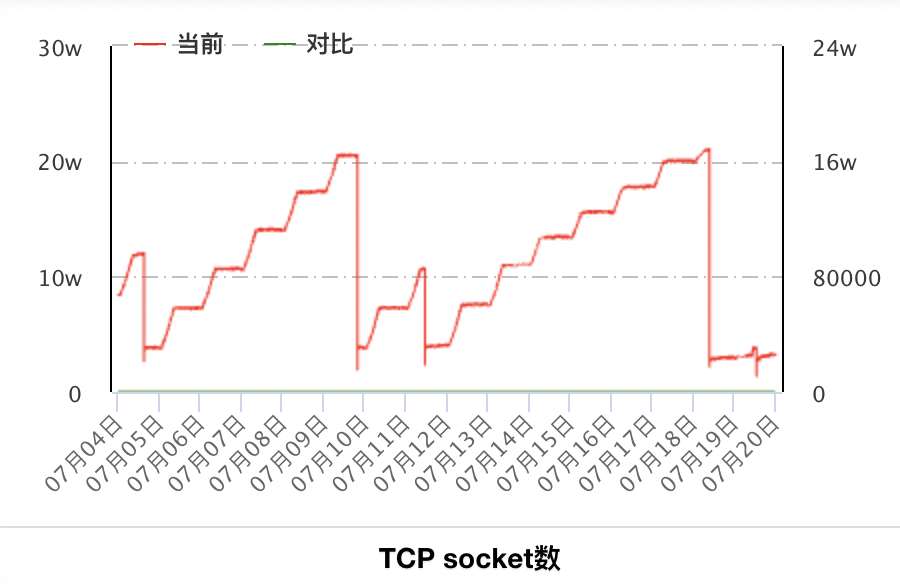
7月9日的异常和7月18日的异常(7月15日只有少数实例异常,该实例不在列)socket数都达到了相似的20W+,观察A服务其他实例所在机器也可以看到这两次也是达到了相同的峰值20W+。因为服务是混布的,这个socket数是机器上所有服务的socket总数。但20W相关的限制我没有找到对应的配置,机器的fd最大数量限制是2000W,和这个20W也匹配不上。也可能是耗尽了本机端口号(毕竟TCP连接的客户端也是需要端口号的)。但这些不影响我们的结论,问题根源还是SDK没有处理好TCP连接。
每天下线的机器,A服务进程中没有关闭对应的socket,导致出现大量CLOSE_WAIT。在有了这个推论的基础上,有针对性地再去阅读SDK代码,果不其然,发现了当前SDK中的逻辑问题:每次SDK在发送请求的时候,操作的都是名字服务返回的IP,而下线的机器IP不再返回,SDK中也没有额外操作对这些已下线机器连接过的socket进行清理。
修复验证
修复逻辑
第一时间,想到的修复的方案比较简单,那就是及时关闭掉异常的连接即可。实现的时候也是有多种方案,比如实现一个定时的心跳探活,或者定时的关闭空闲连接。出于实现简单考虑,这里选择了后者。思路是每隔N分钟check一次最近N分钟内没有用的连接,没有用到就close掉,然后从connect_map中erase掉,因为这些不用的连接对象一直在connect_map中存着,也会导致connect_map对象越来越大,有内存泄露风险。
接着就是确定定时的方案,当然可以新建一个线程来定时轮询每个Worker中的connect_map,检查并close,然后erase。但是引入单独的轮询线程,势必会出现一些极端的race condition,比如当检测线程判断了有一个连接N分钟没有使用,开始close的时候,这时候某个正在处理请求的工作线程,SDK中的名字服务推荐了这个连接对应IP:PORT,接着Worker开始从connect_map中获取对象……
那需要加锁吗?
