C++服务编译耗时优化原理及实践
一、背景
美团搜索与NLP部为公司提供基础的搜索平台服务,出于性能的考虑,底层的基础服务通过C++语言实现,其中我们负责的深度查询理解服务(Deep Query Understanding,下文简称DQU)也面临着编译耗时较长这个问题,整个服务代码在优化前编译时间需要二十分钟左右(32核机器并行编译),已经影响到了团队开发迭代的效率。
在这样的背景下,我们针对DQU服务的编译问题进行了专项优化。在这个过程中,我们也积累了一些优化的知识和经验,在这里分享给大家。
二、编译原理及分析
2.1 编译原理介绍
为了更好地理解编译优化方案,在介绍优化方案之前,我们先简单介绍一下编译原理,通常我们在进行C++开发时,编译的过程主要包含下面四个步骤:

- gcc -E选项可以得到预处理后的结果,扩展名为.i 或 .ii。
- C/C++预处理不做任何语法检查,不仅是因为它不具备语法检查功能,也因为预处理命令不属于C/C++语句(这也是定义宏时不要加分号的原因),语法检查是编译器要做的事情。
- 预处理之后,得到的仅仅是真正的源代码。
编译器:生成汇编代码,得到汇编语言程序(把高级语言翻译为机器语言),该种语言程序中的每条语句都以一种标准的文本格式确切的描述了一条低级机器语言指令。
- gcc -S选项可以得到编译后的汇编代码文件,扩展名为.s。
- 汇编语言为不同高级语言的不同编译器提供了通用的输出语言。
汇编器:生成目标文件。
- gcc -c选项可以得到汇编后的结果文件,扩展名为.o。
- .o文件,是按照的二进制编码方式生成的文件。
链接器:生成可执行文件或库文件。
- 静态库:指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了,其后缀名一般为“.a”。
- 动态库:在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可执行文件比较小,动态库一般后缀名为“.so”。
- 可执行文件:将所有的二进制文件链接起来融合成一个可执行程序,不管这些文件是目标二进制文件还是库二进制文件。
2.2 C++编译特点
1. 每个源文件独立编译
C/C++的编译系统和其他高级语言存在很大的差异,其他高级语言中,编译单元是整个Module,即Module下所有源码,会在同一个编译任务中执行。而在C/C++中,编译单元是以文件为单位。每个.c/.cc/.cxx/.cpp源文件是一个独立的编译单元,导致编译优化时只能基于本文件内容进行优化,很难跨编译单元提供代码优化。
2. 每个编译单元,都需要独立解析所有包含的头文件
如果N个源文件引用到了同一个头文件,则这个头文件需要解析N次(对于Thrift文件或者Boost头文件这类动辄几千上万行的头文件来说,简直就是“鬼故事”)。
如果头文件中有模板(STL/Boost),则该模板在每个cpp文件中使用时都会做一次实例化,N个源文件中的std::vector会实例化N次。
3. 模板函数实例化
