一文详解K8s环境下Job类日志采集方案

背景
K8s丰富的controller为容器编排提供了极大的便利,其中针对单次任务和定时任务的需求,K8s提供了Job和Cronjob控制器来满足非常驻容器编排的需要。由于这种非常驻的特征,任务容器的时长可能很短(如定时清理数据的任务),甚至有些任务因为一启动就运行失败出现秒退的情况,这给采集Job日志带来了很大的挑战。
本文将基于高性能轻量级可观测采集器iLogtail探讨Job日志的多种采集方案,分析这些方案在不同场景下对日志采集所能做到稳定性保证以及方案优化空间。
Job容器的特点
为了表述方便,本文将由Job控制器控制的业务容器都称为Job容器。相比于其他类型容器,Job容器具有如下特点:
- 增删频率高:Job容器经常为周期性调度或者on-demand调度并且执行完毕即结束,因此增删频率会显著高于其他类型容器。
- 生命周期短:Job容器的预期就是执行完任务后退出,并非常驻服务,因此生命周期相对较短。有些Job仅仅用于简单地删除历史数据等,生命周期仅秒级。
- 突发并发大:Job容器常在编排批处理任务或者测试场景使用,此类场景往往会瞬时触发大量Job容器实例的生成,并伴随生成大量日志。
Job日志采集方案选择的关键考虑点
因此,对于Job日志采集以下三个考虑点至关重要。
容器发现速度:Job容器增删频率高,如果容器发现的速度太慢,那么可能还没有来得及发现容器,容器就已经销毁了,更妄谈数据采集。
开始采集延时:Job容器生命周期可能很短,K8s中Pod销毁时会连带删除其下所有容器数据,如果没有及时开始采集,那么就无法锁定文件句柄,被删除的文件数据也就无法采集了。
弹性支持:Job容器的突发高并发特性非常适合使用弹性资源以节省成本,因此对应地希望采集方案可以适配支持弹性扩缩容。
同时,容器日志采集的一些通用需求在选择方案时也需要纳入考量。
资源开销:更低的资源开销通常意味着更低的成本,同时也减少日志采集对业务使用资源的影响。
meta信息打标:元信息用来标识日志来源,丰富的元信息有助于日志的查找和使用。
侵入性:侵入性决定了采集日志的开发成本,同时更强的侵入性也会增加日志采集和业务的耦合,给未来方案修改升级带来潜在成本。
iLogtail容器采集方案比较
DaemonSet采集方式
DaemonSet采集方式,利用K8s的DaemonSet控制器在每一个节点上部署一个iLogtail容器用于该节点上所有容器的日志采集。这种部署方式通过与节点上的docker.sock或者containerd.sock与容器运行时通信以发现节点上所有容器,从返回的容器信息中获取容器的标准输出路径和存储路径,并挂载主机路径以采集数据。
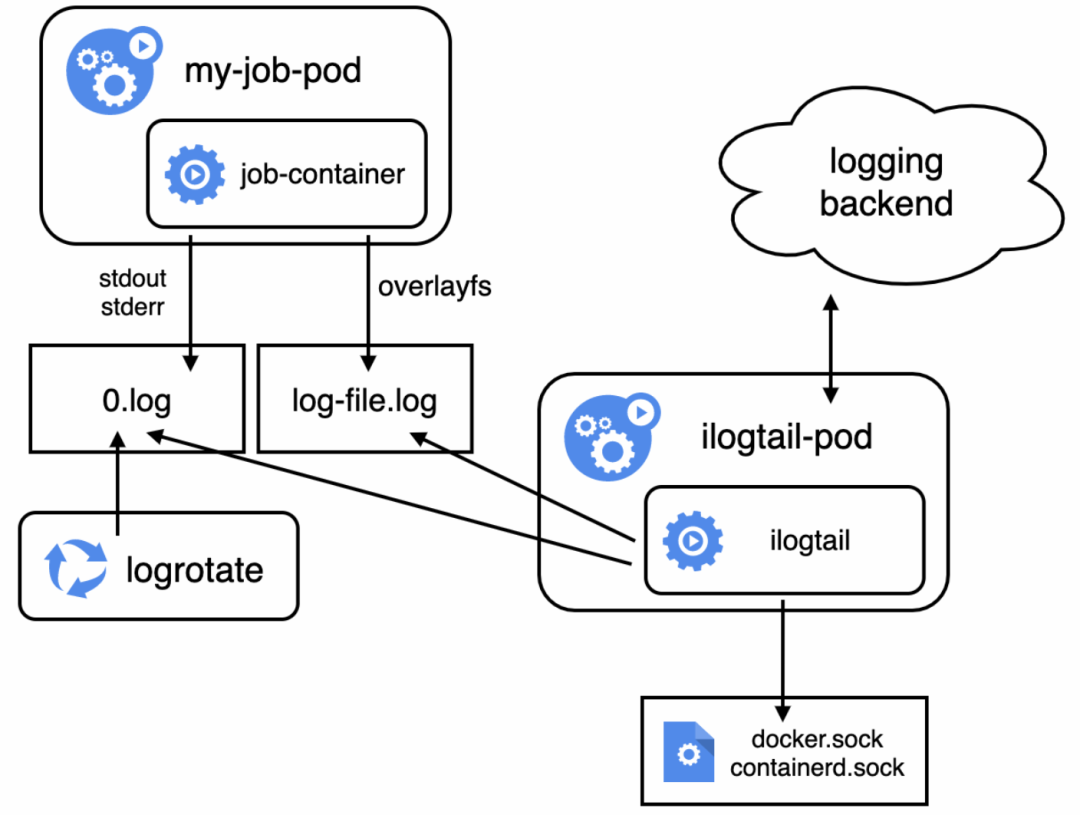