不需要,因为我的实现方案并没有用独立线程来清理。我修改了SDK,在每次SDK中进行完B服务的发包和收包之后,检查一下是否到了清理连接的时间了(设置的5分钟),如果距离上一次清理已经超过5分钟,则开始遍历当前的connect_map中的所有连接,逐个连接判断上一次访问时间(每条连接也有记录访问时间),如果有超过5分钟的就close掉。并且从connect_map中erase。
这样实现不需要额外考虑线程安全的问题。
值得一提的是如果当前Worker对象一直没有新的请求命中,比如A服务空闲时,360个Worker中,有几个Worker所对应的线程一直没有请求进来,那么其中connect_map中的连接也是得不到释放的,不过这种情况发生发生的概率并不高,因为在A服务选择工作线程的时候,肯定是均匀的,在流量是稳定持续的时候,每个Worker都被选中,所以不会有问题。即使极端情况下,流量特别小,有某个Worker一直没有请求进来,但也因为没有命中,所以不会调用名字服务获取新的B实例IP,也就不会感知B服务的机器变化,自然也不会导致socket数增多。
其实还有其他更为优雅的解法,在本文最后一节有探讨。
上线效果
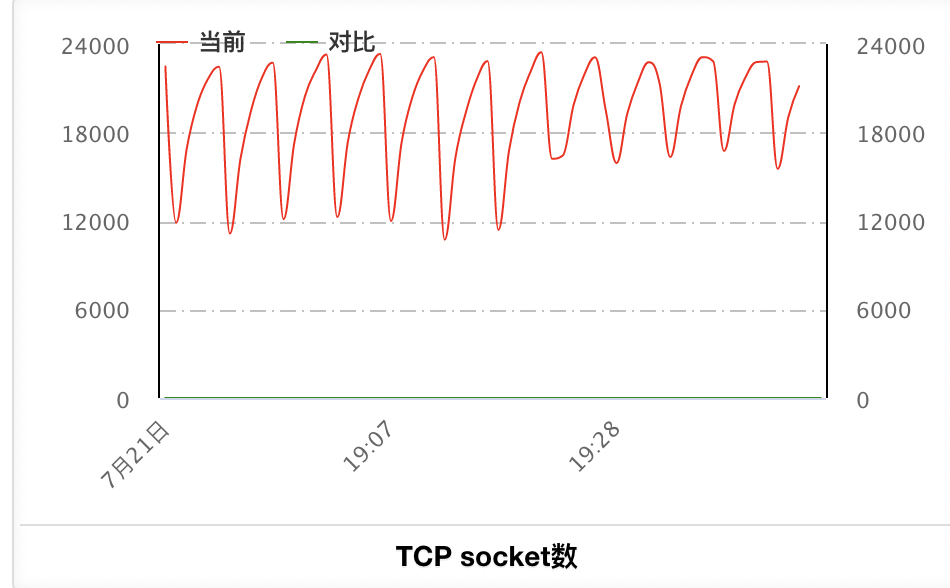
7月21日晚上完成了修复逻辑的上线。上线之后单台机器tcp socket数2小时变化如下(微观视角,5分钟清理一次socket):
7月22日凌晨开始到10点的整体变化,可以看到socket数不会再持续上涨(宏观视角,socket数总体趋势和流量趋势一致):
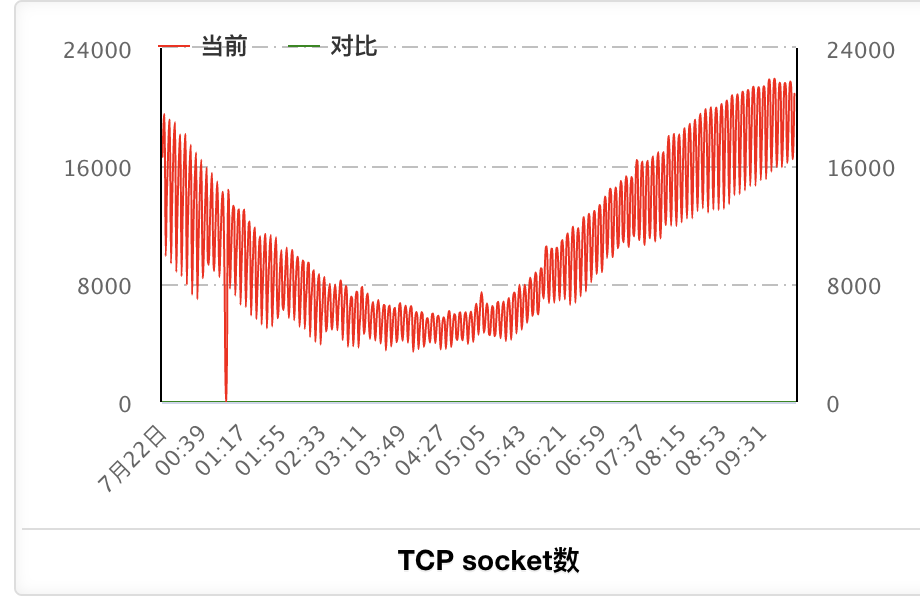
继续打开名字服务的网站查看,可以看到7.22凌晨也有实例的下线和上线操作。但我们的机器socket数已经不再持续增长,后面继续观察了一周,确认问题修复。
延伸探讨
keep_alive与CLOSE_WAIT
回说前面提到的CLOSE_WAIT有超时时间吗?如果你在网上搜索,可以看到这样的说法:
CLOSE_WAIT有超时设置,是通过TCP的keepalive机制设置实现的。
在Linux系统有三个keepalive的配置:
cat /proc/sys/net/ipv4/tcp_keepalive_time 7200
cat /proc/sys/net/ipv4/tcp_keepalive_intvl 75
cat /proc/sys/net/ipv4/tcp_keepalive_probes 9这三个配置表示7200s后发送一次TCP连接的探活包,这时候即使对端连接已经彻底关闭,但对端的操作系统也会回复一个RST过来(并不会没有回复),然后本端操作系统感知到会立刻关闭连接,从而让CLOSE_WAIT状态的连接消失。但如果没有收到任何响应(比如不止服务下线,机器也下线了),则会继续每75s发送一次,再发送9次,如果都失败,那么本端的操作系统会也会来关闭这条连接。
看起来最少等待7200s(两个小时)最多等待7200975 = 8175s(两个小时11分钟后)系统就能自动close掉连接。
网上大部分资料都是这么说的,很多资料提议修改系统配置,说两小时太长,建议减少这个时间。但这说法仍然不完全准确,因为据我观察A服务实例上那些凌晨下线的B服务实例机器,它的连接,我到了当天下午还能查询的到。早就过了该触发系统回收的时间。那这又是为什么呢?