在C++ 98语言标准中,对于源代码中出现的每一处模板实例化,编译器都需要去做实例化的工作;而在链接时,链接器还需要移除重复的实例化代码。显然编译器遇到一个模板定义时,每次都去进行重复的实例化工作,进行重复的编译工作。此时,如果能够让编译器避免此类重复的实例化工作,那么可以大大提高编译器的工作效率。在C++ 0x标准中一个新的语言特性 -- 外部模板的引入解决了这个问题。
在C++ 98中,已经有一个叫做显式实例化(Explicit Instantiation)的语言特性,它的目的是指示编译器立即进行模板实例化操作(即强制实例化)。而外部模板语法就是在显式实例化指令的语法基础上进行修改得到的,通过在显式实例化指令前添加前缀extern,从而得到外部模板的语法。
① 显式实例化语法:template class vector。 ② 外部模板语法:extern template class vector。
一旦在一个编译单元中使用了外部模板声明,那么编译器在编译该编译单元时,会跳过与该外部模板声明匹配的模板实例化。
4. 虚函数
编译器处理虚函数的方法是:给每个对象添加一个指针,存放了指向虚函数表的地址,虚函数表存储了该类(包括继承自基类)的虚函数地址。如果派生类重写了虚函数的新定义,该虚函数表将保存新函数的地址,如果派生类没有重新定义虚函数,该虚函数表将保存函数原始版本的地址。如果派生类定义了新的虚函数,则该函数的地址将被添加到虚函数表中。
调用虚函数时,程序将查看存储在对象中的虚函数表地址,转向相应的虚函数表,使用类声明中定义的第几个虚函数,程序就使用数组的第几个函数地址,并执行该函数。
使用虚函数后的变化:
① 对象将增加一个存储地址的空间(32位系统为4字节,64位为8字节)。 ② 每个类编译器都创建一个虚函数地址表。 ③ 对每个函数调用都需要增加在表中查找地址的操作。
5. 编译优化
GCC提供了为了满足用户不同程度的的优化需要,提供了近百种优化选项,用来对编译时间,目标文件长度,执行效率这个三维模型进行不同的取舍和平衡。优化的方法不一而足,总体上将有以下几类:
① 精简操作指令。 ② 尽量满足CPU的流水操作。 ③ 通过对程序行为地猜测,重新调整代码的执行顺序。 ④ 充分使用寄存器。 ⑤ 对简单的调用进行展开等等。
如果全部了解这些编译选项,对代码针对性的优化还是一项复杂的工作,幸运的是GCC提供了从O0-O3以及Os这几种不同的优化级别供大家选择,在这些选项中,包含了大部分有效的编译优化选项,并且可以在这个基础上,对某些选项进行屏蔽或添加,从而大大降低了使用的难度。
- O0:不做任何优化,这是默认的编译选项。
- O和O1:对程序做部分编译优化,编译器会尝试减小生成代码的尺寸,以及缩短执行时间,但并不执行需要占用大量编译时间的优化。
- O2:是比O1更高级的选项,进行更多的优化。GCC将执行几乎所有的不包含时间和空间折中的优化。当设置O2选项时,编译器并不进行循环展开以及函数内联优化。与O1比较而言,O2优化增加了编译时间的基础上,提高了生成代码的执行效率。