而与Job日志采集密切相关3个关键点上DaemonSet方式反而表现一般。通过DaemonSet部署iLogtail时,iLogtail的发现容器的机制依赖与docker.sock或者containerd.sock通信,docker有自己的EventListener机制可以实时获取容器的创建销毁事件;而containerd则没有,只能通过轮询机制了解容器的创建销毁,在最新版本中轮询间隔为1秒,因此可以认为iLogtail发现容器的延时为1秒。从发现容器到将开始数据采集还有一个3-6秒左右的延时,其中采集stdout的延时来自stdout采集插件内部的轮询间隔,而采集容器文件的延时则来自docker_file插件的轮询间隔和C++核心部分加载最新容器配置的频率限制。因此,再加上一些处理耗时,DaemonSet方式预期的容器日志开始采集延时为5-8秒左右。弹性方面,DaemonSet部署的iLogtail可以支持动态节点扩容方式,但无法直接支持没有物理节点的弹性容器扩容方式。
Sidecar采集方式
Sidecar采集方式,利用K8s同一个Pod内的容器可以共享存储卷的特性,在一个业务Pod内同时部署业务和采集容器以达到业务数据的目的。这种采集方式要求业务容器将需要采集的目录挂载出来与采集容器共享,采集容器则使用采集本地文件的方式采集业务容器日志。
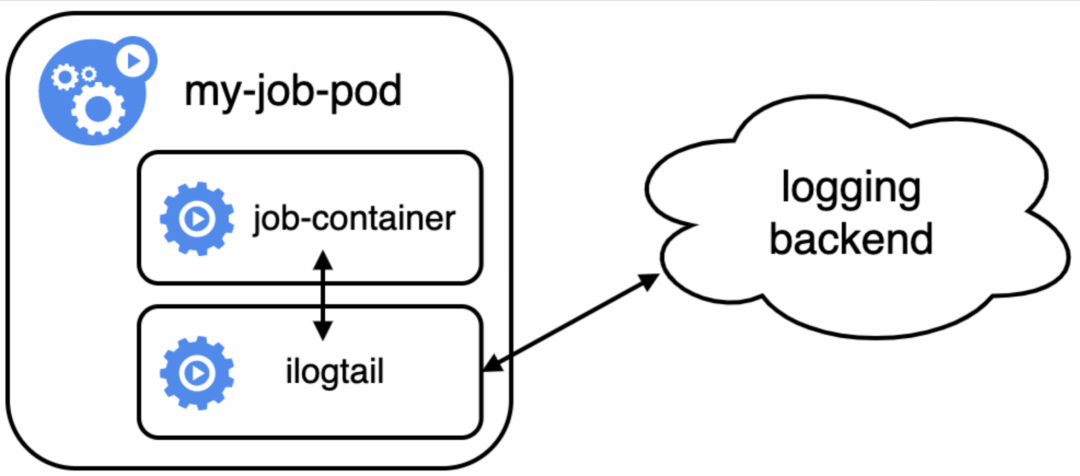
但是相比于DaemonSet,Sidecar并没有那么受欢迎,除了无法直接支持采集容器标准输出的功能因素外,还有一些缺点限制了其使用的范围。首先是资源消耗较大,每个Pod都需要一个Sidecar采集容器,其资源开销与业务Pod数量成正比。其次,由于采集的原理本质同主机,因此容器的meta信息无法自动采集,需要通过环境变量等方式暴露到采集容器中。最后,每个业务Pod都需要为目标数据配置共享存储,并且要考虑通知采集容器退出的机制,存在一定的侵入性。
ECI弹性容器产品采集方式
ECI是弹性容器实例的缩写(详见阿里云官方介绍),相当于一个小型虚拟机,用完即毁,没有物理节点的羁绊,对于突发高并发场景具备成本和弹性优势,而这刚好是部分Job容器使用场景的特点。ECI产品采集方式的原理与DaemonSet采集方式类似,其不同点在于,在ECI中的iLogtail容器不受Kube Scheduler控制,而是由ECI进行控制的,对用户不可见。iLogtail的容器发现方式,也不通过与docker.sock或containerd.sock通信,而是通过静态容器信息发现要采集的容器。为了支持容器数据获取,ECI还会将ECI上的路径挂载到iLogtail容器中,与DaemonSet挂载主机路径原理相同。

成本方面,虽然每个Pod都会启动一个ECI并附带iLogtail Pod,但由于弹性容器资源随用随还的特点,对于突发高并发的Job场景其实际成本可能比自建节点更低。由于ECI仅为需要采集数据的容器创建iLogtail容器,因此需要一些手段判断业务容器的日志采集需求,目前支持采用CRD(K8s Operator)或者环境变量。CRD方式是目前更为推荐的一种接入方式,对业务容器无入侵且支持更丰富的采集配置。若采用环境变量方式,则存在一定的侵入性。
同容器采集方式
同容器采集方式是指将采集进程和业务进程同容器部署,相当于将容器视为一个虚拟机的部署方式,因此采集的原理也完全同主机。