其实原因是keepalive的特性并不是默认开启的,需要自己给socket进行设置socket选项SO_KEEPALIVE才行。在没有设置这个选项的时候,不会因为上述三个配置,导致CLOSE_WAIT的连接超过两个小时就被系统关闭连接!
所以针对我本次遇到的问题,通过给每个socket设置SO_KEEPALIVE,让socket和连接被系统回收,理论上也是能解决问题的。
后来我还真做了测试,修改SDK代码去掉我第一版的修复逻辑,改成给客户端socket设置SO_KEEPALIVE选项:
int val = 1;
if (setsockopt(client_fd, SOL_SOCKET, SO_KEEPALIVE, &val, sizeof(val)) == -1) {
...
}然后找了一台非线上环境的A服务实例(平时没流量),在15:47发了连续发了两波10qps请求,一波1分钟,一波3分钟。等待2个小时后:
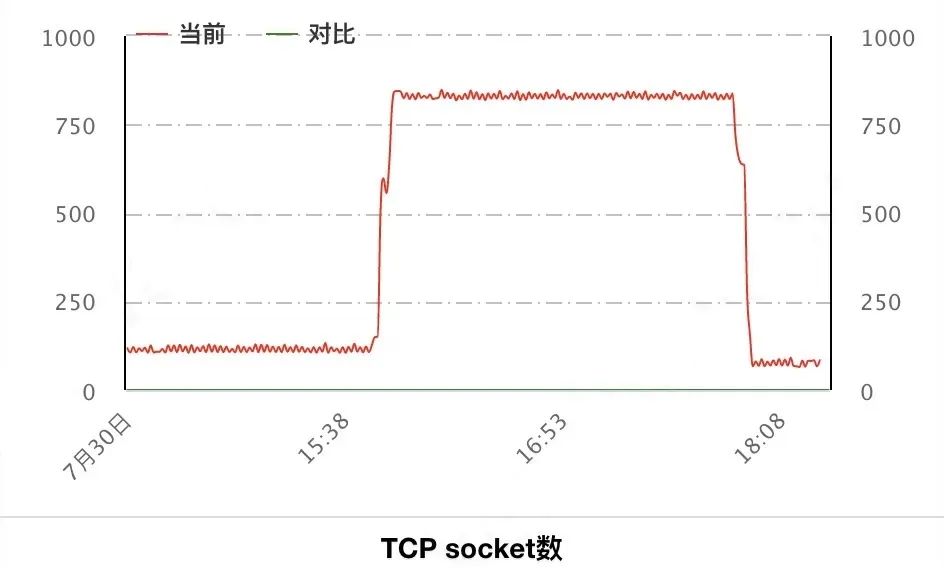
果然也看到了socket数的下降。这里正好是7200s(两个小时)socket数就开始下降,这是因为这期间B服务的机器并没有缩容掉,机器仍然在线,只是因为2个小时内没有新的请求,所以被对端关闭了连接。如果机器已经被缩容,那么需要等待 8175s 之后socket数才会下降的!
其实要看keepalive生效没有,也可以使用ss命令的-e参数:
ss -tnae|grep $PORT|grep CLOSE

但是这个两个小时的时间确实还是太长了,而且修改系统级别的TCP配置,又不是我能修改的。还有其他办法吗?其实也有,那就是那三个keepalive的设置,还可以通过设置socket选项的方式来覆盖系统配置,比如:
int val = 600;
if (setsockopt(client_fd, IPPROTO_TCP, TCP_KEEPIDLE, &val, sizeof(val)) < 0) {
...
}
val = 5;
if (setsockopt(cliend_fd, IPPROTO_TCP, TCP_KEEPINTVL, &val, sizeof(val)) < 0) {
...
}
val = 3;
if (setsockopt(, IPPROTO_TCP, TCP_KEEPCNT, &val, sizeof(val)) < 0) {
...
}这样改确实也能解决问题,不过connect_map中的连接虽然被关闭了,但是对象并没有被erase,所以还是需要搭配额外的遍历connect_map和erase逻辑。
好了,其实怎么修复都不重要了,重要的是这个问题已经研究清楚了。记住任何时候,如果出现了大量CLOSE_WAIT,请记住这都是『结果』,而不是『原因』。不要一上来就想着通过修改系统的配置来加速连接回收,其实本质还是自身代码不够健壮,要从代码本身入手。