- O3:在O2的基础上进行更多的优化,例如使用伪寄存器网络,普通函数的内联,以及针对循环的更多优化。
- Os:主要是对代码大小的优化, 通常各种优化都会打乱程序的结构,让调试工作变得无从着手。并且会打乱执行顺序,依赖内存操作顺序的程序需要做相关处理才能确保程序的正确性。
编译优化有可能带来的问题:
① 调试问题:正如上面所提到的,任何级别的优化都将带来代码结构的改变。例如:对分支的合并和消除,对公用子表达式的消除,对循环内load/store操作的替换和更改等,都将会使目标代码的执行顺序变得面目全非,导致调试信息严重不足。
② 内存操作顺序改变问题:在O2优化后,编译器会对影响内存操作的执行顺序。例如:-fschedule-insns允许数据处理时先完成其他的指令;-fforce-mem有可能导致内存与寄存器之间的数据产生类似脏数据的不一致等。对于某些依赖内存操作顺序而进行的逻辑,需要做严格的处理后才能进行优化。例如,采用Volatile关键字限制变量的操作方式,或者利用Barrier迫使CPU严格按照指令序执行。
6. C/C++ 跨编译单元的优化只能交给链接器
当链接器进行链接的时候,首先决定各个目标文件在最终可执行文件里的位置。然后访问所有目标文件的地址重定义表,对其中记录的地址进行重定向(加上一个偏移量,即该编译单元在可执行文件上的起始地址)。然后遍历所有目标文件的未解决符号表,并且在所有的导出符号表里查找匹配的符号,并在未解决符号表中所记录的位置上填写实现地址,最后把所有的目标文件的内容写在各自的位置上,就生成一个可执行文件。链接的细节比较复杂,链接阶段是单进程,无法并行加速,导致大项目链接极慢。
三、服务问题分析
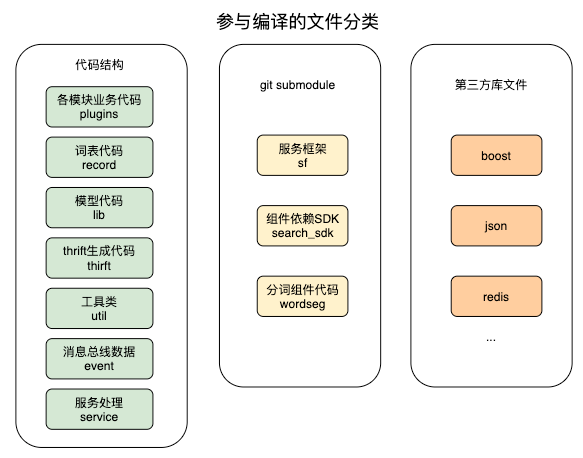
DQU是美团搜索使用的查询理解平台,内部包含了大量的模型、词表、在代码结构上,包含20多个Thrift文件 ,使用大量Boost处理函数 ,同时引入了SF框架,公司第三方组件SDK以及分词三个Submodule,各个模块采用动态库编译加载的方式,模块之间通过消息总线做数据的传输,消息总线是一个大的Event类,这样这个类就包含了各个模块需要的数据类型的定义,所以各个模块都会引入Event头文件,不合理的依赖关系造成这个文件被改动,几乎所有的模块都会重新编译。
3.1 编译展开分析
编译展开分析就是通过C++的预编译阶段保留的.ii文件,查看通过展开后的编译文件大小,具体可以通过在cmake中指定编译选型 “-save-temps” 保留编译中间文件。
set(CMAKE_CXX_FLAGS "-std=c++11 ${CMAKE_CXX_FLAGS} -ggdb -Og -fPIC -w -Wl,--export-dynamic -Wno-deprecated -fpermissive -save-temps")