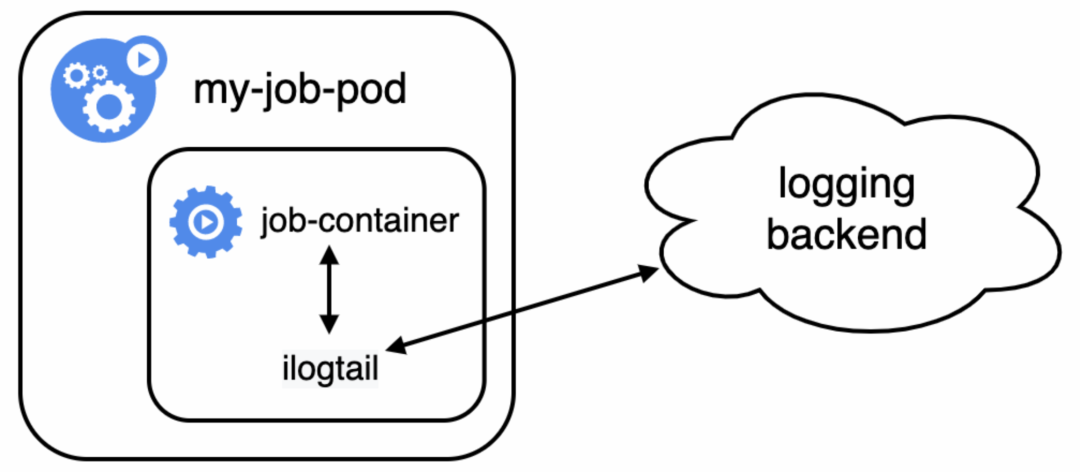
在资源开销方面,每个业务容器均额外消耗采集进程开销,资源消耗较大。而要采集容器的meta信息,则需要通过环境变量等方式暴露在业务容器中,不能进行自动标注。
独立存储采集方式
独立存储方式是指容器将要采集的数据都打印到共享的pv或hostPath挂载的路径上,而采集容器只需要关心将pv或hostPath上的数据采集上来的采集方案。有些Job调度器可以指定每个Job的日志路径,因此可以将日志都打在同一个共享卷上。当使用共享pv上时,所有数据采集只需要由1个采集容器负责采集即可;使用hostPath时,则需要使用DaemonSet部署采集容器,使每个节点上都恰好有一个采集容器。
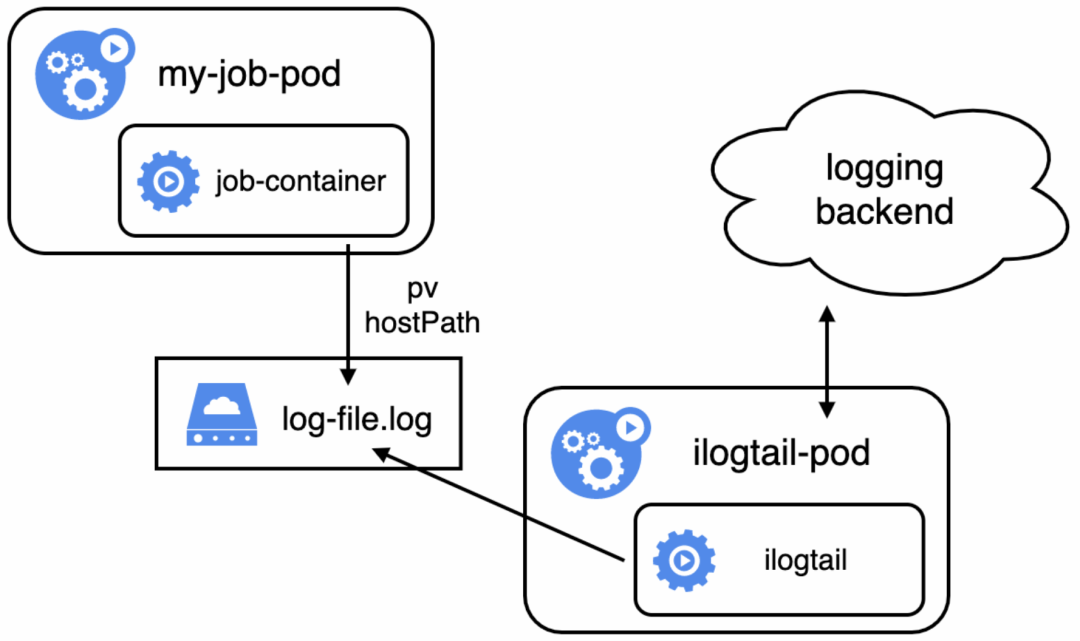
但在弹性方面独立存储采集方式表现不佳,若使用PV并对应一个采集容器,则一个采集容器的吞吐会成为采集性能的瓶颈,而如果使用hostPath配合DaemonSet部署则无法支持弹性容器。这种采集方式在获取meta信息方面也支持不佳,只能通过将meta信息内嵌在数据存储路径中来暴露一些元信息。比如在volume挂载时设定SubPathExpr为logs/$(POD_NAMESPACE)_$(POD_NAME)_$(POD_IP)_$(NODE_IP)_$(NODE_NAME)。
小结
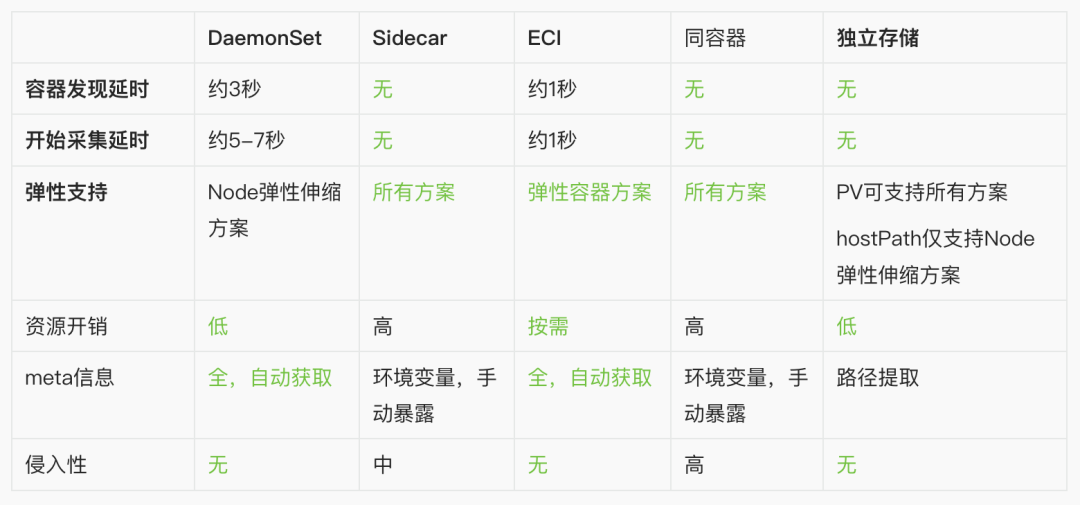
下表总结了前文描述的5种采集方案:
典型场景
短生命周期Job
如果任务的执行时间较长,比如1分钟以上,那么给予采集端采集Job容器数据的时间窗口就会较大。此时由于对采集方案的容器发现延时和开始采集延时不敏感,所以采用DaemonSet的采集方法也不会有任何问题。但当Job的生命周期小于1分钟时,默认的采集参数就可能出现日志丢失的现象。当Job容器的生命周期在10秒以上时,我们都可以继续使用DaemonSet的采集方案,只需要对一些参数进行调整,就可以确保数据采集完整。由于标准输出采集原理与容器文件不同,因此两者需要调整的参数也不完全相同。
- 通过调整启动参数(全局生效)docker_config_update_interval来减小容器发现后生效延时,比如1.0.34版本前从默认10 s调整到3 s(之后版本默认就是3 s),降低容器发现后锁定不了文件的可能性。
- 通过调整轮询时间来减小开始采集的延时,提前锁定文件句柄,防止Pod删除后数据采集不到。标准输出需要调整采集配置(局部采集配置生效),参数名FlushIntervalMs,比如从默认3000 ms调整为1000 ms;文件采集需要调整启动参数(全局生效),参数名max_docker_config_update_times,比如从默认3分钟频控10调整为60。
- 如果启动Job启动时会打印大量日志,可以调整发现文件后开始采集的位置,防止因开始采集不是文件起始位置导致日志丢失。标准输出需要调整采集配置(局部采集配置生效),参数名StartLogMaxOffset,比如从默认131072 B调整为13107200 B;文件采集需要调整采集配置(局部采集配置生效),参数名tail_size_kb,比如从默认1024 KB调整为10240 KB。