编译耗时的最直接原因就是编译文件展开之后比较大,通过编译展开后的文件大小和内容,通过预编译展开分析能看到文件展开后的文件有40多万行,发现有大量的Boost库引用及头文件引用造成的展开文件比较大,影响到编译的耗时。通过这个方式能够找到各个文件编译耗时的共性,下图是编译展开后文件大小截图。

头文件依赖分析是从引用头文件数量的角度来看代码是否合理的一种分析方式,我们实现了一个脚本,用来统计头文件的依赖关系,并且分析输出头文件依赖引用计数,用来辅助判断头文件依赖关系是否合理。
1. 头文件引用总数结果统计
通过工具统计出编译源文件直接和间接依赖的头文件的总个数,用来从头文件引入数量上分析问题。

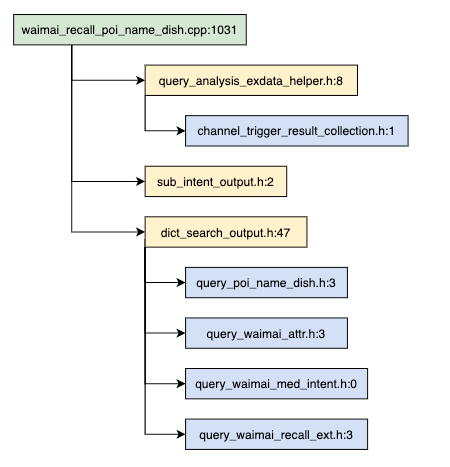
2. 单个头文件依赖关系统计
通过工具分析头文件依赖关系,生成依赖关系拓扑图,能够直观的看到依赖不合理的地方。
图中包含引用层次关系,以及引用头文件个数。
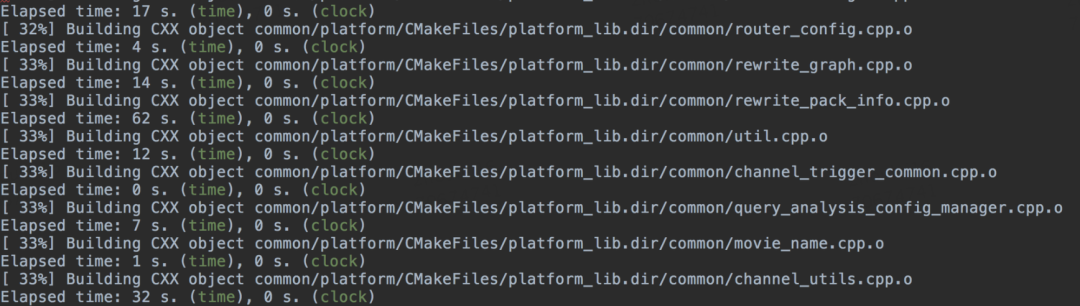
编译耗时分段统计是从结果上看各个文件的编译耗时以及各个编译阶段的耗时情况,这个是直观的一个结果,正常情况下,是和文件展开大小以及头文件引用个数是正相关的,cmake通过指定环境变量能打印出编译和链接阶段的耗时情况,通过这个数据能直观的分析出耗时情况。
set_property(GLOBAL PROPERTY RULE_LAUNCH_COMPILE "${CMAKE_COMMAND} -E time")
set_property(GLOBAL PROPERTY RULE_LAUNCH_LINK "${CMAKE_COMMAND} -E time")编译耗时结果输出:
通过上面的工具分析能拿到几个编译数据:
① 头文件依赖关系及个数。 ② 预编译展开大小及内容。 ③ 各个文件编译耗时。 ④ 整体链接耗时。 ⑤ 可以计算出编译并行度。
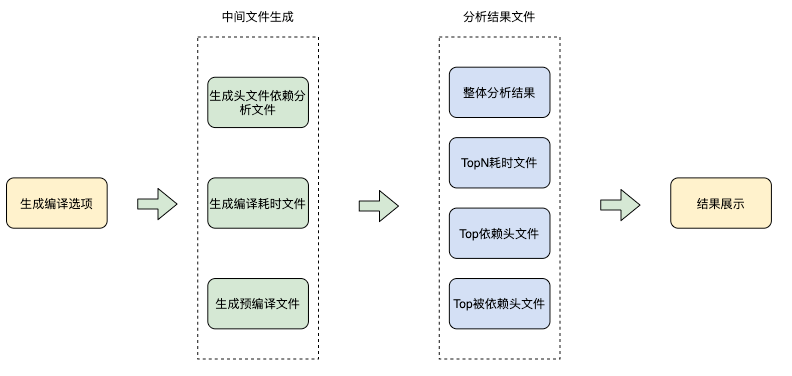
通过这几个数据的输入我们考虑可以做个自动化分析工具,找出优化点以及界面化展示。基于这个目的,我们建设了全流程自动化分析工具,能够自动分析耗时共性问题以及TopN耗时文件。分析工具处理流程如下图所示:
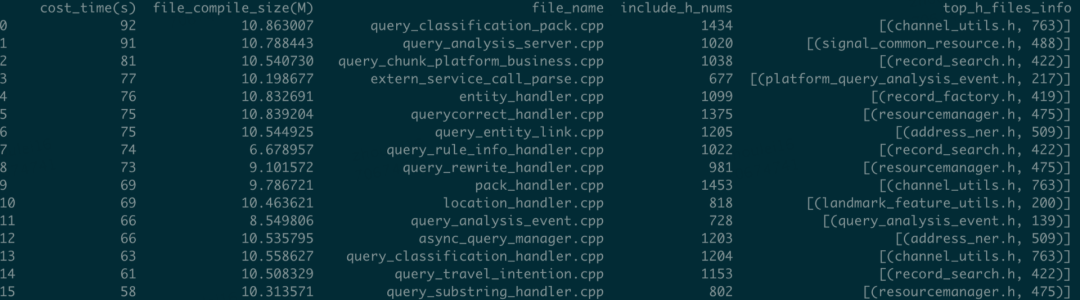
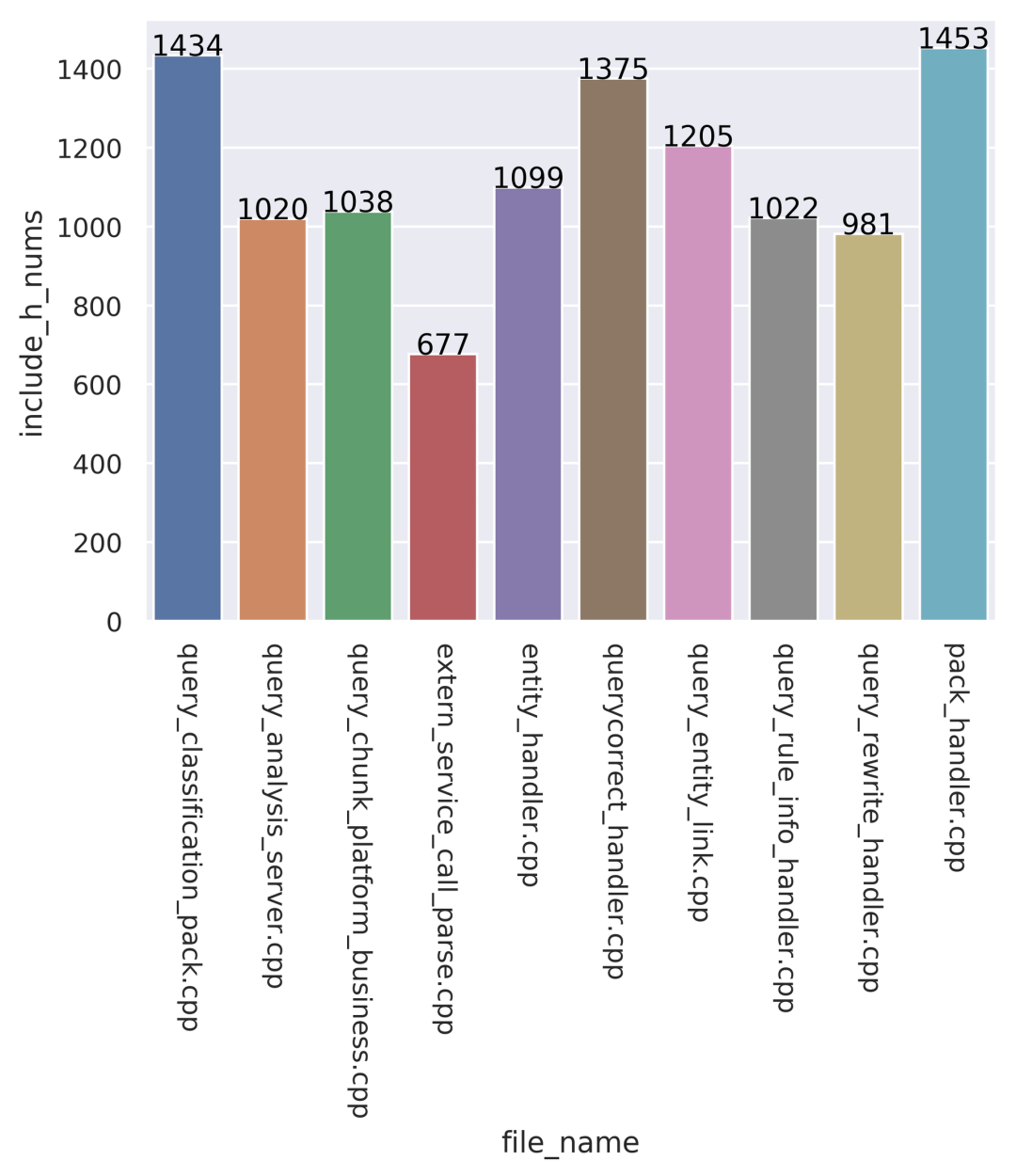
① cost_time 编译耗时,单位是秒。 ② file_compile_size,编译中间文件大小,单位是M。 ③ file_name,文件名称。 ④ include_h_nums,引入头文件个数,单位是个。 ⑤ top_h_files_info, 引入最多的TopN头文件。
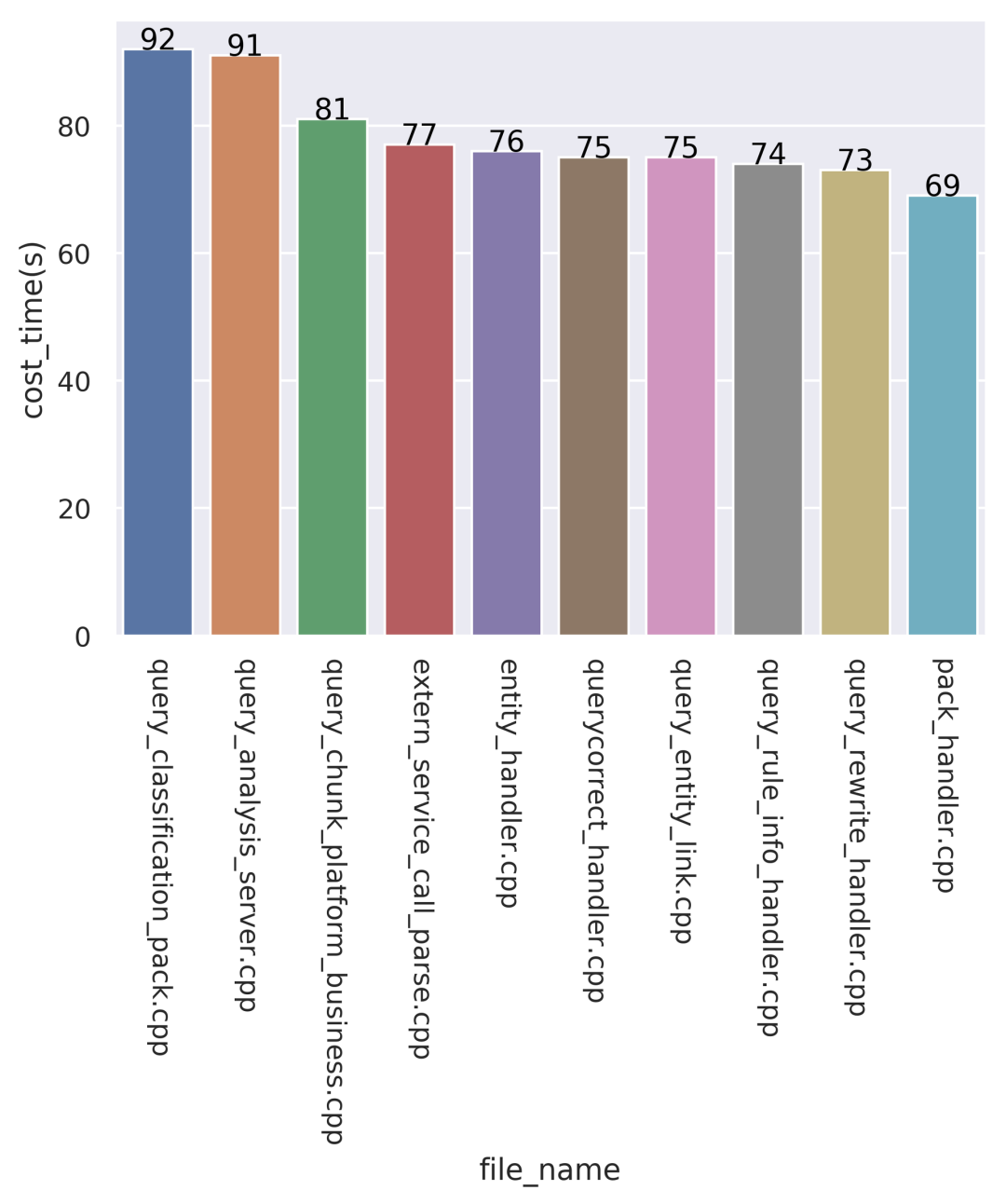
2. Top10 编译耗时文件统计
用来展示统计编译耗时最久的TopN文件,N可以自定义指定。
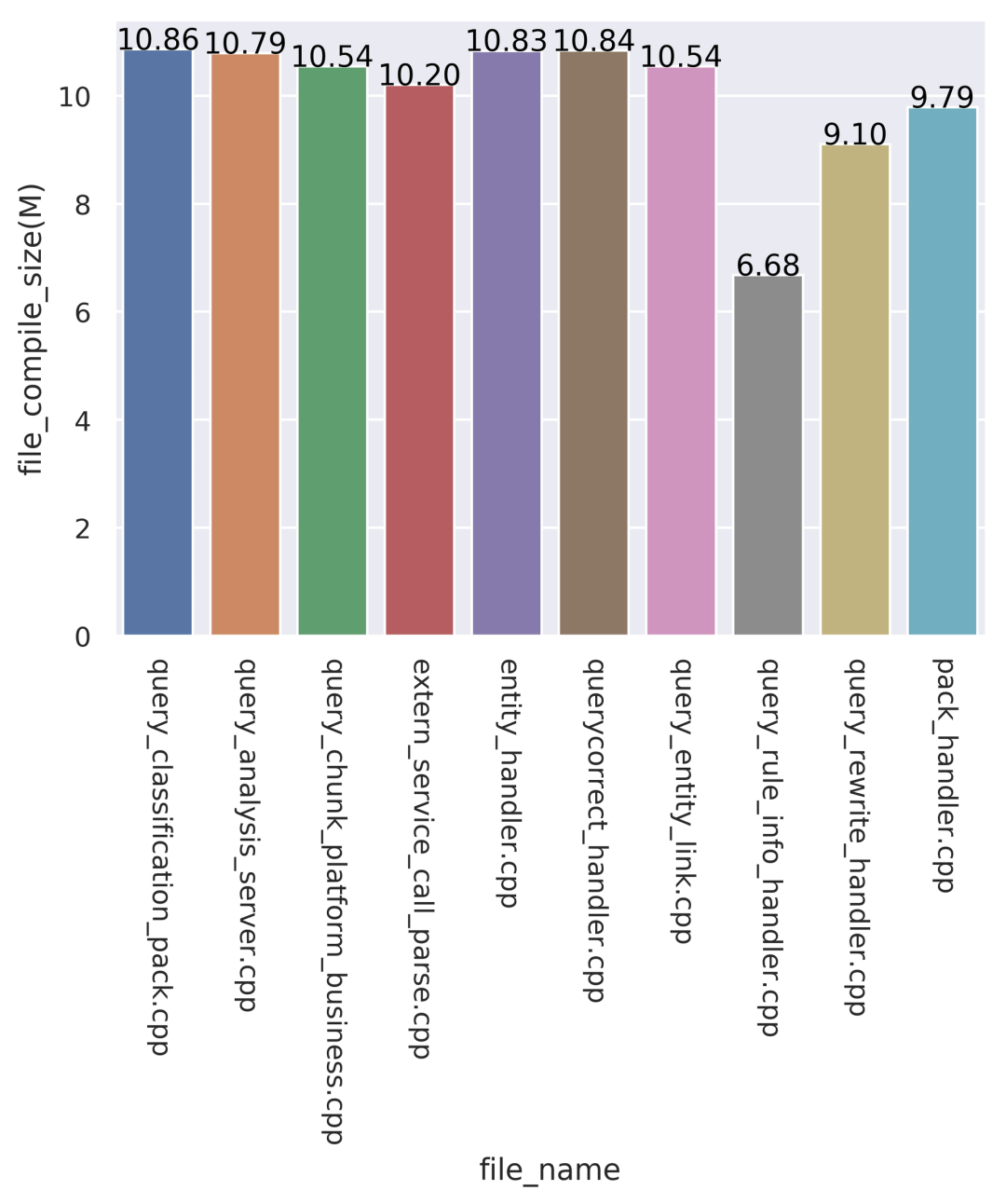
通过统计和展示编译文件大小,用来判断这块是否符合预期,这个是和编译耗时一一对应的。