- 检查Job结束后不会立刻被清理,即刚退出的容器标准输出日志仍可读。使用内置CronJob调度的,确认CronJob的.spec.successfulJobsHistoryLimit and .spec.failedJobsHistoryLimit未配置或者 > 0;使用自定义调度器的,确认Job的.spec.ttlSecondsAfterFinished未配置或> 0,且自身逻辑不会立刻清理已完成的Job。
示例的DaemonSet patch如下:
spec:
template:
spec:
containers:
- name: logtail
env:
- name: docker_config_update_interval # 减小容器发现延时
value: "3"
- name: max_docker_config_update_times # 提高容器配置加载频率,减小开始采集延时
value: "60"kubectl patch ds logtail-ds -n kube-system --patch-file ds-patch.yaml
示例的容器标准输入采集配置如下:
{
"inputs": [
{
"detail": {
"FlushIntervalMs": 1000 # 加快插件轮询频率,减小开始采集延时
},
"type": "service_docker_stdout"
}
]
}秒退Job
如果容器的生命周期极短,不到10秒,甚至秒退,那么使用DaemonSet方式因其不可避免的容器发现延时,极易导致此类Job容器数据采集丢失。对于这种情况,我们建议使用以下2种方式之一解决:
- 使用容器标准输出。将容器日志输出改造为使用标准输出,将日志轮转请理交由kubelet处理。K8s的垃圾回收机制通常可以保证每个Pod留存最近1个容器的容器元信息和标准输出日志记录,这样即使容器已经退出,但只要Pod没有被删除,容器仍然可以被发现,并采集其标准输出日志。采用这一方案仍然需要注意上面提到调整参数的4 JobsHistoryLimit,避免日志采集前Pod被销毁。
2 . 使用SideCar或者ECI方式采集以保证数据采集完整性。与采集普通容器日志不同的是,Job容器使用Sidecar方式采集需要注意退出机制问题。普通容器退出,通常是由控制器发起要求Pod退出,因此Pod中所有容器都会收到sigterm信号。但Job容器通常都是任务执行完成自动退出,采集容器不会收到sigterm信号,因此需要业务容器通知其退出。一个简单的实现方式是通过共享卷上的文件进行通知。
示例的Sidecar容器文件采集配置
apiVersion: batch/v1
kind: Job
metadata:
name: sidecar-demo
namespace: default
spec:
ttlSecondsAfterFinished: 90