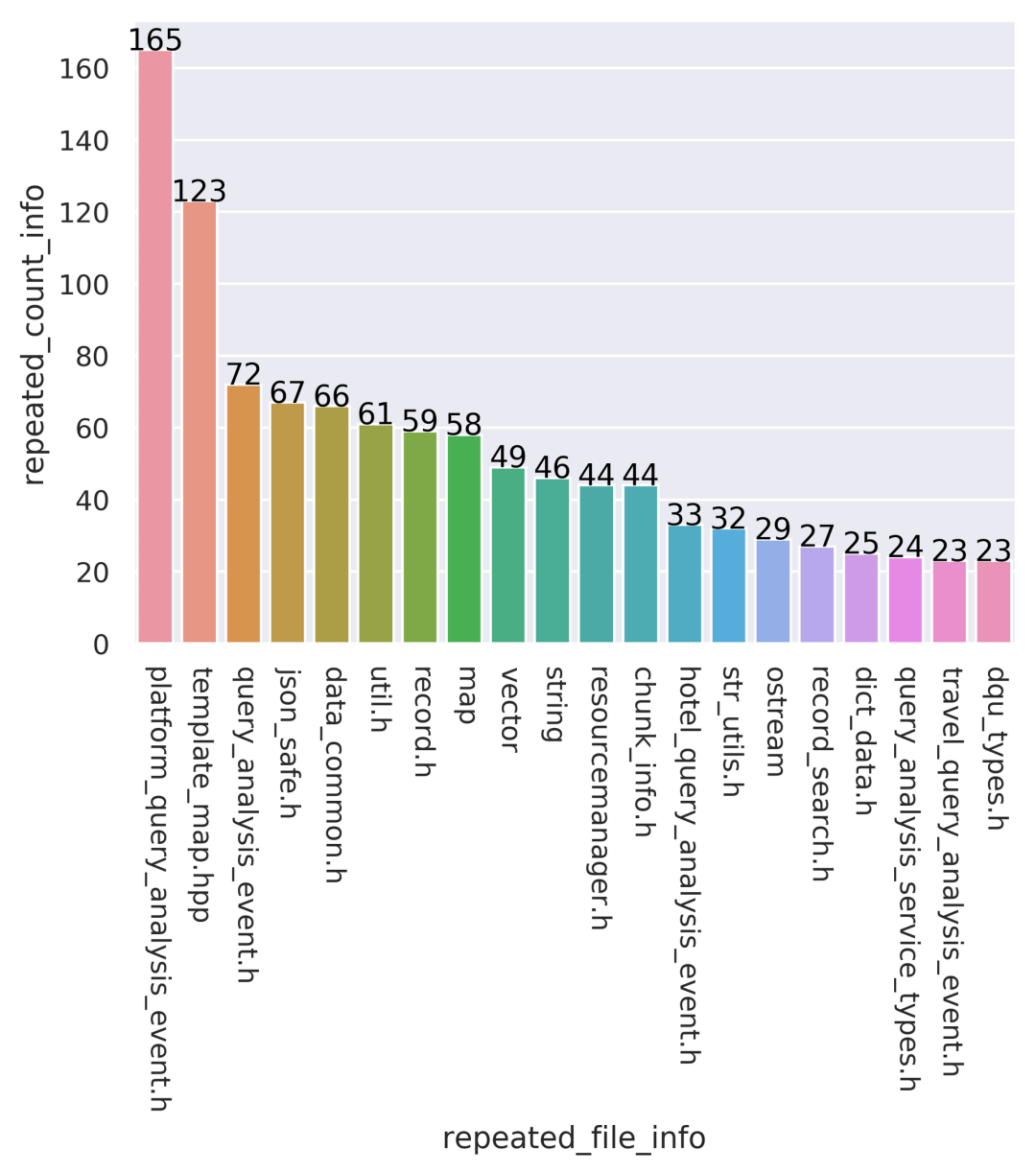
四、优化方案与实践
通过运用上述相关工具,我们能够发现Top10编译耗时文件的共性,比如都依赖消息总线文件platform_query_analysis_enent.h,这个文件又直接间接引入2000多个头文件,我们重点优化了这类文件,通过工具的编译展开,找出了Boost使用、模板类展开、Thrift头文件展开等共性问题,并针对这些问题做专门的优化。此外,我们也使用了一些业内通用的编译优化方案,并取得了不错的效果。下面详细介绍我们采用的各种优化方案。
4.1 通用编译加速方案
业内有不少通用编译加速工具(方案),无需侵入代码就能提高编译速度,非常值得尝试。
1. 并行编译
在Linux平台上一般使用GNU的Make工具进行编译,在执行make命令时可以加上-j参数增加编译并行度,如make -j 4将开启4个任务。在实践中我们并不将该参数写死,而是通过$(nproc)方法动态获取编译机的CPU核数作为编译并发度,从而最大限度利用多核的性能优势。
2. 分布式编译
使用分布式编译技术,比如利用Distcc和Dmucs构建大规模、分布式C++编译环境,Linux平台利用网络集群进行分布式编译,需要考虑网络时延与网络稳定性。分布式编译适合规模较大的项目,比如单机编译需要数小时甚至数天。DQU服务从代码规模以及单机编译时长来说,暂时还不需要使用分布式的方式来加速,具体细节可以参考Distcc官方文档说明。
3. 预编译头文件
PCH(Precompiled Header),该方法预先将常用头文件的编译结果保存起来,这样编译器在处理对应的头文件引入时可以直接使用预先编译好的结果,从而加快整个编译流程。PCH是业内十分常用的加速编译的方法,且大家反馈效果非常不错。在我们的项目中,由于涉及到很多Shared Library的编译生成,而Shared Library相互之间无法共享PCH,因此没有取得预想效果。
4. CCache
CCache(Compiler Cache)是一个编译缓存工具,其原理是将cpp的编译结果保存在文件缓存中,以后编译时若对应文件无变动可直接从缓存中获取编译结果。需要注意的是,Make本身也有一定缓存功能,当目标文件已编译(且依赖无变化)时,若源文件时间戳无变化也不会再次编译;但CCache是按文件内容做的缓存,且同一机器的多个项目可以共享缓存,因此适用面更大。
5. Module编译
如果你的项目是用C++ 20进行开发的,那么恭喜你,Module编译也是一个优化编译速度的方案,C++20之前的版本会把每一个cpp当做一个编译单元处理,会存在引入的头文件被多次解析编译的问题。而Module的出现就是解决这一问题,Module不再需要头文件(只需要一个模块文件,不需要声明和实现两个文件),它会将你的(.ixx 或者 .cppm)模块实体直接编译,并自动生成一个二进制接口文件。import和include预处理不同,编译好的模块下次import的时候不会重复编译,可以大幅度提高编译器的效率。