template:
metadata:
name: sidecar-demo
spec:
restartPolicy: Never
containers:
- name: nginx-log-demo
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/sh", "-c"]
args:
- /bin/mock_log --log-type=nginx --stdout=false --stderr=true --path=/var/log/nginx/access.log --total-count=10 --logs-per-sec=10;
retcode=$?;
touch /graveyard/tombstone;
exit $retcode
volumeMounts:
- name: nginx-log
mountPath: /var/log/nginx
- mountPath: /graveyard
name: graveyard
##### logtail sidecar container
- name: logtail
# more info: https://cr.console.aliyun.com/repository/cn-hangzhou/log-service/logtail/detail
# this images is released for every region
image: registry.cn-huhehaote.aliyuncs.com/log-service/logtail:latest
command: ["/bin/sh", "-c"]
args:
- /etc/init.d/ilogtaild start;
sleep 10;
until [[ -f /graveyard/tombstone ]]; do sleep 3; done;
/etc/init.d/ilogtaild stop;
livenessProbe:
exec:
command:
- /etc/init.d/ilogtaild
- status
initialDelaySeconds: 30
periodSeconds: 30
resources:
limits:
memory: 512Mi
requests:
cpu: 10m
memory: 30Mi
env:
##### base config
# user id
- name: ALIYUN_LOGTAIL_USER_ID
value: "1654218965343050"
# user defined id
- name: ALIYUN_LOGTAIL_USER_DEFINED_ID
value: hhht-ack-containerd-sidecar
# config file path in logtail's container
- name: ALIYUN_LOGTAIL_CONFIG
value: /etc/ilogtail/conf/cn-huhehaote/ilogtail_config.json
##### env tags config
- name: ALIYUN_LOG_ENV_TAGS
value: _pod_name_|_pod_ip_|_namespace_|_node_name_|_node_ip_
- name: _pod_name_
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: _pod_ip_
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: _namespace_
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: _node_name_
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: _node_ip_
valueFrom:
fieldRef:
fieldPath: status.hostIP
volumeMounts:
- name: nginx-log
mountPath: /var/log/nginx
- mountPath: /graveyard
name: graveyard
##### share this volume
volumes:
- name: nginx-log
emptyDir: {}
- name: graveyard
emptyDir:
medium: Memory在该示例配置中,业务容器使用/graveyard/tombstone文件通知采集容器退出,而采集容器中通过将meta信息暴露在env中,使iLogtail可以获取容器元信息进行日志打标。几个值得注意的细节如下:
- 业务容器无论成功与否都要通知采集容器退出:见下方代码摘要的2-4行。
- /bin/mock_log --log-type=nginx --stdout=false --stderr=true --path=/var/log/nginx/access.log --total-count=10 --logs-per-sec=10;
retcode=$?;
touch /graveyard/tombstone;
exit $retcode2 .采集容器至少等待10秒后才退出:见下方代码第2行。这是因为iLogtail启动后要去服务端拉取采集配置,如果过早退出则有可能因为还没来得及获取采集配置而丢失采集数据。
- /etc/init.d/ilogtaild start;
sleep 10;
until [[ -f /graveyard/tombstone ]]; do sleep 3; done;
/etc/init.d/ilogtaild stop;3 .容器元信息的打标方式:通过ALIYUN_LOG_ENV_TAGS告知iLogtail需要用于打标的环境变量,多个环境变量使用“|”分隔。而被提及的环境变量则可以通过valueFrom的方式引用容器元信息的值。
- name: ALIYUN_LOG_ENV_TAGS