6. 自动依赖分析
Google也推出了开源的Include-What-You-Use工具(简称IWYU),基于Clang的C/C++工程冗余头文件检查工具。IWYU依赖Clang编译套件,使用该工具可以扫描出文件依赖问题,同时该工具还提供脚本解决头文件依赖问题,我们尝试搭建了这套分析工具,这个工具也提供自动化头文件解决方案,但是由于我们的代码依赖比较复杂,有动态库、静态库、子仓库等,这个工具提供的优化功能不能直接使用,其它团队如果代码结构比较简单的话,可以考虑使用这个工具分析优化,会生成如下结果文件,指导哪些头文件需要删除。
>>> Fixing #includes in '/opt/meituan/zhoulei/query_analysis/src/common/qa/record/brand_record.h'
@@ -1,9 +1,10 @@
#ifndef _MTINTENTION_DATA_BRAND_RECORD_H_
#define _MTINTENTION_DATA_BRAND_RECORD_H_
-#include "qa/data/record.h"
-#include "qa/data/template_map.hpp"
-#include "qa/data/template_vector.hpp"
-#include <boost/serialization/version.hpp>
+#include <boost/serialization/version.hpp> // for BOOST_CLASS_VERSION
+#include <string> // for string
+#include <vector> // for vector
+
+#include "qa/data/file_buffer.h" // for REG_TEMPLATE_FILE_HANDLER4.2 代码优化方案与实践
1. 前置类型声明
通过分析头文件引用统计,我们发现项目中被引用最多的是总线类型Event,而该类型中又放置了各种业务需要的成员,示例如下:
#include “a.h”
#include "b.h"
class Event {
// 业务A, B, C ...
A1 a1;
A2 a2;
// ...
B1 b1;
B2 b2;
// ...
};这导致Event中包含了数量庞大的头文件,在头文件展开后,文件大小达到15M;而各种业务都会需要使用Event,自然会严重拖累编译性能。
我们通过前置类型声明来解决这个问题,即不引入对应类型的头文件,只做前置声明,在Event中只使用对应类型的指针,如下所示:
class A1;
class A2;
// ...
class Event {
// 业务A, B, C ...
shared_ptr<A1> a1;
shared_ptr<A2> a2;
// ...
shared_ptr<B1> b1;
shared_ptr<B2> b2;
// ...
};只有在真正使用对应成员变量时,才需要引入对应头文件;这样真正做到了按需引入头文件。
2. 外部模板
由于模板被使用时才会实例化这一特性,相同的实例可以出现在多个文件对象中。编译器要对每一处模板进行实例化,链接器还要移除重复的实例化代码。当在广泛使用模板的项目中,编译器会产生大量的冗余代码,这会极大地增加编译时间和链接时间。C++ 11新标准中可以通过外部模板来避免。
// util.h
template <typename T>
void max(T) { ... }
// A.cpp
extern template void max<int>(int);
#include "util.h"
template void max<int>(int); // 显式地实例化
void test1()
{
max(1);
}在编译A.cpp的时候,实例化出一个 max(int)版本的函数。
// B.cpp
#include "util.h"
extern template void max<int>(int); // 外部模板的声明
void test2()
{
max(2);
}在编译B.cpp的时候,就不再生成 max(int)实例化代码,这样就节省了前面提到的实例化,编译以及链接的耗时了。
3. 多态替换模板使用
我们的项目重度使用词典相关操作,如加载词典、解析词典、匹配词典(各种花式匹配),这些操作都是通过Template模板扩展支持各种不同类型的词典。据统计,词典的类型超过150个,这也造成模板展开的代码量膨胀。
template <class R>
class Dict {
public:
// 匹配key和condition,赋值给record
bool match(const string &key, const string &condition, R &record); // 对每种类型的Record都会展开一次
private:
map<string, R> dict;
};幸运的是,我们词典的绝大部分操作都可以抽象出几类接口,因此可以只实现针对基类的操作:
class Record { // 基类
public:
virtual bool match(const string &condition); // 派生类需实现
};
class Dict {
public:
shared_ptr<Record> match(const string &key, const string &condition); // 使用方传入派生类的指针即可
private:
map<string, shared_ptr<Record>> dict;
};通过继承和多态,我们有效避免了大量的模板展开。需要注意的是,使用指针作为Map的Value会增加内存分配的压力,推荐使用Tcmalloc或Jemalloc替换默认的Ptmalloc优化内存分配。
4. 替换Boost库
Boost是一个广泛使用的基础库,涵盖了大量常用函数,十分方便、好用,然而也存在一些不足之处。一个显著缺点是其实现采用了hpp的形式,即声明和实现均放在头文件中,这会造成预编译展开后十分巨大。
// 字符串操作是常用功能,仅仅引入该头文件展开大小就超过4M
#include <boost/algorithm/string.hpp>
// 与此相对的,引入多个STL的头文件,展开后仅仅只有1M
#include <vector>
#include <map>