value: _pod_name_|_pod_ip_|_namespace_|_node_name_|_node_ip_
- name: _pod_name_
valueFrom:
fieldRef:
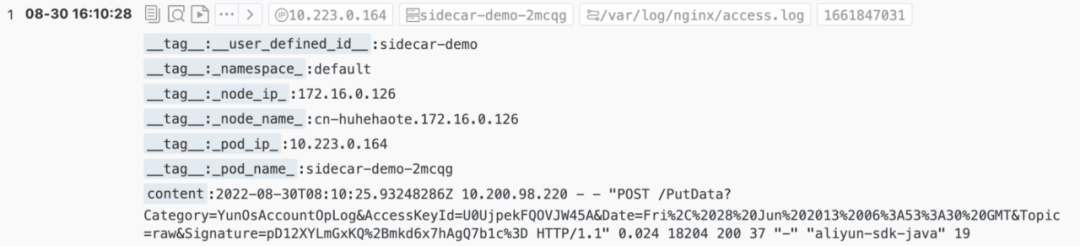
fieldPath: metadata.name采集效果如下:
示例的ECI容器文件采集配置
apiVersion: log.alibabacloud.com/v1alpha1
kind: AliyunLogConfig
metadata:
# 设置资源名,在当前Kubernetes集群内唯一。
name: eci-demo
spec:
# 设置Logstore名称。如果您所指定的Logstore不存在,日志服务会自动创建。
logstore: eci-demo
# 设置Logtail采集配置。
logtailConfig:
# 设置采集的数据源类型。采集标准输出时,需设置为plugin。
inputType: file # 设置采集的数据源类型。
configName: eci-demo # 设置Logtail配置名称,与资源名(metadata.name)保持一致。
inputDetail: # 设置Logtail采集配置的详细信息。
# 指定通过完整正则模式采集容器文本日志。
logType: common_reg_log
# 设置日志文件所在路径。
logPath: /var/log/nginx
# 设置日志文件的名称。支持通配符星号(*)和半角问号(?),例如log_*.log。
filePattern: access.log
# 设置用于匹配日志行首的行首正则表达式。如果为单行模式,设置成'.*'。
logBeginRegex: '.*'
# 设置正则表达式,用于提取日志内容。请根据实际情况设置。
regex: '(\S+)\s(\S+)\s\S+\s\S+\s"(\S+)\s(\S+)\s+([^"]+)"\s+(\S+)\s(\S+)\s(\d+)\s(\d+)\s(\S+)\s"([^"]+)"\s.*'
# 设置提取的字段列表。
key : ["time", "ip", "method", "url", "protocol", "latency", "payload", "status", "response-size", "user-agent"]使用CRD方式进行采集配置灵活性较大,可以基本实现控制台上的所有配置能力。inputType支持文件或者插件作为输入类型,inputDetail中支持多种多种文本格式类型配置,同时允许级联plugin配置对日志进行采集或处理,详情可参考帮助文档进行配置。
突发大量Job
突发大量Job的挑战在于短期内需要采集大量数据,因此对采集容器压力会突增,要求更大的资源上限。对于客户端建议调大iLogtail的配置参数和容器的资源限制:
spec:
template:
spec:
containers:
- name: logtail
resources:
limits:
cpu: 4000M
memory: 4096Mi
requests:
cpu: 10M
memory: 30Mi
env:
- name: cpu_usage_limit
value: "9"
- name: mem_usage_limit
value: "4096"
- name: max_bytes_per_sec
value: "209715200"
- name: send_request_concurrency
value: "80"
- name: process_thread_count # 会牺牲SLS上下文功能
value: "8"这些参数的含义可以参见帮助文档。注意process_thread_count > 1会破坏SLS日志上下文浏览功能,仅在其他参数设置后仍然无法追上数据时采用。对于服务端建议扩大LogStore的shard,确认容量充足。shard的数量可以通过峰值流量 / 5 M/s计算得到。如果在采集时出现写入慢的情况,则可以通过Cloud Lens for SLS的查看是否服务端有quota打满。
小结
下表总结了前文描述的3种场景和对应采集解决方案:
| 场景要素 | 推荐方案 |
|---|---|
| Job生命周期> 1 min | DaemonSet |
| Job生命周期> 10 s | DaemonSet + 参数调优 |
| Job生命周期<= 10 s | DaemonSet + 标准输出 / Sidecar + 正确退出机制 + 元信息环境变量 / ECI |
| 突发大量Job | 客户端:调大参数和资源限制,服务端:调大shard数 |
从表中可以看出,Job容器采集并没有放之四海而皆准的最优方案,需要根据不同场景进行选择。而Job容器采集的方案虽然逃不脱DaemonSet或者Sidecar等采集方式,但往往需要在此基础上进行参数调整,对用户使用的要求较高。使用ECI方式运行Job并采集日志,不需要用户进行太多额外配置,似乎是一个对用户来说简单轻松的选择。
总结和展望
Job容器采集因其增删频率高、生命周期短和突发并发大的特点,对日志采集的方案提出了特殊的要求。本文针对这些特点,从3个主要考虑点和3个次要考虑点分析了5种采集方案的优缺点,并结合典型的Job场景给出了具体的采集解决方案。从讨论的结果来看,要做到各种Job场景下数据不丢往往需要对采集容器的调参,使用ECI方式运行Job并采集日志因其弹性能力与Job场景匹配且采集配置简单,也许会成为未来运行云原生Job的最佳实践。
对于iLogtail来说,如何进一步减小容器发现和开始采集延时,避免需要用户手动调参优化是下一步需要优化的方向。对SLS产品来说,如何更好地应对突发大流量,减少用户介入成本也是一个可以考虑的优化点。
关于iLogtail
iLogtail作为阿里云SLS提供的可观测数据采集器,可以运行在服务器、容器、K8s、嵌入式等多种环境,支持采集数百种可观测数据(日志、监控、Trace、事件等),已经有千万级的安装量。目前,iLogtail已正式开源,欢迎使用及参与共建。