// ...在我们项目中主要使用的Boost函数不超过二十个,部分可以在STL中找到替代,部分我们手动做了实现,使得项目从重度依赖Boost转变成绝大部分达到Boost-Free,大大降低了编译的负担。
5. 预编译
代码中有一些平常改动比较少,但是对编译耗时产生一定的影响,比如Thrift生成的文件,模型库文件以及Common目录下的通用文件,我们采取提起预编译成动态库,减少后续文件的编译耗时,也解决了部分编译依赖。
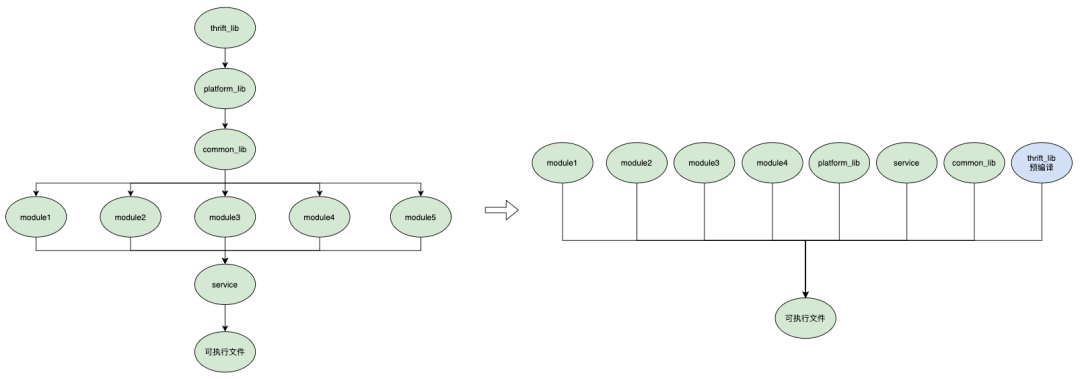
6. 解决编译依赖,提高编译并行度
在我们项目中有大量模块级别的动态库文件需要编译,cmake文件指定的编译依赖关系在一定程度上限制了编译并行度的执行。
比如下面这个场景,通过合理设置库文件依赖关系,可以提高编译并行度。
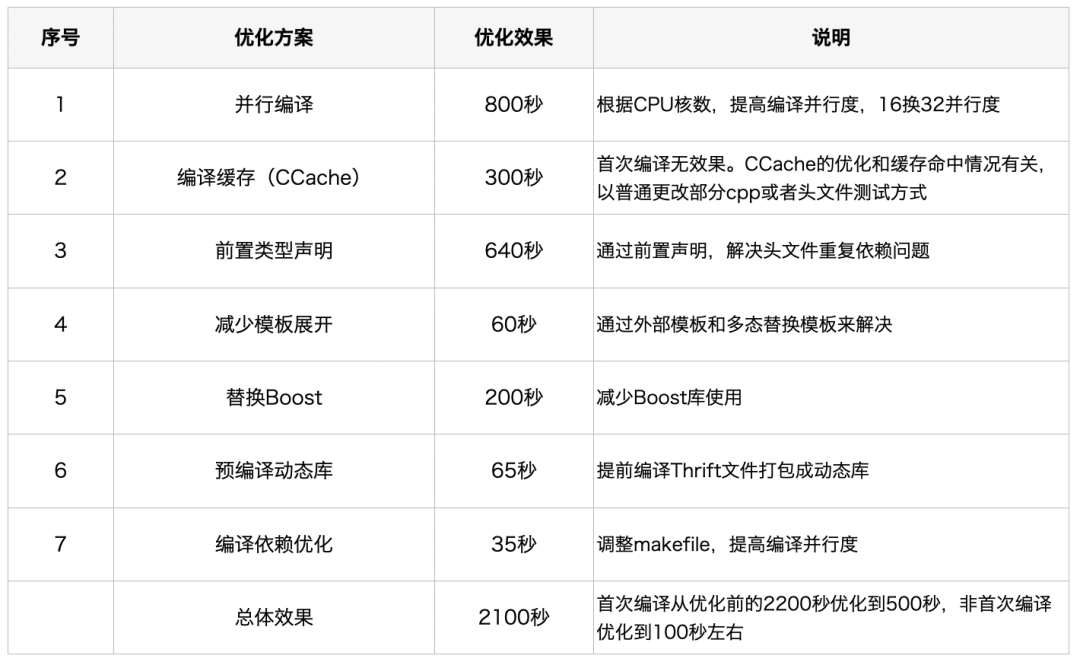
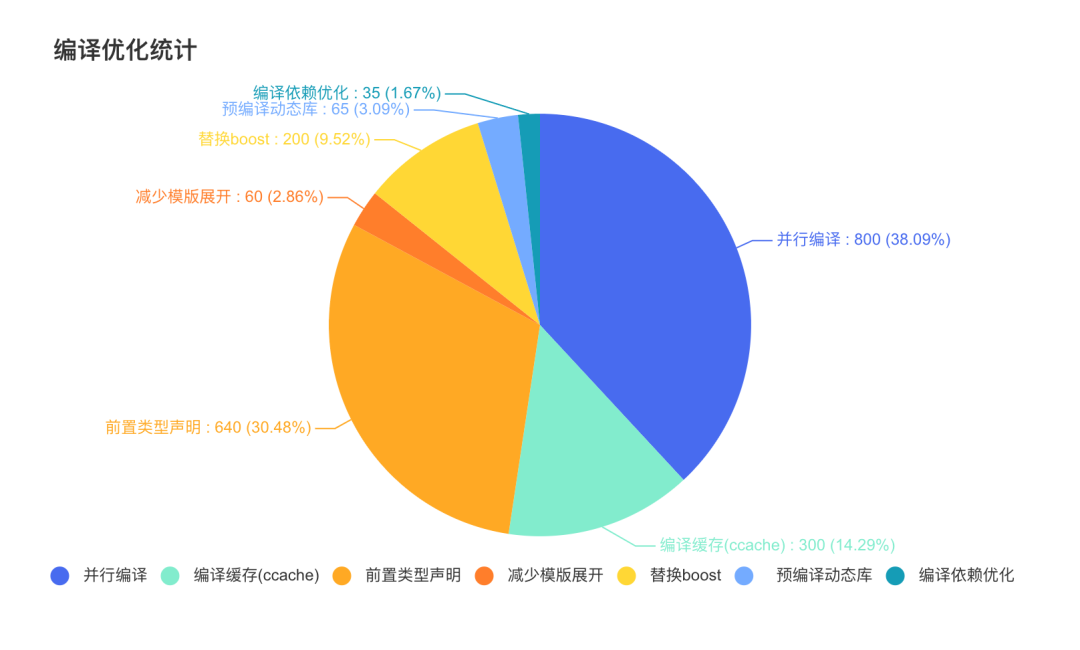
我们通过32C、64G内存机器做了编译耗时优化前后的效果对比,统计结果如下:
编译优化是一件“逆水行舟”的事情,开发人员总是倾向于不断增加新的功能、新的库乃至新的框架,而要删除旧代码、旧库、下线旧框架总是困难重重(相信一线开发人员一定深有体会)。因此,如何守住之前取得的优化成果也是至关重要的。我们在实践中有以下几点体会:
- 代码审核是困难的(引起编译耗时增加的改动,往往无法通过审核代码直观地发现)。
- 工具、流程才值得依赖。
- 关键在于控制增量。
我们发现,cpp文件的编译耗时,和其预编译展开文件(.ii)大小呈正相关(绝大部分情况下);对每一个上线版本,将其所有cpp文件的预编译展开大小记录下来,就形成了其编译指纹(CF,Compile Fingerprint)。通过比较相邻两个版本的CF,就能较准确的知道新版带来的编译耗时主要由哪些改动引入,并可以进一步分析耗时上涨是否合理,是否有优化空间。
我们将该种方式制作成脚本工具并引入上线流程,从而能够很清楚的了解每次代码发版带来的编译性能影响,并有效地帮助我们守住前期的优化成果。
五、总结
DQU项目是美团搜索业务环节中重要的一环,该系统需要对接20+RPC、数十个模型、加载超过300个词典,使用内存数十G,日均响应请求超过20亿的大型C++服务。在业务高速迭代的情况,冗长的编译时间为开发同学带来较大的困扰,一定程度上制约了开发效率。最终我们通过编译优化分析工具建设,结合采用了通用编译优化加速方案和代码层面的优化,将DQU的编译时间缩短了70%,并通过引CCache等手段,使得本地开发的编译,能够在100s内完成,给开发团队节省了大量的时间。
在取得阶段性成果之后,我们总结整个问题解决的过程,并沉淀出一些分析方法、工具以及流程规范。这些工具在后续的开发迭代过程中,能够快速有效地检测新的代码变更带来的编译时间变化,并成为了我们的上线流程检查中的一环检测标准。这一点与我们以往一次性的或者针对性的编译优化,产生了很大的区别。毕竟代码的维护是一个持久的过程,系统化的解决这一问题,不只是需要有效的方法和便捷的工具,更需要一个标准化的,规范化的上线流程来保持成果。希望本文对大家能有所帮助。
参考文献
[1]《编译原理透视·图解编译原理》
[2] CCache
[3] 分布式编译
[4] 头文件预编译
[5] 头文件预编译
[6] C++Templates介绍
[7] Include-what-you-use